시작에 앞서
해당 내용은 <파이썬으로 데이터 주무르기> -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.
보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.
기존 작업 내용
[파이썬] 주유소 가격 비교하기 - 1
시작에 앞서 해당 내용은 -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다. 보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다. 서울시 구별 주유소 가격 정보 얻기 먼저 sele
puppy-foot-it.tistory.com
구별 주유소 가격에 대한 데이터 정리 (feat. glob 모듈)
기존 작업에서 다운 받은 25개의 엑셀 파일을 작업 폴더에 옮기고 불러와야 하는데,
이때 25개의 파일을 read하는 명령으로 읽으면 25줄을 입력해야 하지만 이를 효율적으로 작업해줄 좋은 모듈이 있다.
먼저, pandas와 glob 라고 하는 파일 경로 등을 쉽게 접근할 수 있게 해주는 모듈을 import
[사용법]
glob.('참조하길 원하는 폴더의 경로/*.확장자')
glob('../data/지역*.xls')
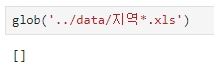
하지만 데이터 리스트가 안 보인다.
명령어가 잘못된 것인지 상위 폴더를 검색해보니 잘 나온다.
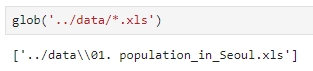
glob('../data/지역/*.xls')지역과 * 사이에 / 하나를 넣어주니 잘 나온다. (교재 상의 오타인듯 싶다)

station_files 변수에 리스트 저장하기
station_files 변수에 각 엑셀 파일의 경로와 이름을 리스트로 저장
station_files = glob('../data/지역/*.xls')
station_files

반복문으로 25개의 엑셀 파일을 하나로 합치기
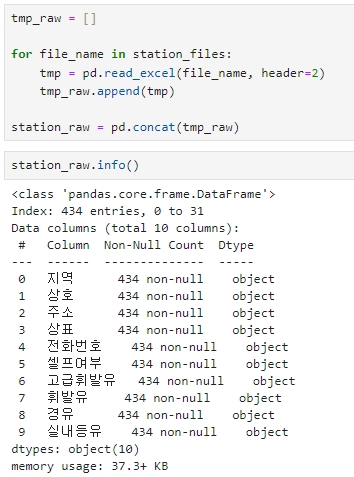
read_excel 로 각 파일을 반복문을 이용하여 읽은 후, tml_raw 변수에 append 시키고, concat 명령으로 하나로 합친다.
tmp_raw = []
for file_name in station_files:
tmp = pd.read_excel(file_name, header=2)
tmp_raw.append(tmp)
station_raw = pd.concat(tmp_raw)1) 위 코드는 여러 개의 엑셀 파일을 읽어와서 각각의 데이터를 임시 리스트인 tmp_raw에 저장하고,
이를 모두 합쳐서 하나의 데이터프레임인 station_raw에 저장하는 과정을 수행.
2) station_files에 있는 각 파일의 이름을 반복하여 엑셀 파일을 읽어와서 데이터를 임시로 tmp에 저장
3) 각 엑셀 파일에서 헤더(열 이름)는 세 번째 행부터 시작하므로 header=2로 설정
4) 읽어온 데이터를 tmp_raw 리스트에 추가
5) 마지막으로 pd.concat() 함수를 사용하여 tmp_raw 리스트에 있는 모든 데이터프레임을 합쳐서 station_raw 데이터프레임으로 만듦.
그리고 저장해보면, 총 434개의 주유소 정보가 저장된 것을 확인할 수 있다.
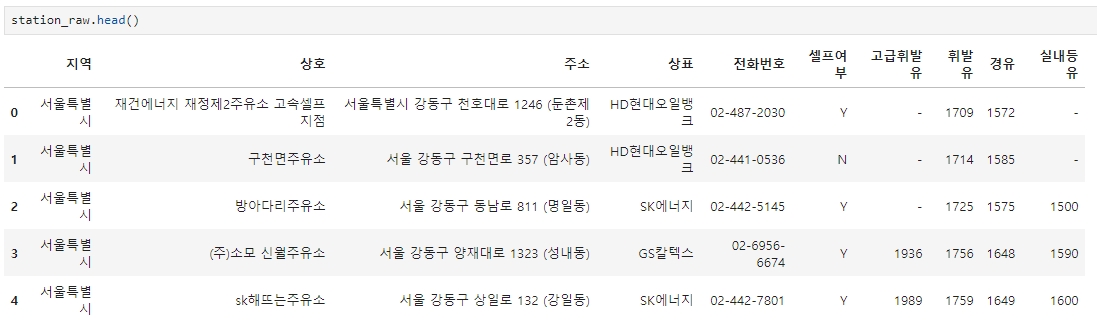
원하는 컬럼만 가져와서 이름 변경하기
station = pd.DataFrame({'Oil_store':station_raw['상호'], # 표를 만들고, station 이라는 변수로 지정/ 상호 컬럼은 Oil_store로
'주소':station_raw['주소'], #주소 컬럼명은 주소로
'가격':station_raw['휘발유'], #휘발유 컬럼명은 가격으로
'셀프':station_raw['셀프여부'], #셀프여부 컬럼명은 셀프로
'상표':station_raw['상표']}) #상표 컬럼명은 상표로
station.head()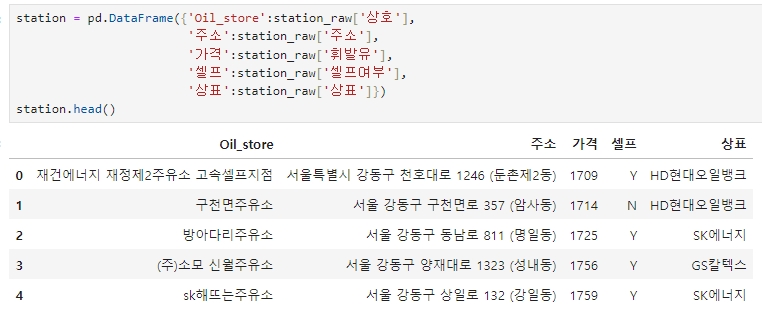
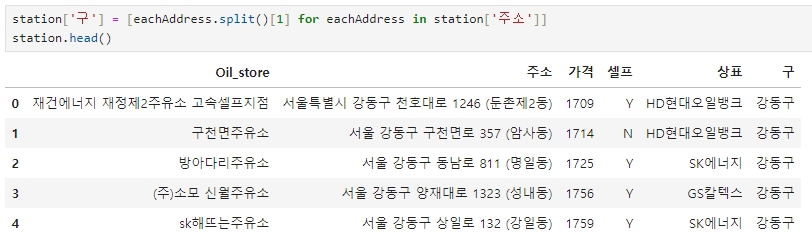
추가로 주소에서 구 이름만 추출하여 구별 가격도 조사
station['구'] = [eachAddress.split()[1] for eachAddress in station['주소']]
station.head()
300여 개의 데이터를 일일이 보기는 어려우므로, unique() 를 수행하여 구 데이터가 잘 나왔는지 확인

※ 만약 문제가 있을 경우에는 해당 데이터를 조회하고 (조회하는 법은 하단 이미지 참고)
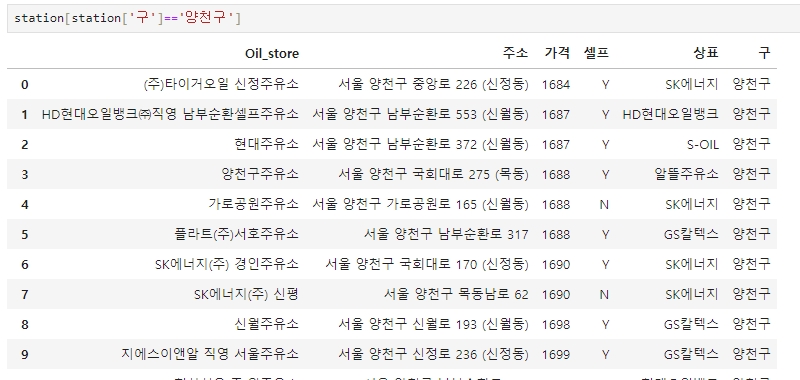
직접 변경해주면 됨.
station.loc[station['구']=='잘못된데이터', '구'] = '바꾸고자하는데이터'
station.unique()
#교재 상에선 잘못된 데이터는 '서울특별시', 바꾸고자하는 데이터는 '성동구'
가격 컬럼 데이터 조회하기
station[station['가격']=='-']가격이 기록되지 않은 경우 '-' 으로 처리되어 있는 것을 확인할 수 있는데,

이를 대상에서 제외시킴
station = station[station['가격'] !='-']
그리고나서 가격 정보를 숫자형으로 변환 시킨다
station['가격'] = [float(value) for value in station['가격']]
reset_index 명령으로 인덱스 기록
25개의 엑셀을 합쳤기 때문에 index가 중복될 수 있으니 reset_index 명령으로 인덱스를 처음부터 다시 기록
이때 index 라는 컬럼이 하나 더 생상되는데, 이 부분도 제거
station.reset_index(inplace=True)
del station['index']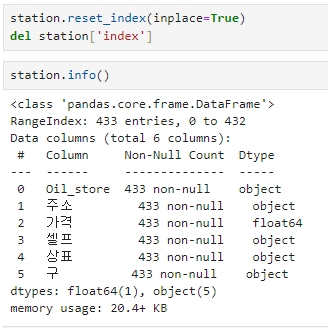
boxplot 으로 셀프 주유소 가격이 정말 저렴한지 확인하기
먼저 한글 문제를 해결하는 코드 준비 (운영체제 윈도우)
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import platform
path = "c:/Windows/Fonts/malgun.ttf"
from matplotlib import font_manager, rc
if platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Sorry')
boxplot 만들기
station.boxplot(column='가격', by='셀프', figsize=(12,8));
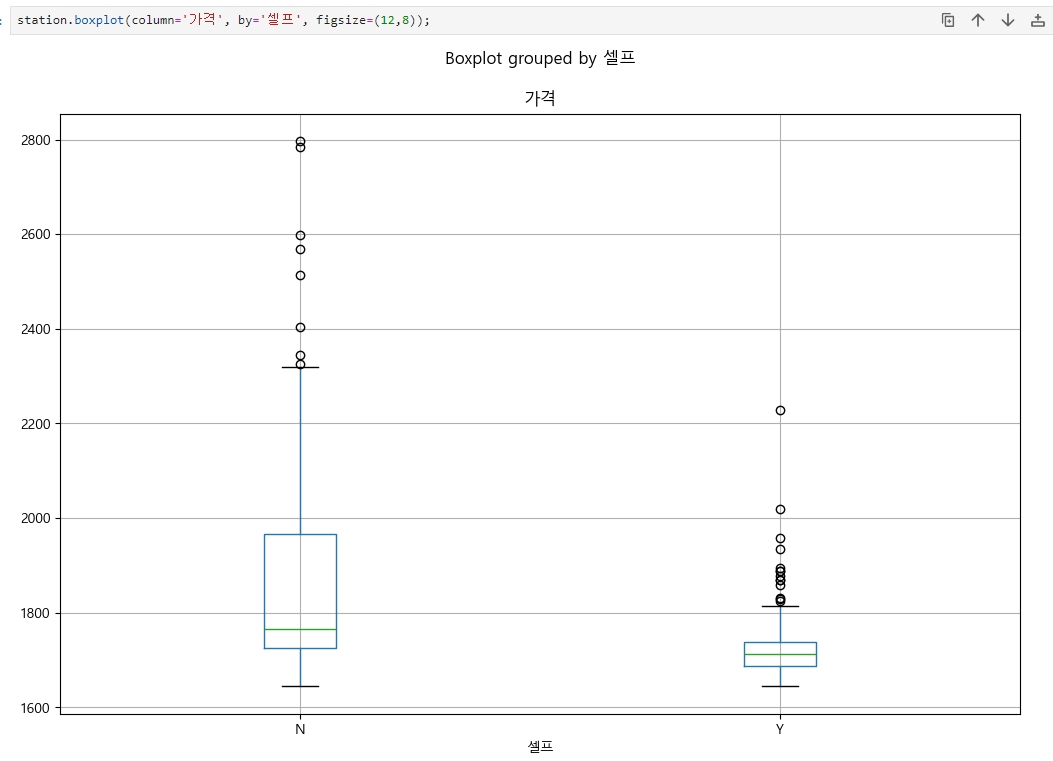
▶ 일반적으로 셀프 주유소 (Y) 의 가격이 아닌(N) 주유소보다 낮게 되어 있음을 알 수 있다.
주유소 상표별로 셀프 주유소 가격 확인하기
plt.figure(figsize=(12,8))
sns.boxplot(x="상표", y="가격", hue="셀프", data=station, palette="Set3")
plt.show()위 코드는
1) seaborn 라이브러리를 사용하여 가격 데이터를 상표와 셀프 주유소 여부에 따라 상자 그림(box plot)으로 시각화
2) plt.figure(figsize=(12,8))는 그림의 크기를 설정하는 코드입니다. 크기는 가로 12인치, 세로 8인치로 설정
3) sns.boxplot() 함수는 상자 그림을 그리는 함수이며, x="상표"는 x축에 상표(주유소 브랜드)를, y="가격"은 y축에 가격을, hue="셀프"는 주유소가 셀프 주유소인지 여부에 따라 다른 색상으로 구분하여 표시
4) data=station은 시각화할 데이터프레임을 지정하는 것으로, station 데이터프레임에서 데이터를 가져와 시각화
5) palette="Set3"는 색상 팔레트를 설정하는 것으로, 'Set3' 팔레트를 사용하여 다양한 색상으로 구분
6) plt.show()는 그림을 화면에 출력하는 함수
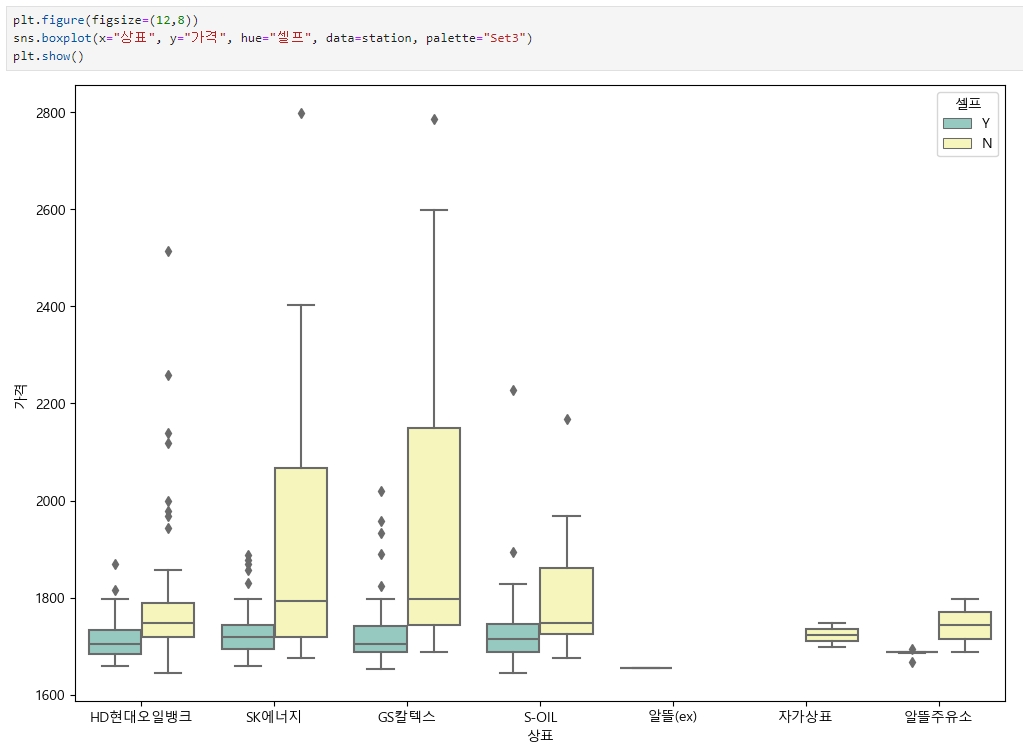
▶ 현대오일뱅크, SK에너지, GS칼텍스, S-OIL 모두 셀프주유소가 저렴하며, GS 칼텍스가 가장 가격대가 높게 형성되어 있음
Swarmplot 으로 더 자세히 보기
plt.figure(figsize=(12,8))
sns.boxplot(x="상표", y="가격", data=station, palette="Set3")
sns.swarmplot(x="상표", y="가격", data=station, color=".6")
plt.show() 위 코드는
|
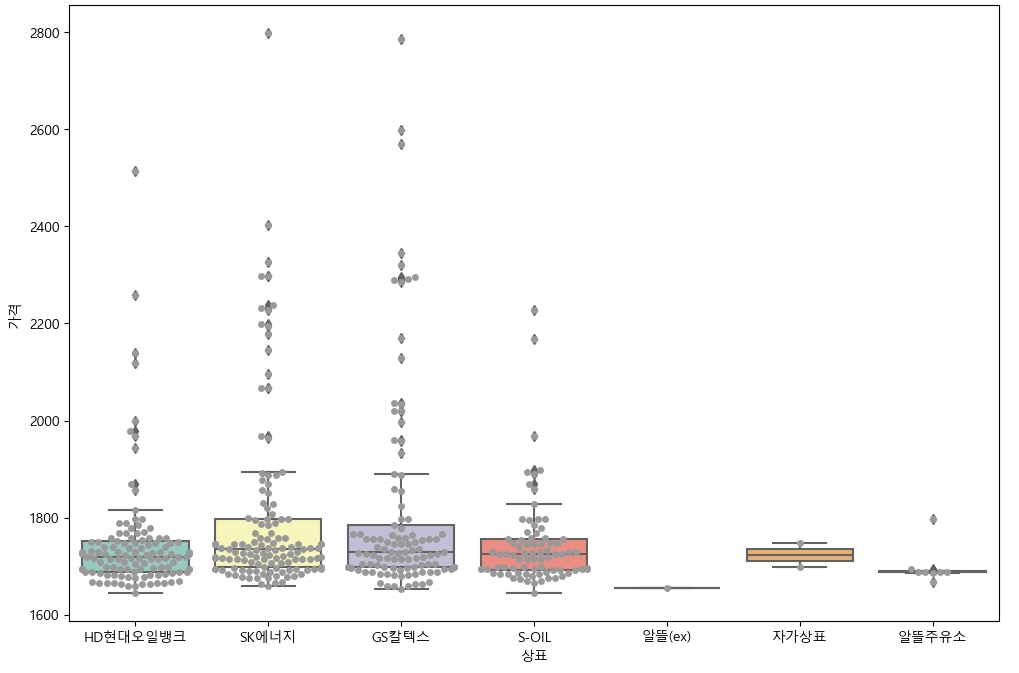
▶ 상표별로 확인해본 결과, 4대 주유소 중에 현대오일뱅크가 가장 저렴하다는 것을 확인할 수 있다
다음글
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 주유소 가격 비교하기 - 4 (0) | 2024.04.29 |
|---|---|
| [파이썬] 주유소 가격 비교하기 - 3 (0) | 2024.04.29 |
| [파이썬] 주유소 가격 비교하기 - 1 (0) | 2024.04.20 |
| [파이썬] 시카고 맛집 분석-3 (2) | 2024.04.18 |
| [파이썬] 시카고 맛집 분석-2 (1) | 2024.04.17 |



