분류란?
[머신러닝] 분류와 분류 관련 머신러닝 알고리즘
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 분류(Classification) 지도학습
puppy-foot-it.tistory.com
이전 내용
[머신러닝] 분류: MNIST 데이터셋 실습 - 1
분류란? [머신러닝] 분류와 분류 관련 머신러닝 알고리즘시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적
puppy-foot-it.tistory.com
다중 분류
이진 분류기는 두 개의 클래스를 구별하는 반면 다중 분류기는 둘 이상의 클래스를 구별할 수 있다.
- LogisticRegression, RandomForestClassifier, GaussianNB 등: 여러 개의 클래스 처리 가능
- SGDClassifier, SVC 등: 이진 분류만 가능
- 이진 분류기를 여러 개 사용해 다중 클래스를 분류하는 기법도 있음
OvR 또는 OvA: 이미지를 분류할 때 각 분류기의 결정 점수 중에서 가장 높은 것을 클래스로 선택
- OvR: One versus the rest
- OvA: One versus all
OvO(One versus one): 각 숫자의 조합마다 이진 분류기를 훈련 시키는 방법. 클래스가 N개라면 분류기는 N*(N-1)/2 개 필요
다중 클래스 분류 작업에 이진 분류 알고리즘을 선택하면 사이킷런이 알고리즘에 따라 자동으로 OvR 또는 OvO를 실행한다.
sklearn.svm.SVD 클래스를 사용해 서포트 벡터 머신 분류기를 테스트 해보는데, 처음 2000개의 이미지만 사용해 훈련해 본다.
from sklearn.svm import SVC
svm_clf = SVC(random_state=42)
svm_clf.fit(X_train[:200], y_train[:200])
한 이미지에 대한 예측을 만들어본다
svm_clf.predict([some_digit])
decision_function() 메서드를 호출하면 샘플마다 총 10개의 점수(클래스마다 하나씩)를 반환하는 것을 볼 수 있는데, 각 클래스는 동률 문제를 해결하기 위해 분류기 점수를 기반으로 각 쌍에서 이긴 횟수에 약간의 조정 값을 더하거나 뺀 점수를 얻는다.
some_digit_scores = svm_clf.decision_function([some_digit])
print('점수 반환:', some_digit_scores.round(2))
print('가장 높은 점수:', round(some_digit_scores.max(), 2))
class_id = some_digit_scores.argmax()
print('가장 높은 점수의 클래스:', class_id)
분류기가 훈련될 때 classes_ 속성에 타깃 클래스의 리스트를 값으로 정렬하여 저장하는데, MNIST의 경우 classes_ 배열에 있는 각 클래스의 인덱스가 클래스이 값 자체와 같다 (인덱스 5 = 클래스 5) 그러나, 이런 경우는 드물기 때문에 클래스 레이블을 확인해 봐야 한다.
print('클래스 레이블 확인:\n',svm_clf.classes_)
print('class5의 레이블:', svm_clf.classes_[class_id])
사이킷런에서 OvR이나 OvO를 사용하도록 강제하려면 OneVsRestClassifier 나 OneVsOneClassifier를 사용하여 간단하게 이진 분류기 인스턴스를 만들어 객체를 생성할 때 전달하면 된다.
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC(random_state=42))
ovr_clf.fit(X_train[:2000], y_train[:2000])
# 훈련된 분류기 개수 확인
print(ovr_clf.predict([some_digit]))
print('훈련된 분류기 개수:', len(ovr_clf.estimators_))
다중 분류 데이터셋에서 SGDClassifier를 훈련하고 예측을 만드는 것도 간단하다
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train)
sgd_clf.predict([some_digit])▶ 예측 오류가 발생하였다.
decision_function() 메서드를 통해 SGD 분류기가 각 클래스에 부여한 점수를 확인해 본다
sgd_clf.decision_function([some_digit]).round()▶ 대부분의 점수가 큰 음수이나, 클래스 3만 유일하게 +1824 이며 클래스 5도 -1386으로 다른 수에 비해 값이 작다
cross_val_score() 함수를 사용해 이 모델을 평가해본다
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring='accuracy')▶ 모든 테스트 폴드에서 85% 이상의 정확도를 얻었는데, 이 성능을 더 높이기 위해서는 입력의 스케일을 조정하는 등의 전처리 작업을 진행해주면 정확도를 더 높일 수 있다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype('float64'))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring='accuracy')▶ 정확도가 89.1% 이상으로 향상되었다.
오류 분석
가능성이 높은 모델을 하나 찾았다고 가정하고 이 모델의 성능을 향상시킬 방법을 찾기 위한 방법 중 하나로 오류의 종류를 분석해본다.
먼저 오차 행렬을 살펴보기 위해 cross_val_score() 함수를 사용해 예측을 만들고 confusion_matrix() 함수를 호출하면서 이 함수에 레이블과 예측을 전달한다. 그러나 클래스가 10개라서 오차 행렬에 상당히 많은 숫자가 포함되므로 가독성을 높이기 위해 컬러 그래프로 나타내어 분석해본다.
오차 행렬을 그래프로 그리려면 ConfusionMatrixDisplay.from_predictions() 함수를 사용하면 된다.
from sklearn.metrics import ConfusionMatrixDisplay
y_train_pred = cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3)
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred)
plt.show()
5번 행과 5 열의 대각선에 있는 셀은 다른 숫자보다 약간 더 어두워 보이는데, 이는 모델이 5에서 더 많은 오류를 범했거나 데이터 집합에 다른 숫자보다 5가 적기 때문일 것이다. 따라서 각 값을 해당 클래스의 총 이미지수로 나누어 (행의 합) 오차 행렬을 정규화하는 것이 중요한데, normalize='True'로 지정하면 이 작업을 간단히 수행할 수 있다.
또한 values_format='.0%' 매개변수를 지정하여 소수점 없이 백분율을 표시할 수도 있다.
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,
normailze='true', values_format='.0%')
plt.show()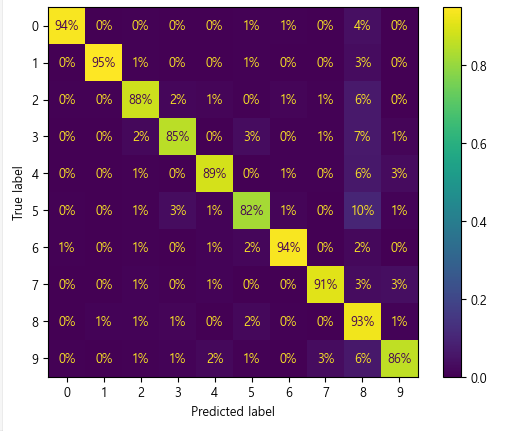
▶ 정규화작업과 표현 형식을 간결화를 통해 가독성을 높여서 이제 5 이미지의 82%만이 올바르게 분류되었다는 것을 알 수 있다.
오류를 더 눈에 띄게 만들고 싶다면 올바른 예측에 대한 가중치를 0으로 설정하면 분류기가 어떤 종류의 오류를 범하는지 훨씬 더 명확하게 확인할 수 있다
sample_weight = (y_train_pred != y_train)
plt.rc('font', size=10) # 폰크 크기 조정
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,
sample_weight=sample_weight,
normalize="true", values_format=".0%")
plt.show()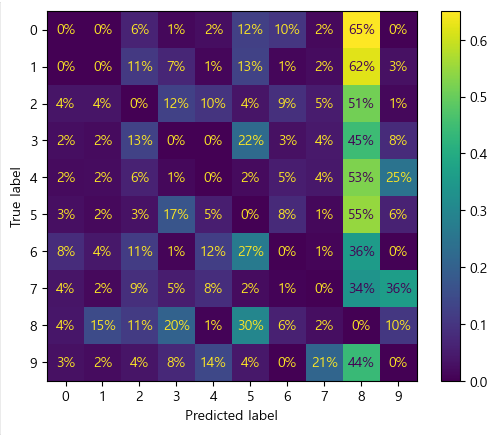
▶ 클래스 8의 열이 매우 밝아진 것으로 보아 많은 이미지가 8로 잘못 분류되었음을 알 수 있다.
오차 행렬을 행 단위가 아닌 열 단위로 정규화할 수도 있는데, normalize='pred' 로 지정하면 된다.
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(9, 4))
plt.rc('font', size=10)
# 행 기준
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred, ax=axs[0],
sample_weight=sample_weight,
normalize="true", values_format=".0%")
axs[0].set_title("행별로 정규화된 오차 행렬")
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred, ax=axs[1],
sample_weight=sample_weight,
normalize="pred", values_format=".0%")
axs[1].set_title("열별로 정규화된 오차 행렬")
plt.show()
plt.rc('font', size=14)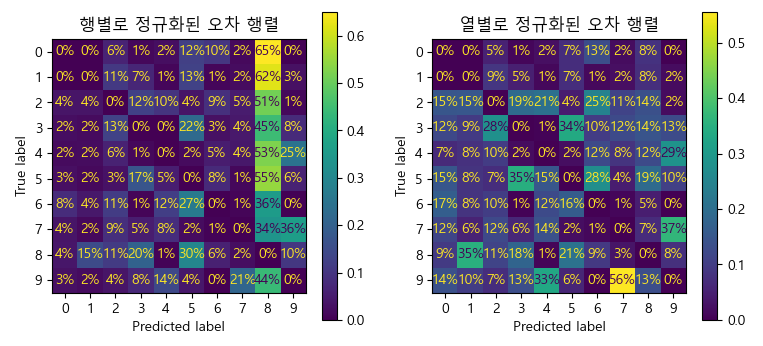
▶
* 행별로 정규화된 오차 행렬
7번 행, 9번 열의 36%는 모든 7 이미지 중 36%가 9로 잘못 분류되었다는 뜻이 아니라,
모델이 7 이미지에서 발생한 오류 중 36%가 9로 잘못 분류되었다는 의미이다.
* 열별로 정규화된 오차 행렬
잘못 분류된 7의 56%가 실제로는 9였다는 의미이다.
각각의 오류를 분석해보면 분류기가 무슨 일을 하는지, 왜 잘못되었는지 인사이트를 얻을 수 있다.
예를 들어 오차 행렬 스타일로 3과 5의 샘플을 그려보면 분류기가 잘못 분류한 숫자의 일부는 정말 잘못 쓰여 있어서 사람도 분류하기 어려울 것으로 보인다. 그러나 대부분의 잘못 분류된 이미지는 확실한 오류로 보이며 분류기가 실해한 이유를 이해하기 어렵다.
cl_a, cl_b = '3', '5'
X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)]
X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)]
X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)]
X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)]size = 5
pad = 0.2
plt.figure(figsize=(size, size))
for images, (label_col, label_row) in [(X_ba, (0, 0)), (X_bb, (1, 0)),
(X_aa, (0, 1)), (X_ab, (1, 1))]:
for idx, image_data in enumerate(images[:size*size]):
x = idx % size + label_col * (size + pad)
y = idx // size + label_row * (size + pad)
plt.imshow(image_data.reshape(28, 28), cmap="binary",
extent=(x, x + 1, y, y + 1))
plt.xticks([size / 2, size + pad + size / 2], [str(cl_a), str(cl_b)])
plt.yticks([size / 2, size + pad + size / 2], [str(cl_b), str(cl_a)])
plt.plot([size + pad / 2, size + pad / 2], [0, 2 * size + pad], "k:")
plt.plot([0, 2 * size + pad], [size + pad / 2, size + pad / 2], "k:")
plt.axis([0, 2 * size + pad, 0, 2 * size + pad])
plt.xlabel("Predicted label")
plt.ylabel("True label")
plt.show()
3과 5의 오류를 줄이는 방법은 이미지를 중앙에 위치시키고 회전되어 있지 않도록 전처리하는 것이나, 각 이미지에 대해 정확한 회전을 예측해야 하므로 쉽지 않을 수 있다. 이보다 훨씬 간단한 접근 방식은 훈련 이미지를 약간 이동시키거나 회전된 변형 이미지로 훈련 집합을 보강하는 것(데이터 증식)이며, 이렇게 하면 모델이 이러한 변형에 더 잘 견디도록 학습하게 된다.
다중 레이블 분류
◆ 다중 레이블 분류 시스템: 여러 개의 이진 꼬리표를 출력하는 분류 시스템
각 숫자 이미지에 두 개의 타깃 레이블이 담긴 y_multi_label 배열을 만들고 첫 번째는 숫자가 큰 값(7, 8, 9)인지 나타내고
두 번째는 홀수 여부를 나타낸다.
그다음 KNeighborsClassifier 인스턴스를 만들고 다중 타깃 배열을 사용하여 훈련시키고 예측을 만든다.
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= '7')
y_train_odd = (y_train.astype('int8') % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
# 예측을 만들면 레이블 두 개 출력
knn_clf.predict([some_digit])
▶ 숫자 5는 크지 않고, 홀수라는 올바른 결과가 나온다.
다중 레이블을 평가하는 방법은 많은데 그 중 하나는 각 레이블의 F1-Score를 구하고 간단하게 평균 점수를 계산하는 것이다.
y_train_knn_pred = cross_val_score(knn_clf, X_train, y_multilabel, cv=3)
f1_score(y_multilabel, y_train_knn_pred, average='macro')
만약 얼굴 인식 시스템 등을 만든다고 할 때 특정 사진이 다른 사진에 비해 많다면 특정 사진에 대한 분류기의 점수에 더 높은 가중치를 둘 것이기 때문에 레이블에 클래스의 지지도를 가중치로 준다.
f1_score(y_multilabel, y_train_knn_pred, average="weighted")
SVC와 같이 기본적으로 다중 레이블 분류를 지원하지 않는 분류기를 사용하는 경우에는 레이블당 하나의 모델을 학습시키는 전략을 사용할 수 있지만 레이블 간의 의존성을 포착하기 어렵게 할 수 있다.
(예. 큰 숫자는 짝수보다 홀수일 가능성이 두 배 더 높지만 홀수 레이블에 대한 분류기는 큰 값 레이블로 분류기가 무엇을 예측했는지 알 수 없음.)
이 문제를 해결하기 위해 모델을 체인으로 구성할 수 있으며 사이킷런에는 이 작업을 수행하는 ClassifierChain 클래스가 있다.
이는 한 모델이 예측을 할 때 입력 특성과 체인 앞에 있는 모델의 모든 예측을 사용한다.
from sklearn.multioutput import ClassifierChain
chain_clf = ClassifierChain(SVC(), cv=3, random_state=42)
# 속도를 높이기 위해 훈련 세트에서 처음 2000개 이미지만 사용
chain_clf.fit(X_train[:2000], y_multilabel[:2000])
# ClassifierChain을 통한 예측 수행
chain_clf.predict([some_digit])
다중 출력 분류
◆ 다중 출력 분류(다중 출력 다중 클래스 분류):
다중 레이블 분류에서 한 레이블이 다중 클래스가 될 수 있도록 일반화하여 값을 두개 이상 가질 수 있도록 한 것.
이미지에서 잡음을 제거하는 시스템 만들기
이 시스템은 잡음이 많은 숫자 이미지를 입력으로 받아 깨끗한 숫자 이미지를 MNIST 이미지처럼 픽셀의 강도를 담은 배열로 출력하는데, 분류기의 출력 다중 레이블이고 각 레이블은 값을 여러 개 가진다 (0~255)
먼저 MNIST 이미지에서 추출한 훈련 세트와 테스트 세트에 넘파이의 randint() 함수를 사용하여 픽셀 강도에 잡음을 추가한다.
np.random.seed(42) # 동일하게 재현되도록 하기 위해 지정
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
# 분류기를 훈련시켜 잡음이 섞인 이미지를 깨끗하게 만들기
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[0]])
plot_digit(clean_digit)
plt.show()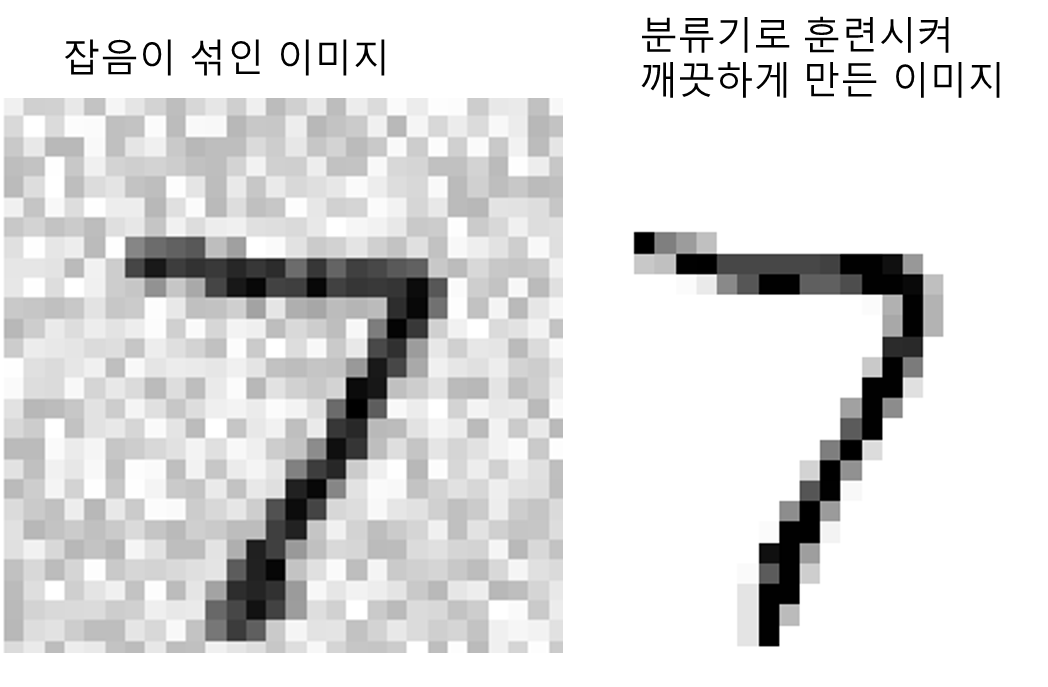
다음 내용
[머신러닝] 모델 훈련
머신러닝 모델 훈련 머신러닝 모델이 어떻게 작동하는지 잘 이해하고 있으면 적절한 모델, 올바른 훈련 알고리즘, 작업에 맞는 좋은 하이퍼 파라미터를 빠르게 찾을 수 있다. 또한 디버깅이나
puppy-foot-it.tistory.com
[출처]
핸즈온 머신러닝
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 모델 훈련 - 2 (3) | 2024.11.13 |
|---|---|
| [머신러닝] 모델 훈련 - 1 (6) | 2024.11.09 |
| [머신러닝] 분류: MNIST 데이터셋 실습 - 1 (0) | 2024.11.09 |
| [머신러닝] 캘리포니아 주택 가격 프로젝트-3 (0) | 2024.11.08 |
| [머신러닝] 캘리포니아 주택 가격 프로젝트-2 (0) | 2024.11.08 |



