◆ 프로젝트: 캘리포니아 주택 가격 데이터셋을 이용한 머신러닝 프로젝트
이 데이터셋은 1990년 캘리포니아 인구 조사 데이터를 기반으로 하며, 진행할 주요 단계는 아래와 같다.
- 데이터 준비
- 데이터로부터 인사이트를 얻기 위해 탐색하고 시각화
- 모델 선택하고 훈련
- 모델 미세 튜닝
- 솔루션 제시
- 시스템 론칭, 모니터링, 유지보수
이전 내용
[머신러닝] 캘리포니아 주택 가격 프로젝트-2
◆ 프로젝트: 캘리포니아 주택 가격 데이터셋을 이용한 머신러닝 프로젝트이 데이터셋은 1990년 캘리포니아 인구 조사 데이터를 기반으로 하며, 진행할 주요 단계는 아래와 같다.데이터 준비데
puppy-foot-it.tistory.com
모델 선택과 훈련
[훈련 세트에서 훈련하고 평가하기]
간단한 선형 회귀 모델 훈련하기
from sklearn.linear_model import LinearRegression
lin_reg = make_pipeline(preprocessing, LinearRegression())
lin_reg.fit(housing, housing_labels)
# 훈련세트에 적용하고 처음 다섯 개 예측과 레이블 비교
housing_predictions = lin_reg.predict(housing)
print(housing_predictions[:5].round(-2))
print(housing_labels.iloc[:5].values)
전체 훈련 세트에 대해서 이 회귀 모델의 RMSE 측정
from sklearn.metrics import mean_squared_error
lin_rmse = mean_squared_error(housing_labels, housing_predictions,
squared=False)
lin_rmse
▶ 대부분 구역의 중간 주택 가격은 $120,000 ~ $265,000 사이인데, 예측 오차가 $68,972인 것은 매우 만족스럽지 못하며, 이는 모델이 훈련 데이터에 과소적합된 사례이다.
이런 상황은 특성들이 좋은 예측을 만들 만큼 충분한 정보를 제공하지 못했거나 모델이 충분히 강력하지 못하다는 사실을 말해주는데, 과소적합을 해결하는 주요 방법은
- 더 강력한 모델을 선택하거나,
- 훈련 알고리즘에 더 좋은 특성을 주입하거나,
- 모델의 규제를 감소시키는 것 (이 모델은 규제를 사용하지 않았으므로 이 방법은 제외)
첫 번째 방법을 위해 강력하며 데이터에서 복잡한 비선형 관계를 찾을 수 있는 DecisionTreeRegressor (결정 트리)를 훈련시켜 본다
from sklearn.tree import DecisionTreeRegressor
tree_reg = make_pipeline(preprocessing, DecisionTreeRegressor(random_state=42))
tree_reg.fit(housing, housing_labels)
# 모델 훈련 후 훈련 세트로 평가
housing_predictions = tree_reg.predict(housing)
tree_rmse = mean_squared_error(housing_labels, housing_predictions,
squared=False)
tree_rmse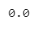
▶ 모델이 심하게 과대적합 되었을 가능성이 있으나, 확신이 드는 모델을 론칭하기 전까지는 테스트 세트를 사용하지 않을 것이므로 훈련 세트의 일부분으로 훈련하고 다른 일부분을 모델 검증에 사용해야 한다.
[교차 검증으로 평가하기]
사이킷런의 k-폴드 교차 검증 기능을 사용하여 훈련 세트를 폴드라 불리는 중복되지 않은 10개의 서브셋으로 랜덤으로 분할하고, 결정 트리 모델을 10번 훈련하고 평가한다. 평가 시에는 매번 다른 폴드를 선택해 평가에 사용하고 나머지 9개 폴드는 훈련에 사용된다.
10개의 평가 점수가 담긴 배열이 결과가 된다.
from sklearn.model_selection import cross_val_score
# neg_mean_squared_error 함수는 RMSE의 음숫값을 출력하므로 - 부호 추가
tree_rmses = -cross_val_score(tree_reg, housing, housing_labels,
scoring='neg_root_mean_squared_error', cv=10)
# 결과 표시
pd.Series(tree_rmses).describe()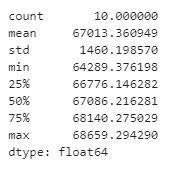
이번에는 RandomForestRegressor 모델로 한 번 더 시도해본다.
랜덤 포레스트는 특성을 랜덤으로 선택해서 많은 결정 트리를 만들고 예측의 평균을 구하는 방식으로 작동하며, 서로 다른 모델들로 구성된 모델(앙상블)은 기반 모델의 성능을 높인다.
from sklearn.ensemble import RandomForestRegressor
forest_reg = make_pipeline(preprocessing, RandomForestRegressor(random_state=42))
forest_rmses = -cross_val_score(forest_reg, housing, housing_labels,
scoring='neg_root_mean_squared_error', cv=10)
pd.Series(tree_rmses).describe()
각 모델의 RMSE 점수를 비교해 본다.
forest_reg.fit(housing, housing_labels)
housing_predictions_forest = forest_reg.predict(housing)
forest_rmse = mean_squared_error(housing_labels, housing_predictions_forest,
squared=False)
tree_reg.fit(housing, housing_labels)
housing_predictions_tree = tree_reg.predict(housing)
tree_rmse = mean_squared_error(housing_labels, housing_predictions_tree,
squared=False)
lin_reg.fit(housing, housing_labels)
housing_predictions_lin = lin_reg.predict(housing)
lin_rmse = mean_squared_error(housing_labels, housing_predictions_lin,
squared=False)
# 각 모델의 RMSE 점수
print('forest_rmse:', forest_rmse)
print('tree_rmse:', tree_rmse)
print('lin_rmse:', lin_rmse)
▶ 랜덤 포레스트는 다른 모델에 비해 훨씬 좋으나, 여전히 과대적합되어 있으므로 여러 종류의 머신러닝 알고리즘에서 다양한 모델을 시도해보는 게 좋다.
모델 미세 튜닝
가능성 있는 모델을 추린 다음에 추려진 모델들을 미세 튜닝해야 한다.
[그리드 서치]
사이킷런의 GridSearchCV를 사용하여 만족할 만한 하이퍼파라미터 조합을 찾는데, 탐색하고자 하는 하이퍼파라미터와 시도해볼 값을 지정하면 교차 검증을 사용해 가능한 모든 하이퍼파라미터 조합을 평가한다.
RandomForestRegressor 에 대한 최적의 하이퍼파라미터 조합 탐색하기
from sklearn.model_selection import GridSearchCV
full_pipeline = Pipeline([
("preprocessing", preprocessing),
("random_forest", RandomForestRegressor(random_state=42)),
])
param_grid = [
{'preprocessing__geo__n_clusters': [5, 8, 10],
'random_forest__max_features': [4, 6, 8]},
{'preprocessing__geo__n_clusters': [10, 15],
'random_forest__max_features': [6, 8, 10]},
]
grid_search = GridSearchCV(full_pipeline, param_grid, cv=3,
scoring='neg_root_mean_squared_error')
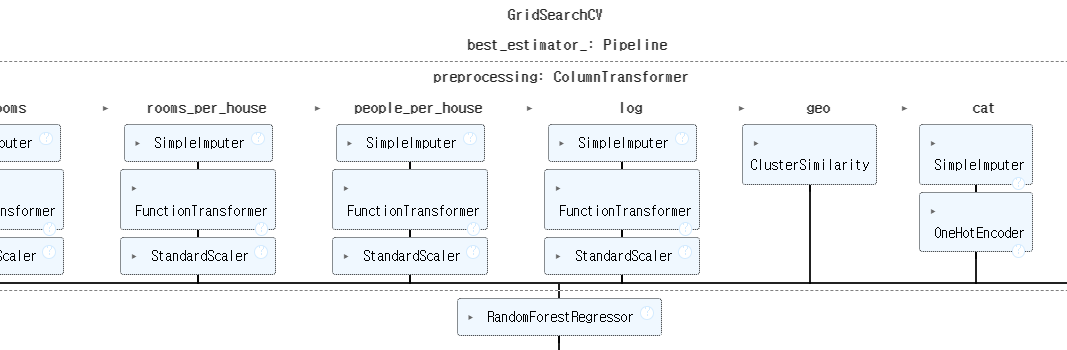
grid_search.fit(housing, housing_labels)- 'preprocessing__geo__n_clusters' 를 이중 밑줄 문자를 기준으로 나누고 파이프라인에서 'preprocessing' 이란 이름의 추정기를 찾으면 전처리 ColumnTransformer를 찾게 된다
- 그리고 ColumnTransformer 안에서 'geo' 란 이름의 변환기를 찾는데, 이 변환기는 위도와 경도에 사용하는 ClusterSimilarity 이다.
- 그 다음 변환기의 n_clusters 하이퍼 파라미터를 찾는다. random_forest__max_features는 'radom_forest'란 이름의 추정기에 있는 'max_features' 하이퍼 파라미터를 의미한다.
- param_grid에는 두 개의 딕셔너리가 있는데, 각 딕셔너리에 있는 하이퍼파라미터 값의 3*3=9개 조합, 2*3=6개 조합을 모두 평가한다 (총 15개 하이퍼파라미터 조합을 탐색한다)
- 3-폴드 교차 검증을 사용하므로 각 조합마다 3번씩 파이프라인을 훈련하며, 이는 총 15*3=45 번의 훈련이 일어난다는 것을 의미한다 (따라서 시간이 좀 걸린다)
최상의 하이퍼파라미터 조합 출력
grid_search.best_params_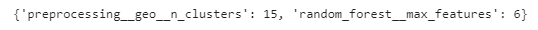
▶ n_clusters를 15, max_features를 6으로 지정하여 최상의 모델을 얻을 수 있다.
최상의 추정기 출력
grid_search.best_estimator_
평가 점수 얻기
cv_res = pd.DataFrame(grid_search.cv_results_)
cv_res.sort_values(by='mean_test_score', ascending=False, inplace=True)
# 열 이름을 바꾸고 점수를 음수로 바꿈
cv_res = cv_res[["param_preprocessing__geo__n_clusters",
"param_random_forest__max_features", "split0_test_score",
"split1_test_score", "split2_test_score", "mean_test_score"]]
score_cols = ["split0", "split1", "split2", "mean_test_rmse"]
cv_res.columns = ["n_clusters", "max_features"] + score_cols
cv_res[score_cols] = -cv_res[score_cols].round().astype(np.int64)
cv_res.head()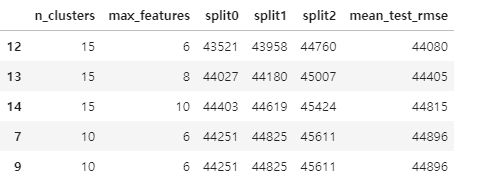
▶ 최상의 모델에 대한 평균 테스트 RMSE 점수는 44.080이다.
[랜덤 서치]
그리드 서치 방법은 비교적 적은 수의 조합을 탐구할 때 좋으나, 하이퍼파라미터 탐색 공간이 커지면 RandomizedSearchCV가 종종 선호된다. 이는 GridSearchCV와 달리 가능한 모든 조합을 시도하는 대신 각 반복마다 하이퍼파라미터에 임의의 수를 대입하여 지정한 횟수만큼 평가한다.
- 랜덤 서치의 주요 장점
- 하이퍼파라미터 값이 연속적이면 (또는 이산적이나 가능한 값이 많다면) 랜덤 서치를 1,000번 실행했을 때 각 하이퍼파라미터마다 1,000개의 다른 값을 탐색한다. 반면 그리드 서치는 하이퍼파라미터에 대해 나열한 몇 개의 값만을 탐색한다.
- 어떤 하이퍼파라미터가 성능 면에서 큰 차이를 만들지 못하지만 아직 이 사실을 모른다고 가정할 경우, 10개의 가능한 값이 있을 때 이를 그리드 서치에 추가하면 훈련이 10배 더 오래 걸리나 랜덤 서치에 추가하면 탐색 시간이 더 늘어나지 않는다
- 6개의 하이퍼파라미터에 대해 각각 10개의 값을 탐색한다면 그리드 서치는 백만 번 모델을 훈련해야 하나, 랜덤 서치는 지정한 반복 횟수만큼 실행할 수 있다
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {'preprocessing__geo__n_clusters': randint(low=3, high=50),
'random_forest__max_features': randint(low=2, high=20)}
rnd_search = RandomizedSearchCV(
full_pipeline, param_distributions=param_distribs, n_iter=10, cv=3,
scoring='neg_root_mean_squared_error', random_state=42)
rnd_search.fit(housing, housing_labels)
랜덤 서치의 결과도 출력해본다
cv_res = pd.DataFrame(rnd_search.cv_results_)
cv_res.sort_values(by="mean_test_score", ascending=False, inplace=True)
cv_res = cv_res[["param_preprocessing__geo__n_clusters",
"param_random_forest__max_features", "split0_test_score",
"split1_test_score", "split2_test_score", "mean_test_score"]]
cv_res.columns = ["n_clusters", "max_features"] + score_cols
cv_res[score_cols] = -cv_res[score_cols].round().astype(np.int64)
cv_res.head()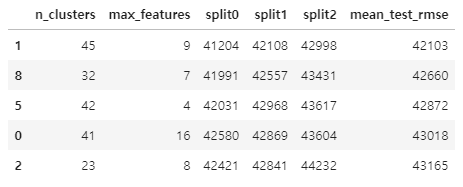
사이킷런은 HalvingRandomSearchCV와 HlvingGridSearchCV 하이퍼파라미터 탐색 클래스도 제공하는데, 빠르게 훈련하고 대규모 하이퍼파라미터 공간을 탐색하기 위해 계산 자원을 더 효율적으로 사용한다.
-작동 방식
- 첫 번째 반복에서 많은 하이퍼파라미터 조합이 그리드 서치나 랜덤 서치를 사용해 생성됨
- 후보들을 사용해 모델을 훈련하고 이전과 같은 방식으로 교차 검증 사용해 평가 (첫 번째 반복의 속도를 높이기 위해 제한된 자원으로 훈련하는데, 이는 훈련 세트의 작은 일부분에서 훈련함을 의미하며 다른 제한도 가능)
- 모든 후보를 평가한 후에 최상의 후보만 다음 단계로 넘어가 더 많은 자원 사용
- 몇 번의 반복이 진행된 후 최종 후보들이 전체 자원을 사용해 평가
<보너스 섹션: 하이퍼파라미터를 위한 샘플링 분포 선택 방법>
- 출처: ickiepark/handson-ml3 깃허브
- scipy.stats.randint(a, b+1): a~b 사이의 이산적인 값을 가진 하이퍼파라미터. 이 범위의 모든 값은 동일한 확률 가짐.
- scipy.stats.uniform(a, b): 매우 비슷하지만 연속적인 파라미터에 사용.
- scipy.stats.geom(1 / scale): 이산적인 값의 경우 주어진 스케일 안에서 샘플링하고 싶을 때 사용. 예를 들어 scale=1000인 경우 대부분의 샘플은 이 범주 안에 있지만 모든 샘플 중 10% 정도는 100보다 작고, 10% 정도는 2300보다 큼.
- scipy.stats.expon(scale): geom의 연속적인 버전. scale을 가장 많이 등장할 값으로 지정.
- scipy.stats.loguniform(a, b): 하이퍼파라미터 값의 스케일을 어떻게 지정할지 모를 때 사용. a=0.01, b=100으로 지정하면 0.01과 0.1 사이의 샘플링과 10과 100 사이의 샘플링 비율이 동일.
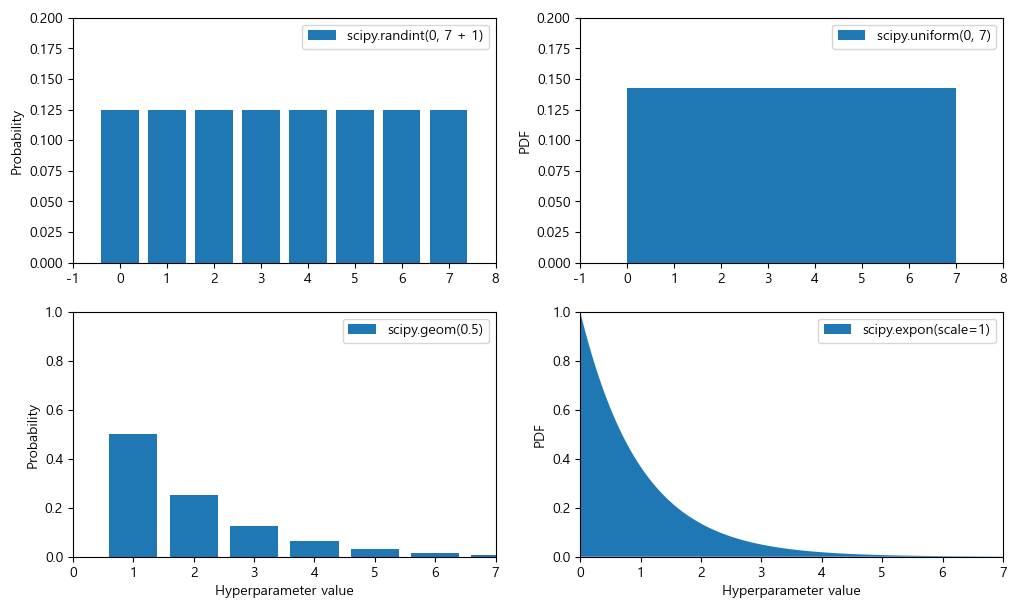
아래는 randint(), uniform(), geom(), expon()에 대한 확률 질량 함수(이산형 변수)와 확률 밀도 함수(연속형 변수)의 그래프이다:
# 추가 코드 – 랜덤 서치에서 사용할 수 있는 몇가지 분포에 대한 그래프
from scipy.stats import randint, uniform, geom, expon
xs1 = np.arange(0, 7 + 1)
randint_distrib = randint(0, 7 + 1).pmf(xs1)
xs2 = np.linspace(0, 7, 500)
uniform_distrib = uniform(0, 7).pdf(xs2)
xs3 = np.arange(0, 7 + 1)
geom_distrib = geom(0.5).pmf(xs3)
xs4 = np.linspace(0, 7, 500)
expon_distrib = expon(scale=1).pdf(xs4)
plt.figure(figsize=(12, 7))
plt.subplot(2, 2, 1)
plt.bar(xs1, randint_distrib, label="scipy.randint(0, 7 + 1)")
plt.ylabel("Probability")
plt.legend()
plt.axis([-1, 8, 0, 0.2])
plt.subplot(2, 2, 2)
plt.fill_between(xs2, uniform_distrib, label="scipy.uniform(0, 7)")
plt.ylabel("PDF")
plt.legend()
plt.axis([-1, 8, 0, 0.2])
plt.subplot(2, 2, 3)
plt.bar(xs3, geom_distrib, label="scipy.geom(0.5)")
plt.xlabel("Hyperparameter value")
plt.ylabel("Probability")
plt.legend()
plt.axis([0, 7, 0, 1])
plt.subplot(2, 2, 4)
plt.fill_between(xs4, expon_distrib, label="scipy.expon(scale=1)")
plt.xlabel("Hyperparameter value")
plt.ylabel("PDF")
plt.legend()
plt.axis([0, 7, 0, 1])
plt.show()
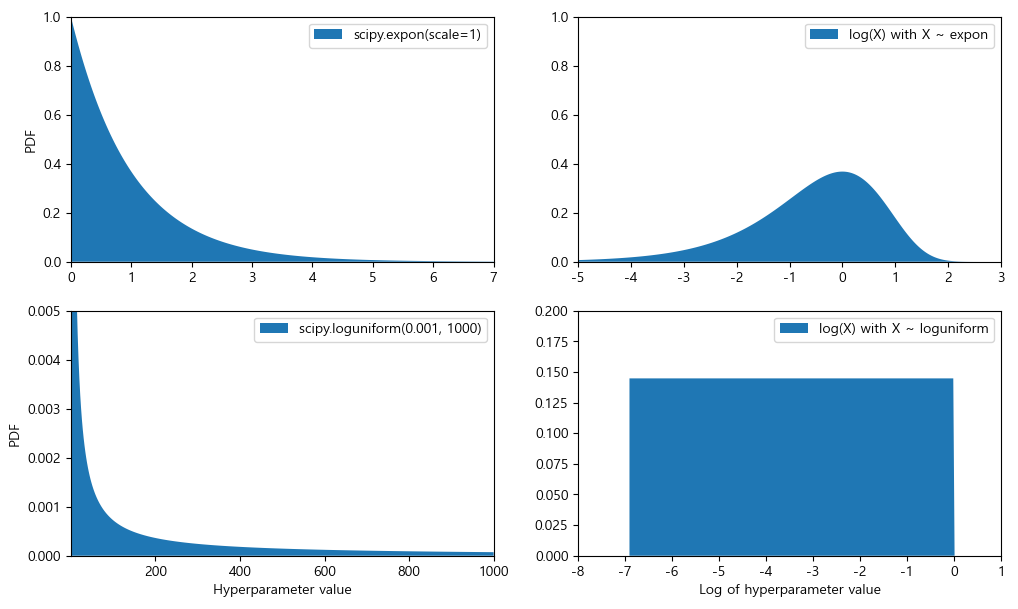
아래는 expon()와 loguniform()의 확률 밀도 함수(왼쪽 열), log(X)의 확률 밀도 함수(오른쪽 열)이이다. 오른쪽 열은 하이퍼파라미터 스케일의 분포를 보여준다. expon()는 대체적으로 원하는 스케일을 따라 하이퍼파라미터를 선택하고 작은 스케일 쪽으로는 긴 꼬리를 형성한다. 하지만 loguniform()는 스케일에 영향을 받지 않고 모두 동일한 확률을 가진다:
[앙상블 방법]
모델을 세밀하게 튜닝하는 또 다른 방법은 최상의 모델을 연결해보는 것이다. 모델의 그룹이 최상의 단일 모델보다 더 나은 성능을 발휘할 때가 많은데, 특히 개별 모델이 각기 다른 형태의 오차를 만들 때 더욱 그렇다.
앙상블 관련
[머신러닝] 분류 - 앙상블 학습(Ensemble Learning) 1
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.앙상블 학습(Ensemble Learning)
puppy-foot-it.tistory.com
[최상의 모델과 오차 분석]
최상의 모델을 분석하면 문제에 대한 좋은 인사이트를 얻는 경우가 많다.
final_model = rnd_search.best_estimator_ # 전처리 포함
# RandomForestRegressor의 각 특성의 상대적 중요도 보기
feature_importances = final_model['random_forest'].feature_importances_
feature_importances.round(2)
각 특성별 중요도 점수를 내림차순으로 정렬하고 특성 이름과 함께 표시해 본다
sorted(zip(feature_importances,
final_model['preprocessing'].get_feature_names_out()), reverse=True)
▶ 이 정보를 바탕으로 덜 중요한 특성들을 제외할 수 있다.
[테스트 세트로 시스템 평가하기]
테스트 세트의 특성과 레이블을 사용해 final_model을 실행하여 데이터를 변환하고 예측을 만든 뒤, 이 예측을 평가한다.
X_test = strat_test_set.drop('median_house_value', axis=1)
y_test = strat_test_set['median_house_value'].copy()
final_predictions = final_model.predict(X_test)
final_rmse = mean_squared_error(y_test, final_predictions, squared=False)
print(final_rmse)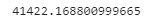
scipy.stats.t.interval()을 사용해 일반화 오차의 95% 신뢰 구간을 계산해 본다
from scipy import stats
confidence = 0.95
squared_errors = (final_predictions - y_test) ** 2
np.sqrt(stats.t.interval(confidence, len(squared_errors) -1,
loc=squared_errors.mean(),
scale=stats.sem(squared_errors)))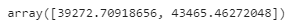
▶ 구간은 39,272와 43,465 사이로 꽤 크며 추정값인 41,422는 대략 중간에 해당한다.
하이퍼파라미터 튜닝을 많이 했다면 교차 검증을 사용해 측정한 것보다 성능이 조금 낮은 것이 보통인데, 이는 우리 시스템이 검증 데이터에서 좋은 성능을 내도록 세밀하게 튜닝되었기 때문에 새로운 데이터셋에는 잘 작동하지 않을 가능성이 크기 때문이다.
하지만 이런 경우가 생기더라도 테스트 세트에서 성능 수치를 좋게 하려고 하이퍼파라미터를 튜닝하려 시도해서는 안 된다.
모델 저장 및 로드
joblib 라이브러리를 사용하여 훈련된 최상의 모델을 저장하고 제품 환경으로 이 파일을 전달하여 로드한다.
# 모델 저장
import joblib
joblib.dump(final_model, 'my_california_housing_model.pkl')
# 모델 임포트
import joblib
# 필요한 클래스 임포트
from sklearn.cluster import KMeans
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.metrics.pairwise import rbf_kernel
# 모든 작업을 수행하는 파이프라인 만들기
def column_ratio(X):
return X[:, [0]] / X[:, [1]]
def ratio_name(function_transformer, feature_names_in):
return ['ratio'] # get_feature_names_out에 사용
def ratio_pipeline():
return make_pipeline(
SimpleImputer(strategy='median'),
FunctionTransformer(column_ratio, feature_names_out=ratio_name),
StandardScaler())
log_pipeline = make_pipeline(
SimpleImputer(strategy='median'),
FunctionTransformer(np.log, feature_names_out='one-to-one'),
StandardScaler())
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
default_num_pipeline = make_pipeline(SimpleImputer(strategy='median'),
StandardScaler())
preprocessing = ColumnTransformer([
('bedrooms', ratio_pipeline(), ['total_bedrooms', 'total_rooms']),
('rooms_per_house', ratio_pipeline(), ['total_rooms', 'households']),
('people_per_house', ratio_pipeline(), ['population', 'households']),
('log', log_pipeline, ['total_bedrooms', 'total_rooms', 'population',
'households', 'median_income']),
('geo', cluster_simil, ['latitude', 'longitude']),
('cat', cat_pipeline, make_column_selector(dtype_include=object)),
],
remainder=default_num_pipeline) # 남은 특성: housing_median_age
class ClusterSimilarity(BaseEstimator, TransformerMixin):
def __init__(self, n_clusters=10, gamma=1.0, random_state=None):
self.n_clusters = n_clusters
self.gamma = gamma
self.random_state = random_state
def fit(self, X, y=None, sample_weight=None):
self.kmeans_ = KMeans(self.n_clusters, random_state=self.random_state)
self.kmeans_.fit(X, sample_weight=sample_weight)
return self # 항상 self를 반환
def transform(self, X):
return rbf_kernel(X, self.kmeans_.cluster_centers_, gamma=self.gamma)
def get_feature_names_out(self, names=None):
return [f'클러스터 {i} 유사도' for i in range(self.n_clusters)]
final_model_reloaded = joblib.load("my_california_housing_model.pkl")
new_data = housing.iloc[:5] # 예측을 만드려는 새로운 구역
predictions = final_model_reloaded.predict(new_data)다음 내용
[머신러닝] 모델 훈련 - 1
머신러닝 모델 훈련 머신러닝 모델이 어떻게 작동하는지 잘 이해하고 있으면 적절한 모델, 올바른 훈련 알고리즘, 작업에 맞는 좋은 하이퍼 파라미터를 빠르게 찾을 수 있다. 또한 디버깅이나
puppy-foot-it.tistory.com
[출처]
핸즈온 머신러닝
https://github.com/rickiepark/handson-ml3/blob/main/02_end_to_end_machine_learning_project.ipynb
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 분류: MNIST 데이터셋 실습 - 2 (0) | 2024.11.09 |
|---|---|
| [머신러닝] 분류: MNIST 데이터셋 실습 - 1 (0) | 2024.11.09 |
| [머신러닝] 캘리포니아 주택 가격 프로젝트-2 (0) | 2024.11.08 |
| [머신러닝] 데이터셋을 구하기 좋은 사이트 모음 (1) | 2024.11.08 |
| [머신러닝] 캘리포니아 주택 가격 프로젝트-1 (4) | 2024.11.07 |



