텐서플로

[머신러닝] 텐서플로(TensorFlow)란?
텐서플로(TensorFlow)란? 텐서플로(TensorFlow)는 구글에서 개발한 오픈소스 머신러닝 프레임워크이다. 주로 딥러닝 모델을 만들고 학습시키는 데 사용되며, 다양한 플랫폼에서 실행이 가능하다. 텐
puppy-foot-it.tistory.com
이전 내용
[딥러닝] 텐서플로 함수와 그래프
텐서플로 [머신러닝] 텐서플로(TensorFlow)란?텐서플로(TensorFlow)란? 텐서플로(TensorFlow)는 구글에서 개발한 오픈소스 머신러닝 프레임워크이다. 주로 딥러닝 모델을 만들고 학습시키는 데 사용되
puppy-foot-it.tistory.com
텐서플로를 사용한 데이터 적재와 전처리
◆ tf.data: 텐서플로 자체의 데이터 로드 및 전처리 API
대용량 데이터셋에서 텐서플로 모델을 훈련할 때는 텐서플로 자체의 데이터 로드 및 전처리 API인 tf.data를 사용하는 것이 좋다. 이 API는 매우 효율적으로 데이터를 로드하고 전처리 할 수 있으며, 멀티스레드와 큐를 사용하여 여러 파일에서 동시에 읽고, 샘플을 셔플링하거나 배치로 만드는 등의 작업을 수행할 수 있다.
또한 GPU 또는 TPU가 훈련을 위해 현재 데이터를 빠르게 처리하는 동안 동시에 여러 CPU 코어에 걸쳐 다음 데이터 배치를 로드하고 전처리할 수 있다.
tf.data API를 사용하면 메모리보다 큰 데이터셋을 처리할 수 있으며, 하드웨어 리소스를 최대한 활용할 수 있으므로 훈련 속도가 향상된다. 기본 기능으로 데이터 API는CSV 같은 텍스트 파일, 고정 길이의 레코드를 가진 이진 파일, 텐서플로의 TFRecord 포맷을 사용하는 이진 파일에서 데이터를 읽을 수 있으며, 이 포맷은 길이가 다른 레코드를 지원한다. 또한 데이터 API는 SQL 데이터베이스에서 읽는 기능을 지원하고, 구글 빅쿼리와 같은 다양한 데이터 소스에서 읽을 수 있는 오픈 소스도 있다.
케라스는 모델에 포함시킬 수 있는 강력하면서도 사용하기 쉬운 전처리 층을 제공한다. 이렇게 하면 모델을 제품 호나경에 배포할 때 다른 전처리 코드를 추가할 필요 없이 원시 데이터를 직접 주입할 수 있다. 또한 훈련 중에 사용된 전처리 코드와 제품 환경에서 사용되는 전처리 코드가 달려져 훈련/서빙의 차이를 일으키는 위험을 제거할 수 있다.
서로 다른 프로그래밍 언어로 코딩된 여러 앱에 모델을 배포하는 경우 동일한 전처리 코드를 여러 번 다시 구현할 필요가 없으므로 이런 불일치에 대한 위험도 줄어든다.
전체적인 tf.data API의 중심에는 tf.data.Dataset 개념이 있다. 이는 데이터 항목의 시퀀스를 나타낸다.
일반적으로 디스크에서 데이터를 점진적으로 읽는 데이터셋을 사용한다.
간단히 tf.data.Dataset.from_tensor_slices()를 사용해 간단한 텐서로 데이터셋을 생성해 본다.
X = tf.range(10) #임의의 데이터 텐서
dataset = tf.data.Dataset.from_tensor_slices(X)
dataset
from_tensor_slices() 함수는 텐서를 받아 첫 번째 차원을 따라 X의 각 원소가 아이템으로 표현되는 tf.data.Dataset을 만든다.
이 데이터셋은 텐서 0~9에 해당하는 10개의 아이템을 가진다.
아래와 같이 데이터셋의 아이템을 순회할 수 있다.
dataset = tf.data.Dataset.from_tensor_slices(tf.range(10))
for item in dataset:
print(item)tf.data API는 스트리밍 API로, 데이터셋의 아이템을 매우 효율적으로 반복할 수 있으나, 인덱싱이나 슬라이싱을 위해 설계된 것은 아니다.
데이터셋에는 텐서 튜플, 이름/텐서 쌍의 딕셔너리, 중첩된 튜플과 딕셔너리도 포함될 수 있다. 튜플, 딕셔너리 또는 중첩 구조를 슬라이싱할 때, 데이터셋은 튜플/딕셔너리 구조를 유지하면서 그 안에 포함된 텐서만 슬라이싱한다.
X_nested = {'a': ([1, 2, 3], [4, 5, 6]), 'b': [7, 8, 9]}
dataset = tf.data.Dataset.from_tensor_slices(X_nested)
for item in dataset:
print(item)◆ 연쇄 변환
데이터셋이 준비되면 변환 메서드를 호출하여 여러 종류의 변환을 수행할 수 있다.
dataset = tf.data.Dataset.from_tensor_slices(tf.range(10))
dataset = dataset.repeat(3).batch(7)
for item in dataset:
print(item)▶ 원본 데이터셋에서 repeat() 메서드를 호출하면 원본 데이터셋의 아이템을 세 차례 반복하는 새로운 데이터셋을 반환한다. 그리고 새로운 데이터셋에서 batch() 메서드를 호출하면 다시 새로운 데이터셋이 만들어진다. 이 메서드는 이전 데이터셋의 아이템을 7개씩 그룹으로 묶는다. 마지막으로 마지막 데이터셋의 아이템을 순회한다. 여기서는 batch() 매서드에서 출력된 마지막 배치 크기는 7이 아니라 2인데, batch() 메서드를 drop_remainder=True 로 호출하면 길이가 모자란 마지막 배치를 버리고 모든 배치를 동일한 크기로 맞춘다.
- map() 메서드를 호출하여 아이템을 변환할 수도 있다.
아래 코드는 모든 아이템에 2를 곱하여 새로운 데이터셋을 만든다.
dataset = dataset.map(lambda x: x * 2) # x는 하나의 배치.
for item in dataset:
print(item)map() 메서드를 사용하면 데이터에 어떤 전처리 작업도 적용할 수 있다. map() 메서드에 전달하는 함수는 텐서플로 함수로 변환 가능해야 한다.
- filter() 메서드를 사용하여 데이터셋을 필터링할 수도 있다.
아래 코드는 아이템의 합이 50보다 큰 배치만을 담은 데이터셋을 만든다.
dataset = dataset.filter(lambda x: tf.reduce_sum(x) > 50)
for item in dataset:
print(item)
- take() 메서드는 데이터셋에 있는 몇 개의 아이템만 볼 때 사용한다.
for item in dataset.take(2):
print(item)◆ 데이터 셔플링
경사 하강법은 훈련 세트에 있는 샘플이 독립적이고 동일한 분포일 때 최고의 성능을 발휘하는데, 이렇게 하는 간단한 방법은 suffle() 메서드를 사용하여 샘플을 섞는 것이다. 이 메서드는 먼저 원본 데이터셋의 처음 아이템을 buffer_size 개수만큼 추출하여 버퍼에 채우고, 새로운 아이템이 요청되면 이 버퍼에서 랜덤하게 하나를 꺼내 반환한다. 그리고 원본 데이터셋에서 새로운 아이템을 추출하여 비워진 버퍼를 채우며, 원본 데이터셋의 모든 아이템이 사용될 때까지 반복된다. 그다음엔 버퍼가 비워질 때까지 계속하여 랜덤하게 아이템을 반환한다.
이 메서드를 사용하려면 버퍼 크기를 지정해야 하는데, 버퍼 크기를 충분히 하는 것이 중요하며, 그렇지 않을 경우 셔플링의 효과가 감소한다. 다만 보유한 메모리 크기를 넘지 않아야 하며, 충분한 메모리가 있더라도 버퍼 크기가 데이터셋 크기보다 클 필요는 없다.
프로그램을 실행할 때마다 셔플링되는 순서를 동일하게 만들려면 랜덤 시드를 부여한다.
아래 코드는 정수 0에서 9까지 세 번 반복된 데이터셋을 만든 다음 버퍼 크기 5와 랜덤 시드 42를 사용하여 셔플링하고 배치 크기 7로 나누어 출력한다.
dataset = tf.data.Dataset.range(10).repeat(2)
dataset = dataset.shuffle(buffer_size=4, seed=42).batch(7)
for item in dataset:
print(item)
◆ 여러 파일에서 한 줄씩 번갈아 읽기
먼저 캘리포니아 주택 데이터셋을 로드하고 훈련 세트, 검증 세트, 테스트 세트로 분할 한다.
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(
housing.data, housing.target.reshape(-1, 1), random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_full, y_train_full, random_state=42)
메모리에 맞지 않는 매우 큰 데이터셋의 경우, 일반적으로 먼저 여러 파일로 분할한 다음 텐서플로가 이 파일들을 병렬로 읽도록 한다. 이를 시연하기 위해 주택 데이터셋을 분할하여 20개의 CSV 파일로 저장한다.
# 추가 코드 - 데이터셋을 20개 파일로 분할하여 CSV 파일로 저장합니다.
import numpy as np
from pathlib import Path
def save_to_csv_files(data, name_prefix, header=None, n_parts=10):
housing_dir = Path() / "datasets" / "housing"
housing_dir.mkdir(parents=True, exist_ok=True)
filename_format = "my_{}_{:02d}.csv"
filepaths = []
m = len(data)
chunks = np.array_split(np.arange(m), n_parts)
for file_idx, row_indices in enumerate(chunks):
part_csv = housing_dir / filename_format.format(name_prefix, file_idx)
filepaths.append(str(part_csv))
with open(part_csv, "w") as f:
if header is not None:
f.write(header)
f.write("\n")
for row_idx in row_indices:
f.write(",".join([repr(col) for col in data[row_idx]]))
f.write("\n")
return filepaths
train_data = np.c_[X_train, y_train]
valid_data = np.c_[X_valid, y_valid]
test_data = np.c_[X_test, y_test]
header_cols = housing.feature_names + ["MedianHouseValue"]
header = ",".join(header_cols)
train_filepaths = save_to_csv_files(train_data, "train", header, n_parts=20)
valid_filepaths = save_to_csv_files(valid_data, "valid", header, n_parts=10)
test_filepaths = save_to_csv_files(test_data, "test", header, n_parts=10)
이제 이 CSV 파일 중 하나의 처음 몇 줄을 살펴 본다.
print("".join(open(train_filepaths[0]).readlines()[:4]))
train_filepaths는 훈련 파일 경로를 담은 리스트이다. (이 외에도 valid_filepaths 와 test_filepaths도 있다.)
train_filepaths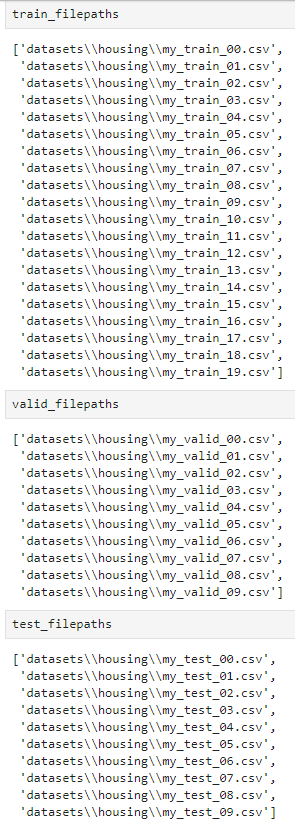
파일 패턴도 사용할 수 있다. 파일 경로가 담긴 데이터셋을 만든다.
filepath_dataset = tf.data.Dataset.list_files(train_filepaths, seed=42)▶ 기본적으로 list_files() 함수는 파일 경로를 섞은 데이터셋을 반환한다.
그다음 interleave() 메서드를 호출하여 한 번에 다섯 개의 파일을 한 줄씩 번갈아 읽는다. 각 파일 첫 번째 줄은 열 이름이므로 skip() 메서드를 사용하여 건너뛴다.
n_readers = 5
dataset = filepath_dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1),
cycle_length=n_readers)▶ interleave() 메서드는 filepath_dataset에 있는 다섯 개의 파일 경로에서 데이터를 읽는 데이터셋을 만든다. 이 메서드에 전달한 함수를 각 파일에 대해 호출하여 새로운 데이터셋(여기서는 TextLineDataset)을 만든다.
인터리브 데이터셋을 반복문에 사용하면 다섯 개의 TextLineDataset을 순회하며, 모든 데이터셋이 아이템이 소진될 때까지 한 번에 한 줄씩 읽는다. 그리고 나서 filepath_dataset에서 다음 다섯 개의 파일 경로를 가져오고 동일한 방식으로 한 줄씩 읽으며, 모든 파일 경로가 소진될 때까지 계속된다.
기본적으로 interleave() 메서드는 병렬화를 사용하지 않으며, 각 파일에서 한 번에 한 줄씩 순서대로 읽는다. 여러 파일에서 병렬로 읽고 싶다면 interleave() 메서드의 num_parallel_calls 매개변수에 원하는 스레드 개수를 지정한다. 이 매개변수를 tf.data.AUTOTUNE으로 지정하면 텐서플로가 가용한 CPU를 기반으로 동적으로 적절한 스레드 개수를 선택할 수 있다.
◆ 데이터 전처리
각 샘플을 바이트 문자열이 담긴 텐서로 반환하는 주택 데이터셋이 있으므로 문자열을 파싱하고 데이터 스케일을 조정하는 등의 전처리가 필요한 데, 이를 위한 사용자 정의 함수 몇 개를 만든다.
# 각 특성의 평균 및 표준 편차 계산
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
# 데이터 전처리 수행위한 사용자 정의 함수 생성
X_mean, X_std = scaler.mean_, scaler.scale_
n_inputs = 8
def parse_csv_line(line):
defs = [0.] * n_inputs + [tf.constant([], dtype=tf.float32)]
fields = tf.io.decode_csv(line, record_defaults=defs)
return tf.stack(fields[:-1]), tf.stack(fields[-1:])
def preprocess(line):
x, y = parse_csv_line(line)
return (x - X_mean) / X_std, y▶ 이 코드는 훈련 세트에 있는 각 특성의 평균과 표준 편차를 계산하고, X_mean과 X_std는 특성마다 1개씩 8개의 실수를 가진 1D 텐서(또는 넘파이 배열)이다. 데이터셋에서 충분히 큰 랜덤 샘플을 추출하여 사이킷런의 StandardScaler로 이를 계산할 수 있다.
- parse_csv_line() 함수: CSV 한 라인을 받아 파싱하는 데, 이를 위해 tf.io_decode_csv() 함수를 사용한다. 이 함수는 파싱할 라인, CSV파일의 각 열에 대한 기본값을 담은 배열 이렇게 두 개의 매개변수를 받는다.
- tf.io_decode_csv() 함수: 열마다 한 개씩 스칼라 텐서의 리스트를 반환한다. 하지만 1D 텐서 배열을 반환해야 하므로 마지막 열을 제외하고 모든 텐서에 대해 tf.stack() 함수를 호출한다. 이 함수는 모든 텐서를 쌓아 1D 배열을 만들고, 그다음 타깃값에도 동일하게 적용한다. 이렇게 하면 스칼라 텐서가 아니라 하나의 값을 가진 1D 텐서가 된다.
- preprocess() 함수: parse_csv_line() 함수를 호출하고, 입력 특성에서 평균을 빼고 표준 편차로 나누어 스케일을 조정한다. 그리고 스케일이 조정된 특성과 타깃을 담은 튜플을 반환한다.
이 전처리 함수를 테스트 해본다.
preprocess(b'4.2083,44.0,5.323204419889502,0.9171270718232044,846.0,2.3370165745856353,37.47,-122.2,2.782')
잘 작동하는 것이 확인된다. (process 괄호 내에 있는 입력 값은 CSV 파일 중 첫 번째 행에 해당하는 여러 값들 중 하나를 임의로 넣은 것이다.)
◆ 데이터 적재와 전처리 합치기
재사용성이 더 높은 코드르 만들기 위해 앞서 진행한 것들을 또 다른 헬퍼 함수로 만든다. 이 함수는 CSV 파일에서 캘리포니아 주택 데이터셋을 효율적으로 적재하고 전처리, 셔플링, 배치를 적용한 데이터셋을 만들어 반환한다.
def csv_reader_dataset(filepaths, n_readers=5, n_read_threads=None,
n_parse_threads=5, shuffle_buffer_size=10_000, seed=42,
batch_size=32):
dataset = tf.data.Dataset.list_files(filepaths, seed=seed)
dataset = dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1),
cycle_length=n_readers, num_parallel_calls=n_read_threads)
dataset = dataset.map(preprocess, num_parallel_calls=n_parse_threads)
dataset = dataset.shuffle(shuffle_buffer_size, seed=seed)
return dataset.batch(batch_size).prefetch(1)
데이터셋에서 생성된 처음 몇 개의 배치를 출력 해본다.
example_set = csv_reader_dataset(train_filepaths, batch_size=3)
for X_batch, y_batch in example_set.take(2):
print("X =", X_batch)
print("y =", y_batch)
print()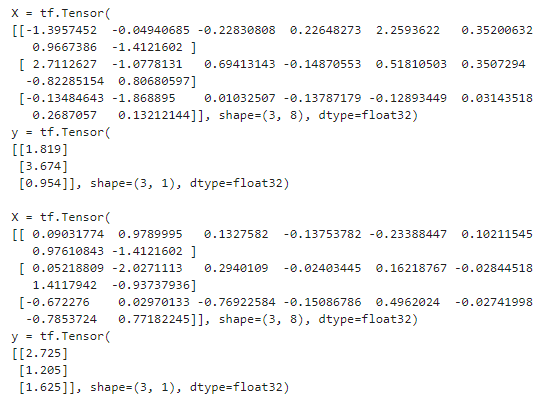
◆ 프리패치(prefetch)
csv_reader_dataset() 함수 마지막에 prefetch(1)을 호출하면 훈련 알고리즘이 한 배치로 작업을 하는 동안 이 데이터셋이 동시에 다음 배치를 준비하며, 이 기능은 성능을 크게 향상시킨다.
멀티스레드로 데이터를 적재하고 전처리하면 여러 개의 CPU 코어를 활용하여 GPU에서 훈련 스텝을 수행하는 것보다 짧은 시간 안에 하나의 배치 데이터를 준비할 수 있다. 이렇게 하면 GPU를 거의 100% 활용할 수 있어 훈련 속도가 더 빨라진다.
즉, 프리페치로 CPU와 GPU를 동시에 사용하여 GPU가 한 배치를 처리할 때 CPU가 다음 배치를 준비한다.
데이터셋이 메모리에 모두 들어갈 수 있을 정도로 작다면 RAM에 모두 캐싱할 수 있는 cache() 메서드를 사용하여 훈련 속도를 크게 높일 수 있다. 일반적으로 데이터를 적재하고 전처리한 후 셔플링, 반복, 배치, 프리페치하기 전에 캐싱을 수행한다. 이렇게 하면 각 샘플을 매 에포크가 아니라 한 번만 읽고 전처리하지만 에포크마다 다르게 셔플링되고 다음 배치도 미리 준비된다.
# tf.data.Dataset 클래스의 모든 메서드
for m in dir(tf.data.Dataset):
if not (m.startswith("_") or m.endswith("_")):
func = getattr(tf.data.Dataset, m)
if hasattr(func, "__doc__"):
print("● {:21s}{}".format(m + "()", func.__doc__.split("\n")[0]))◆ 케라스와 데이터셋 사용하기
앞서 작성한 사용자 정의 csv_reader_dataset() 함수를 사용하여 훈련 세트, 검증 세트, 테스트 세트를 위한 데이터셋을 만들 수 있다. (각 세트는 각 에포크마다 셔플된다.)
train_set = csv_reader_dataset(train_filepaths)
valid_set = csv_reader_dataset(valid_filepaths)
test_set = csv_reader_dataset(test_filepaths)
이제 케라스 모델을 만들고 이 데이터셋으로 훈련할 수 있다.
모델의 fit() 메서드를 호출할 때 X_train, y_train 대신에 train_set을 전달하고,
validation_data=(X_valid, y_valid_ 대신에 validation_data=valid_set 을 전달한다.
model = tf.keras.Sequential([
tf.keras.layers.Dense(30, activation="relu", kernel_initializer="he_normal",
input_shape=X_train.shape[1:]),
tf.keras.layers.Dense(1),
])
model.compile(loss="mse", optimizer="sgd")
model.fit(train_set, validation_data=valid_set, epochs=5)
비슷하게 evaluate()와 predict() 메서드에 데이터셋을 전달할 수 있다.
test_mse = model.evaluate(test_set)
new_set = test_set.take(3) # 새로운 샘플이 3개 있다고 가정
y_pred = model.predict(new_set) # 넘파이 배열도 전달 가능
만약 자신만의 훈련 반복을 만들고 싶다면 그냥 훈련 세트를 반복하면 된다.
# 훈련을 위한 옵티마이저 및 손실 함수 정의.
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
loss_fn = tf.keras.losses.MeanSquaredError()
n_epochs = 5
for epoch in range(n_epochs):
for X_batch, y_batch in train_set:
# 경사 하강법 스텝 하나 수행.
print("\rEpoch {}/{}".format(epoch + 1, n_epochs), end="")
with tf.GradientTape() as tape:
y_pred = model(X_batch)
main_loss = tf.reduce_mean(loss_fn(y_batch, y_pred))
loss = tf.add_n([main_loss] + model.losses)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
한 번의 에포크 동안 모델을 훈련하는 텐서플로 함수를 만들 수도 있으며, 이렇게 하면 훈련 속도가 상당히 높아진다.
@tf.function
def train_one_epoch(model, optimizer, loss_fn, train_set):
for X_batch, y_batch in train_set:
with tf.GradientTape() as tape:
y_pred = model(X_batch)
main_loss = tf.reduce_mean(loss_fn(y_batch, y_pred))
loss = tf.add_n([main_loss] + model.losses)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
loss_fn = tf.keras.losses.MeanSquaredError()
for epoch in range(n_epochs):
print("\rEpoch {}/{}".format(epoch + 1, n_epochs), end="")
train_one_epoch(model, optimizer, loss_fn, train_set)▶ 실제로 수행해보니, 이전 코드보다 수행속도가 훨씬 빠르다.
TFRecord 포맷
TFRecord 포맷: 대용량 데이터를 저장하고 효율적으로 읽기 위해 텐서플로가 선호하는 포맷이다. 이 포맷은 크기가다른 연속된 이진 레코드를 저장하는 단순한 이진 포맷이며, 각 레코드는 레코드 길이, 길이가 올바른지 체크하는 CRC 체크섬, 실제 데이터, 데이터를 위한 CRC 체크섬으로 구성된다.
tf.io.TFRecordWriter 클래스를 사용해 TFRecord를 손쉽게 만들 수 있다.
with tf.io.TFRecordWriter('my_data.tfrecord') as f:
f.write(b'This is the first record')
f.write(b'And this is the second record')
그리고 tf.data.TFRecordDataset을 사용해 하나 이상의 TFRecord를 읽을 수 있다.
filepaths = ['my_data.tfrecord']
dataset = tf.data.TFRecordDataset(filepaths)
for item in dataset:
print(item)
◆ 압축된 TFRecord 파일
네트워크를 통해 읽어야 할 때처럼 TFRecord 파일을 압축해야 할 경우 options 매개변수를 사용하여 압축된 TFRecord 파일을 만들 수 있다.
options = tf.io.TFRecordOptions(compression_type='GZIP')
with tf.io.TFRecordWriter('my_compressed.tfrecord', options) as f:
f.write(b'Compress, compress, compress!')
압축된 TFRecord 파일을 읽으려면 압축 형식을 지정해야 한다.
dataset = tf.data.TFRecordDataset(['my_compressed.tfrecord'],
compression_type='GZIP')◆ 프로토콜 버퍼 개요
각 레코드는 어떤 이진 포맷도 사용할 수 있지만 일반적으로 TFRecord는 직렬화된 프로토콜 버퍼를 담고 있다.
프로토콜 버퍼는 2001년 구글이 개발한 이식성과 확장성이 좋고 효율적인 이진 포맷으로, 2008년에 오픈 소스로 공개되었다.
프로토콜 버퍼는 다음과 같은 간단한 언어를 사용하여 정의된다.
%%writefile person.proto
syntax = "proto3";
message Person {
string name = 1;
int32 id = 2;
repeated string email = 3;
}※ 주의: 언어 중립적인 목적을 달성하기 위해 데이터 타입을 독특한 방식으로 정의하기 때문에, 여느 파이썬 처럼 '#' 주석 넣으면 SyntaxError: invalid syntax 뜬다.
일반적으로 텐서플로에서 사용할 프로토콜 버퍼 정의는 이미 컴파일되어 텐서플로 안에 파이썬 클래스로 포함되어 있다. 따라서 protoc 를 사용할 필요가 없고, 프로토콜 버퍼 정의에 따라 생성된 파이썬 클래스의 사용법을 알아야 하는 것이 전부다.
그리고 컴파일 한다.
!protoc person.proto --python_out=. --descriptor_set_out=person.desc --include_imports%ls person*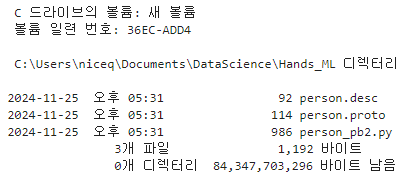
▶%ls 명령은 주피터 노트북에서 사용할 수 있는 마법 명령어로, 현재 작업 디렉토리의 파일 및 디렉토리를 나열하는 명령이다. person*는 파일 이름 패턴을 지정하는 와일드카드 문자로, person으로 시작하는 모든 파일을 나열한다.
즉, %ls person*은 현재 작업 디렉토리에서 person으로 시작하는 모든 파일을 표시한다.
Person 프르토콜 버퍼로 생성된 클래스를 사용하는 간단한 예
from person_pb2 import Person # 생성된 액세스 클래스 가져오기
person = Person(name="Al", id=123, email=["a@b.com"]) # Person 만들기
print(person) # Person 출력
print('이름:', person.name) # 필드 읽기
person.name = 'Alice' # 필드 수정
print('첫번째 이메일:', person.email[0]) # 반복 필드는 배열처럼 참조 가능
person.email.append('c@d.com') # 이메일 주소 추가
serialized = person.SerializeToString() # 바이트 문자열로 객체를 직렬화
print('직렬화:', serialized)
person2 = Person() # 새로운 Person 객체 생성
print('문자열 파싱:', person2.ParseFromString(serialized)) # 길이가 27인 문자열 파싱
print('두 객체 동일한지 여부:', person == person2)
직렬화된 Person 객체를 TFRecord 파일로 저장한 다음 읽고 파싱할 수 있다. 하지만 ParseFromString()은 텐서플로 연산이 아니기 때문에 tf.data 파이프라인 안에 있는 전처리 함수에 포함할 수 없다. 하지만 프로토콜 버퍼 정의만 제공하면 tf.io.decode_proto() 함수를 사용하여 어떤 프로토콜도 파싱할 수 있다.
person_tf = tf.io.decode_proto(
bytes=serialized,
message_type="Person",
field_names=["name", "id", "email"],
output_types=[tf.string, tf.int32, tf.string],
descriptor_source="person.desc")
person_tf.values
하지만 일반적으로 텐서플로가 전용 파싱 연산을 제공하는 사전 정의된 프로토콜 버퍼를 대신 사용하는 것이 좋다.
◆ 텐서플로 프로토콜 버퍼
TFRecord 파일에서 사용하는 전형적인 주요 프로토콜 버퍼는 데이터셋에 있는 하나의 샘플을 표현하는 Example 프로토콜 버퍼이다. 이 프로토콜 버퍼는 이름을 가진 특성의 리스트를 가지고 있으며, 각 특성은 바이트 문자열의 리스트나 실수의 리스트, 정수의 리스트 중 하나이다.
다음은 이 프로토콜 버퍼의 정의이다.
%%writefile Example.proto
syntax = "proto3";
message BytesList { repeated bytes value = 1; }
message FloatList { repeated float value = 1 [packed = true]; }
message Int64List { repeated int64 value = 1 [packed = true]; }
message Feature {
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
message Features { map<string, Feature> feature = 1; };
message Example { Features features = 1; };
아래는 앞서 Person과 동일하게 표현한 tf.train.Example 객체를 만드는 방법이다.
from tensorflow.train import BytesList, FloatList, Int64List
from tensorflow.train import Feature, Features, Example
person_example = Example(
features=Features(
feature={
'name': Feature(bytes_list=BytesList(value=[b'Alice'])),
'id': Feature(int64_list=Int64List(value=[123])),
'emails': Feature(bytes_list=BytesList(value=[b'a@b.com',
b'c@d.com']))
}))
Example 프로토콜 버퍼를 만들었으므로 SerializeToString() 메서드를 호출하여 직렬화하고 결과 데이터를 TFRecord 파일에 저장할 수 있다.
다섯 개의 연락처가 있다고 가정하고 반복해서 저장해본다.
with tf.io.TFRecordWriter('my_contacts.tfrecord') as f:
for _ in range(5):
f.write(person_example.SerializeToString())◆ Example 프로토콜 버퍼 읽고 파싱하기
직렬화된 Example 프로토콜 버퍼를 읽기 위해서 tf.data.TFRecordDataset을 다시 사용하고 tf.io.parse_single_example()로 각 Example을 파싱한다. 이 함수에는 두 개의 매개변수가 필요하다.
- 직렬화된 데이터를 담은 문자열 스칼라 텐서
- 각 특성에 대한 설명: 설명을 각 특성 이름을 특성의 크기, 타입, 기본값을 표현한 tf.io.FixedLenFeature 또는 특성 리스트의 길이가 가변적인 경우 특성의 타입만 표현한 tf.io.VarLenFeature 에 매핑한 딕셔너리이다.
아래 코드는 설명 딕셔너리를 정의한 다음 TFRecordDataset을 만들고 사용자 정의 함수를 적용하여 이 데이터셋에 퐇마된 직렬화된 Example 프로토콜 버퍼를 파싱한다.
feature_description = {
"name": tf.io.FixedLenFeature([], tf.string, default_value=""),
"id": tf.io.FixedLenFeature([], tf.int64, default_value=0),
"emails": tf.io.VarLenFeature(tf.string),
}
def parse(serialized_example):
return tf.io.parse_single_example(serialized_example, feature_description)
dataset = tf.data.TFRecordDataset(["my_contacts.tfrecord"]).map(parse)
for parsed_example in dataset:
print(parsed_example)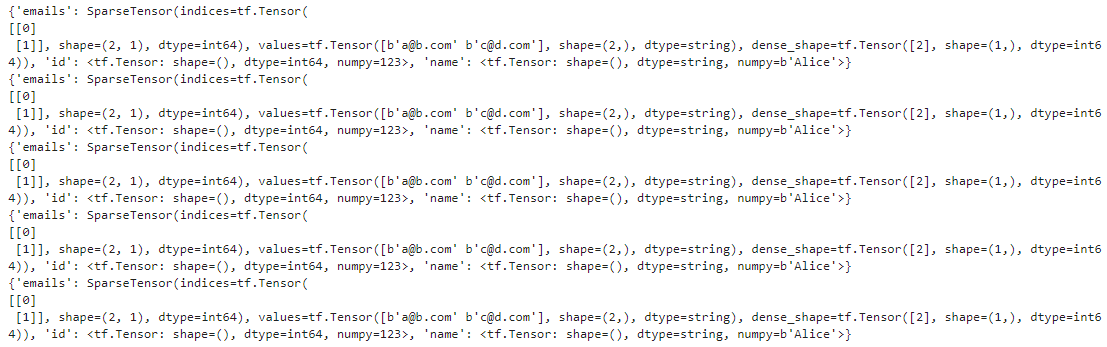
고정 길이 특성은 보통의 텐서로 파싱되지만 가변 길이 특성은 희소 텐서로 파싱된다. tf.sparse.to_dense()로 희소 텐서를 밀집 텐서로 변환할 수 있지만 여기에서는 희소 텐서의 값을 바로 참조하는 것이 더 간단하다.
tf.sparse.to_dense(parsed_example["emails"], default_value=b"")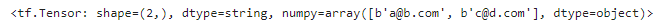
parsed_example["emails"].values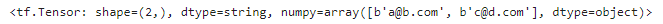
tf.io.parse_single_example()로 하나씩 파싱하는 대신 tf.io.parse_example()을 사용하여 배치 단위로 파싱할 수 있다.
def parse(serialized_examples):
return tf.io.parse_example(serialized_examples, feature_description)
dataset = tf.data.TFRecordDataset(['my_contacts.tfrecord']).batch(2).map(parse)
for parsed_examples in dataset:
print(parsed_examples) # 한번에 두 개의 Example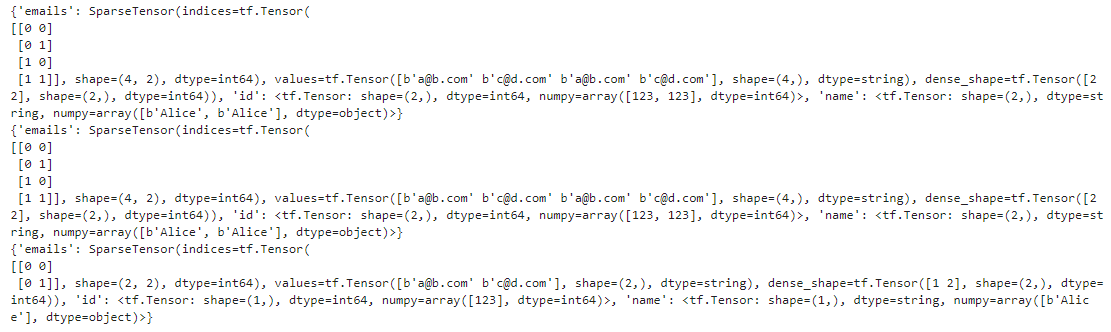
◆ 이미지와 텐서를 TFRecord에 저장하기
ByteList는 직렬화된 객체를 포함해 원하는 어떤 이진 데이터도 포함할 수 있다.
예를 들어 tf.io.encode_jpeg()를 사용해 JPEG 포맷 이미지를 인코딩하고 이 이진 데이터를 ByteList에 넣을 수 있다.
예제 이미지를 로드하고 표시
import matplotlib.pyplot as plt
from sklearn.datasets import load_sample_images
img = load_sample_images()["images"][0]
plt.imshow(img)
plt.axis("off")
plt.title("Original Image")
plt.show()
JPEG로 인코딩된 이미지가 포함된 Example 프로토버프 생성
data = tf.io.encode_jpeg(img)
example_with_image = Example(features=Features(feature={
"image": Feature(bytes_list=BytesList(value=[data.numpy()]))}))
serialized_example = example_with_image.SerializeToString()
with tf.io.TFRecordWriter("my_image.tfrecord") as f:
f.write(serialized_example)
마지막으로, 이 TFRecord 파일을 읽고, 각 Example 프로토콜 버퍼(이 경우 하나만)를 파싱하고, 예제에 포함된 이미지를 파싱하여 표시하는 tf.data 파이프라인을 생성해 본다.
feature_description = { "image": tf.io.VarLenFeature(tf.string) }
def parse(serialized_example):
example_with_image = tf.io.parse_single_example(serialized_example,
feature_description)
return tf.io.decode_jpeg(example_with_image["image"].values[0])
# 또는 tf.io.decode_image()를 대신 사용할 수 있다.
dataset = tf.data.TFRecordDataset("my_image.tfrecord").map(parse)
for image in dataset:
plt.imshow(image)
plt.axis("off")
plt.show()
Example 프로토콜 버퍼는 매우 유연하기 때문에 대부분의 경우 이 정도로 충분하나, 리스트의 리스트를 다룰 때는 사용하기 어렵다. 이런 경우를 위해 텐서플로의 SequenceExample이 고안되었다.
◆ SequenceExample 프로토콜 버퍼로 리스트의 리스트 다루기
앞서 말했듯, Example 프로토콜 버퍼는 리스트의 리스트를 다룰 때는 프로토콜 버퍼의 구조적 한계와 제약 사항 때문에 사용하기 어렵다. 구체적인 이유는 아래와 같다.
1. 중첩 구조 제한
Example 프로토콜 버퍼는 다음과 같은 간단한 필드를 지원한다:
- bytes_list: 바이트 데이터(문자열 포함)의 리스트
- float_list: 부동 소수점 수치의 리스트
- int64_list: 64비트 정수의 리스트
하지만 이 필드들은 기본적으로 단일 리스트를 지원하며, 중첩된 리스트(리스트의 리스트)는 직접적으로 지원하지 않는다.
이는 다음과 같은 구조를 다루기 어렵게 만든다:
nested_list = [[1, 2, 3], [4, 5], [6]]
2. 구조적 정의의 어려움
Example 프로토콜 버퍼의 정의는 단순 필드 타입을 위한 명확한 지원이 있지만, 중첩된 리스트의 경우 이를 표현할 수 있는 명확한 방법이 없다. 예를 들어 중첩된 리스트는 단일 필드에 값을 저장할 때 리스트의 경계를 유지하기 어렵게 만든다.
★ SequenceExample
SequenceExample은 TensorFlow의 텐서플로우 프로토콜 버퍼에서 시퀀스 데이터를 다루기 위한 특수 데이터 구조이다. 이 구조는 Example 프로토콜 버퍼가 단일 데이터 포인트를 표현하는 데 적합한 반면, SequenceExample은 다양한 길이의 시퀀스를 포함하는 데이터를 표현하는 데 유용하다. 이러한 시퀀스 데이터는 자연어 처리, 시계열 데이터 분석, 동영상 처리 등 다양한 응용 분야에서 자주 사용된다.
- SequenceExample 구조
SequenceExample은 두 가지 종류의 특징(features)을 포함한다:
- Context 특징: 시퀀스 전체에 대해 일정한 정보를 포함한다. 즉, 시퀀스의 모든 요소에 공통적인 정보를 포함하는 특징이다.
- Feature Lists: 시퀀스의 각 요소에 대한 정보를 포함한다. 즉, 시퀀스 내의 개별 요소에 대한 정보를 나열한다.
다음은 SequnceExample 프로토콜 버퍼의 정의이다.
%%writefile SequnceExample.proto
syntax = "proto3";
message FeatureList { repeated Feature feature = 1; };
message FeatureLists { map<string, FeatureList> feature_list = 1; };
message SequenceExample {
Features context = 1;
FeatureLists feature_lists = 2;
};
SequenceExample은 문맥 데이터를 위한 하나의 Features 객체와 이름이 있는 한 개 이상의 FeatureList를 가진 FeatureLists 객체를 포함한다. 각 FeatureList는 Feature 객체의 리스트를 포함하고 있다. Feature 객체는 바이트 문자열의 리스트나 64비트 정수의 리스트, 실수의 리스트일 수 있다.
from tensorflow.train import FeatureList, FeatureLists, SequenceExample
context = Features(feature={
"author_id": Feature(int64_list=Int64List(value=[123])),
"title": Feature(bytes_list=BytesList(value=[b"A", b"desert", b"place", b"."])),
"pub_date": Feature(int64_list=Int64List(value=[1623, 12, 25]))
})
content = [["When", "shall", "we", "three", "meet", "again", "?"],
["In", "thunder", ",", "lightning", ",", "or", "in", "rain", "?"]]
comments = [["When", "the", "hurlyburly", "'s", "done", "."],
["When", "the", "battle", "'s", "lost", "and", "won", "."]]
def words_to_feature(words):
return Feature(bytes_list=BytesList(value=[word.encode("utf-8")
for word in words]))
content_features = [words_to_feature(sentence) for sentence in content]
comments_features = [words_to_feature(comment) for comment in comments]
sequence_example = SequenceExample(
context=context,
feature_lists=FeatureLists(feature_list={
"content": FeatureList(feature=content_features),
"comments": FeatureList(feature=comments_features)
}))
sequence_examplecontext {
feature {
key: "author_id"
value {
int64_list {
value: 123
}
}
}
feature {
key: "pub_date"
value {
int64_list {
value: 1623
value: 12
value: 25
}
}
}
feature {
key: "title"
value {
bytes_list {
value: "A"
value: "desert"
value: "place"
value: "."
}
}
}
}
feature_lists {
feature_list {
key: "comments"
value {
feature {
bytes_list {
value: "When"
value: "the"
value: "hurlyburly"
value: "\'s"
value: "done"
value: "."
}
}
feature {
bytes_list {
value: "When"
value: "the"
value: "battle"
value: "\'s"
value: "lost"
value: "and"
value: "won"
value: "."
}
}
}
}
feature_list {
key: "content"
value {
feature {
bytes_list {
value: "When"
value: "shall"
value: "we"
value: "three"
value: "meet"
value: "again"
value: "?"
}
}
feature {
bytes_list {
value: "In"
value: "thunder"
value: ","
value: "lightning"
value: ","
value: "or"
value: "in"
value: "rain"
value: "?"
}
}
}
}
}serialized_sequence_example = sequence_example.SerializeToString()context_feature_descriptions = {
"author_id": tf.io.FixedLenFeature([], tf.int64, default_value=0),
"title": tf.io.VarLenFeature(tf.string),
"pub_date": tf.io.FixedLenFeature([3], tf.int64, default_value=[0, 0, 0]),
}
sequence_feature_descriptions = {
"content": tf.io.VarLenFeature(tf.string),
"comments": tf.io.VarLenFeature(tf.string),
}parsed_context, parsed_feature_lists = tf.io.parse_single_sequence_example(
serialized_sequence_example, context_feature_descriptions,
sequence_feature_descriptions)
parsed_content = tf.RaggedTensor.from_sparse(parsed_feature_lists["content"])
parsed_context
SequenceExample을 만들고 직렬화하고 파싱하는 것은 Example을 만들고 직렬화하고 파싱하는 것과 비슷하나, 하나의 SequenceExample을 파싱하려면 tf.io.parse_single_sequence_example()을 사용하고 배치를 파싱하려면 tf.io.parse_sequence_example()을 사용해야 한다. 두 함수는 모두 문맥 특성과 특성 리스트를 담은 튜플을 반환한다. 특성 리스트가 가변 길이의 시퀀스를 담고 있다면 tf.RaggedTensor.from_sparse()를 사용해 래그드 텐서로 바꿀 수 있다.
print(tf.RaggedTensor.from_sparse(parsed_feature_lists["content"]))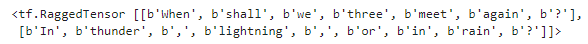
다음 내용
[딥러닝] 케라스의 전처리 층
텐서플로 [머신러닝] 텐서플로(TensorFlow)란?텐서플로(TensorFlow)란? 텐서플로(TensorFlow)는 구글에서 개발한 오픈소스 머신러닝 프레임워크이다. 주로 딥러닝 모델을 만들고 학습시키는 데 사용되
puppy-foot-it.tistory.com
[출처]
핸즈 온 머신러닝
'[파이썬 Projects] > <파이썬 딥러닝, 신경망>' 카테고리의 다른 글
| [딥러닝] 케라스의 전처리 층 (0) | 2024.11.26 |
|---|---|
| [딥러닝] 심층 신경망 훈련 - 4 (1) | 2024.11.26 |
| [딥러닝] 텐서플로 함수와 그래프 (0) | 2024.11.25 |
| [딥러닝] 심층 신경망 훈련 - 3 (1) | 2024.11.25 |
| [딥러닝] 텐서플로를 사용한 사용자 정의 모델과 훈련 (0) | 2024.11.24 |


