머신러닝 기반 분석 모형 선정
[머신러닝] 머신러닝 기반 분석 모형 선정
머신러닝 기반 분석 모형 선정 지도 학습, 비지도 학습, 강화 학습, 준지도 학습, 전이 학습 1) 지도 학습: 정답인 레이블(Label)이 포함되어 있는 학습 데이터를 통해 컴퓨터를 학습시키는 방법(
puppy-foot-it.tistory.com
회귀(Regression)
회귀 분석은 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법이다.
회귀는 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법을 통칭한다. 예를 들어 집의 방 개수, 방 크기, 주변 학군 등 여러 개의 독립변수에 따라 주택 가격이라는 종속변수가 어떤 관계를 나타내는지를 모델링하고 예측하는 것이다.
머신러닝 관점에서 보면 독립변수는 피처에 해당되며 종속변수는 결정 값이다.
[변수]
| 영향을 주는 변수 | 독립 변수, 설명 변수, 예측 변수 |
| 영향을 받는 변수 | 종속 변수, 반응 변수, 결과 변수 |

머신러닝 회귀 예측의 핵심은 주어진 피처와 결정 값 데이터 기반에서 학습을 통해 최적의 회귀 계수를 찾아내는 것이다.
회귀 모형의 가정
선형성, 독립성, 등분산성, 비상관성, 정상성
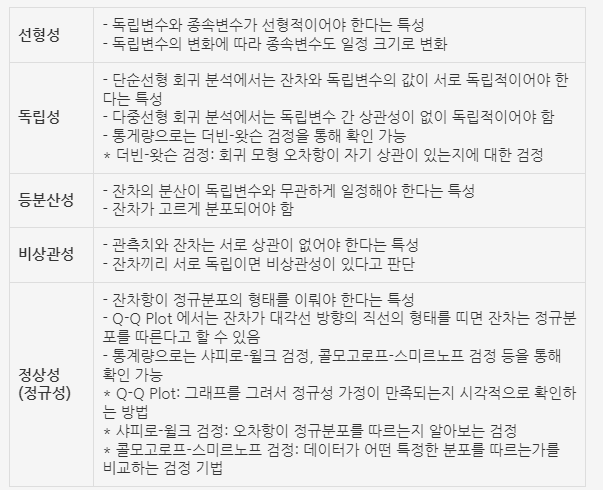
◆ 회귀 모형의 체크리스트
- 회귀 모형이 통계적으로 유의미한가? (F-통계량 통해 확인)
- 회귀 계수들이 유의미한가? (t-통계량 통해 확인)
- 회귀 모형이 얼마나 설명력을 갖는가? (결정계수로 판단)
- 회귀 모형이 데이터를 잘 적합하고 있는가? (잔차를 그래프로 그리고 회귀진단)
- 데이터가 가정을 만족시키는가? (회귀 모형 가정을 만족해야 함)
회귀 유형의 구분
회귀는 회귀 계수의 선형/비선형 여부, 독립변수의 개수, 종속변수의 개수에 따라 여러 가지 유형으로 나눌 수 있으며, 회귀에서 가장 중요한 것은 회귀 계수(regression coefficients) 이다. 이 회귀 계수가 선형이냐 아니냐에 따라 선형 회귀와 비선형 회귀로 나눌 수 있고, 독립변수의 개수가 한 개인지 여러 개인지에 따라 단일 회귀, 다중 회귀로 나뉜다.
<회귀 유형의 구분>
| 독립변수 개수 | 회귀 계수의 결합 |
| 1개: 단일 회귀 | 선형: 선형 회귀 |
| 2개: 다중 회귀 | 비선형: 비선형 회귀 |
지도학습은 두 가지 유형으로 나뉘는데, 바로 분류와 회귀이다.
이 두 가지 기법의 가장 큰 차이는
- 분류: 예측값이 카테고리와 같은 이산형 클래스 값
- 회귀: 예측값이 연속형 숫자 값
여러 가지 회귀 중에서 선형 회귀가 가장 많이 사용되는데, 선형 회귀는 실제 값과 예측값의 차이(오류의 제곱값)를 최소화하는 직선형 회귀선을 최적화하는 방식이다. 선형 회귀 모델은 규제 방법에 따라 다시 별도의 유형으로 나뉠 수 있다.
★ 규제(regularization): 일반적인 선형 회귀의 과적합 문제를 해결하기 위해서 회귀 계수에 패널티 값을 적용하는 것
[회귀 분석 유형]
1) 단순선형 회귀: 독립변수가 1개, 종속변수와의 관계가 직선
2) 다중선형 회귀: 독립변수가 k개, 종속변수와의 관계가 선형 (1차 함수)
3) 다항 회귀: 독립변수와 종속변수와의 관계가 1차 함수 이상인 관계 (독립변수가 1개일 경우에는 2차 함수 이상)
4) 곡선회귀: 독립변수가 1개 이며, 종속변수와의 관계가 곡선
[머신러닝]경사 하강법(GD, gradient descent)
[머신러닝] 회귀 - LinearRegression 클래스
[대표적인 선형 회귀 모델]
1) 일반 선형 회귀: 예측값과 실제 값의 RSS(Residual Sum of Squares)를 최소화할 수 있도록 회귀 계수를 최적화하며, 규제를 적용하지 않은 모델
2) 릿지(Ridge): 선형 회귀에 L2 규제를 추가한 회귀 모델. 릿지 회귀는 L2 규제를 적용하는데, L2 규제는 상대적으로 큰 회귀 계수 값의 예측 영향도를 감소시키기 위해서 회귀 계수값을 더 작게 만드는 규제 모델이다.
3) 라쏘(Lasso): 선형 회귀에 L1 규제를 적용한 방식. L2 규제가 회귀 계수 값의 크기를 줄이는 데 반해, L1 규제는 예측 영향력이 작은 피처의 회귀 계수를 0으로 만들어 회귀 예측 시 피처가 선택되지 않게 하는 것이다. 이러한 특성 때문에 L1 규제는 피처 선택 기능으로도 불린다.
4) 엘라스틱넷: L2, L1 규제를 결합한 모델. 주로 피처가 많은 데이터 세트에서 적용되며, L1 규제로 피처의 개수를 줄임과 동시에 L2 규제로 계수 값의 크기를 조정.
5) 로지스틱회귀: '회귀' 라는 이름이 붙어 있으나, 분류에 사용되는 선형 모델. 로지스틱 회귀는 이진 분류 뿐만 아니라 희소 영역의 분류 (텍스트 분류 등) 영역에서 뛰어난 예측 성능을 보이는 매우 강력한 분류 알고리즘. 종속변수가 범주형인 경우 적용
6) 비선형 회귀: 회귀식의 모양이 미지의 모수들의 선형관계로 이뤄져 있지 않은 모형
[머신러닝] 회귀 - 규제 선형 모델: 릿지, 라쏘, 엘라스틱넷
단순 선형 회귀를 통한 회귀 이해
단순 선형 회귀: 독립변수도 하나, 종속변수도 하나인 선형 회귀.
최적의 회귀 모델을 만든다는 것은 전체 데이터의 잔차 합이 최소가 되는 모델을 만든다는 의미인 동시에 오류 값 합이 최소가 될 수 있는 최적의 회귀 계수를 찾는다는 의미이다.
★ 잔차: 실제 값과 회귀 모델의 차이에 따른 오류 값 (남은 오류). 오류 값은 +나 -가 될 수 있다.
보통 오류 합을 계산할 때는 절댓값을 취해서 더하거나 (Mean Absolute Error), 오류 값의 제곱을 구해서 더하는 방식(RSS, Residual Sum of Square) 값을 취한다. 일반적으로 미분 등의 계산을 편리하게 하기 위해서 RSS 방식으로 오류 합을 구한다.
RSS는 회귀식의 독립변수 X, 종속변수가 중심 변수가 아니라 w 변수(회귀 계수)가 중심 변수임을 인지하는 것이 매우 중요하다.
회귀에서 이 RSS는 비용(Cost)이며 w 변수(회귀 계수)로 구성되는 RSS를 비용 함수라고 한다.
머신러닝 회귀 알고리즘은 데이터를 계속 학습하면서 이 비용 함수가 반환하는 값(오류 값)을 지속해서 감소시키고 최종적으로는 더 이상 감소하지 않는 최소의 오류 값을 구하는 것이다.
비용 함수는 손실 함수(loss function)라고도 한다.
회귀 모형의 평가지표

정리
- 선형 회귀는 실제값과 예측값의 차이인 오류를 최소로 줄일 수 있는 선형 함수를 찾아서 이 선형 함수에 독립변수(피처)를 입력해 종속변수(타깃값, 예측값)를 예측하는 것이다.
- 최적의 선형 함수를 찾기 위해 실제값과 예측값 차이의 제곱을 회귀 계수 W를 변수로 하는 비용 함수로 만들고, 이 비용 함수가 최소화되는 W의 값을 찾아 선형 함수를 도출한다.
- 비용 함수를 최소화할 수 있는 방법으로 경사 하강법이 있다.
- 실제값과 예측값의 차이를 최소화하는 것에만 초점을 맞춘 단순 선형 회귀는 학습 데이터에 과적합되는 문제를 수반할 가능성이 높다.
- 과적합 문제를 해결하기 위해 규제를 도입할 수 있으며, 대표적인 규제 선형 회귀는 L2 규제를 적용한 릿지, L1 규제를 적용한 라쏘, 그리고 L1에 L2 규제를 결합한 엘라스틱넷으로 나누어 진다.
- 로지스틱 회귀는 선형 회귀를 분류에 적용한 대표적인 모델이며, 이름은 회귀이지만 실제로는 분류를 위한 알고리즘이다.
- 로지스틱 회귀는 선형 함수 대신 최적의 시그모이드 함수를 도출하고, 독립변수(피처)를 이 시그모이드 함수에 입력해 반환된 결과를 확률값으로 변환해 예측 레이블을 결정한다.
- 로지스틱 회귀는 매우 뛰어난 분류 알고리즘이며, 특히 이진 분류나 희소 행렬로 표현되는 텍스트 기반의 분류에서 높은 예측 성능을 나타낸다.
- 회귀 트리는 분류를 위해 만들어진 분류 트리와 크게 다르지 않으나, 리프 노드에서 예측 결정 값을 만드는 과정에 차이가 있다.
- 회귀 트리는 리프 노드에 속한 데이터 값의 평균값을 구해 회귀 예측값을 계산한다
- 결정 트리, GBM, XGBoost, LightGBM 모두 회귀 트리를 이용해 회귀를 수행하는 방법을 제공한다
- 선형 회귀는 데이터 값의 분포도가 정규 분포와 같이 종 모양의 형태를 선호하며, 특히 타깃값의 분포도가 왜곡(Skew)되지 않고 정규 분포 형태로 되어야 예측 성능을 저하시키지 않는다.
- 데이터 세트가 왜곡된 데이터 분포도를 가지고 있을 때 일반적으로 로그 변환을 적용하는 것이 유용하다
- 선형 회귀의 경우 데이터 세트에 카테고리형 데이터가 있을 경우 이를 레이블 인코딩을 통한 숫자형 변환보다는 원-핫 인코딩으로 변환해줘야 한다. (회귀 트리의 경우 인코딩 방식에 크게 영향 받지 않음)
- 스태킹 모델을 회귀에 적용해 예측 성능을 향상시킬 수 있다.
[관련 프로젝트]
다음 내용
[머신러닝] 차원 축소(Dimension Reduction)
차원 축소(Dimension Reduction)차원 축소의 중요한 의미는차원 축소를 통해 좀 더 데이터를 잘 설명할 수 있는잠재적인 요소를 추출하는 데 있다.차원 축소: 매우 많은 피처로 구성된 다차원 데이터
puppy-foot-it.tistory.com
[출처]
파이썬 머신러닝 완벽 가이드 - 권철민 저, 위키북스
빅데이터분석기사 필기 - 수제비
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 회귀 - LinearRegression 클래스 (2) | 2024.10.21 |
|---|---|
| [머신러닝] 경사 하강법(GD, gradient descent) (3) | 2024.09.22 |
| [머신러닝] 스태킹 앙상블 (0) | 2024.09.21 |
| [머신러닝] Pytorch 설치하기 (Nvidia GPU 버전) (0) | 2024.09.09 |
| [머신러닝] Intel GPU로 Pytorch 구동하기(는 안할게..) (1) | 2024.09.09 |



