허깅페이스란?

허깅페이스(Hugging Face)는 자연어 처리(NLP)와 머신러닝(ML) 커뮤니티에서 가장 혁신적이고 중요한 플랫폼 중 하나로 자리 잡고 있다. 허깅페이스는 주로 Transformer 모델을 중심으로 한 오픈 소스 라이브러리와 도구를 제공하며, 연구자, 개발자, 기업이 쉽게 AI 모델을 구축하고 배포할 수 있도록 돕는다.
허깅페이스는 미국의 인공지능 스타트업이며, 트랜스포머나 데이터셋 같은 머신러닝 프레임워크를 제공하는 세계 최대의 인공지능 플랫폼 중 하나이다.
개발자는 여기에 공개된 머신러닝 레퍼런스를 통해 최신 모델을 스스로 구축할 수 있다. 트랜스포머 모델을 만들 때 코드를 작성할 필요없이 여기서 트랜스포머 라이브러리를 가져오기만 하면 되기 때문에 앱 구축 과정에서 상당히 유용하다. 최신 모델을 업데이트할 뿐만 아니라, 지속적인 리뷰를 통해 완성도 높은 모델을 받을 수 있다. 특히 배포->리뷰->수정 단계를 거치도록 형성하는 오픈 소스 커뮤니티라는 장점을 갖고 있다.
[허깅페이스 홈페이지]
Hugging Face – The AI community building the future.
The Home of Machine Learning Create, discover and collaborate on ML better. We provide paid Compute and Enterprise solutions. We are building the foundation of ML tooling with the community.
huggingface.co
허깅페이스는 오픈 소스 프로젝트 외에도 기업을 위한 프리미엄 서비스와 솔루션을 제공한다. 이는 주로 허깅페이스 허브의 기업용 플랜과 클라우드 기반의 API 서비스로 구성되어 있다. 이를 통해 기업들은 허깅페이스의 강력한 NLP 도구를 활용하여 다양한 비즈니스 문제를 해결할 수 있다.
허깅페이스의 주요 기능
1. Transformers 라이브러리: 다양한 NLP 작업을 위한 사전 훈련된 모델을 포함하고 있으며, 이를 통해 언어 모델링, 텍스트 생성, 번역, 감정 분석 등의 작업을 쉽게 수행할 수 있다.
2. Datasets 라이브러리: 다양한 형태의 데이터셋을 간편하게 로드하고 전처리할 수 있는 도구를 제공한다. 이 라이브러리는 데이터셋의 탐색, 분석, 변환을 용이하게 하여 모델 훈련에 필요한 데이터를 손쉽게 준비할 수 있게 해준다.
3. Tokenizers 라이브러리: 텍스트 데이터를 토큰화하고 전처리하는 데 최적화된 도구이며, 이는 NLP 모델의 성능을 극대화하기 위해 필수적인 단계이다.
4. Hub: 허깅페이스 허브는 모델, 데이터셋, 응용 프로그램을 공유하고 협업할 수 있는 플랫폼이다. 사용자들은 자신의 모델과 데이터셋을 업로드하여 커뮤니티와 공유하고, 다른 사용자의 리소스를 활용할 수 있다.
[LLM] 허깅페이스 라이브러리 사용법 익히기
허깅페이스 [AI 플랫폼] 허깅페이스: AI와 머신러닝의 새로운 지평허깅페이스란? 허깅페이스(Hugging Face)는 자연어 처리(NLP)와 머신러닝(ML) 커뮤니티에서 가장 혁신적이고 중요한 플랫폼 중 하나
puppy-foot-it.tistory.com
허깅페이스의 혁신적인 기술들
허깅페이스의 핵심 기술은 Transformer 모델이다.
Transformer 모델: 기존의 RNN(Recurrent Neural Network)과 LSTM(Long Short-Term Memory) 모델의 한계를 극복하며, 병렬 처리와 더 나은 성능을 제공하는 모델이다.
이 모델은 특히 BERT, GPT, T5와 같은 유명한 사전 훈련된 모델들을 기반으로 하여 NLP 작업에서 탁월한 성능을 발휘한다.
BERT(Bidirectional Encoder Representations from Transformers): BERT는 양방향 학습을 통해 문맥을 이해하는 모델로, 문장 내 모든 단어를 동시에 학습하여 더 정교한 언어 이해를 가능하게 한다.
GPT(Generative Pre-trained Transformer): GPT는 생성적 사전 훈련 모델로, 주어진 텍스트의 문맥을 기반으로 새로운 텍스트를 생성하는 데 뛰어난 성능을 보인다. GPT-3는 특히 큰 관심을 받으며, 다양한 응용 분야에서 활용되고 있다.
T5(Text-To-Text Transfer Transformer): T5는 모든 NLP 작업을 텍스트 입력과 텍스트 출력으로 변환하여 통일된 형식으로 처리하는 모델이다. 이를 통해 다양한 작업에서 일관된 성능을 발휘한다.
허깅페이스의 트랜스포머 라이브러리
허깅페이스는 오픈 소스 커뮤니티를 중심으로 성장해 왔으며, 수많은 개발자와 연구자들이 적극적으로 참여하고 있다. 이 커뮤니티는 지속적으로 새로운 모델과 기술을 공유하며, 혁신을 이끌어가고 있다. 허깅페이스의 허브는 이러한 협업을 촉진하는 플랫폼으로, 전 세계의 AI 연구자들이 쉽게 접근하고 기여할 수 있다.
허깅 페이스의 모델 허브를 통해 사전 훈련된 고성능 모델을 쉽게 다운로드할 수 있어 일반적으로 트랜스포머를 직접 구현하지 않아도 된다. 이 생태계의 핵심 구성 요소는 사전 훈련된 모델과 이에 상응하는 토크나이저를 쉽게 다운로드한 다음, 필요한 경우 자체 데이터셋에서 미세 튜닝할 수 있는 트랜스포머스 라이브러리이다. 또한 이 라이브러리는 텐서플로, 파이토치, JAX(Flax 라이브러리를 통해) 를 지원한다.
먼저 최신 버전의 트랜스포머스 모듈을 설치한다.
pip install transformers
트랜스포머스스 라이브러리를 사용하는 가장 간단한 방법은 transformers.pipeline() 함수를 사용하는 것으로, 감성 분석, 개체명 인식, 요약 등 원하는 작업을 지정하기만 하면 사전 훈련된 기본 모델을 다운로드하여 바로 사용할 수 있다.
from transformers import pipeline
classifier = pipeline('sentiment-analysis')
result = classifier('The actors were very convincing.')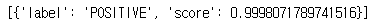
▶ 결과 내용은 입력 텍스트당 하나의 딕셔너리를 담은 파이썬 리스트이다. 이 예제에서 모델은 약 99.99% 신뢰도로 해당 문장이 긍정임을 정확하게 판단했다.
모델에 문장의 배치를 전달할 수도 있다.
classifier(['I am from India.', 'I am from Iraq.'])
pipeline() 함수는 주어진 작업에 대해 기본 모델을 사용한다. 예를 들어, 감성 분석과 같은 텍스트 분류 작업의 경우, 이 함수를 작성할 당시에는 기본적으로 disilbert-base-uncased-finetuned-sst-2-english 모델을 사용한다. 영어 위키백과와 영어 책 말뭉치에 대해 훈련했고, 스탠퍼드 감성 트리뱅크 vs 작업에 대해 미세 튜닝되었으며, 대소문자를 구분하지 않는 토크나이저를 사용하는 DistilBERT 모델이다.
다른 모델을 수동으로 지정하는 것도 가능한데, 예를 들어 두 문장을 모순, 중립, 함의 의 세 가지 클래스로 분류하는 MultiNLI 작업에서 미세 튜닝된 DistilBERT 모델을 사용할 수 있다.
model_name = 'huggingface/distilbert-base-uncased-finetuned-mnli'
classifier_mnli = pipeline('text-classification', model=model_name)
classifier_mnli('She loves me. [SEP] She loves me not')
※ contradiction: 모순
사용 가능한 모델은 https://huggingface.co/models 에서,
작업 목록은 https://huggingface.co/tasks 에서 확인가능하다.
파이프라인 API는 매우 간단하고 편리하지만 때로는 더 많은 제어가 필요할 수 있다. 이러한 경우를 위해 트랜스포머스 라이브러리는 다양한 종류의 토크나이저, 모델, 설정, 콜백 등 많은 클래스를 제공한다.
예를 들어 TFAutoModelForSequenceClassification 과 AutoTokenizer 클래스를 사용하여 동일한 DistilBERT 모델을 토크나이저와 함께 로드해본다.
from transformers import TFAutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
그리고 두 개의 문장 쌍을 토큰화한다. 이 코드에서는 패딩을 활성화하고 텐서플로 텐서를 사용한다.
# 두 개의 문장 쌍 토큰화 (패딩 활성화, 텐서플로 텐서 사용)
token_ids = tokenizer(['I like soccer. [SEP] We all love soccer!',
'Bell lived for a very long time. [SEP] Bell is old'],
padding=True, return_tensors='tf')
출력은 딕셔너리와 비슷한 BatchEncoding 클래스의 객체로 토큰 ID의 시퀀스와 패딩 토큰을 0으로 마스킹한 마스크를 포함한다.
token_ids
토크나이저를 호출할 때 return_token_type_ids=True로 설정하면 각 토큰이 속한 문장을 나타내는 추가 텐서도 얻을 수 있다. (일부 모델에 필요하지만 DistilBERT 모델에는 불필요)
그다음 이 BatchEncoding 객체를 모델에 직접 전달하면 예측 클래스 로짓을 포함하는 TFSequenceClassifierOutput 객체가 반환된다.
outputs = model(token_ids)
outputs
그리고 소프트맥스 활성화 함수를 적용하여 로짓을 클래스 확률로 변환하고, argmax() 함수를 사용하여 각 입력 문장 쌍에 대해 가장 높은 확률을 가진 클래스를 예측할 수 있다.
Y_probas = tf.keras.activations.softmax(outputs.logits)
Y_probas
Y_pred = tf.argmax(Y_probas, axis=1)
Y_pred # 0 = 모순, 1 = 함의, 2 = 중립
▶ 모델은 첫 번째 문장 을 중립으로, 두 번째 쌍을 함의로 올바르게 분류한다.

자체 데이터셋에서 이 모델을 미세 튜닝하려면 케라스를 사용하여 모델을 훈련할 수 있다. 하지만 이 모델은 확률 대신 로짓을 출력하기 때문에 'sparse_categorical_crossentropy' 손실 대신 tf.keras.losses.SparseCategoricalCrossentropy(from_logits=Ture) 손실을 사용해야 한다. 또한 이 모델은 훈련 중에 BatchEncoding 입력을 지원하지 않으므로 data 속성을 사용하여 일반 딕셔너리로 준비해야 한다.
sentences = [('Sky is blue', 'Sky is red'), ('I love her', 'She loves me')]
X_train = tokenizer(sentences, padding=True, return_tensors='tf').data
y_train = tf.constant([0, 2]) # 모순, 중립
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(loss=loss, optimizer='nadam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=2)
또한, 허깅페이스는 표준 데이터셋 또는 사용자 정의 데이터셋을 쉽게 다운로드하고 이를 사용해 모델을 미세 튜닝할 수 있는 데이터셋 라이브러리를 만들었다. 이는 텐서플로 데이터셋과 유사하지만 마스킹과 같은 일반적인 전처리 작업을 즉석에서 수행할 수 있는 도구도 제공한다.
Hugging Face – The AI community building the future.
huggingface.co
허깅페이스의 미래 전망
허깅페이스는 AI와 NLP 분야에서 계속해서 혁신을 주도할 것으로 기대된다. 지속적인 기술 개발과 커뮤니티의 활발한 참여로 인해 허깅페이스는 앞으로도 더욱 많은 사람들이 AI 기술을 쉽게 접근하고 활용할 수 있도록 돕는 중요한 플랫폼이 될 것이다.
허깅페이스는 단순한 기술 제공을 넘어, 전 세계의 AI 커뮤니티와 협력하여 더 나은 미래를 만들기 위한 노력을 지속하고 있다. 이러한 점에서 허깅페이스는 AI와 머신러닝의 미래를 이끌어가는 선도적인 플랫폼으로 자리매김하고 있다.
AI 모델 및 도구 확장: Hugging Face는 다양한 응용 분야에 유용한 AI 모델과 도구를 지속적으로 개발하고 확장할 계획이다.
전략적 파트너십: 기술 대기업 및 기타 업계 리더와의 전략적 파트너십을 통해 역량과 도달 범위를 향상시킬 계획이다.
커뮤니티 참여: AI 애호가 및 전문가들 간의 협업, 자원 공유 및 토론을 장려하여 강력한 커뮤니티를 구축하는 데 중점을 둘 것이다.
윤리적 AI: 기술이 책임감 있게 개발되고 사용되도록 윤리적 AI 관행을 촉진할 것을 약속한다.
혁신 및 연구: 생성 AI의 새로운 영역과 응용 분야를 탐구하는 등 AI 기술의 최전선에 머물기 위해 연구와 혁신에 계속 투자할 것이다.
[출처]
허깅페이스 웹사이트
나무위키
위키피디아
AI타임스
네이버
핸즈 온 머신러닝
'프로그래밍 및 기타 > 프로그래밍 용어, 상식, 마케팅 등' 카테고리의 다른 글
| [AI기술] 멀티모달(Multi Modal) AI란? (0) | 2024.08.08 |
|---|---|
| [제품 수명 주기] PLC(Product Life Cycle) 란? (0) | 2024.08.08 |
| [HBM] 고대역폭 메모리(High Bandwidth Memory) 란? (0) | 2024.08.07 |
| [자동화 시스템] PLC(Programmable Logic Controller)란? (0) | 2024.08.06 |
| MES(Manufacturing Execution System) 란? (0) | 2024.07.17 |



