앙상블 학습
[머신러닝] 분류 - 앙상블 학습(Ensemble Learning)
앙상블 학습(Ensemble Learning) 앙상블 학습을 통한 분류는,여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법을 말한다. 앙상블 학습의 목표는,다양한
puppy-foot-it.tistory.com
스태킹 모델
스태킹(Stacking)은 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는 점에서 배깅(Bagging) 및 부스팅(Boosting)과 공통점을 갖고 있으나, 가장 큰 차이점은 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 것이다.
- 배깅: 훈련 세트에서 중복을 허용하여 샘플링하는 방식.
- 부스팅: 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법, 앞의 모델을 보완해나가면서 일련의 예측기를 학습시킴.
즉, 개별 알고리즘의 예측 결과 데이터 세트를 최종적인 메타 데이터 세트로 만들어 별도의 머신러닝 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행하는 방식이다.
★ 메타 모델: 개별 모델의 예측된 데이터 세트를 다시 기반으로 하여 학습하고 예측하는 방식.
스태킹 모델은 두 종류의 모델이 필요하다.
1) 개별적인 기반 모델
2) 최종 메타 모델: 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어 학습하는 모델
▶ 스태킹 모델의 핵심은 여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해 최종 메타 모델의 학습용 피처 데이터 세트와 테스트용 피처 데이터 세트를 만드는 것이다.
스태킹은 일반적인 현실 모델에 적용하는 경우는 많지 않으나, 성능 수치를 조금이라도 높여야 하는 캐글 같은 대회에서 자주 사용된다. 스태킹을 적용 시에는 2~3개의 개별 모델만을 결합해서는 쉽게 예측 성능을 향상시킬 수 없고, 스태킹을 적용한다고 해서 반드시 성능 향상이 보장되지는 않기 때문에 많은 개별 모델이 필요하다.
스태킹 앙상블
M개의 로우, N개의 피처(칼럼)를 가진 데이터 세트에 스태킹 앙상블을 적용하고, 학습에 사용할 ML 알고리즘 모델은 모두 3개라고 가정한다.
먼저 모델별로 각각 학습을 시킨 뒤 예측을 수행하면 각각 M개의 로우를 가진 1개의 레이블 값을 도출할 것이다.
모델별로 도출된 예측 레이블 값을 다시 합해서(스태킹) 새로운 데이터 세트를 만들고 이렇게 스태킹된 데이터 세트에 대해 최종 모델을 적용해 최종 예측을 하는 것이 스태킹 앙상블 모델이다.

사이킷런에서의 스태킹 앙상블
사이킷런은 스태킹 앙상블을 위한 StackingClassifier(분류)와 StackingRegressor(회귀) 클래스를 제공한다.
◆ moons 데이터셋을 활용한 스태킹 앙상블 구현
from sklearn.ensemble import StackingClassifier
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
stacking_clf = StackingClassifier(
estimators=[
('lr', LogisticRegression(random_state=42)),
('rf', RandomForestClassifier(random_state=42)),
('svc', SVC(probability=True, random_state=42))
],
final_estimator=RandomForestClassifier(random_state=42),
cv=5 # 교차 검증 폴드 개수
)
stacking_clf.fit(X_train, y_train)
▶ 각 예측기에 대해 스태킹 분류기는 사용 가능한 경우 predict_proba()를 호출하고, 그렇지 않은 경우 decision_function()을 사용하거나 최후의 수단으로 predict()를 호출한다.
최종 예측기를 제공하지 않으면 StackingClassifier는 LogisticRegression을 사용하고 StackingRegressor 는 RidgeCV를 사용한다.
테스트 세트에서 이 스태킹 모델을 평가해본다.
stacking_clf.score(X_test, y_test)
▶ 약 91.2% 의 정확도를 얻을 수 있다.
기본 스태킹 모델
기본 스태킹 모델을 위스콘신 암 데이터 세트에 적용하는 예제를 통해 스태킹 모델의 개념을 더 파악해본다.
◆ 데이터를 로딩하고 학습 데이터 세트와 테스트 데이터 세트로 나눈다.
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
X_train, X_test, y_train, y_test = train_test_split(X_data, y_label, test_size=0.2, random_state=0)
◆ 스태킹에 사용될 머신러닝 알고리즘 클래스를 생성
개별 모델은 KNN, 랜덤포레스트, 결정 트리, 에이다부스트이며, 이들 모델의 예측 결과를 합한 데이터 세트로 학습/예측하는 최종 모델은 로지스틱 회귀이다.
#스태킹에 사용될 머신러닝 알고리즘 클래스를 생성
#개별 ML 모델 생성
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0)
df_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
#스태킹으로 만들어진 데이터 세트를 학습, 예측할 최종 모델
lr_final = LogisticRegression()
◆ 개별 모델 학습
#개별 모델 학습
knn_clf.fit(X_train, y_train)
rf_clf.fit(X_train, y_train)
df_clf.fit(X_train, y_train)
ada_clf.fit(X_train, y_train)

[경고 메시지 확인 및 해결 방법]
The SAMME.R algorithm (the default) is deprecated and will be removed in 1.6. Use the SAMME algorithm to circumvent this warning. warnings.warn
이라는 경고가 나올 경우에는,
이 경고 메시지는 scikit-learn 라이브러리를 사용할 때 발생하는 것으로, SAMME.R 알고리즘이 더 이상 권장되지 않으며, scikit-learn 버전 1.6부터는 제거될 예정이라는 내용을 담고 있다. 경고에서 제안하는 대로 SAMME 알고리즘을 사용하여 이 문제를 해결할 수 있다.
[SAMME.R vs SAMME]
- SAMME.R은 실수(real-valued) 기반 부스팅 알고리즘으로, 종종 빠르게 수렴하여 더 적은 에러로 테스트 결과를 낼 수 있지만 곧 지원이 중단된다.
- SAMME는 이산(discrete) 기반 부스팅 알고리즘으로, 향후 계속 지원될 예정이다.
▶ 해결방법
AdaBoostClassifier를 사용할 때, algorithm='SAMME'로 설정하면 경고 없이 사용할 수 있다.
[해결 코드]
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(algorithm='SAMME')
코드를 입력 후, 개별 모델 학습 코드를 다시 실행해보니 문제 없이 진행된다.
◆ 개별 모델의 예측 데이터 세트를 반환하고 각 모델의 예측 정확도 파악
#예측 데이터 세트 반환, 각 모델의 예측 정확도 파악
#학습된 개별 모델들이 각자 반환하는 예측 데이터 세트를 생성하고 개별 모델의 정확도 측정
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
df_pred = df_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
print('KNN 정확도: {0:4f}'.format(accuracy_score(y_test, knn_pred)))
print('랜덤 포레스트 정확도: {0:4f}'.format(accuracy_score(y_test, rf_pred)))
print('결정 트리 정확도: {0:4f}'.format(accuracy_score(y_test, df_pred)))
print('에이다부스트 정확도: {0:4f}'.format(accuracy_score(y_test, ada_pred)))
◆ 개별 알고리즘을부터 예측된 예측값을 칼럼 레벨로 옆으로 붙여서 피처 값으로 만들어, 최종 메타 모델인 로지스틱 회귀에서 학습 데이터로 다시 사용한다.
반환된 예측 데이터 세트는 1차원 형태의 ndarray 이므로 먼저 반환된 예측 결과를 행 형태로 붙인 뒤, 넘파이의 transpose() 를 이용해 행과 열 위치를 바꾼 ndarray로 변환하면 된다.
pred = np.array([knn_pred, rf_pred, df_pred, ada_pred])
print(pred.shape)
# transpose를 이용해 행과 열의 위치 교환. 칼럼 레벨로 각 알고리즘의 예측 결과를 피처로 만듦
pred = np.transpose(pred)
print(pred.shape)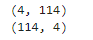
◆ 예측 데이터(pred)로 생성된 데이터 세트를 기반으로 최종 메타 모델인 로지스틱 회귀(Logistic Regression)를 학습하고 예측 정확도를 측정
# 최종 메타 모델 예측 (로지스틱 회귀)
lr_final.fit(pred, y_test)
final = lr_final.predict(pred)
print('최종 메타 모델의 예측 정확도: {0:4f}'.format(accuracy_score(y_test, final)))
개별 모델의 예측 데이터를 스태킹으로 재구성해 최종 메타 모델에서 학습하고 예측한 결과, 정확도가 96.49%가 나왔는데, 보통의 스태킹 기법은 모델 정확도가 개별 모델에 비해 향상되긴하나, 무조건 좋아진다는 보장은 없다.
[스태킹 모델을 향상 시킬 수 있는 방법]
스태킹 기법을 사용했음에도 예측 정확도가 향상되지 않는 이유는 여러 가지가 있을 수 있다. 몇 가지 주요 원인과 해결 방안을 제시한다:
1. 개별 모델의 성능 문제
스태킹 기법에서는 하위 모델들이 각기 다른 패턴을 잘 학습해야 한다. 하지만, 사용된 모델들이 비슷한 성격을 가지거나 성능이 낮으면 메타 모델이 충분한 정보를 얻지 못할 수 있다.
해결 방안: 서로 다른 유형의 모델(예: SVM, XGBoost 등)을 추가하거나 개별 모델의 하이퍼파라미터를 최적화.
2. 메타 모델의 부적절한 선택
최종 메타 모델로 로지스틱 회귀를 사용했는데, 데이터가 선형적으로 분리되지 않는다면 로지스틱 회귀는 좋은 선택이 아닐 수 있다.
해결 방안: 메타 모델을 랜덤포레스트나 XGBoost와 같은 더 복잡한 모델로 교체.
3. 과적합 문제
스태킹에서 개별 모델들이 과적합되면 메타 모델이 이를 반영하여 테스트 성능이 떨어질 수 있다.
해결 방안: 교차 검증을 활용해 각 모델의 과적합을 방지하고, 개별 모델의 규제를 강화하는 것이 좋다.
4. 데이터의 문제
데이터의 품질이나 특성이 문제가 될 수 있다. 예를 들어, 데이터의 편향이나 잡음이 많다면 어떤 기법을 사용해도 성능 개선이 어렵다.
해결 방안: 데이터 전처리를 개선하고, 특성 선택 및 스케일링 재검토.
CV 세트 기반의 스태킹
CV 세트 기반의 스태킹 모델은 과적합을 개선하기 위해 최종 메타 모델을 위한 데이터 세트를 만들 때 교차 검증 기반으로 예측된 결과 데이터 세트를 이용한다.
앞 예제에서 마지막에 메타 모델인 로지스틱 회귀 모델 기반에서 최종 학습할 때 레이블 데이터 세트로 학습 데이터가 아닌 테스트용 레이블 데이터 세트를 기반으로 학습했기에 과적합 문제가 발생할 수 있다.
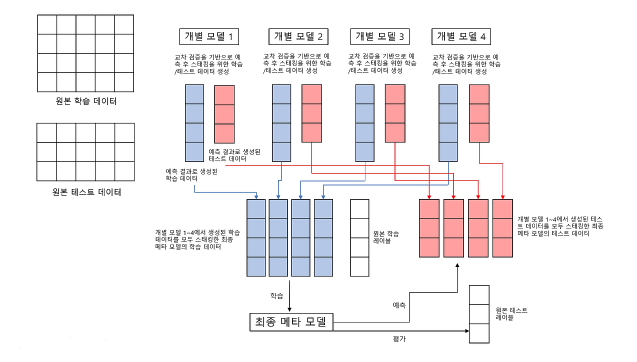
CV 세트 기반의 스태킹은 이에 대한 개선을 위해 개별 모델들이 각각 교차 검증으로 메타 모델을 위한 학습용 스태킹 데이터 생성과 예측을 위한 테스트용 스태킹 데이터를 생성한 뒤 이를 기반으로 메타 모델이 학습과 예측을 수행한다.
이는 다음과 같이 2단계로 구분될 수 있다.
- 1단계: 각 모델별로 원본 학습/데이터를 예측한 결과 값을 기반으로 메타 모델을 위한 학습용/테스트용 데이터를 생성
- 2단계: 1단계에서 개별 모델들이 생성한 학습용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 학습용 데이터 세트를 생성. 마찬가지로 각 모델들이 생성한 테스트용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 예측할 최종 테스트 데이터 세트를 생성. 메타 모델은 최종적으로 생성된 학습 데이터 세트와 원본 학습 데이터의 레이블 데이터를 기반으로 학습한 뒤, 최종적으로 생성된 테스트 데이터 세트를 예측하고, 원본 테스트 데이터의 레이블 데이터를 기반으로 평가한다.
[1단계 상세 설명]
먼저 학습용 데이터를 N개의 폴드(Fold)로 나눈다. 만약 3개라고 가정할 경우, 3개의 폴드세트 이므로 3번의 유사한 반복 작업을 수행하고, 마지막 3번째 반복에서 개별 모델의 예측 값으로 학습 데이터와 테스트 데이터를 생성한다.
1) 학습용 데이터를 3개의 폴드로 나눔 ▶ 2개는 학습용, 1개는 검증용
2) 학습 데이터를 기반으로 개별 모델 학습
3) 학습된 개별 모델은 검증 폴드 1개 데이터로 예측하고 그 결과를 저장
1), 2), 3)의 로직을 3번 반복하되, 학습 데이터와 검증 데이터 세트를 변경해가면서 학습 후 에측 결과를 별도로 저장
▶ 이렇게 만들어진 예측 데이터는 메타 모델을 학습시키는 학습 데이터로 사용된다.
2개의 학습 폴드 데이터로 학습된 개별 모델은 원본 테스트 데이터를 예측하여 예측값을 생성
▶ 이러한 로직을 3번 반복하면서 이 예측값의 평균으로 최종 결괏값을 생성하고 이를 메타 모델을 위한 테스트 데이터로 사용
[2단계 상세 설명]
각 모델들이 1단계에서 생성한 학습과 테스트 데이터를 모두 합쳐서 최종적으로 메타 모델이 사용할 학습 데이터와 테스트 데이터를 생성하기만 하면 된다.
메타 모델이 사용할 최종 학습 데이터와 원본 데이터의 레이블 데이터를 합쳐서 메타 모델을 학습한 후에 최종 테스트 데이터로 예측을 수행한 뒤, 최종 예측 결과를 원본 테스트 데이터의 레이블 데이터와 비교해 평가하면 된다.
코드로 작성해보는 CV 세트 기반의 스태킹
[1단계 구현]
◆ 개별 모델이 메타 모델을 위한 학습용 데이터와 테스트 데이터 생성
- get_stacking_base_datasets() 함수 생성
이 함수에서는 개별 모델의 Classifier 객체, 학습용 피처 데이터(원본), 학습용 레이블 데이터(원본), 테스트 피처 데이터 (원본), K 폴드를 몇 개로 할지를 파라미터로 입력받는다.
함수 내에서는 폴드의 개수만큼 반복을 수행하면서 폴드된 학습용 데이터로 학습한 뒤 예측 결괏값을 기반으로 메타 모델을 위한 학습용 데이터와 테스트용 데이터를 새롭게 생성
#CV 세트 기반의 스태킹
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
#개별 기반 모델에서 최종 메타 모델이 사용할 학습 및 테스트용 데이터를 생성하기 위한 함수
def get_stacking_base_datasets(model, X_train_n, y_train_n, X_test_n, n_folds):
#지정된 n_folds 값으로 KFold 생성
kf = KFold(n_splits=n_folds, shuffle=False)
#추후에 메타 모델이 사용할 학습 데이터 반환을 위한 넘파이 배열 초기화
train_fold_pred = np.zeros((X_train_n.shape[0],1))
test_pred = np.zeros((X_test_n.shape[0], n_folds))
print(model._class_._name_, 'model 시작')
for folder_counter, (train_index, valid_index) in enumerate(kf.split(X_train_n)):
#입력된 학습 데이터에서 기반 모델이 학습/예측할 폴드 데이터 세트 추출
print('\t 폴드 세트: ', folder_counter, '시작')
X_tr = X_train_n[train_index]
y_tr = y_train_n[train_index]
X_te = X_train_n[valid_index]
#폴드 세트 내부에서 다시 만들어진 학습 데이터로 기반 모델의 학습 수행
model.fit(X_tr, y_tr)
#폴드 세트 내부에서 다시 만들어진 검증 데이터로 기반 모델 예측 후 데이터 저장
train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1, 1)
#입력된 원본 테스트 데이터를 폴드 세트내 학습된 기반 모델에서 예측 후 데이터 저장
test_pred[:, folder_counter] = model.predict(X_test_n)
#폴드 세트 내에서 원본 테스트 데이터를 예측한 데이터를 평균하여 테스트 데이터로 생성
test_pred_mean = np.mean(test_pred, axis=1).reshape(-1, 1)
#train_fold_pred는 최종 메타 모델이 사용하는 학습 데이터, test_pred_mean은 테스트 데이터
return train_fold_pred, test_pred_mean
▶ AttributeError: 'KNeighborsClassifier' object has no attribute '_class_' 이라는 오류는 아래의 부분때문에 발생하는데,
print(model._class_._name_, 'model 시작')
scikit-learn의 모델들은 _class_라는 속성을 갖고 있지 않기 때문에, 속성 오류가 발생한 것이다.
모델의 이름을 출력하려면 type(model).__name__을 사용하여 모델 클래스의 이름을 가져와야 하며, 이를 사용하면 모델의 이름을 올바르게 출력할 수 있다.
print(type(model).__name__, 'model 시작')
◆ 여러 개의 분류 모델별로 stack_base_model() 함수 수행
개별 모델은 앞의 기본 스태킹 모델에서 생성한 KNN, 랜덤 포레스트, 결정 트리, 에이다부스트 모델이며, 이들 모델별로 get_stacking_base_datasets() 함수를 호출해 각각 메타 모델이 추후에 사용할 학습용, 테스트용 데이터 세트를 반환
#각각 메타 모델이 추후에 사용할 학습용, 테스트용 데이터 세트 반환
knn_train, knn_test = get_stacking_base_datasets(knn_clf, X_train, y_train, X_test, 7)
rf_train, rf_test = get_stacking_base_datasets(rf_clf, X_train, y_train, X_test, 7)
df_train, df_test = get_stacking_base_datasets(df_clf, X_train, y_train, X_test, 7)
ada_train, ada_test = get_stacking_base_datasets(ada_clf, X_train, y_train, X_test, 7)
[2단계 구현]
앞에서 get_stacking_base_datasets() 호출로 반환된 각 모델별 학습 데이터와 테스트 데이터를 합치기만 하면 된다.
넘파이의 concatenate() 를 이용해 쉽게 수행할 수 있다.
★ concatenate(): 여러 개의 넘파이 배열을 칼럼 도는 로우 레벨로 합쳐주는 기능 제공
#2단계: 각 모델별 학습 데이터와 테스트 데이터 합치기
Stack_final_X_train = np.concatenate((knn_train, rf_train, df_train, ada_train), axis=1)
Stack_final_X_test = np.concatenate((knn_test, rf_test, df_test, ada_test), axis=1)
print('원본 학습 피처 데이터 Shape:', X_train.shape, '원본 테스트 피처 Shape:', X_test.shape)
print('스태킹 학습 피처 데이터 Shape:', Stack_final_X_train.shape,
'스태킹 테스트 피처 데이터 Shape:', Stack_final_X_test.shape)
Stack_final_X_train: 메타 모델이 학습할 학습용 피처 데이터 세트
Stack_final_X_test: 메타 모델이 예측할 테스트용 피처 데이터 세트
스태킹 학습 피처 데이터: 원본 피처 데이터와 로우 크기는 같으며, 4개의 개별 모델 에측값을 합친 것이므로 칼럼 크기는 4.
◆ 최종 메타 모델인 로지스틱 회귀를 스태킹된 학습용 피처 데이터 세트와 원본 학습 레이블 데이터로 학습한 후 스태킹된 테스트 데이터 세트로 예측하고, 예측 결과를 원본 테스트 레이블 데이터와 비교해 정확도 측정
lr_final.fit(Stack_final_X_train, y_train)
stack_final = lr_final.predict(Stack_final_X_test)
print('최종 메타 모델의 예측 정확도: {0:4f}'.format(accuracy_score(y_test, stack_final)))
최종 메타 모델의 예측 정확도는 약 97.36%로 측정되었다.
스태킹을 이루는 모델은 최적으로 파라미터를 튜닝한 상태에서 스태킹 모델을 만드는 것이 일반적이며, 여러 명으로 이뤄진 분석 팀에서 개별적으로 각각 모델을 최적으로 학습시켜서 스태킹 모델을 더 빠르게 최적화할 수 있을 것이다.
일반적으로 스태킹 모델의 파라미터 튜닝은 개별 알고리즘 모델의 파라미터를 최적으로 튜닝하는 것을 말한다.
스캐팅 모델은 분류(Classification) 뿐만 아니라 회귀(Regression)에도 적용 가능하다.
정리
스태킹은 여러 개의 개별 모델들이 생성한 예측 데이터를 기반으로 최종 메타 모델이 학습할 별도의 학습 데이터 세트와 예측할 테스트 데이터 세트를 재 생성하는 기법이다.
스태킹 모델의 핵심은 메타 모델이 사용할 학습 데이터 세트와 예측 데이터 세트를 개별 모델의 예측 값들을 스태킹 형태로 결합해 생성하는 데 있다.
다음 글
[머신러닝] 회귀(Regression)
회귀(Regression) 회귀 분석은 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법이다.회귀는 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기
puppy-foot-it.tistory.com
[출처]
파이썬 머신러닝 완벽 가이드
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 경사 하강법(GD, gradient descent) (3) | 2024.09.22 |
|---|---|
| [머신러닝] 회귀(Regression) (2) | 2024.09.21 |
| [머신러닝] Pytorch 설치하기 (Nvidia GPU 버전) (0) | 2024.09.09 |
| [머신러닝] Intel GPU로 Pytorch 구동하기(는 안할게..) (1) | 2024.09.09 |
| [머신러닝] 머신러닝에 적합한 도구, Pytorch 설치하기(CPU버전) (1) | 2024.09.08 |



