이전 내용
[딥러닝] 텐서플로 데이터셋 프로젝트
텐서플로 [머신러닝] 텐서플로(TensorFlow)란?텐서플로(TensorFlow)란? 텐서플로(TensorFlow)는 구글에서 개발한 오픈소스 머신러닝 프레임워크이다. 주로 딥러닝 모델을 만들고 학습시키는 데 사용되
puppy-foot-it.tistory.com
합성곱 신경망(CNN, convolutional neural network)
합성곱 신경망은 대뇌의 시각 피질 연구에서 시작되었고 1980년대부터 컴퓨터 이미지 인식 분야에 사용되었다. 이 기술은 이미지 검색 서비스, 자율 주행 자동차, 영상 자동 분류 시스템 등에 큰 기여를 했다. CNN은 시각 분야에 국한되지 않고 음성 인식이나 자연어 처리 같은 다른 작업에도 많이 사용된다.
CNN의 가장 중요한 구성 요소는 합성곱 층(convolutional layer)이다. 첫 번째 합성곱 층의 뉴런은 입력 이미지의 모든 픽셀에 연결되는 것이 아니라 합성곱 층 뉴런의 수용장 안에 있는 픽셀에만 연결된다. 두 번째 합성곱 층에 있는 각 뉴런은 첫 번째 층의 작은 사각 영역 안에 위치한 뉴런에 연결된다. 이런 구조는 네트워크가 첫 번째 은닉 층에서는 작은 저수준 특성에 집중하고, 그다음 은닉 층에서는 더 큰 고수준 특성으로 조합해 나가도록 도와준다. 이런 계층적 구조는 실제 이미지에서 흔히 볼 수 있으며, CNN이 이미지 인식에 잘 작동하는 이유이기도 하다.
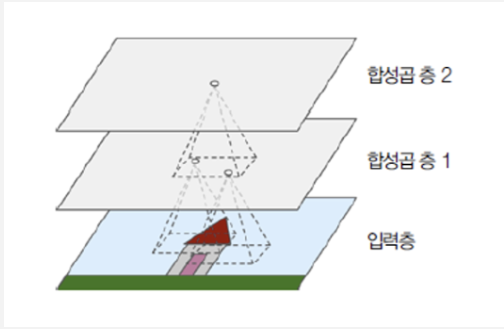
◆ 필터(Filter), 스트라이드(Strides), 패딩(Padding)
- 필터(Filter): 합성곱 신경망(Convolutional Neural Networks, CNN)에서 기본적인 요소 중 하나이다. 필터는 주로 커널(Kernel)이라고도 불리며, 입력 데이터에 대해 합성곱 연산을 수행하여 특징 맵(Feature Map)을 추출한다.
- 구조: 필터는 보통 작은 고정 크기의 행렬로 구성된다. 예를 들면, 3x3, 5x5 크기의 행렬이다.
- 가중치: 필터는 학습 과정 중에 업데이트 되는 가중치(Weights)를 가지고 있다. 이 가중치는 중요한 특징들을 학습하여 검출할 수 있도록 도와준다.
- 역할: 필터는 입력 이미지 또는 데이터에 대하여 지역적으로 적용되어 그 부분의 특징을 추출한다. 각각의 필터는 특정한 패턴이나 특징(예: 가장자리, 색상 변화 등)을 감지하기 위한 목적으로 사용된다.
※ 합성곱 연산 (Convolution Operation)
합성곱 연산은 필터를 입력 데이터 위에 놓고, 위에서부터 아래, 왼쪽에서 오른쪽으로 이동시키며(Stride에 따라), 필터와 입력 데이터 간의 점곱(Dot Product)을 계산하는 과정.
- 스트라이드 (Strides): 필터(kernel)가 입력 데이터를 이동하는 간격을 의미한다.
- 기본값: 일반적으로 1이 기본값이며, 이는 필터가 한 번에 1 픽셀씩 이동하는 것을 의미.
- 높은 스트라이드 값: 스트라이드 값이 증가하면, 필터가 더 큰 간격으로 이동하게 되어 출력 크기가 줄어듦.
예를 들어, 스트라이드 값이 2이면 필터는 두 번째 픽셀마다 뛰어넘어 계산을 수행한다. 이는 출력 공간의 축소를 보다 급격하게 만들어주며, 연산량을 줄이는 데 유용할 수 있다.
- 패딩 (Padding): 합성곱 연산을 수행하기 전에 입력 데이터 주변에 특정 값을 추가하여 크기를 늘리는 과정이다.
주요 목적:
- 출력 크기의 제어: 패딩을 사용하여 출력 크기를 일정하게 유지하거나 원하는 크기로 만들 수 있다.
- 정보 보존: 입력 경계 근처의 정보 손실을 방지하기 위해 사용될 수 있다.
종류:
- Valid Padding (패딩 없음): 입력 데이터의 원래 값을 유지하여 합성곱 연산 수행 후 크기가 줄어든다. 패딩을 하지 않기 때문에 'valid'라고 불린다.
- Same Padding (제로 패딩): 입력과 동일한 크기의 출력을 유지하기 위해 가장 흔히 사용되는 패딩 방법이다. 입력 데이터 주위에 0 값을 추가하여 연산 후 출력을 입력과 같은 크기로 만들어준다.
케라스로 합성곱 층 구현하기
먼저 사이킷런의 load_sample_image() 함수로 몇 개의 샘플 이미지를 로드하고 케라스 CenterCrop과 Rescaling 층으로 전처리 해본다.
from sklearn.datasets import load_sample_images
import tensorflow as tf
images = load_sample_images()['images']
images = tf.keras.layers.CenterCrop(height=70, width=120)(images)
images = tf.keras.layers.Rescaling(scale=1 / 255)(images)
# images 텐서 크기 확인
images.shape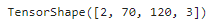
▶ 4D 텐서이다.
- 첫 번째 차원 (2): 두 개의 샘플 이미지가 있음을 의미
- 두 번째, 세 번째 차원 (70, 120): 이미지의 크기로, 각 이미지는 70 * 120을 의미. (CenterCrop 층을 만들 때 지정)
- 네 번째 차원 (3) : 채널 수. 각 픽셀은 컬러 채널 당 하나의 값을 가지며, 빨강, 초록, 파랑 세 개의 채널이 있으므로 3.
2D 합성곱 층을 만들고 이런 이미지를 주입하여 어떤 값이 출력되는지 확인해본다. 이를 위해 케라스는 Convolution2D (또는 Conv2D) 층을 제공하며, 내부적으로 이 층은 텐서플로의 tf.nn.conv2d() 연산을 사용한다.
tf.random.set_seed(42) # 재현성 보장
conv_layer = tf.keras.layers.Conv2D(filters=32, kernel_size=7)
fmaps = conv_layer(images)
fmaps.shape▶ Conv2D(filters=32, kernel_size=7)은 크기가 7*7인 필터 32개로 구성된 합성곱 층을 의미한다.
이 층을 두 개의 이미지로 구성된 작은 배치에 적용해본다.
conv_layer = tf.keras.layers.Conv2D(filters=32, kernel_size=7)
fmaps = conv_layer(images)
# 출력의 크기 확인
fmaps.shape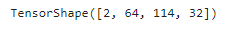
▶ filters=32 라고 지정했기 때문에, 채널 개수는 32 (마지막 차원)
padding='same' 이라 지정하면 출력 특성 맵이 입력과 같은 크기가 되도록 입력 가장자리에 충분한 패딩이 추가된다.
conv_layer = tf.keras.layers.Conv2D(filters=32, kernel_size=7, padding='same')
fmaps = conv_layer(images)
# 출력의 크기 확인
fmaps.shape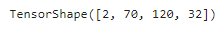
스트라이드가 1보다 크면 padding='same'으로 지정해도 출력 크기가 입력 크기와 같지 않게 된다.
conv_layer = tf.keras.layers.Conv2D(filters=32, kernel_size=7, padding='same',
strides=2)
fmaps = conv_layer(images)
# 출력의 크기 확인
fmaps.shape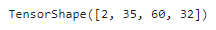
Dense 층과 마찬가지로 Conv2D 층은 커널과 편향을 포함해 모든 가중치를 가지고 있다. 커널은 랜덤하게 초기화되고 편향은 0으로 초기화된다. 이런 가중치는 weigths 속성을 통해 텐서플로 변수나 get_weights() 함수를 통해 넘파이 배열로 참조할 수 있다.
kernels, biases = conv_layer.get_weights()
print(kernels.shape)
print(biases.shape)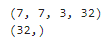
▶ kernels 배열은 4D 이고 크기는 [kernel_height, kernel_width, input_channels, output_channels] 이다.
biases 배열은 1D이고 크기는 [output_channels] 이다.
출력 채널의 개수는 출력 특성 맵의 개수, 필터의 개수와도 같다.
Conv2D 층을 만들 때 일반적으로 ReLU와 같은 활성화 함수와 He 초기화 같은 커널 초기화 방법을 지정한다. Dense 층과 마찬가지로 합성곱 층은 선형 연산을 수행하기 때문에 활성화 함수 없이 여러 개의 합성곱 층을 쌓아도 하나의 합성곱 층과 동일하며 복잡한 것을 학습할 수 없게 된다.
합성곱 층에는 filters, kernel_size, padding, strides, activation, kernel_initializer 등 여러 개의 하이퍼 파라미터가 있다.
CNN애 관련된 다른 문제는 합성곱 층이 많은 양의 RAM을 필요로 한다는 점인데, 특히 훈련하는 동안에 역전파 알고리즘이 역방향 계산을 할 때 정방향에서 계산했던 모든 중간 값을 필요로 한다.
만약 메모리 부족으로 훈련이 실패한다면 미니배치 크기를 줄여보거나, 스트라이드를 사용해 차원을 줄이거나 몇 개의 층을 제거할 수 있다. 아니면 32비트 부동소수 대신 16비트 부동소수를 사용할 수 있고, 여러 장치에 CNN을 분산시킬 수도 있다.
풀링 층
합성곱 신경망(Convolutional Neural Networks, CNN)에서 풀링(Pooling) 층은 중요한 구성 요소 중 하나이다. 풀링 층은 특징 맵(Feature Map)의 특정 정보를 요약 및 축소하여 중요한 특성을 유지하면서 데이터의 크기를 줄이는 역할을 한다.
◆ 풀링(Pooling)의 개념
풀링 층은 입력 데이터(주로 특징 맵)의 크기를 줄여 연산량을 감소시키고, 모델의 과적합을 방지하며, 주요 특성을 추출한다. 풀링에는 여러 종류가 있지만 가장 일반적인 두 가지 방법은 최대 풀링(Max Pooling)과 평균 풀링(Average Pooling)이다.
1. 최대 풀링 (Max Pooling)
최대 풀링은 풀링 창 내의 최대 값을 선택하여 특징 맵의 크기를 줄인다. 이 방법은 이미지나 데이터에서 가장 중요한 특징을 추출하는 데 효과적이다.
- 동작 원리:
- 특정 크기의 풀링 창(예: 2x2, 3x3)을 정의.
- 이를 입력 데이터 위에 스트라이드 값을 기준으로 이동시키며, 각 창 내의 최대 값을 선택.
- 선택된 최대값들로 새로운 축소된 특징 맵을 생성.
- 예시: 2x2 풀링 창, 스트라이드 2의 경우
입력 데이터 (4x4):
1 3 2 4
5 6 1 2
7 8 9 0
3 2 1 4
최대 풀링 결과 (2x2):
6 4
8 9
2. 평균 풀링 (Average Pooling)
평균 풀링은 풀링 창 내의 모든 값들의 평균을 계산하여 특징 맵의 크기를 줄인다. 이 방법은 입력 데이터의 정보가 손실되지 않도록 하면서도 크기를 줄이는 데 유용하다.
- 동작 원리:
특정 크기의 풀링 창(예: 2x2, 3x3)을 정의.
이를 입력 데이터 위에 스트라이드 값을 기준으로 이동시키며, 각 창 내의 값들의 평균 계산.
계산된 평균값들로 새로운 축소된 특징 맵을 생성.
- 예시: 2x2 풀링 창, 스트라이드 2의 경우
입력 데이터 (4x4):
1 3 2 4
5 6 1 2
7 8 9 0
3 2 1 4
- 평균 풀링 결과 (2x2):
3.75 2.25
5.0 3.5
풀링의 주요 장점
- 크기 축소: 풀링을 통해 특징 맵의 크기를 줄여 모델의 연산량을 줄일 수 있다.
- 위치 불변성: 풀링은 위치 변화에 대한 불변성을 제공한다. 예를 들어, 이미지가 약간 변더라도 주요 특징은 보존된다.
- 과적합 방지: 데이터의 크기를 줄이고 중요한 특징만을 추출함으로써 모델의 과적합을 방지하는 데 도움을 준다.
케라스로 풀링 층 구현하기
최대 풀링 층
아래 코드는 MaxPooling2D (또는 MaxPool2D)를 사용해 2*2 커널을 사용하는 풀링층을 만든다.
max_pool = tf.keras.layers.MaxPool2D(pool_size=2)스트라이드의 기본값은 커널 크기이므로 이 층은 수평과 수직 모두 스트라이드 2를 사용하며, 기본적으로 'valid' 패딩 즉, 패딩을 하지 않는다.
평균 풀링 층을 만들려면 MaxPool2D 대신 AveragePooling2D (또는 AvgPool2D)를 사용하는 데, 이 층은 최댓값이 아닌 평균을 계산하는 것만 빼면 최대 풀링 층과 동일하게 작동한다.
평균 풀링 층이 잘 알려져 있으나 최대 풀링 층이 보통 성능이 더 좋아서 대부분 최대 풀링 층을 사용한다.
- 평균 풀링: 최댓값을 계산하는 것보다 정보 손실 적음
- 최대 풀링: 의미 없는 것은 모두 제거하고 가장 큰 특징만을 유지해 다음 층이 조금 더 명확한 신호로 작업 가능. 또한, 평균 풀링보다 강력한 이동 불변성을 제공하고 연산 비용이 조금 덜 듦.
최대 풀링과 평균 풀링은 공간 차원이 아니라 깊이 차원으로 수행될 수 있는데, 이를 통해 CNN이 다양한 특성에 대한 불변성을 학습할 수 있다. 케라스는 깊이 방향 최대 풀링 층을 제공하지 않지만 사용자 정의 층으로 구현할 수 있다.
class DepthPool(tf.keras.layers.Layer):
def __init__(self, pool_size=2, **kwargs):
super().__init__(**kwargs)
self.pool_size = pool_size
def call(self, inputs):
shape = tf.shape(inputs) # shape[-1]는 채널 개수.
groups = shape[-1] // self.pool_size # 채널 그룹 수
new_shape = tf.concat([shape[:-1], [groups, self.pool_size]], axis=0)
return tf.reduce_max(tf.reshape(inputs, new_shape), axis=-1)
이 층은 입력의 채널을 원하는 크기(pool_size)의 그룹으로 나누고, tf.reduce_max()를 사용해 각 그룹의 최댓값을 계산한다.
전역 평균 풀링 층의 작동 방식은 최대 풀링 층, 평균 풀링 층과 매우 다른 데, 이 층에서는 각 특성 맵의 평균을 계산한다. 이는 각 샘플의 특성 맵마다 하나의 숫자를 출력한다는 의미이며, 출력 층 직전에 유용하게 쓰인다.
이런 층을 만들려면 GlobalAveragePooling2D 클래스 (또는 GlobalAvgPool2D) 를 사용한다.
global_avg_pool = tf.keras.layers.GlobalAvgPool2D()
이는 공간 방향(높이와 너비)을 따라 평균을 계산하는 Lambda 층과 동등하다.
global_avg_pool = tf.keras.layers.Lambda(
lambda X: tf.reduce_mean(X, axis=[1, 2]))
예를 들어 이 층에 입력 이미지를 적용하면 각 이미지의 빨강, 초록, 파랑 색의 평균 강도를 얻는다.
global_avg_pool(images)
CNN 구조
CNN 구조와 이미지넷 대회에서 우승한 모델들 관련 내용
[CNN 구조] 합성곱 신경망을 사용한 컴퓨터 비전
CNN 구조 전형적인 CNN 구조는 합성곱 층을 몇 개 쌓고(각각 ReLU 층을 그 뒤에 놓고), 그 다음에 풀링 층을 쌓고, 그 다음에 또 합성곱 층을 몇 개 더 쌓고, 그 다음에 다시 풀링 층을 쌓는 식이다.네
puppy-foot-it.tistory.com
패션 MNIST 데이터셋 문제를 해결하기 위한 기본적인 CNN
from functools import partial
DefaultConv2D = partial(tf.keras.layers.Conv2D, kernel_size=3, padding='same',
activation='relu', kernel_initializer='he_normal')
model = tf.keras.Sequential([
DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]),
tf.keras.layers.MaxPool2D(),
DefaultConv2D(filters=128),
DefaultConv2D(filters=128),
tf.keras.layers.MaxPool2D(),
DefaultConv2D(filters=256),
DefaultConv2D(filters=256),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=128, activation='relu',
kernel_initializer='he_normal'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=64, activation='relu',
kernel_initializer='he_normal'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=10, activation='softmax')
])
[코드 설명]
- DefaultConv2D라는 변수를 정의하여 기본적인 Conv2D(2차원 합성곱) 층을 미리 설정해둔다. 이를 통해 각 합성곱 층을 설정할 때 반복적인 파라미터 지정을 생략할 수 있다.
- 모델의 층을 Sequential API를 사용해 순차적으로 쌓아나간다.
- DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]): 첫 번째 합성곱 층, 필터의 수는 64개, 필터 크기는 7x7이며, 입력 모양은 28x28 크기의 흑백 이미지(채널 수 1)이다.
- tf.keras.layers.MaxPool2D(): 최대 풀링 층, 공간 차원을 절반으로 줄인다.
- DefaultConv2D(filters=128): 128개의 필터를 갖는 두 번째 합성곱 층 (기본 설정 유지)
- DefaultConv2D(filters=128): 128개의 필터를 갖는 세 번째 합성곱 층 (기본 설정 유지)
- tf.keras.layers.MaxPool2D(): 최대 풀링 층, 공간 차원을 다시 절반으로 줄인다.
- DefaultConv2D(filters=256): 256개의 필터를 갖는 네 번째 합성곱 층 (기본 설정 유지)
- DefaultConv2D(filters=256): 256개의 필터를 갖는 다섯 번째 합성곱 층 (기본 설정 유지)
- tf.keras.layers.MaxPool2D(): 최대 풀링 층, 공간 차원을 다시 절반으로 줄인다.
- tf.keras.layers.Flatten(): 2D 데이터를 1D로 변환하여 완전 연결층(Dense layer)에 입력될 수 있도록 한다.
- tf.keras.layers.Dense(units=128, activation='relu', kernel_initializer='he_normal'): 128개의 유닛을 갖는 완전 연결층, ReLU 활성화 함수 사용, He 초기화.
- tf.keras.layers.Dropout(0.5): 드롭아웃 층, 50% 확률로 뉴런을 비활성화하여 과적합 방지.
- tf.keras.layers.Dense(units=64, activation='relu', kernel_initializer='he_normal'): 64개의 유닛을 갖는 완전 연결층, ReLU 활성화 함수 사용, He 초기화.
- tf.keras.layers.Dropout(0.5): 드롭아웃 층, 50% 확률로 뉴런을 비활성화하여 과적합 방지.
- tf.keras.layers.Dense(units=10, activation='softmax'): 출력층, 10개의 유닛(클래스 수)과 소프트맥스 활성화 함수 사용하여 각 클래스에 대한 확률을 출력한다.
이 모델은 28x28 크기의 흑백 이미지를 입력받아 10개의 클래스 중 하나를 예측하는 아키텍처를 가진 합성곱 신경망이다. 합성곱 층, 풀링 층, 완전 연결층을 통해 이미지의 특징을 추출하고, 드롭아웃을 사용하여 과적합을 방지한다. 소프트맥스 활성화 함수가 사용된 마지막 출력층은 이미지가 각 클래스에 속할 확률을 출력한다.
케라스로 ResNet-34 CNN 구현하기
CNN 구조는 케라스를 사용해 쉽게 구현할 수 있다. 케라스를 사용해 ResNet-34 모델을 구현해본다.
DefaultConv2D = partial(tf.keras.layers.Conv2D, kernel_size=3, strides=1,
padding="same", kernel_initializer="he_normal",
use_bias=False)
class ResidualUnit(tf.keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = tf.keras.activations.get(activation)
self.main_layers = [
DefaultConv2D(filters, strides=strides),
tf.keras.layers.BatchNormalization(),
self.activation,
DefaultConv2D(filters),
tf.keras.layers.BatchNormalization()
]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
DefaultConv2D(filters, kernel_size=1, strides=strides),
tf.keras.layers.BatchNormalization()
]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)
[코드 설명]
위 코드는 Residual Block(잔차 블록)을 구현한 예제이며, Residual Block은 딥 러닝 모델, 특히 Residual Networks(ResNet)에서 사용되며, 신경망 학습을 더 효과적으로 하기 위해 설계되었다.
- DefaultConv2D 정의
먼저, DefaultConv2D라는 변수를 정의하여 기본적인 Conv2D(2차원 합성곱) 층을 미리 설정해둔다. 이는 반복적인 파라미터 설정을 피하기 위해 사용한다.
- ResidualUnit 클래스 정의
ResidualUnit 클래스는 tf.keras.layers.Layer를 상속 받아 Residual Block을 구현한 것이다.
- 주요 구성 요소 설명
- Main Layers: 이 블록은 기본적으로 두 개의 합성곱 층과 두 개의 배치 정규화 층, 그리고 중간에 활성화 함수를 포함하고 있다. 두 번째 합성곱 층 이후에는 활성화 함수가 적용되지 않는는다.
- Skip Layers: Skip connection(잔차 연결)은 기본적으로 Identity Mapping을 사용하지만, 입력과 출력의 크기가 다를 경우 (즉, strides > 1인 경우)에는 이를 조정하기 위해 추가 합성곱 층과 배치 정규화 층이 사용된된다.
이 경우 입력을 1x1 합성곱 층을 통해 크기를 맞추고 배치 정규화를 수행하여 출력과 동일한 크기로 만든다.
- call 메서드는 Residual Block의 순전파(forward pass)를 수행하며, 입력 데이터를 처리하여 출력값을 생성한다.
이 네트워크는 연속되어 길게 연결된 층이기 때문에 Sequential 클래스를 사용해 ResNet-34 모델을 만들 수 있다. ResidualUnit 클래스를 준비해놓았으니 잔차 유닛을 하나의 층처럼 취급할 수 있다.
model = tf.keras.Sequential([
DefaultConv2D(64, kernel_size=7, strides=2, input_shape=[224, 224, 3]),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same'),
])
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(tf.keras.layers.GlobalAvgPool2D())
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(10, activation='softmax'))다음 내용
[출처]
핸즈 온 머신러닝
https://ingu627.github.io/hands_on/TDL5/
'[파이썬 Projects] > <파이썬 딥러닝, 신경망>' 카테고리의 다른 글
| [딥러닝] 객체 탐지, 객체 추적 (0) | 2024.11.29 |
|---|---|
| [딥러닝] 케라스의 사전 훈련 모델 사용하기 (1) | 2024.11.29 |
| [딥러닝] 텐서플로 데이터셋 프로젝트 (0) | 2024.11.27 |
| [딥러닝] 케라스의 전처리 층 (0) | 2024.11.26 |
| [딥러닝] 심층 신경망 훈련 - 4 (1) | 2024.11.26 |



