[머신러닝] 캘리포니아 주택 가격 프로젝트-2
◆ 프로젝트: 캘리포니아 주택 가격 데이터셋을 이용한 머신러닝 프로젝트
이 데이터셋은 1990년 캘리포니아 인구 조사 데이터를 기반으로 하며, 진행할 주요 단계는 아래와 같다.
- 데이터 준비
- 데이터로부터 인사이트를 얻기 위해 탐색하고 시각화
- 모델 선택하고 훈련
- 모델 미세 튜닝
- 솔루션 제시
- 시스템 론칭, 모니터링, 유지보수
이전 내용
[머신러닝] 캘리포니아 주택 가격 프로젝트
◆ 프로젝트: 캘리포니아 주택 가격 데이터셋을 이용한 머신러닝 프로젝트이 데이터셋은 1990년 캘리포니아 인구 조사 데이터를 기반으로 하며, 진행할 주요 단계는 아래와 같다.데이터 준비데
puppy-foot-it.tistory.com
특성 스케일과 변환
데이터에 적용할 변환 한 가지는 특성 스케일링으로, 머신러닝 알고리즘은 입력된 숫자 특성들의 스케일이 많이 다르면 제대로 작동하지 않는다.
주택 가격 데이터의 경우, 전체 방 개수의 범위는 6~39,320인 반면 중간 소득의 범위는 0~15로, 스케일링을 적용하지 않으면 대부분의 모델은 방 개수에 더 초점을 맞출 것이다.
[대표적인 스케일링 방법]
- min-max 스케일링(정규화): 각 특성에 대해서 0~1 범위에 들도록 값을 이동하고 스케일을 조정 - 사이킷런의 MinMaxScaler 변환기 (feature_range 매개변수 사용)
- 표준화: 먼저 평균을 뺀 후 표준 편차로 나누는데, 특정 범위로 값을 제한하지 않음. 이상치에 영향을 덜 받는다. - 사이킷런의 StandardScaler 변환기
# 정규화
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler(feature_range=(-1, 1))
housing_num_min_max_scaled = min_max_scaler.fit_transform(housing_num)# 표준화
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
housing_num_std_scaled = std_scaler.fit_transform(housing_num)※ 희소 행렬을 밀집 행렬로 바꾸지 않고 스케일링하고 싶다면 StandardScaler 사용 시 with_mean 하이퍼파라미터를 False로 지정하면 데이터에서 평균을 빼지 않고 표준 편차로 나눠 희소성이 깨지지 않는다.
[꼬리가 두꺼운 특성 처리하는 방법]
특성 분포의 꼬리가 두꺼울 때 min-max 스케일링과 표준화는 대부분의 값을 작은 범위로 압축하는데, 머신러닝 모델은 일반적으로 이런 값을 좋아하지 않는다. 따라서 특성을 스케일링 하기 전에 두꺼운 꼬리를 줄이도록 데이터를 먼저 변환하고 분포가 대략적으로 대칭이 되도록 만들어야 한다.
1) 멱법칙 분포처럼 특성 분포의 꼬리가 아주 길고 두껍다면 특성을 로그값으로 바꾸는 것이 도움이 될 수 있다.
인구 특성을 가우스 분포에 가깝게 변환하기
fig, axs = plt.subplots(1, 2, figsize=(8, 3), sharey=True)
housing["population"].hist(ax=axs[0], bins=50)
housing["population"].apply(np.log).hist(ax=axs[1], bins=50)
axs[0].set_xlabel("Population")
axs[1].set_xlabel("Log of population")
axs[0].set_ylabel("Number of districts")
plt.show()
2) 특성을 버킷타이징 한다.
※ 버킷타이징: 분포를 거의 동일한 크기의 버키승로 자른 뒤 특성값을 해당하는 버킷의 인덱스로 만드는 것.
거의 동일한 크기의 버킷을 사용하면 거의 균등 분포인 특성을 만들어 추가적으로 스케일링을 할 필요가 없다. 또는 버킷 개수로 나누어 0~1 사이 범위로 만들 수 있다.
housing_med1ian_age 처럼 특성이 멀티모달 분포일 때 버킷타이징을 사용하면 도움이 될 수 있다. 이런 방법을 사용하면 회귀 모델이 특성값의 여러 범주에 대해서 다양한 규칙을 쉽게 학습할 수 있다.
멀티모달 분포를 변환하는 또 다른 방법은 주요 모드에 대해 특정 모드 사이의 유사도를 나타내는 특성을 추가하는 것인데, 유사도 측정은 일반적으로 입력값과 고정 포인트 사이의 거리에만 의존하는 방사 기저 함수(RBF)를 사용한다.
가장 널리 사용되는 RBF는 입력값이 고정 포인트에서 멀어질수록 출력값이 지수적으로 감소하는 가우스 RBF이다.
사이킷런의 rbf_kernel() 함수를 사용하면 중간 주택 연도와 35 사이의 유사도를 재는 새로운 가우스 RBF 특성을 만들 수 있다.
from sklearn.metrics.pairwise import rbf_kernel
age_simil_35 = rbf_kernel(housing[['housing_median_age']], [[35]], gamma=0.1)
ages = np.linspace(housing["housing_median_age"].min(),
housing["housing_median_age"].max(),
500).reshape(-1, 1)
gamma1 = 0.1
gamma2 = 0.03
rbf1 = rbf_kernel(ages, [[35]], gamma=gamma1)
rbf2 = rbf_kernel(ages, [[35]], gamma=gamma2)
fig, ax1 = plt.subplots()
ax1.set_xlabel("Housing median age")
ax1.set_ylabel("Number of districts")
ax1.hist(housing["housing_median_age"], bins=50)
ax2 = ax1.twinx() # x축을 공유 하는 쌍둥이 축을 만듭니다
color = "blue"
ax2.plot(ages, rbf1, color=color, label="gamma = 0.10")
ax2.plot(ages, rbf2, color=color, label="gamma = 0.03", linestyle="--")
ax2.tick_params(axis='y', labelcolor=color)
ax2.set_ylabel("Age similarity", color=color)
plt.legend(loc="upper left")
plt.show()
※ 멀티모달 분포 (빨간색 네모): 모드라 부르는 정점이 두 개 이상 나타나는 분포)
[타깃값 변환]
타깃 분포의 꼬리가 두껍다면 타깃을 로그값으로 바꿀 수 있으나, 이렇게 하면 회귀 모델이 중간 주택 가격 자체가 아니라 중간 주택 가격의 로그를 예측하게 되므로 중간 주택 가격을 얻고 싶다면 모델 예측에 지수 함수를 적용해야 한다.
대부분의 사이킷런 변환기에는 역변환을 수행하는 inverse_transform() 메서드가 있으며, TransformedTargetRegressor를 사용하는 것이 더 간단하다.
이 클래스의 객체를 생성한 다음 회귀 모델과 레이블 변환기를 전달하고 스케일링 되지 않은 원본 레이블을 사용해 훈련 세트로 훈련하고, 예측을 만들 때는 회귀 모델의 predict() 메서드를 호출하고 변환기의 inverse_transform() 메서드를 사용해 예측을 생성한다.
from sklearn.compose import TransformedTargetRegressor
from sklearn.linear_model import LinearRegression
model = TransformedTargetRegressor(LinearRegression(),
transformer=StandardScaler())
model.fit(housing[['median_income']], housing_labels)
# 새로운 데이터
some_new_data = housing[['median_income']].iloc[:5]
predictions= model.predict(some_new_data)
[사용자 정의 변환기]
어떤 훈련도 필요하지 않는 변환의 경우, 넘파이 배열을 입력받고 변환된 배열을 출력하는 함수 작성
(로그 변환기를 만들어 인구 특성에 적용)
from sklearn.preprocessing import FunctionTransformer
log_transformer = FunctionTransformer(np.log, inverse_func=np.exp)
log_pop = log_transformer.transform(housing[['population']])▶ inverse_func 매개변수는 선택사항
사용자 정의 변환 함수는 추가적인 인수로 하이퍼파라미터를 받을 수 있다.
rbf_transformer = FunctionTransformer(rbf_kernel,
kw_args=dict(Y=[[35.]], gamma=0.1))
age_simil_35 = rbf_transformer.transform(housing[['housing_median_age']])▶ RBF 커널은 고정 포인트에서 일정 거리만큼 떨어진 값이 항상 두 개이기 때문에 역함수가 없다
두 개의 특성을 가진 배열을 전달하면 유사도를 측정하기 위해 유클리드 거리를 계산한다.
# 각 구역과 샌프란시스코 사이의 지리적 유사도를 측정하는 특성 추가
sf_coords = 37.7749, -122.41
sf_transformer = FunctionTransformer(rbf_kernel,
kw_args=dict(Y=[sf_coords], gamma=0.1))
sf_simil = sf_transformer.transform(housing[["latitude", "longitude"]])
sf_simil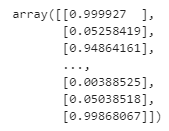
사용자 정의 변환기는 특성을 합칠 때도 유용하다.
(첫 번째 입력 특성과 두 번째 특성 사이의 비율 계산)
ratio_transformer = FunctionTransformer(lambda X : X[:, [0]] / X[:, [1]])
ratio_transformer.transform(np.array([[1., 2.], [3., 4.]]))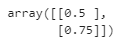
FuctionTransformer는 매우 편리하지만 fit() 메서드에서 특정 파라미터를 학습하고 나중에 transform() 메서드에서 이를 사용하기 위해 훈련 가능한 변환기가 필요할 경우 사용자 정의 클래스를 작성해야 한다.
필요한 것은 fit(), transform(), fit_transform() 세 개의 메서드인데, fit_transform() 메서드는 TransformerMixin을 상속하면 자동으로 생성되고, 기본적으로 이 메서드는 그냥 fit()과 transform()을 연달아 호출한다. 또한 BaseEstimator를 상속하면 하이퍼파라미터 튜닝에 필요한 두 메서드 get_params()와 set_params()를 추가로 얻게 된다.
# StandadrdScaler와 비슷하게 작동하는 사용자 정의 변환기
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils.validation import check_array, check_is_fitted
class StandardScalerClone(BaseEstimator, TransformerMixin):
def __init__(self, with_mean=True): # args나 **kwargs 를 사용하지 않음
self.with_mean = with_mean
def fit(self, X, y=None): # 사용하지 않더라도 y를 넣어야 함
X = check_array(X) # X가 부동소수점 배열인지 확인
self.mean_ = X.mean(axis=0)
self.scale_ = X.std(axis=0)
self.n_features_in_ = X.shape[1] # 모든 추정기는 fit()에서 이를 저장
return self # 항상 self를 반환
def transform(self, X):
check_is_fitted(self) # 훈련으로 학습된 속성이 있는지 확인
X = check_array(X)
assert self.n_features_in_ == X.shape[1]
if self.with_mean:
X = X - self.mean
return X / self.scale_- sklearn.utils.validation 패키지에는 입력을 검증하기 위해 사용할 수 있는 함수가 여러 개 있다
- 사이킷런 파이프라인은 X와 y 두 개의 매개변수를 가진 메서드가 필요하여 y를 사용하지 않지만 y=None 필요
- 모든 사이킷런 추정기는 fit() 메서드 안에서 n_features_in_을 설정하고 transform()이나 predict() 메서드에 전달된 데이터의 특성 개수가 동일한지 확인
- fit() 메서드는 self를 반환해야 한다
- 모든 추정기는 DataFrame이 전달될 때 fit() 메서드 안에서 feature_names_in_을 설정해야 하며, 모든 변환기는 get_feature_names_out() 메서드와 역변환을 위한 inverse_transform() 메서드를 제공해야 한다
하나의 사용자 변환기가 구현 안에서 다른 추정기를 사용할 수 있다.
# fit() 메서드 안에서 훈련 데이터에 있는 핵심 클러스 식별을 위해 KMeans 클래스 사용
# transform() 메서드에서 rbf_kernel()을 사용해 각 샘플이 클러스터 중심과 얼마나 유사한지 측정
from sklearn.cluster import KMeans
class ClusterSimilarity(BaseEstimator, TransformerMixin):
def __init__(self, n_clusters=10, gamma=1.0, random_state=None):
self.n_clusters = n_clusters
self.gamma = gamma
self.random_state = random_state
def fit(self, X, y=None, sample_weight=None):
self.kmeans_ = KMeans(self.n_clusters, random_state=self.random_state)
self.kmeans_.fit(X, sample_weight=sample_weight)
return self # 항상 self를 반환
def transform(self, X):
return rbf_kernel(X, self.kmeans_.cluster_centers_, gamma=self.gamma)
def get_feature_names_out(self, names=None):
return [f'클러스터 {i} 유사도' for i in range(self.n_clusters)]
k-평균은 데이터에 있는 클러스터를 찾는 군집 알고리즘이며, 찾으려는 클러스터 개수는 n_clusters 하이퍼파라미터로 지정한다.
훈련이 끝난 다음 클러스터 중심은 cluster_centers_ 속성으로 확인할 수 있다.
KMeans의 fit() 메서드는 선택적 매개변수 sample_weight를 제공하며 이 매개변수에 샘플의 상대적인 가중치를 지정할 수 있다.
k-평균은 확률적인 알고리즘으로, 클러스터를 찾기 위해 무작위성에 의존하여 결과를 동일하게 재현하려면 random_state 매개변수를 지정해야 한다.
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
similarities = cluster_simil.fit_transform(housing[['latitude', 'longitude']],
sample_weight=housing_labels)
similarities[:3].round(2)
housing_renamed = housing.rename(columns={
"latitude": "Latitude", "longitude": "Longitude",
"population": "Population",
"median_house_value": "Median house value (ᴜsᴅ)"})
housing_renamed["Max cluster similarity"] = similarities.max(axis=1)
housing_renamed.plot(kind="scatter", x="Longitude", y="Latitude", grid=True,
s=housing_renamed["Population"] / 100, label="Population",
c="Max cluster similarity",
cmap="jet", colorbar=True,
legend=True, sharex=False, figsize=(10, 7))
plt.plot(cluster_simil.kmeans_.cluster_centers_[:, 1],
cluster_simil.kmeans_.cluster_centers_[:, 0],
linestyle="", color="black", marker="X", markersize=20,
label="Cluster centers")
plt.legend(loc="upper right")
# 마이너스 기호 문제 해결하기
plt.rcParams['axes.unicode_minus'] = False
plt.show()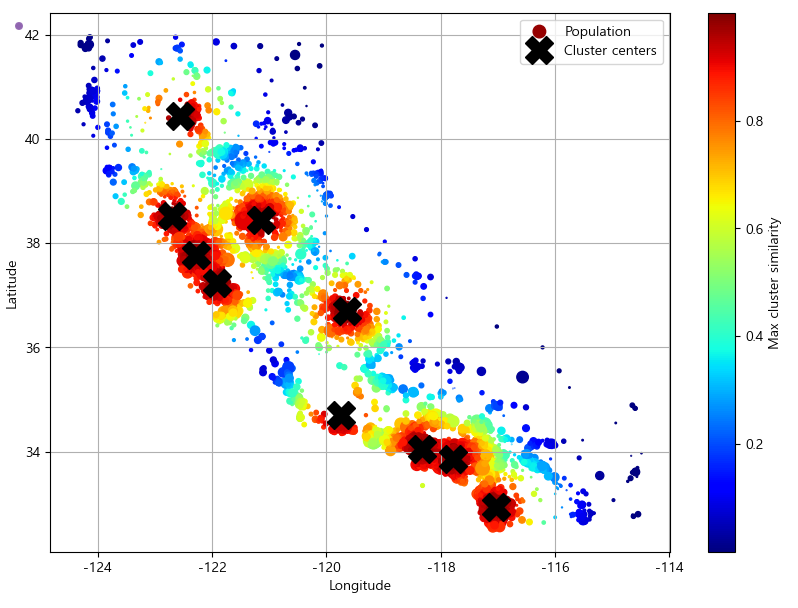
▶ 상단의 코드는 k-평균으로 찾은 클러스터 10개의 중심을 보여준다. 구역의 색은 가장 가까운 클러스터 중심과의 지리적 유사도에 따라서 지정된 것이며, 대부분의 클러스터는 인구가 많고 값비싼 지역에 위치해 있다.
[변환 파이프라인]
변환은 올바른 순서대로 실행되어야 하는데, 사이킷런은 변환을 순서대로 처리하도록 도와주는 Pipeline 클래스를 제공한다.
수치 특성에서 누락된 값을 대체하고 스케일을 조정하는 간단한 파이프라인
from sklearn.pipeline import Pipeline
from sklearn import set_config
# 사이킷런 시각화
set_config(display='diagram')
num_pipeline = Pipeline([
('impute', SimpleImputer(strategy='median')),
('standardize', StandardScaler()),
])
num_pipeline
변환기의 이름을 짓는 게 귀찮다면 make_pipeline() 함수를 사용하면 되는데, 이 함수는 위치 매개변수로 변환기를 받고 변환기의 클래스 이름을 밑줄 문자 없이 소문자로 바꾸어서 Pipeline 객체를 만든다
from sklearn.pipeline import make_pipeline
num_pipeline = make_pipeline(SimpleImputer(strategy='median'),StandardScaler())
파이프라인의 fit() 메서드를 호출하면 모든 변환기의 fit_transform() 메서드를 순서대로 호출하면서 한 단계의 출력을 다음 단계의 입력으로 전달하고, 마지막 단계에서는 fit() 메서드만 호출한다.
파이프라인 객체는 마지막 추정기와 동일한 메서드를 제공하는데, 만약 추정기가 변환기가 아니라 예측기라면 파이프라인은 transform() 메서드 대신 predict() 메서드를 가지며 이 파이프라인을 호출하면 데이터의 모든 변환을 순서대로 적용하고 그 결과를 예측기의 predict() 메서드에 전달한다
# 파이프라인의 fit_transform() 메서드를 호출하고 출력에서 처음 두 행의 출력을 소수점 둘째 자리에서 반올림
housing_num_prepared = num_pipeline.fit_transform(housing_num)
housing_num_prepared[:2].round(2)
파이프라인은 인덱싱 기능을 제공한다
# 데이터프레임으로 재구성하려면 get_feature_names_out() 메서드 사용
df_housing_num_prepared = pd.DataFrame(
housing_num_prepared, columns=num_pipeline.get_feature_names_out(),
index=housing_num.index)
df_housing_num_prepared.head()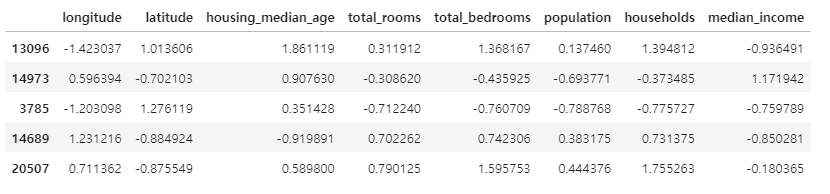
ColumnsTransformer로 하나의 변환기로 각 열마다 적절한 변환을 적용하여 모든 열을 처리할 수 있다
num_pipeline은 수치형, cat_pipeline은 범주형 특성에 적용하여 ColumnsTransformer 수행
from sklearn.compose import ColumnTransformer
num_attribs = ['longitude', 'latitude', 'housing_median_age', 'total_rooms', 'total_bedrooms',
'population', 'households', 'median_income']
cat_attribs = ['ocean_proximity']
cat_pipeline = make_pipeline(
SimpleImputer(strategy='most_frequent'),
OneHotEncoder(handle_unknown='ignore'))
preprocessing = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", cat_pipeline, cat_attribs),
])- ColumnTransformer 클래스 임포트
- 수치형 특성과 범주형 특성의 이름 리스트 생성
- 범주형 특성을 위한 간단한 파이프라인 생성
- ColumnsTransformer 객체 생성 (클래스의 생성자는 세 개의 원소를 가진 튜플의 리스트를 가지며, 각 튜플은 이름, 변환기, 변환기가 적용될 열 이름 또는 인덱스의 리스트로 구성)
※ 튜플에 변환기를 사용하는 대신 삭제하고 싶은 특성이 있다면 'drop'으로 지정하고,
변환을 적용하지 않을 특성이 있다면 'passthrough'로 지정
기본적으로 나머지 열은 삭제되는데, 나머지 열을 다르게 처리하고 싶다면 remainder 하이퍼파라미터에 변환기 또는 passthrough 를 지정할 수 있다 (remainder의 기본값은 drop)
모든 특성 이름을 일일이 나열하는 것은 번거롭기 때문에 사이킷런은 수치형이나 범주형처럼 주어진 타입의 모든 특성을 자동으로 선택해주는 make_column_selector 클래스를 제공한다. 이 클래스의 객체를 특성 이름이나 인덱스 대신 ColumnTransformer에 전달해주는 make_column_transformer 클래스를 사용하면 된다. 다만 변환기 이름은 'pipeline-1'처럼 자동 지정된다.
from sklearn.compose import make_column_selector, make_column_transformer
preprocessing = make_column_transformer(
(num_pipeline, make_column_selector(dtype_include=np.number)),
(cat_pipeline, make_column_selector(dtype_include=object)),
)
# ColumnTransformer 주택 데이터셋에 적용
housing_prepared = preprocessing.fit_transform(housing)앞서 진행한 모든 변환을 수행할 단일 파이프라인 만들기
[파이프라인이 할 일과 그 이유]
- 대부분의 머신러닝 알고리즘은 누락된 값을 기대하지 않기 때문에 수치형 특성의 경우 누락된 값을 중간값으로 대체. 범주형 특성의 경우 누락된 값을 가장 많이 등장하는 카테고리로 바꿈.
- 대부분의 머신러닝 알고리즘은 수치 입력만 받기 때문에 범주형 특성을 원-핫 인코딩
- 비율 특성인 bedrooms_ratio, rooms_per_house, people_per_house 를 계산하여 추가하면 중간 주택 가격과 상관관계가 높으므로 머신러닝 모델에 도움이 되기를 기대해볼 수 있다
- 몇 가지 클러스터 유사도 특성을 추가. 위도와 경도보다 모델에 더 유용할 수 있다
- 대부분의 모델은 균등 분포나 가우스 분포에 가까운 특성을 선호하기 때문에 꼬리가 두꺼운 분포를 띠는 특성을 로그값으로 변환
- 대부분의 머신러닝 알고리즘은 모든 특성이 대체로 동일한 스케일을 가질 때 잘 작동하므로 모든 수치 특성을 표준화
# 모든 작업을 수행하는 파이프라인 만들기
def column_ratio(X):
return X[:, [0]] / X[:, [1]]
def ratio_name(function_transformer, feature_names_in):
return ['ratio'] # get_feature_names_out에 사용
def ratio_pipeline():
return make_pipeline(
SimpleImputer(strategy='median'),
FunctionTransformer(column_ratio, feature_names_out=ratio_name),
StandardScaler())
log_pipeline = make_pipeline(
SimpleImputer(strategy='median'),
FunctionTransformer(np.log, feature_names_out='one-to-one'),
StandardScaler())
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
default_num_pipeline = make_pipeline(SimpleImputer(strategy='median'),
StandardScaler())
preprocessing = ColumnTransformer([
('bedrooms', ratio_pipeline(), ['total_bedrooms', 'total_rooms']),
('rooms_per_house', ratio_pipeline(), ['total_rooms', 'households']),
('people_per_house', ratio_pipeline(), ['population', 'households']),
('log', log_pipeline, ['total_bedrooms', 'total_rooms', 'population',
'households', 'median_income']),
('geo', cluster_simil, ['latitude', 'longitude']),
('cat', cat_pipeline, make_column_selector(dtype_include=object)),
],
remainder=default_num_pipeline) # 남은 특성: housing_median_age
ColumnTransformer를 실행하면 모든 변환이 수행되고 24개의 특성을 가진 넘파이 배열이 출력된다
housing_prepared = preprocessing.fit_transform(housing)
housing_prepared.shape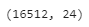
preprocessing.get_feature_names_out()
다음 내용
[머신러닝] 캘리포니아 주택 가격 프로젝트-3
◆ 프로젝트: 캘리포니아 주택 가격 데이터셋을 이용한 머신러닝 프로젝트이 데이터셋은 1990년 캘리포니아 인구 조사 데이터를 기반으로 하며, 진행할 주요 단계는 아래와 같다.데이터 준비데
puppy-foot-it.tistory.com
[출처]
핸즈온 머신러닝
hayeonoct.log