시작에 앞서
해당 내용은 <파이썬으로 데이터 주무르기> -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.
보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.
지난 챕터
[파이썬] 자연어 처리(NLP) 시작하기 - 1
시작에 앞서해당 내용은 -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.자연어 처리(NLP)란? 자연어처리 (NLP; Natural langu
puppy-foot-it.tistory.com
한글 자연어 처리 기초 - 꼬꼬마 모듈
지난 분석에서 언급했듯, KoNLPy 는 꼬꼬마, 한나눔 등의 엔진을 사용할 수 있게 해준다.
# konlpy.tag 모듈에서 Kkma 클래스를 가져오기
from konlpy.tag import Kkma
kkma = Kkma()- 문장 (sentences) 분석

- 명사(nouns) 분석

- 형태소(pos) 분석
한글은 영어와 달리 단어의 형태 변화가 많아 영어처럼 쉽게 접근하기 어렵기 때문에,
일반적으로 형태소로 언어를 분석

한글 자연어 처리 기초 - 한나눔 모듈
# konlpy.tag 모듈에서 한나눔 클래스를 가져오기
from konlpy.tag import Hannanum
hannanum = Hannanum()- 명사(nouns) 분석

- 형태소(morphs | pos) 분석
| ※ morphs 와 pos 의 차이 [with Chat GPT] 한국어 자연어 처리(NLP)에서는 morphs()와 pos() 메소드가 다양한 목적으로 사용됩니다. morphs(): 이 방법은 한국어 텍스트를 구성 형태소로 토큰화하는 데 사용됩니다 형태소는 언어에서 가장 작은 의미를 지닌 단위입니다. 예를 들어, 영어에서 "cats"라는 단어는 "cat"(어근)과 "s"(복수 표시)라는 두 가지 형태소로 구성됩니다. 마찬가지로 한국어에서도 단어는 의미나 문법적 기능을 전달하는 형태소로 구성됩니다 문장은 명사, 동사, 형용사, 입자 및 기타 문법 요소를 포함한 개별 형태소로 토큰화됩니다. pos(): 이 방법은 문장의 각 단어에 명사, 동사, 형용사 등과 같은 해당 품사를 표시하는 품사(POS) 태깅에 사용됩니다. POS 태깅은 필수입니다. 문장의 문법 구조와 의미를 이해하는 데 도움이 됩니다. 문장의 각 단어에 해당하는 품사 태그가 지정됩니다. 예를 들어 'N'은 명사, 'J'는 조사, 'X'는 조동사 어간, 'E'는 어미, 'S'는 문장 끝 표시를 나타냅니다. 요약하자면 morphs()는 한국어 텍스트를 형태소로 토큰화하는 데 사용되는 반면, pos()는 각 형태소에 해당 품사를 태그하는 데 사용됩니다. 이러한 방법은 서로 다른 목적으로 사용되지만 텍스트를 이해하고 분석하기 위해 한국어 NLP 작업에서 함께 사용되는 경우가 많습니다. |

한글 자연어 처리 기초 - 트위터 분석
# konlpy.tag 모듈에서 트위터 클래스를 가져오기
from konlpy.tag import Twitter
t = Twitter()
하지만, 하단과 같은 경고 메시지가 나오는데
C:\Users\niceq\anaconda3\Lib\sitepackages\konlpy\tag\_okt.py:17: UserWarning: "Twitter" has changed to "Okt" since KoNLPy v0.4.5.warn('"Twitter" has changed to "Okt" since KoNLPy v0.4.5.')
보고 있는 경고는 KoNLPy 라이브러리에서 토큰화에 사용되는 클래스 이름이 변경되었음을 나타내며, 이전에는 "Twitter"라고 불렸으나 KoNLPy 0.4.5 버전부터 "Okt"로 이름이 변경되었다.
경고의 의미를 더 자세히 설명하면 다음과 같다.
KoNLPy 0.4.5 이전 버전에서는 한국어 텍스트 토큰화를 위한 클래스 이름이 Twitter였다.
그러나 라이브러리의 목적을 더 잘 반영하고 소셜 미디어 플랫폼과의 혼동을 피하기 위해 버전 0.4.5부터 클래스 이름이 'Okt'(Open Korean Text의 약자)로 변경되었다.
따라서 대신 Okt를 사용해야 합니다.
KoNLPy 0.4.5 이상 버전을 사용 중이고 이 경고가 표시되는 경우 한국어 텍스트 토큰화에 'Twitter' 대신 'Okt'를 사용하도록 코드를 업데이트하는 것이 좋다. 이렇게 하면 라이브러리의 향후 버전과의 호환성이 보장된다.
따라서, Okt 모듈을 불러오고, 명사 / 형태소(morphs | pos) 분석을 해보면
from konlpy.tag import Okt
okt = Okt()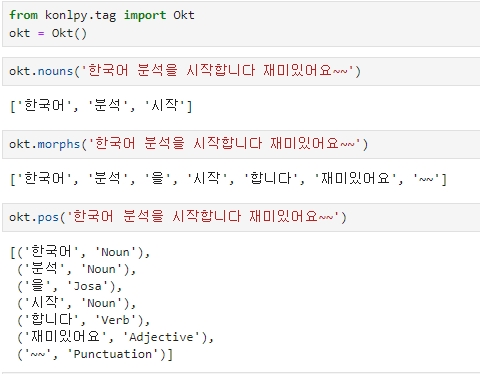
각 엔진 (꼬꼬마, 한나눔, Okt) 별로 미세한 차이가 있음을 알 수 있다.
다음 챕터 주제: 워드 클라우드
다음글
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 자연어 처리(NLP) 시작하기 - 4 (0) | 2024.05.08 |
|---|---|
| [파이썬] 자연어 처리(NLP) 시작하기 - 3 (0) | 2024.05.08 |
| [파이썬] 자연어 처리(NLP) 시작하기 - 1 (0) | 2024.05.06 |
| [파이썬] 시계열 데이터 다루기 - Growth Model / Holiday Forecast (0) | 2024.05.06 |
| [파이썬] 시계열 데이터 다루기 - 3 (0) | 2024.05.06 |



