시작에 앞서
해당 내용은 <파이썬으로 데이터 주무르기> -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.
보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.
이전 분석 내용
[파이썬] 19대 대선 결과 분석 -2
시작에 앞서해당 내용은 -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.이전 분석 내용 [파이썬] 19대 대선 결과 분석 -
puppy-foot-it.tistory.com
'draw_korea' csv 파일 불러오기
이전에 작업했던 'draw_korea.csv' 파일을 읽어온다.
draw_korea = pd.read_csv('../data/05. draw_korea.csv', encoding='utf-8', index_col=0)
draw_korea.head()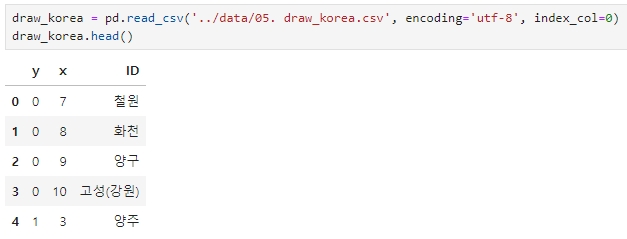
두 데이터의 ID 일치 여부 확인
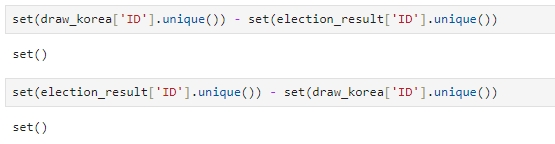
지역별 좌표 정보를 가지고 있는 'draw_korea'의 ID와 시각화돼야 할 대상인 'election_result'의 ID가 서로 일치해야 하므로 일치 여부 확인 (서로의 차집합을 구해서 둘 다 공집합일 경우 일치)
set(draw_korea['ID'].unique()) - set(election_result['ID'].unique())set(election_result['ID'].unique()) - set(draw_korea['ID'].unique())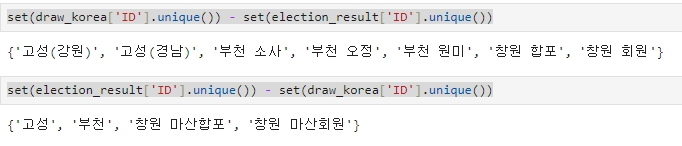
'고성', '창원',' 부천' 이 서로 일치하지 않는 것을 확인할 수 있다
두 데이터의 ID 일치 시켜주기 - 고성
먼저 고성의 경우는 강원도 고성과 경남 고성을 구분하면 된다.
election_result[election_result['ID'] == '고성']
#변수명.loc[인덱스번호, '컬럼명'] = '변경내용'
election_result.loc[125, 'ID'] = '고성(강원)'
election_result.loc[233, 'ID'] = '고성(경남)'
# ID가 잘 변경되었는지 확인
election_result[election_result['시군'] == '고성군']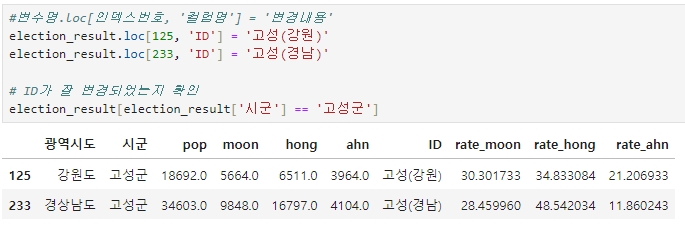
두 데이터의 ID 일치 시켜주기 - 창원
먼저 경상남도를 조회해보면
election_result[election_result['광역시도'] == '경상남도']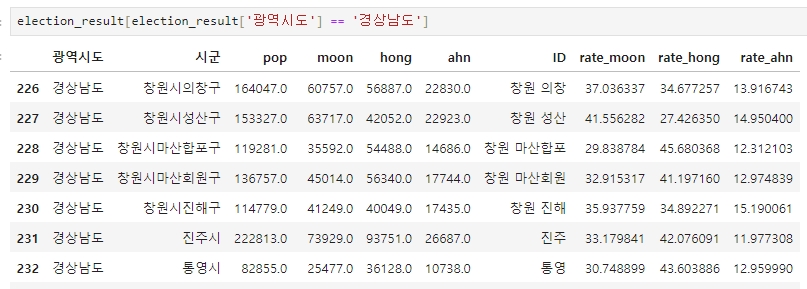
경남의 창원시는 옛 마산이 통합되면서 마산합포구와 마산회원구로 이름이 변경됐는데 문제는 지도로 시각화하기에는 너무 길다. 또한, 현지 지역민들도 창원시 마산합포구라는 이름보다는 창원 합포구라고 줄여 부르기도 하여
두 지역의 이름을 각각 '합포', '회원'으로 변경
#변수명.loc[인덱스번호, '컬럼명'] = '변경내용'
election_result.loc[228, 'ID'] = '창원 합포'
election_result.loc[229, 'ID'] = '창원 회원'
# ID가 잘 변경되었는지 확인
election_result[election_result['광역시도'] == '경상남도']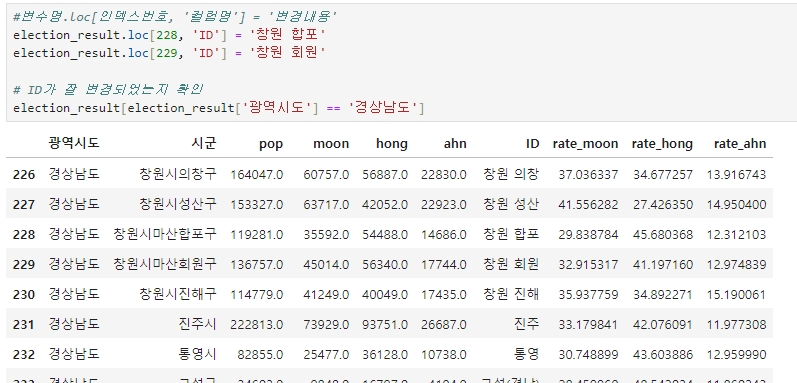
두 데이터의 ID 일치 시켜주기 - 부천
이제 일치하지 않는 지역을 조회하면 '부천' 쪽만 나온다.
set(draw_korea['ID'].unique()) - set(election_result['ID'].unique())set(election_result['ID'].unique()) - set(draw_korea['ID'].unique())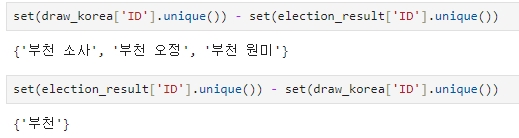
2016년 6월부터 부천시는 소사, 오정, 원미구를 폐지하였다.
그래서 draw_korea의 데이터에는 부천시의 구가 존재하고 election_result에는 없다.
따라서 부천시는 부천시 전체 데이터를 단순히 3으로 나눠 진행. (단, 각 후보의 득표율은 나눌 필요 없음)
election_result[election_result['시군'] == '부천시']
먼저, 데이터를 삽입할 index 번호 확인 (tail 명령)
election_result.tail()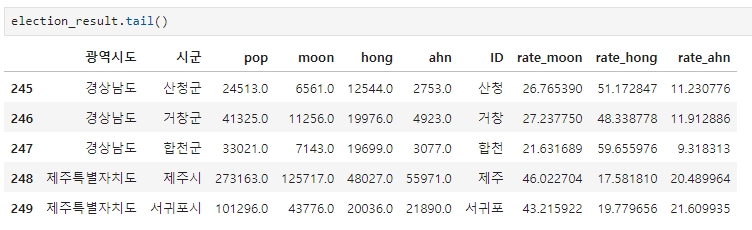
# 잘못된 코드이니 입력하지마세요!!
ahn_tmp = election_result.loc[85, 'ahn']/3 #부천시 ahn/3
hong_tmp = election_result.loc[85, 'hong']/3 #부천시 hong/3
moon_tmp = election_result.loc[85, 'moon']/3 #부천시 moon/3
pop_tmp = election_result.loc[85, 'pop']/3 #부천시 인구/3
#득표율은 그대로
rate_moon_tmp = election_result.loc[85, 'rate_moon']
rate_hong_tmp = election_result.loc[85, 'rate_hong']
rate_ahn_tmp = election_result.loc[85, 'rate_ahn']
#새로운 index 삽입
election_result.loc[250] = [ahn_tmp, hong_tmp, moon_tmp, pop_tmp, '경기도','부천시','부천소사',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]
election_result.loc[251] = [ahn_tmp, hong_tmp, moon_tmp, pop_tmp, '경기도','부천시','부천오정',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]
election_result.loc[252] = [ahn_tmp, hong_tmp, moon_tmp, pop_tmp, '경기도','부천시','부천원미',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]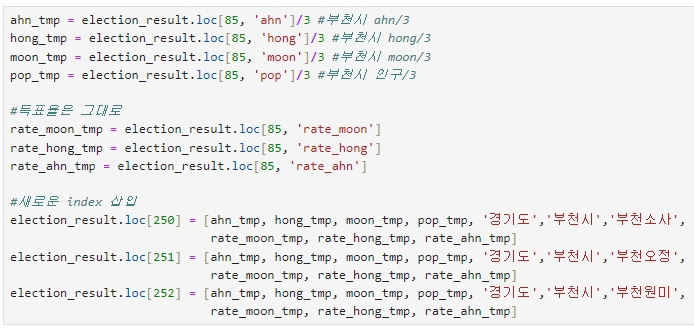
그리고 기존의 부천시 데이터는 삭제하면 된다. (drop 명령)
election_result.drop([85], inplace=True)
election_result[election_result['시군'] == '부천시']
※ 돌발상황
그러나, 문제가 생겼다.
위에서 새로운 데이터를 입력하는 과정에서 저자가 데이터 입력 순서를 잘못 지정한 듯 하다. (교재 내에 이런 오류가 꽤 있다ㅠ)
데이터 순서를 바꿔야 하는 상황.
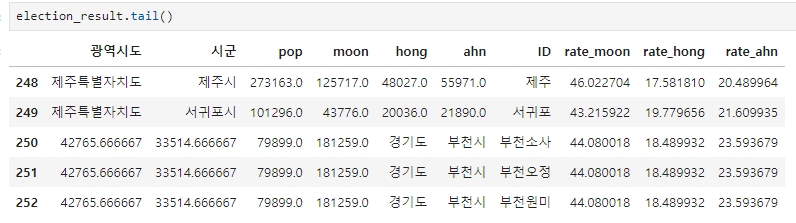
먼저 앞서 만든 250-252 행을 삭제
election_result.drop([250], inplace=True)
election_result.drop([251], inplace=True)
election_result.drop([252], inplace=True)
다시 부천 데이터를 삽입
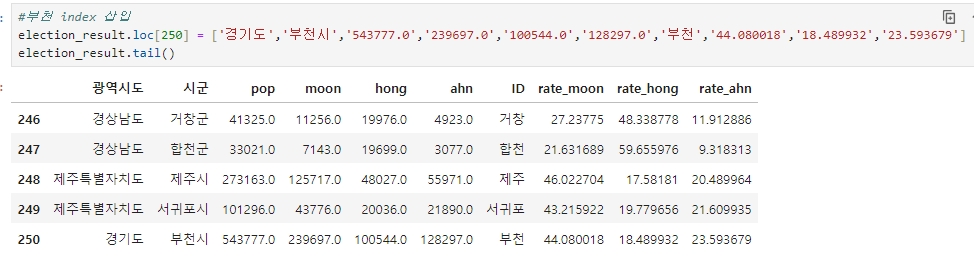
#부천 index 삽입
election_result.loc[250] = ['경기도','부천시','543777.0','239697.0','100544.0','128297.0','부천','44.080018','18.489932','23.593679']
election_result.tail()
위의 코드를 순서를 바꿔서 재입력하면
ahn_tmp = election_result.loc[250, 'ahn']/3 #부천시 ahn/3
hong_tmp = election_result.loc[250, 'hong']/3 #부천시 hong/3
moon_tmp = election_result.loc[250, 'moon']/3 #부천시 moon/3
pop_tmp = election_result.loc[250, 'pop']/3 #부천시 인구/3
#득표율은 그대로
rate_moon_tmp = election_result.loc[250, 'rate_moon']
rate_hong_tmp = election_result.loc[250, 'rate_hong']
rate_ahn_tmp = election_result.loc[250, 'rate_ahn']
#새로운 index 삽입
election_result.loc[251] = ['경기도','부천시', pop_tmp, moon_tmp, hong_tmp, ahn_tmp, '부천 소사',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]
election_result.loc[252] = ['경기도','부천시', pop_tmp, moon_tmp, hong_tmp, ahn_tmp, '부천 오정',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]
election_result.loc[253] = ['경기도','부천시', pop_tmp, moon_tmp, hong_tmp, ahn_tmp, '부천 원미',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]
election_result.tail()
해결!! 은 무슨...
TypeError: unsupported operand type(s) for /: 'str' and 'int'
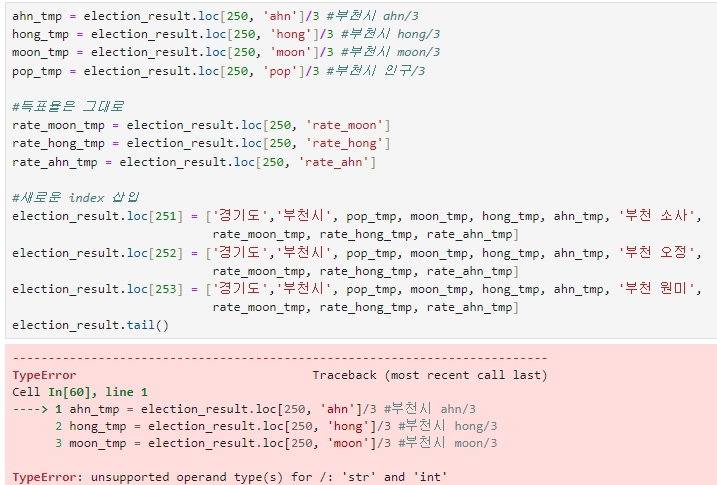
라는 오류가 뜨는데, 아무래도 부천시 인덱스를 새로 삽입할 때 입력한 숫자들이 숫자가 아닌 '문자'로 지정되어 있어
계산이 불가하여 뜨는 오류로 보인다.
그렇다면, 해결책은 부천시 인덱스를 삭제하고, 다시 입력하는데 이때 숫자데이터들이 문자가 아닌 숫자 타입으로 지정되어 입력될 수 있도록 해야 한다.
다시 부천시 인덱스를 삭제(drop)하고, 부천시 데이터를 다시 삽입
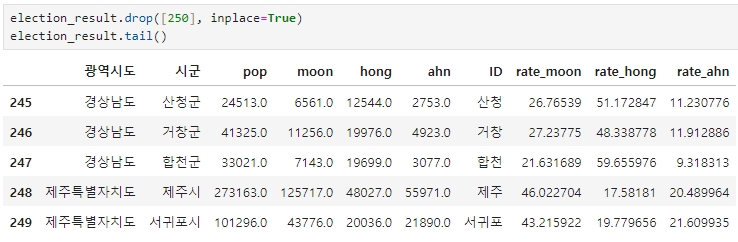

그러나 이번엔 하단의 오류가 떴다.
AttributeError: 'DataFrame' object has no attribute 'append'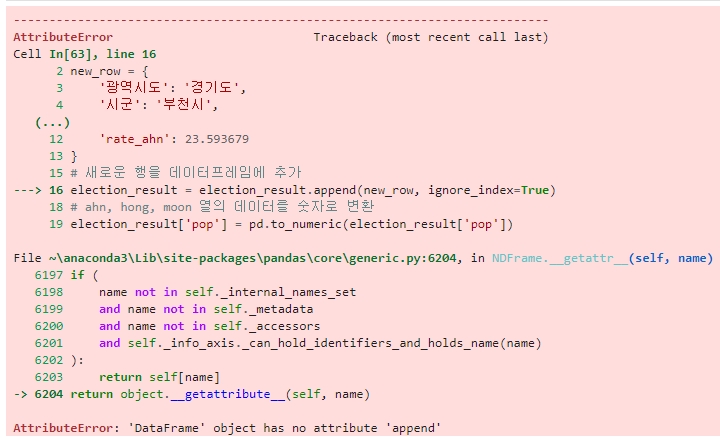
DataFrame 객체가 append 속성을 가지고 있지 않기 때문에 발생한 오류이며,
대신에 concat() 함수를 사용하여 새로운 행을 데이터프레임에 추가할 수 있다는 Chat GPT의 도움을 받았다.
# 부천시 데이터를 데이터프레임에 추가
new_row = {
'광역시도': '경기도',
'시군': '부천시',
'pop': 543777.0,
'moon': 239697.0,
'hong': 100544.0,
'ahn': 128297.0,
'ID': '부천',
'rate_moon': 44.080018,
'rate_hong': 18.489932,
'rate_ahn': 23.593679
}
# 새로운 행을 데이터프레임에 추가
election_result = pd.concat([election_result, pd.DataFrame([new_row])], ignore_index=True)
# 열의 데이터를 숫자로 변환
cols_to_numeric = ['pop', 'moon', 'hong', 'ahn', 'rate_moon', 'rate_hong', 'rate_ahn']
election_result[cols_to_numeric] = election_result[cols_to_numeric].apply(pd.to_numeric)
# 결과 출력
print(election_result.tail())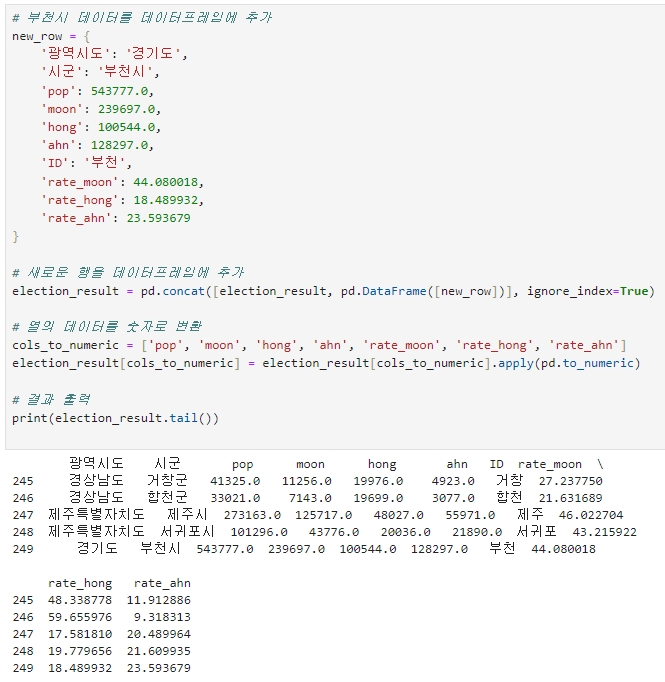
데이터를 조회해보니 잘 들어온 것을 확인할 수 있다.
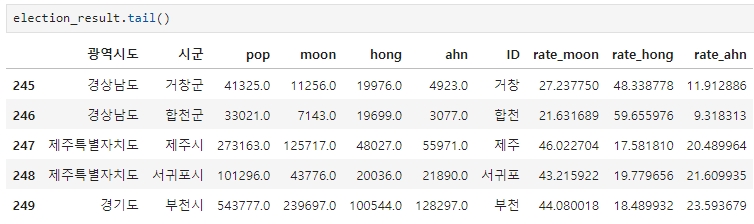
이제 다시 해당 데이터를 3으로 나누어 소사, 오정, 원미구에 대한 데이터를 넣어줘야 한다.
ahn_tmp = election_result.loc[249, 'ahn']/3 #부천시 ahn/3
hong_tmp = election_result.loc[249, 'hong']/3 #부천시 hong/3
moon_tmp = election_result.loc[249, 'moon']/3 #부천시 moon/3
pop_tmp = election_result.loc[249, 'pop']/3 #부천시 인구/3
#득표율은 그대로
rate_moon_tmp = election_result.loc[249, 'rate_moon']
rate_hong_tmp = election_result.loc[249, 'rate_hong']
rate_ahn_tmp = election_result.loc[249, 'rate_ahn']
#새로운 index 삽입
election_result.loc[250] = ['경기도','부천시', pop_tmp, moon_tmp, hong_tmp, ahn_tmp, '부천 소사',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]
election_result.loc[251] = ['경기도','부천시', pop_tmp, moon_tmp, hong_tmp, ahn_tmp, '부천 오정',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]
election_result.loc[252] = ['경기도','부천시', pop_tmp, moon_tmp, hong_tmp, ahn_tmp, '부천 원미',
rate_moon_tmp, rate_hong_tmp, rate_ahn_tmp]
election_result.tail()
아주 다행히도 순서에 맞게 데이터가 잘 들어왔음을 알 수 있다. (진짜 고생했다...)

이제 'ID'가 '부천'인 249행을 지워주고 다음 스텝으로 넘어가면 된다.
election_result.drop([249], inplace=True)
election_result.tail()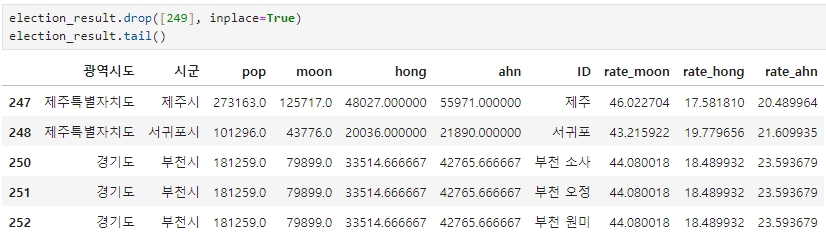
문제 해결 완료!
두 데이터의 일치 여부 재확인
이제 draw_korea 와 election_result 데이터를 합칠 수 있는 준비가 되었다.
draw_korea 와 election_result 합치기 (merge)
merge 명령을 이용하여 draw_korea 와 election_result 를 합치고 final_elect_data 라는 변수로 저장한다.
final_elect_data = pd.merge(election_result, draw_korea, how='left', on=['ID'])
final_elect_data.head()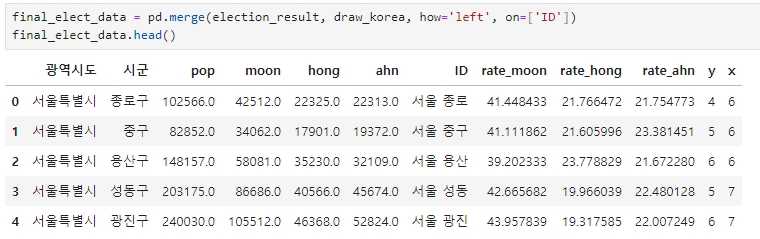
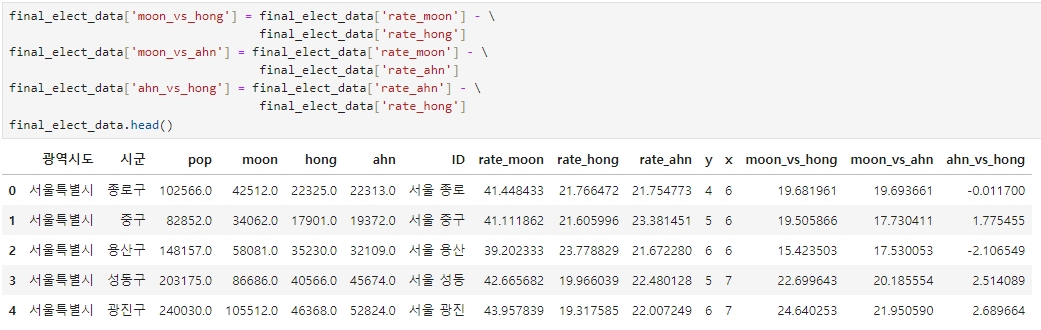
각 후보별 득표율 차이 계산
각 후보별 득표율 차이를 계산하여 새로운 컬럼에 넣어 준다.
final_elect_data['moon_vs_hong'] = final_elect_data['rate_moon'] - \
final_elect_data['rate_hong']
final_elect_data['moon_vs_ahn'] = final_elect_data['rate_moon'] - \
final_elect_data['rate_ahn']
final_elect_data['ahn_vs_hong'] = final_elect_data['rate_ahn'] - \
final_elect_data['rate_hong']
final_elect_data.head()
다음 챕터에서는 19대 대선 결과 득표율 시각화 작업
[파이썬] 19대 대선 결과 분석 -4
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 시계열 데이터 다루기 - 1 (0) | 2024.05.06 |
|---|---|
| [파이썬] 19대 대선 결과 분석 -4 (0) | 2024.05.04 |
| [파이썬] 19대 대선 결과 분석 -2 (0) | 2024.05.01 |
| [파이썬] 19대 대선 결과 분석 -1 (1) | 2024.05.01 |
| [파이썬] 우리나라 인구 소멸 위기 지역 분석 - 4 (0) | 2024.05.01 |



