시작에 앞서
해당 내용은 <파이썬으로 데이터 주무르기> -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.
보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.
이전 시간 분석
[파이썬] 우리나라 인구 소멸 위기 지역 분석 - 1
시작에 앞서해당 내용은 -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.<span style="font-fam..
puppy-foot-it.tistory.com
지도 시각화를 위해 지역별 고유 ID 만들기
먼저 하단의 json 파일 다운로드
고유 ID 확보를 위해 pop['시도']에 대해 unique 조사
pop['시도'].unique()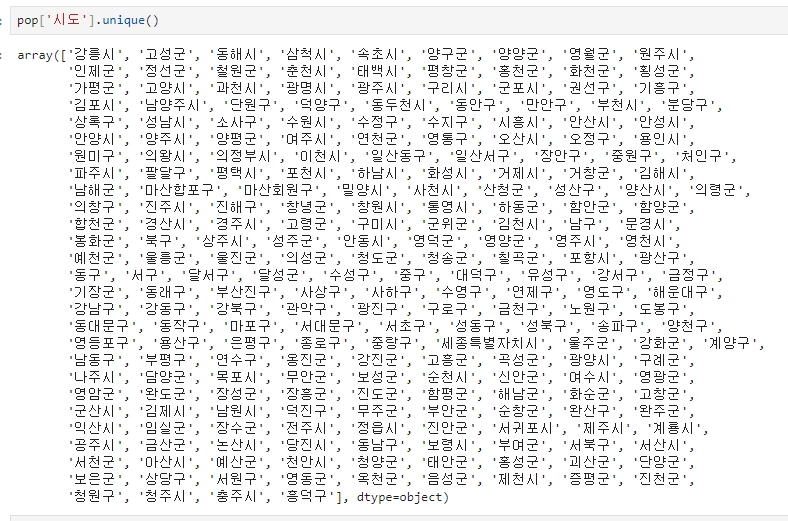
고유 아이디를 '광역시도'의 값과 '시도'의 값으로 합침 (ex. 서울 강남)
구 이름이 두 글자인 경우에는 구 이름 표시 (ex. 서울 중구)
일반 자치시의 경우 '도+시'로 표시 (ex. 충북 제천)
* 행정구의 경우는 '시+구'가 되지 않고, '도+구" 가 되기 때문에 (ex. 경기도 안양시 동안구 > 경기도 동안구)
먼저 광역시가 아니면서 구를 가지고 있는 시와 그 행정구를 파이썬의 dict 형으로 선언
si_name = [None] * len(pop)
tmp_gu_dict = {'수원':['장안구', '권선구', '팔달구', '영통구'],
'성남':['수정구', '중원구', '분당구'],
'안양':['만안구', '동안구'],
'안산':['상록구', '단원구'],
'고양':['덕양구', '일산동구', '일산서구'],
'용인':['처인구', '기흥구', '수지구'],
'청주':['상당구', '서원구', '흥덕구', '청원구'],
'천안':['동남구', '서북구'],
'전주':['완산구', '덕진구'],
'포항':['남구', '북구'],
'창원':['의창구', '성산구', '진해구', '마산합포구', '마산회원구'],
'부천':['오정구', '원미구','소사구']}
[고유 ID 만드는 절차]
1) 광역시도에 있는 이름의 끝 세글자가 '광역시', '특별시', '자치시'로 끝나지 않으면 일반 시 군으로 보고
2) 강원도와 경상남도에 있는 중복되는 '고성군' 처리
3) 일반 시인데 구를 가지는 구역 처리
4) 세종특별자치시 '세종'으로 처리
5) 나머지는 광역시도에서 앞 두 글자와 시도에서 두 글자인 경우 모두, 아니면 앞 두 글자만 선택
for n in pop.index:
if pop['광역시도'][n][-3:] not in ['광역시', '특별시', '자치시']:
if pop['시도'][n][:-1]=='고성' and pop['광역시도'][n]=='강원도':
si_name[n] = '고성(강원)'
elif pop['시도'][n][:-1]=='고성' and pop['광역시도'][n]=='경상남도':
si_name[n] = '고성(경남)'
else:
si_name[n] = pop['시도'][n][:-1]
for keys, values in tmp_gu_dict.items():
if pop['시도'][n] in values:
if len(pop['시도'][n])==2:
si_name[n] = keys + ' ' + pop['시도'][n]
elif pop['시도'][n] in ['마산합포구', '마산회원구']:
si_name[n] = keys + ' ' + pop['시도'][n][2:-1]
else: si_name[n] = keys + ' ' + pop['시도'][n][:-1]
elif pop['광역시도'][n] == '세종특별자치시':
si_name[n] = '세종'
else:
if len(pop['시도'][n])==2:
si_name[n] = pop['광역시도'][n][:2] + ' ' + pop['시도'][n]
else:
si_name[n] = pop['광역시도'][n][:2] + ' ' + pop['시도'][n][:-1]
그리고 이를 조회하면
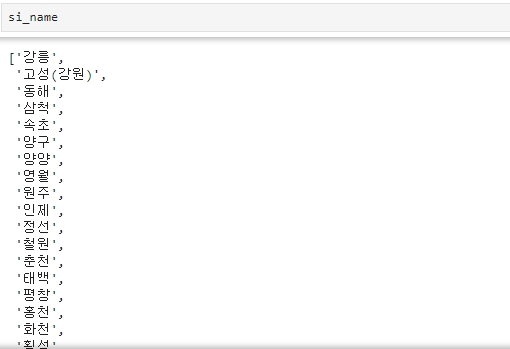
결과를 pop에 포함 시키고
pop['ID'] = si_name
큰 의미가 없는 몇몇 컬럼 제거
del pop['20-39세남자']
del pop['65세이상남자']
del pop['65세이상여자']
pop.head()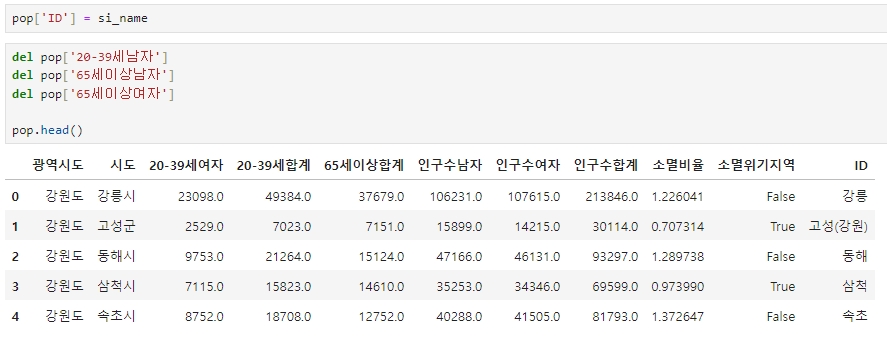
Catogram 으로 우리나라 지도 만들기
저자가 만든 엑셀 파일 다운로드
다운로드 받은 엑셀 파일을 파이썬에서 불러오기
draw_korea_raw = pd.read_excel('../data/05. draw_korea_raw.xlsx', encoding="EUC-KR")
draw_korea_raw그러나, read_excel() got an unexpected keyword argument 'encoding' 이라는 에러가 뜬다.
Chat GPT의 도움을 받아보니,
| 이 에러는 read_excel() 함수가 예상치 못한 키워드 인자인 'encoding'을 받았다는 것을 나타냅니다. 이것은 Pandas 버전에 따라 발생할 수 있는 문제입니다. 대신 read_excel() 함수를 사용하여 엑셀 파일을 읽을 때 인코딩을 지정하는 대신, encoding 대신 engine='openpyxl'을 사용하여 다음과 같이 시도할 수 있습니다: draw_korea_raw = pd.read_excel('../data/05. draw_korea_raw.xlsx', engine='openpyxl') 이렇게 하면 엑셀 파일을 읽을 때 인코딩 문제를 우회할 수 있습니다. 계속해서 진행하려면 이 방법으로 시도해보세요. 문제가 해결되지 않으면 다시 알려주세요! |
Chat GPT 가 알려준대로 코드를 다시 입력하니
draw_korea_raw = pd.read_excel('../data/05. draw_korea_raw.xlsx', engine='openpyxl')
draw_korea_raw문제없이 잘 뜬다
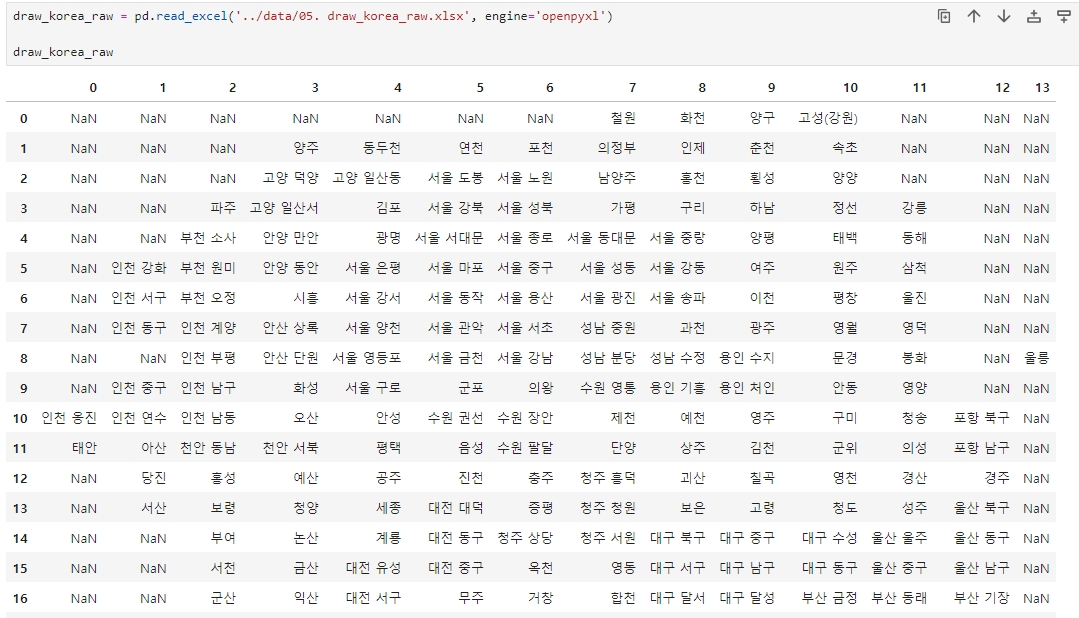
지역별 x,y의 좌표가 필요하므로 stack() 으로 풀고 인덱스를 재설정 (reset_index)
그리고나서 컬럼 이름 변경
draw_korea_raw_stacked = pd.DataFrame(draw_korea_raw.stack()) #스택으로 풀기
draw_korea_raw_stacked.reset_index(inplace=True) #인덱스 재설정
draw_korea_raw_stacked.rename(columns={'level_0':'y', 'level_1':'x', 0:'ID'},
inplace=True) #컬럼명 변경하기
draw_korea_raw_stacked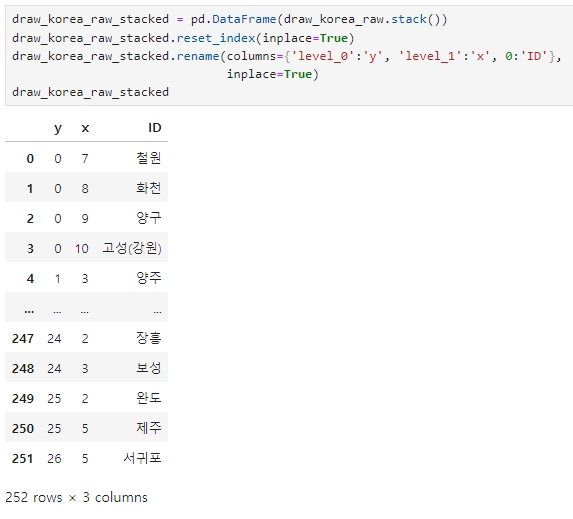
그리고 변수 이름도 변경
draw_korea_raw = draw_korea_raw_stacked
광역시도 구분하는 경계선 코드 입력 (직접 입력하지 마시고 구글링 해서 복붙 하시기를)
BORDER_LINES=[
[(5,1),(5,2),(7,2),(7,3),(11,3),(11,0)], # 인천
[(5,4),(5,5),(2,5),(2,7),(4,7),(4,9),(7,9),(7,7),(9,7),(9,5),(10,5),(10,4),(5,4)], # 서울
[(1,7),(1,8),(3,8),(3,10),(10,10),(10,7),(12,7),(12,6),(11,6),(11,5),(12,5),(12,4),(11,4),(11,3)], # 경기도
[(8,10),(8,11),(6,11),(6,12)], # 강원도
[(12,5),(13,5),(13,4),(14,4),(14,5,),(15,5),(15,4),(16,4),(16,2)], # 충청북도
[(16,4),(17,4),(17,5),(16,5),(16,6),(19,6),(19,5),(20,5),(20,4),(21,4),(21,3),(19,3),(19,1)], # 전라북도
[(13,5),(13,6),(16,6)],
[(13,5),(14,5)], # 대전시 세종
[(21,2),(21,3),(22,3),(22,4),(24,4),(21,2),(24,2)], #광주
[(20,5),(21,5),(21,6),(23,6)], #전라남도
[(10,8),(12,8),(12,9),(14,9),(14,8),(16,8),(16,6)], # 충청북도
[(14,9),(14,11),(14,12),(13,12),(13,13)], # 경상북도
[(15,8),(17,8),(17,10),(16,10),(16,11),(14,11)], # 대구
[(17,9),(18,9),(18,8),(19,8),(19,9),(20,9),(20,10),(21,10)], # 부산
[(16,11),(16,13)],
[(27,5),(27,6),(25,6)]
]
경계선과 지역 이름만 나타나게 하기
plt.figure(figsize=(8, 11))
# 지역 이름 표시
for idx, row in draw_korea_raw.iterrows():
# 광역시는 구 이름이 겹치는 경우가 많아서 시단위 이름도 같이 표시
# (중구, 서구)
if len(row['ID'].split()) == 2:
dispname = '{}\n{}'.format(row['ID'].split()[0], row['ID'].split()[1])
elif row['ID'][:2] == '고성':
dispname = '고성'
else:
dispname = row['ID']
# 서대문구, 서귀포시 같이 이름이 3자 이상인 경우에 작은 글자로 표시
if len(dispname.splitlines()[-1]) >= 3:
fontsize, linespacing = 9.5, 1.5
else:
fontsize, linespacing = 11, 1.2
plt.annotate(dispname, (row['x']+0.5, row['y']+0.5), weight='bold', fontsize=fontsize, ha='center', va='center', linespacing=linespacing)
# 시도 경계 그리기
for path in BORDER_LINES:
ys, xs = zip(*path)
plt.plot(xs, ys, c='black', lw=1.5)
plt.gca().invert_yaxis()
# plt.gca().set_aspect(1)
plt.axis('off')
plt.tight_layout()
plt.show()

다음글
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 우리나라 인구 소멸 위기 지역 분석 - 4 (0) | 2024.05.01 |
|---|---|
| [파이썬] 우리나라 인구 소멸 위기 지역 분석 - 3 (0) | 2024.04.30 |
| [파이썬] 우리나라 인구 소멸 위기 지역 분석 - 1 (0) | 2024.04.29 |
| [파이썬] 주유소 가격 비교하기 - 4 (0) | 2024.04.29 |
| [파이썬] 주유소 가격 비교하기 - 3 (0) | 2024.04.29 |



