이전 내용
[딥러닝] 비지도 학습: 오토인코더, GAN, 확산 모델
이전 내용 오토인코더 오토인코더는 지도 방식을 사용하지 않고 잠재 표현 또는 입력 데이터의 밀집 표현(코딩)을 학습할 수 있는 인공 신경망이다. 코딩은 일반적으로 입력보다 훨씬 낮은 차
puppy-foot-it.tistory.com
강화 학습(Reinforcement Learning, RL)
강화 학습(Reinforcement Learning, RL)은 기계 학습의 한 분야로, 에이전트가 환경과 상호작용하여 보상을 최대화할 수 있는 행동을 학습하는 방법이다. 다양한 상황에서 의사 결정을 하는 방법을 배우고, 결과에 따라 조정하는 과정을 통해 성능을 향상시킨다. 강화 학습은 특히 동적이고 복잡한 환경에서 최적의 전략을 찾는 데 유용하다.
강화 학습에서 소프트웨어 에이전트는 관측을 하고 주어진 환경에서 행동을 한다. 그리고 결과에 따라 환경으로부터 보상을 받는다. 에이전트의 목적은 보상의 장기간 기대치를 최대로 만드는 행동을 학습하는 것이다. 긍정적 보상은 기쁨으로, 부정적 보상은 아픔으로 생각할 수 있다. 즉, 에이전트는 환경 안에서 행동하고 시행착오를 겪으며 기쁨이 최대가 되고 아픔이 최소가 되도록 학습한다.

◆ 강화 학습의 주요 개념
- 에이전트(Agent): 환경과 상호작용하여 학습을 수행하는 주체.
- 환경(Environment): 에이전트가 상호작용하는 시스템 또는 상황.
- 상태(State): 환경의 현재 상태를 나타내는 변수. 일반적으로 (S_t)로 표시.
- 행동(Action): 에이전트가 취할 수 있는 행동. 일반적으로 (A_t)로 표시.
- 보상(Reward): 에이전트가 특정 행동을 수행할 때 환경으로부터 받는 피드백. 일반적으로 (R_t)로 표시.
- 정책(Policy): 각 상태에서 어떤 행동을 취할지 결정하는 전략. 이는 결정론적 또는 확률론적일 수 있다.
- 가치 함수(Value Function): 특정 상태나 상태-행동 쌍의 기대 누적 보상을 평가하는 함수. 가치 함수에는 상태 가치 함수 (V(s))와 행동 가치 함수 (Q(s, a))가 있다.
- 할인율(Discount Factor): 장기적인 보상을 평가할 때의 할인을 나타내는 값으로, 일반적으로 (\gamma)로 표시. 이 값은 미래 보상의 중요도를 결정한다.
◆ 강화 학습의 과정
- 초기화: 에이전트는 초기 정책을 설정하고 환경의 초기 상태를 관찰한다.
- 상호작용: 에이전트는 현재 정책에 따라 행동을 선택하고, 그 결과를 환경으로부터 받는다.
- 보상 및 다음 상태 관찰: 에이전트는 행동에 대한 보상을 받고, 환경의 다음 상태를 관찰한다.
- 정책 업데이트: 에이전트는 받은 보상과 새로운 정보를 사용하여 정책을 업데이트한다.
- 반복: 위 과정을 반복하여 에이전트는 점차 최적의 정책을 학습한다.
◆ 강화 학습의 알고리즘
- Q-러닝(Q-Learning): 상태-행동 쌍의 가치를 추정하여 최적 정책을 학습하는 메서드이다. 에이전트는 Q-값을 업데이트하여 최적의 행동을 찾는다.
- SARSA(State-Action-Reward-State-Action): Q-러닝과 유사하지만, 에이전트가 실제로 취한 행동을 기반으로 Q-값을 업데이트한다.
- 정책 그라디언트(Policy Gradient): 에이전트가 직접 정책을 학습하고, 보상을 최대화하는 방향으로 정책을 조정한다.
◆ 강화 학습의 활용 사례
강화 학습은 다양한 분야에서 활용될 수 있으며, 주로 복잡한 의사 결정 문제가 있는 상황에서 탁월한 성능을 발휘한다.
1. 게임
- 알파고(AlphaGo): 딥마인드가 개발한 바둑 AI로, 딥 Q-러닝과 몬테 카를로 트리 탐색(MCTS)을 결합하여 인간 챔피언을 이겼다.
- 비디오 게임: DQN(Deep Q-Network)을 통해 다양한 비디오 게임에서 인간 수준의 성능을 달성하였다.
2. 로보틱스
- 자율 로봇: 로봇이 강화 학습을 통해 환경을 탐색하고, 장애물을 피하며, 특정 태스크를 수행하는 법을 학습한다.
- 로봇 팔 제어: 정밀한 작업을 수행하기 위해 로봇 팔의 움직임을 최적화하는 데 사용된다.
3. 금융
- 자동 거래 시스템: 시장 데이터를 분석하고 최적의 투자 결정을 내리는 거래 알고리즘을 개발하기 위해 사용된다.
- 포트폴리오 관리: 강화 학습을 통해 자산 배분 전략을 최적화하고, 위험을 관리한다.
4. 교통 관리
- 자율 주행 차량: 차량의 경로 계획 및 충돌 방지를 위해 강화 학습 알고리즘이 사용된다.
- 신호 제어 시스템: 도시의 교통 신호를 최적화하여 교통 흐름을 개선하고 교통 체증을 줄인다.
5. 헬스케어
- 치료 계획 최적화: 환자의 상태에 따라 최적의 치료 계획을 제공하기 위해 강화 학습이 사용된다.
- 약물 개발: 신약 후보 물질을 선택하고, 약물 상호작용을 분석하는 데 사용된다.
정책 탐색
강화 학습에서 정책 탐색(Policy Exploration)은 에이전트가 최적의 정책을 찾기 위해 새로운 행동을 시도하는 과정이다. 정책 탐색 방법은 크게 정책 기반 방법(Policy-based methods)과 값 기반 방법(Value-based methods)으로 나뉜다. 이 두 가지 접근법은 서로 다른 관점에서 문제를 해결하려고 하며, 때로는 하이브리드 방식으로 사용되기도 한다.
1. 정책 기반 방법 (Policy-Based Methods)
정책 기반 방법에서는 에이전트가 직접 정책(Policy)을 파라미터화하고, 이 정책을 학습한다. 이 방법은 주어진 상태에서의 행동 확률을 직접 최적화하는 접근 방식이다.
- 주요 방법
- 정책 그라디언트(Policy Gradient) 방법: 주어진 상태에서 행동의 확률 분포를 정의하는 파라미터화된 정책 (\pi_\theta(a|s))를 학습한다. 목표는 기대 누적 보상 (\mathbb{E}[R])을 최대화하는 방향으로 정책 파라미터 (\theta)를 조정하는 것이다.
- 액터-크리틱(Actor-Critic) 방법: 정책 기반 방법과 값 기반 방법을 결합한 것으로, 액터는 정책을 업데이트하고 크리틱은 가치 함수를 학습한다. 이 접근법에서는 두 네트워크를 사용한다.
- 액터(Actor): 정책 (\pi_\theta)를 업데이트.
- 크리틱(Critic): 상태 가치 함수 Vπ(s) 또는 행동 가치 함수 Qπ(s,a)를 학습.
2. 값 기반 방법 (Value-Based Methods)
값 기반 방법에서는 상태 가치 함수 또는 상태-행동 가치 함수를 학습하고, 이를 통해 최적의 정책을 유도한다. 에이전트는 학습된 가치 함수를 사용하여 각 상태에서 가장 큰 가치를 가지는 행동을 선택한다.
- 주요 방법
- Q-러닝(Q-Learning): 모델 성립에 관계없이 상태-행동 쌍의 Q-값 ( Q(s, a) )을 추정하여 최적 정책을 학습한다.
- 딥 Q-네트워크(DQN, Deep Q-Network): Q-러닝의 확장으로, 심층 신경망을 사용하여 Q-함수를 근사한다. 경험 재생(Experience Replay)과 타깃 네트워크(Target Network) 등의 기법을 통해 학습의 안정성을 확보한다.
◆ 정책 탐색 기법
강화 학습에서 효율적인 정책 탐색을 위해 다양한 기법들이 사용된다. 주로 탐험(exploration)과 이용(exploitation) 간의 균형을 맞추는 데 중점을 둔다.
- 탐험과 이용 균형 (Exploration vs. Exploitation)
- (\epsilon)-탐욕적 방법((\epsilon)-greedy method): 대부분의 시간에는 현재 최적 행동을 선택하고((1 - \epsilon)의 확률), 소수의 시간에는 무작위로 행동을 선택하여((\epsilon)의 확률) 새로운 행동을 탐험한다.
- (\epsilon) 점감((\epsilon) Decay): 학습 초반에는 큰 (\epsilon) 값을 사용하여 탐험을 많이 하고, 시간이 지남에 따라 (\epsilon) 값을 줄여가며 이용을 더 많이 하도록 한다.
- 소프트맥스 탐험(Softmax Exploration)
탐험 시 확률적으로 행동을 선택하며, 선택 확률은 현재 Q-값에 기반하여 결정된다. 이는 소프트맥스 함수로 표현됩니다.
[P(a|s) = \frac{e^{Q(s,a)/\tau}}{\sum_{a'} e^{Q(s,a')/\tau}}]여기서 (\tau)는 온도 매개변수로, (\tau) 값이 높을수록 행동 선택의 확률이 고르게 분포되고, 낮을수록 특정 행동이 선택될 확률이 높아진다.
- 우선순위 경험 재생(Prioritized Experience Replay)
학습에 중요한 경험을 더 자주 재생하여 학습 효율을 높이는 방법이다. 경험이 발생할 수 있는 중요도에 따라 우선순위를 두고, 우선순위 큐를 구성한다.
OpenAI Gym
강화 학습에서 어려운 점은 에이전트를 훈련하기 위해 먼저 작업 환경을 마련해야 한다는 것이다.
OpenAI Gym은 다양한 종류의 시뮬레이션 환경을 제공하는 툴킷이다. 이를 사용하여 에이전트를 훈련하고 이들을 비교하거나 새로운 RL 알고리즘을 개발할 수 있다.
https://openai.com/index/openai-gym-beta/
OpenAI Gym을 사용하기 위해 먼저 설치해준다.
※ 저자 내용
OpenAI는 Gym 라이브러리의 개발과 유지보수를 Farama 재단으로 넘겼습니다(https://farama.org/Announcing-The-Farama-Foundation). 라이브러리 이름은 Gymnasium으로 바뀌었습니다. OpenAI Gym을 쓰는 자리에 대신 사용할 수 있습니다. gym 대신 gymnasium을 설치하고 import gymnasium as gym을 실행하면 됩니다.
pip install gymnasiumpip install gymnasium[classic_control, box2d, atari, accept-rom-license]◆ CartPole 환경을 통한 RL 알고리즘
설치가 완료된 후, Gym을 import 하고 환경을 만든다.
import gymnasium as gym
env = gym.make('CartPole-v1', render_mode='rgb_array')▶ CartPole 환경을 만들었는데, 이것은 카트 위에 놓인 막대가 넘어지지 않도록 왼쪽이나 오른쪽으로 가속할 수 있는 2D 시뮬레이션이다.
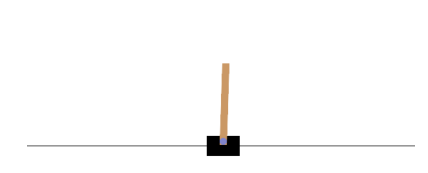
환경을 만든 후 reset() 메서드로 꼭 초기화해야 하는데, 이 메서드는 첫 번째 관측을 반환한다.
reset() 메서드는 추가적으로 환경에 관련된 정보를 담은 딕셔너리도 반환한다. CartPole 환경에서는 이 딕셔너리가 비어있다.
obs, info = env.reset(seed=42)
print(obs)
print(info)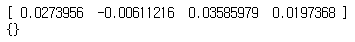
▶ 관측은 환경의 종류에 따라 다르며, CartPole 환경의 경우 각 관측은 네 개의 실수를 담은 1D 넘파이 배열이다. 이 실수는 카트의 수평 위치(0.0=중앙), 카트의 속도(양수는 우측 방향 의미), 막대의 각도(0.0=수직), 막대의 각속도(양수는 시계 방향 의미)를 나타낸다.
render() 메서드를 호출해 이 환경을 이미지로 렌더링해본다. 이 환경을 만들 때 render_mode='rgb_array'로 지정했기 때문에 이미지는 넘파이 배열로 반환된다.
img = env.render()
img.shape # 높이, 너비, 채널 (3 = 빨강, 초록, 파랑)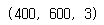
이 환경에서 어떤 행동이 가능한지 확인해본다.
env.action_space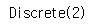
▶ 이 뜻은 가능한 행동이 정수 0과 1이라는 것을 의미하며, 각각 왼쪽 가속과 오른쪽 가속이다.
막대가 오른쪽으로 기울어져 있기 때문에 (obs[2] > 0) 카트를 오른쪽으로 가속해본다.
action = 1 # 오른쪽으로 가속
obs, reward, done, truncated, info = env.step(action)
obs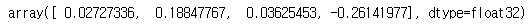
환경은 에이전트에게 마지막 스텝에서 얼마나 많은 보상을 받았는지도 알려준다. step() 메서드는 주어진 행동을 실행하고 네 가지 값을 반환한다.
print(reward)
print(done)
print(truncated)
print(info)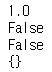
- obs: 새로운 관측값. 카트가 오른쪽 방향으로 움직인다 (obs[1]>0). 막대가 여전히 오른쪽 방향으로 기울어져 있지만(obs[2]>0), 각속도가 음수가 되었으므로 (obs[3]<0) 다음 스텝 후에는 왼쪽으로 기울어질 가능성이 크다.
- reward: 이 환경에서는 어떤 행동을 실행해도 매 스텝마다 1.0의 보상을 받는다. 그러므로 시스템의 목적은 가능한 한 오랫동안 실행하는 것이다.
- done: 이값이 True이면 이 에피소드가 끝난 것이다. 막대가 너무 기울어지거나 화면 밖으로 나가거나 200 스텝을 넘기면 에피소드가 끝난다. (200 스텝을 넘어가게 되면 에이전트의 승리) 에피소드가 끝나면 환경을 다시 사용하기 전에 꼭 초기화해야 한다.
- truncated: 이 값은 에피소드가 중단되는 경우 True 가 된다. 예를 들어 에피소드당 최대 스텝 수를 부과하는 환경 래퍼에 의해 중단되는 경우이다. 일부 RL 알고리즘은 중단된 에피소드를 정상적으로 완료(done=True)된 에피소드와 다르게 처리하지만 여기서는 동일하게 처리한다.
- info: reset() 메서드가 반환하는 값처럼 환경에 관련된 추가 정보를 담은 딕셔너리이다.
#에피소드가 끝날 때 환경을 계속 사용하기 전에 환경 재설정
if done or truncated:
obs, info = env.reset()
▶ 한 환경을 다 사용했다면 close() 메서드를 호출해 자원을 반납해야 한다.
간단한 정책을 하드코딩하는데, 이 정책은 막대가 왼쪽으로 기울어지면 카트를 왼쪽으로 가속하고 오른쪽으로 기울어지면 오른쪽으로 가속한다. 이 정책으로 에피소드 500번을 실행하여 얻은 평균 보상을 확인해본다.
def basic_policy(obs):
angle = obs[2]
return 0 if angle < 0 else 1
totals = []
for episode in range(500):
episode_rewards = 0
obs, info = env.reset(seed=episode)
for step in range(200):
action = basic_policy(obs)
obs, reward, done, truncated, info = env.step(action)
episode_rewards += reward
if done or truncated:
break
totals.append(episode_rewards)
결과를 확인해본다.
np.mean(totals), np.std(totals), min(totals), max(totals)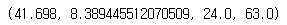
import matplotlib.animation
from IPython.display import HTML
def update_scene(num, frames, patch):
patch.set_data(frames[num])
return patch,
def plot_animation(frames, repeat=False, interval=40):
fig = plt.figure()
patch = plt.imshow(frames[0])
plt.axis('off')
anim = matplotlib.animation.FuncAnimation(
fig, update_scene, fargs=(frames, patch),
frames=len(frames), repeat=repeat, interval=interval)
plt.close()
return anim
def show_one_episode(policy, n_max_steps=200, seed=42):
frames = []
env = gym.make("CartPole-v1", render_mode="rgb_array")
np.random.seed(seed)
obs, info = env.reset(seed=seed)
for step in range(n_max_steps):
frames.append(env.render())
action = policy(obs)
obs, reward, done, truncated, info = env.step(action)
if done or truncated:
break
env.close()
return plot_animation(frames)
# 애니메이션 생성 및 표시
animation = show_one_episode(basic_policy)
HTML(animation.to_jshtml())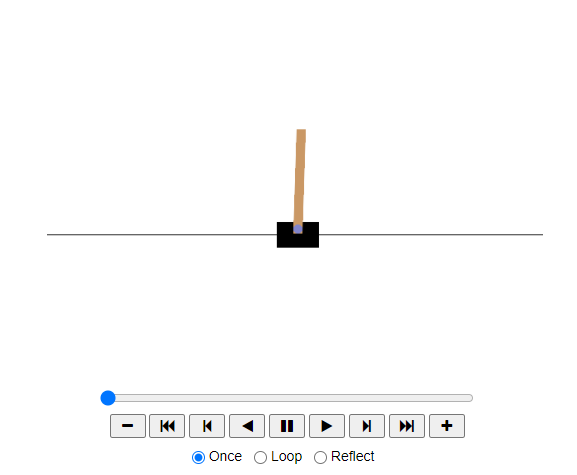
신경망 정책
신경망 정책은 관측을 입력으로 받고 실행할 행동을 출력한다. 즉, 각 행동에 대한 확률을 추정하고, 추정된 확률에 따라 랜덤하게 행동을 선택한다. CartPole 환경의 경우엔 가능한 행동이 두 개(왼쪽, 오른쪽) 있으므로 하나의 출력 뉴런만 있으면 된다. 이 뉴런은 행동 0 (왼쪽)의 확률을 출력하고, 행동 1(오른쪽)의 확률을 1-p가 된다.
이런 방식은 에이전트가 새로운 행동을 탐험하는 것과 잘 할 수 있는 행동을 활용하는 것 사이에 균형을 맞추게 한다.
또한 각 관측이 환경에 대한 완전한 상태를 담고 있으므로 이런 특별한 환경에서는 과거의 행동과 관측은 무시해도 괜찮다.
CartPole 문제는 관측에 잡음이 없고 환경에 대한 완전한 상태를 담는 아주 간단한 문제다.
다음 코드는 케라스를 사용하여 신경망 정책을 구현한다.
model = tf.keras.Sequential([
tf.keras.layers.Dense(5, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])Sequential 모델을 사용해 정책 네트워크를 정의한다.
- 입력의 개수는 관측 공간의 크기로, 이 CartPole의 경우는 4이다.
- 간단한 문제이므로 은닉 유닛 5개 사용.
- 하나의 확률이 필요하므로 시그모이드 활성화 함수를 사용한 하나의 출력 뉴런을 둔다. (만약 가능한 행동이 두 개보다 많으면 행동마다 하나의 출력 뉴런을 두고 소프트맥스 활성화 함수를 사용해야 한다)
주어진 정책 모델에 대한 애니메이션을 만드는 함수를 입력하여 카트와 막대가 어떻게 움직이는지 확인해본다.
def pg_policy(obs):
left_proba = model.predict(obs[np.newaxis], verbose=0)[0][0]
return int(np.random.rand() > left_proba)
np.random.seed(42)
animation = show_one_episode(pg_policy)
HTML(animation.to_jshtml())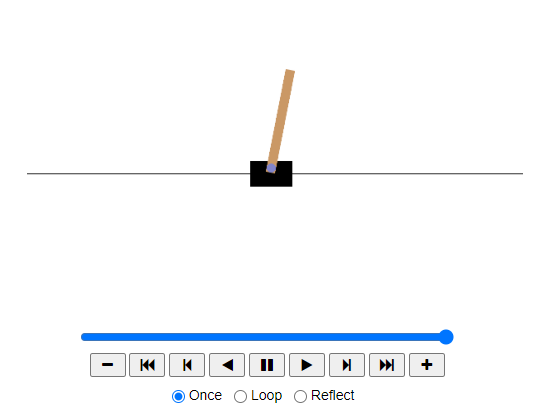
행동 평가: 신용 할당 문제(Credit Assignment Problem)
강화 학습(계층형 강화 학습 포함)에서 신용 할당 문제(Credit Assignment Problem)는 특정 행동이 보상을 받을 때, 해당 보상이 어떤 행동 또는 행동 시퀀스에 기인한 것인지 결정하는 문제를 의미한다. 이는 에이전트가 장기적인 보상 목표를 이루기 위해 필요한 중요한 과제 중 하나다.
- 지연된 보상 (Delayed Reward):
- 강화 학습에서는 행동이 바로 보상으로 이어지지 않는 경우가 많다. 행동의 결과가 나중에 나타날 때, 어떤 행동이 성공에 기여했는지 정확히 판단하는 것은 어렵다.
- 예를 들어, 체스 게임에서 초기 몇 수의 움직임이 최종 승리에 얼마나 기여했는지 파악하는 것이 어려운 것처럼, 에이전트의 특정 행동이 나중에 나타나는 보상에 얼마나 기여했는지 판단하는 것은 복잡한 문제다.
- 에피소드 단위 평가 (Episode-based Evaluation):
- 강화 학습에서는 에피소드 단위를 사용하여 평가를 진행할 때가 많다. 이는 전체 에피소드를 기준으로 보상을 평가하고, 에피소드 내의 개별 행동의 기여도를 판단한다.
- 보상 신호 (Reward Signal):
- 신용 할당 문제는 보상 신호를 통해 해결된다. 값 함수(Value Function)나 정책 함수(Policy Function)를 개선하기 위해 보상 신호는 개별 행동의 효율성을 평가하고 학습의 방향을 제시한다.
- 신용 할당 문제 해결 기법
신용 할당 문제를 해결하기 위해 흔히 사용하는 전략은 행동이 일어난 후 각 단계마다 할인 계수를 적용한 보상을 모두 합하여 행동을 평가하는 것이다. 할인된 보상의 합을 행동의 대가라고 부른다. 할인 계수가 0에 가까우면 미래의 보상은 현재의 보상만큼 중요하게 취급되지 않을 것이고, 할인 계수가 1에 가까우면 먼 미래의 보상이 현재의 보상만큼 중요하게 고려될 것이다. 전형적인 할인 계수의 값은 0.9에서 0.99 사이이다.
그리고 행동 이익을 추정해야 하는데, 행동 이익이란 평균적으로 다른 가능한 행동과 비교해서 각 행동이 얼마나 좋은지 혹은 나쁜지를 추정하는 것이며, 행동 이익을 얻기 위해서는 많은 에피소드를 실행하고 모든 행동의 대가를 평균을 빼고 표준 편차로 나누어 정규화해야 한다. 그러면 행동 이익이 음수인 행동은 나쁘고, 양수인 행동은 좋다고 가정할 수 있다.
- 시간차(TD, Temporal Difference) 학습:
- TD 학습은 지연된 보상을 다루기 위한 방법 중 하나다. TD 학습은 현재 상태에서 다음 상태로의 이동 간의 보상을 기반으로 값을 수정한다. Q-러닝과 SARSA가 대표적인 TD 학습 알고리즘이다.
- 몬테카를로 방법 (Monte Carlo Methods):
- 몬테카를로 방법은 에피소드의 종료 시에 보상을 평가하여, 각 상태-행동 쌍에 대한 평균적인 보상을 계산한다.
- 웅가우스팅 (Bootstrapping):
- Bootstrapping 기법은 상태가 주어졌을 때 미래 보상에 대한 기대값을 사용하여 학습을 진행한다. 이를 통해 보상을 조기 할당하여 신용 할당 문제를 해결한다.
- 경험 재생 (Experience Replay):
- DQN(Deep Q-Network)과 같은 강화 학습 알고리즘에서는 경험 재생을 사용하여 신용 할당 문제를 완화할 수 있다. 에이전트의 경험을 저장한 뒤, 이를 랜덤하게 다시 학습함으로써 데이터 효율성을 높이고, 행동에 대한 신용 할당 정확성을 높인다.
- 장기 단기 기억 (Long Short-Term Memory, LSTM):
- 강화 학습에서 RNN(Recurrent Neural Network)와 같은 순환 신경망 기법을 사용하면, 시퀀스 데이터와 의존성을 학습할 수 있다. LSTM은 장기 의존성을 학습하는 데 유리하여 신용 할당 문제를 효과적으로 해결할 수 있다.
정책 그레이디언트
정책 그레이디언트 알고리즘은 높은 보상을 얻는 방향의 그레이디언트를 따르도록 정책의 파라미터를 최적화하는 알고리즘이며, 그 중 인기 있는 알고리즘은 REINFORCE 알고리즘으로 방식은 다음과 같다.
- 먼저 신경망 정책이 여러 번에 걸쳐 게임을 플레이하고 매 스텝마다 선택된 행동이 더 높은 가능성을 가지도록 만드는 그레이디언트를 계산한다. 그러나 아직 이 그레이디언트를 적용하지는 않는다.
- 에피소드를 몇 번 실행한 다음, 각 행동의 이익을 계산한다.
- 한 행동의 이익이 양수이면 이 행동이 좋은 것임을 의미하므로 미래에 선택될 가능성이 높도록 앞서 계산한 그레이디언트를 적용한다. 그러나 행동 이익이 음수이면 이 행동이 나쁜 것임을 의미하므로 미래에 이 행동이 덜 선택되도록 반대의 그레이디언트를 적용한다. 이는 각 그레이디언트 벡터와 그에 상응하는 행동의 이익을 곱하면 된다.
- 마지막으로 모든 결과 그레이디언트 벡터를 평균 내어 경사 하강법 스텝을 수행한다.
케라스를 사용하여 이 알고리즘을 구현해본다.
def play_one_step(env, obs, model, loss_fn):
with tf.GradientTape() as tape:
left_proba = model(obs[np.newaxis])
action = (tf.random.uniform([1, 1]) > left_proba)
y_target = tf.constant([[1.]]) - tf.cast(action, tf.float32)
loss = tf.reduce_mean(loss_fn(y_target, left_proba))
grads = tape.gradient(loss, model.trainable_variables)
obs, reward, done, truncated, info = env.step(int(action))
return obs, reward, done, truncated, grads[코드 설명]
- left_proba: GradientTape 블록 안에서 하나의 관측과 함께 모델 호출. 모델은 배치를 기대하므로 하나의 샘플이 들어 있는 배치가 되도록 관측의 크기를 바꾼다. 이 모델은 왼쪽으로 이동할 확률을 출력한다.
- action: 0에서 1 사이의 랜덤한 실수를 샘플링한다. 이 값이 left_proba 보다 큰지 확인한다. action은 left_proba 확률로 False가 되고 1-left_proba 확률로 True 가 된다. 이 불리언 값을 정수로 변환하면 action은 출력된 확률에 맞게 0(왼쪽) 또는 1(오른쪽)이 된다.
- y_target: 주어진 손실 함수를 사용해 손실을 계산하고 테이프를 사용해 모델의 훈련 가능한 변수에 대한 손실의 그레이디언트를 계산한다. 이 그레이디언트도 나중에 적용하기 전에 이 행동이 좋은지 나쁜지에 따라 조정된다.
- obs, reward, done, truncated, info & return : 선택한 행동을 플레이하고 새로운 관측, 보상, 에피소드 종료 여부, 에피소드 중단 여부, 계산한 그레이디언트를 반환한다.
play_one_step() 함수를 사용해 여러 에피소드를 플레이하고, 전체 보상 및 각 에피소드와 스텝의 그레이디언트를 반환하는 또 다른 함수를 만들어본다.
def play_multiple_episodes(env, n_episodes, n_max_steps, model, loss_fn):
all_rewards = []
all_grads = []
for episode in range(n_episodes):
current_rewards = []
current_grads = []
obs, info = env.reset()
for step in range(n_max_steps):
obs, reward, done, truncated, grads = play_one_step(
env, obs, model, loss_fn)
current_rewards.append(reward)
current_grads.append(grads)
if done or truncated:
break
all_rewards.append(current_rewards)
all_grads.append(current_grads)
return all_rewards, all_grads
이 알고리즘은 play_multiple_episodes() 함수를 사용하여 여러 번 게임을 플레이하고, 처음부터 모든 보상을 살펴서 각 보상을 할인하고 정규화한다. 이를 위해 함수 몇 개가 더 필요한데,
- discount_rewards: 각 스텝에서 할인된 미래 보사의 합 계산
- discount_and_normalize_rewards: 여러 에피소드에 걸쳐 계산된 할인된 모든 보상(대가)에서 평균을 빼고 표준 편차로 나눠 정규화
def discount_rewards(rewards, discount_factor):
discounted = np.array(rewards)
for step in range(len(rewards) - 2, -1, -1):
discounted[step] += discounted[step + 1] * discount_factor
return discounted
def discount_and_normalize_rewards(all_rewards, discount_factor):
all_discounted_rewards = [discount_rewards(rewards, discount_factor)
for rewards in all_rewards]
flat_rewards = np.concatenate(all_discounted_rewards)
reward_mean = flat_rewards.mean()
reward_std = flat_rewards.std()
return [(discounted_rewards - reward_mean) / reward_std
for discounted_rewards in all_discounted_rewards]
이 두 함수를 확인해본다.
discount_rewards([10, 0, -50], discount_factor=0.8)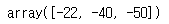
discount_and_normalize_rewards([[10, 0, -50],[10, 20]],
discount_factor=0.8)
하이퍼파라미터를 정의해본다.
- 훈련 반복: 150번. 각 반복은 에피소드 10개를 진행하고, 각 에피소드는 스텝을 최대 200번 플레이
- 할인 계수: 0.95
- 옵티마이저: 학습률 0.01의 Nadam
- 손실 함수: 이진 분류기(왼쪽 또는 오른쪽 두 가지)를 훈련하므로 이진 크로스 엔트로피 손실 함수(binary_crossentropy)
n_iterations = 150
n_episodes_per_update = 10
n_max_steps = 200
discount_factor = 0.95
optimizer = tf.keras.optimizers.Nadam(learning_rate=0.01)
loss_fn = tf.keras.losses.binary_crossentropy
훈련 반복을 만들어 실행한다.
for iteration in range(n_iterations):
all_rewards, all_grads = play_multiple_episodes(
env, n_episodes_per_update, n_max_steps, model, loss_fn)
all_final_rewards = discount_and_normalize_rewards(all_rewards,
discount_factor)
all_mean_grads = []
for var_index in range(len(model.trainable_variables)):
mean_grads = tf.reduce_mean(
[final_reward * all_grads[episode_index][step][var_index]
for episode_index, final_rewards in enumerate(all_final_rewards)
for step, final_reward in enumerate(final_rewards)], axis=0)
all_mean_grads.append(mean_grads)
optimizer.apply_gradients(zip(all_mean_grads, model.trainable_variables))[코드 설명]
- all_rewards, all_grads: 각 훈련 반복에서 play_multiple_episodes() 함수 호출. 이 함수는 게임을 10번 플레이하고 각 에피소드와 스텝에 대한 모든 보상과 그레이디언트 반환
- all_final_rewards: discount_and_normalize_rewards() 함수를 호출하여 각 행동의 정규화된 이익(final_reward)을 계속 계산. 이 값은 각 행동이 실제로 얼마나 좋은지 나쁜지를 알려줌.
- for var_index ~ all_mean_grads.append(mean_grads): 훈련 가능한 변수를 순회하면서 모든 에피소드와 모든 스텝에 대한 각 변수의 그레이디언트를 final_reward로 가중치를 두어 평균.
- optimizer.apply_gradients(~ variables) : 평균 그레이디언트를 옵티마이저에 적용. 모델의 훈련 가능한 변수가 변경되고 정책이 조금 개선됨.
이번에 훈련한 간단한 정책 그레이디언트 알고리즘은 더 크고 복잡한 문제에는 잘 적용되지 못하는 즉, 샘플 효율성이 매우 좋지 않다. 왜냐하면 아주 긴 시간 동안 게임을 플레이해야 정책을 많이 개선할 수 있기 때문이다.
마르코프 결정 과정(Markov Decision Process, MDP)
마르코프 결정 과정(Markov Decision Process, MDP)는 강화 학습의 기초를 이루는 중요한 수학적 개념이다. MDP는 에이전트가 환경과 상호 작용하여 최적의 행동을 선택하는 문제를 모델링하는 데 사용된다. MDP는 확률적이고, 순차적인 의사 결정 문제를 나타낸다.
마르코프 결정 과정은 각 스텝에서 에이전트는 여러 가능한 행동 중 하나를 선택할 수 있고, 전이 확률은 선택된 확률에 따라 달라진다. 또한 어떤 상태 전이는 보상(양수 또는 음수)을 반환한다. 그리고 에이전트의 목적은 시간이 지남에 따라 보상을 최대화하기 위한 정책을 찾는 것이다.
- MDP의 구성 요소
- 상태 집합 ( S ) (State Space):
- 환경의 가능한 모든 상태들의 집합. 상태 ( s \in S )는 환경의 특정 순간 상태를 의미.
- 행동 집합 ( A ) (Action Space):
- 에이전트가 특정 상태에서 취할 수 있는 모든 가능한 행동들의 집합. 행동 ( a \in A(s) )는 상태 ( s )에서 가능한 행동을 의미.
- 상태 전이 확률 ( P(s'|s, a) ) (State Transition Probability):
- 특정 행동 ( a )를 상태 ( s )에서 취했을 때 다음 상태 ( s' )로 전이될 확률. 이는 ( T(s, a, s') )로도 나타낼 수 있다.
- 보상 함수 ( R(s, a) ) (Reward Function):
- 특정 상태 ( s )에서 행동 ( a )를 취했을 때 에이전트가 받는 즉각적인 보상을 의미. 이는 ( R(s, a, s') ) 형태로 상태 전이와 함께 정의될 수도 있다.
- 할인율 ( \gamma ) (Discount Factor):
- 미래 보상의 현재 가치를 나타내는 파라미터. ( 0 \leq \gamma \leq 1 ) 범위의 값을 가지며, 값이 클수록 미래 보상을 더 중시한다.
- MDP의 작동 원리
에이전트는 상태 ( s )에서 행동 ( a )를 선택하고, 이에 따른 보상 ( R(s, a) )와 다음 상태 ( s' )를 받는다. 이는 다음과 같은 반복적인 사이클을 통해 이루어진다:
- 에이전트가 현재 상태 ( s )를 관찰.
- 에이전트가 행동 ( a )를 선택.
- 환경이 행동 ( a )에 대한 보상 ( R(s, a) )을 제공하고, 에이전트는 다음 상태 ( s' )로 전이.
- 에이전트는 새로운 상태 ( s' )에서 다시 행동을 선택.
- MDP의 목표
에이전트의 목표는 누적 보상(즉, 에피소드 동안 받는 모든 보상의 합)을 최대화하는 것이다. 이를 위해 에이전트는 최적의 정책 π∗를 학습해야 한다. 정책 ( \pi )는 상태에서 행동을 선택하는 전략을 정의하며, 최적의 정책은 다음과 같다
π∗(s)=argmaxaE[Rt∣s,aπ∗(s)=argmaxaE[Rt∣s,a ]여기서 ( \mathbb{E}[R_t | s, a] )는 상태 ( s )에서 행동 ( a )를 선택했을 때의 기대 보상이다.
- 가치 함수와 벨만 방정식
MDP에서 에이전트가 최적의 정책을 찾기 위해 두 가지 주요 함수가 사용된다:
- 상태 가치 함수 ( V(s) ) (Value Function):
- 특정 상태에서 시작하여 최적의 정책을 따라가면서 얻을 수 있는 기대 보상의 합.
[ V(s) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t R(s_t, a_t) \mid s_0 = s \right] ]- 상태-행동 가치 함수 ( Q(s, a) ) (State-Action Value Function):
- 특정 상태에서 특정 행동을 하고 나서 최적의 정책을 따라가면서 얻을 수 있는 기대 보상의 합.
[ Q(s, a) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t R(s_t, a_t) \mid s_0 = s, a_0 = a \right] ]- 벨만 방정식은 가치 함수와 상태-행동 가치 함수를 재귀적으로 정의하며, 다음과 같은 식으로 표현된다
[ V(s) = \max_a \left[ R(s, a) + \gamma \sum_{s'} P(s'|s, a) V(s') \right] ]
[ Q(s, a) = R(s, a) + \gamma \sum_{s'} P(s'|s, a) \max_{a'} Q(s', a') ]시간차 학습(TD 학습)
시간차 학습은 Q-가치 반복 알고리즘과 매우 비슷하지만 에이전트가 MDP에 대해 일부 정보만 알고 있을 때를 다룰 수 있도록 변형한 것이다. 일반적으로 에이전트가 초기에 가능한 상태와 행동만 알고 다른 것은 모른다고 가정한다. 에이전트는 탐험 정책을 사용해 MDP를 탐험한다. 탐험이 진행될수록 TD 학습 알고리즘이 실제로 관측된 전이와 보상에 근거하여 상태 가치의 추정값을 업데이트한다.
다른 강화 학습 알고리즘
◆ 알파고 (AlphaGo)
알파고(AlphaGo)는 딥마인드(DeepMind)가 개발한 인공지능 프로그램으로, 주로 바둑 경기에서 인간 수준을 넘는 능력을 보여주었다. 알파고는 심층 신경망(Deep Neural Network)과 몬테카를로 트리 탐색(Monte Carlo Tree Search, MCTS)의 결합을 통해 작동한다.
- 주요 특징:
- 정책 신경망(Policy Network): 특정 상태에서 최적의 수(행동)를 선택하는 확률을 예측한다.
- 가치 신경망(Value Network): 현재 상태에서 최적의 플레이를 했을 때 승리할 확률을 추정한한다.
- 훈련 방법: 사람의 바둑 기보와 강화 학습을 결합한 수많은 자가 대국을 통해 학습한다.
알파고는 2016년 이세돌 9단과의 대국에서 4 대 1로 승리하면서 큰 화제를 모았다.
◆ 액터-크리틱 (Actor-Critic)
액터-크리틱(Actor-Critic)은 정책 그라디언트 방법과 가치 기반 방법을 결합한 강화 학습 알고리즘이다.
에이전트는 두 가지 주요 구성 요소를 사용한다:
- 액터(Actor): 현재 정책에 따라 행동을 선택한다. 이를 통해 행동의 확률 분포를 학습한다.
- 크리틱(Critic): 상태의 가치(또는 행동의 가치)를 평가한다. 현재 정책에 따라 에이전트가 평가한 행동이 좋은지 나쁜지를 판단한다.
액터-크리틱 구조는 학습의 안정성과 효율성을 높이기 위해 종종 사용된다.
◆ A3C (Asynchronous Advantage Actor-Critic)
A3C(Asynchronous Advantage Actor-Critic)는 딥마인드가 제안한 강화 학습 알고리즘으로, 여러 에이전트를 병렬적으로 실행하여 학습하는 방식이다.
- 주요 특징:
- 비동기 학습: 여러 에이전트가 동시에 환경을 탐험하고, 각 에이전트가 독립적으로 업데이트를 수행한다. 이를 통해 학습의 안정성과 수렴 속도를 높인다.
- 어드밴티지 함수(Advantage Function): 액터 업데이트를 도와주는 어드밴티지 함수를 사용하여 특정 행동이 평균보다 얼마나 좋은지 측정한다.
◆ A2C (Advantage Actor-Critic)
A2C(Advantage Actor-Critic)는 A3C의 동기화된 버전입니다.
- 주요 특징:
- 동기화 학습: A3C와 달리, A2C는 여러 에이전트를 동기적으로 업데이트한다. 이는 코드 구현과 디버깅을 쉽게 하며, 여전히 높은 성능을 유지한다.
- 비동기 방식의 단순화: A2C는 A3C의 비동기 방식의 복잡성을 피하고, 간단한 동기화 기법을 사용한다.
◆ SAC (Soft Actor-Critic)
SAC(Soft Actor-Critic)은 최대 엔트로피 강화 학습(Maximum Entropy Reinforcement Learning)을 기반으로 한 알고리즘이다.
- 주요 특징:
- 엔트로피 최대화: 정책의 엔트로피를 최대화하여 탐험을 장려하고, 보다 강건한 정책을 학습한다.
- Off-Policy: 경험 재생(Experience Replay)을 사용하여 데이터를 효율적으로 사용한다.
SAC는 연속적인 행동 공간을 가진 문제에 특히 유용하다.
◆ PPO (Proximal Policy Optimization)
PPO(Proximal Policy Optimization)은 안정적이고 효율적인 강화 학습 알고리즘이다. 이는 정책 그라디언트 방법의 하나로, 기존 정책으로부터 크게 벗어나지 않도록 함으로써 학습의 안정성을 높인다.
- 주요 특징:
- 클리핑 클로즈(Clipping Clause): 큰 정책 업데이트를 방지하여 학습의 안정성을 높인다.
- 시뮬레이션 간의 효율성: PPO는 클리핑 손실 함수(Clipped Loss Function)를 도입하여 높은 샘플 효율성과 안정성을 모두 달성한다.
◆ 호기심 기반 탐색 (Curiosity-Driven Exploration)
호기심 기반 탐색은 강화 학습 에이전트가 새로운 상태나 행동을 탐험하도록 장려하는 기술이다. 이는 보상 신호가 부족한 환경에서 에이전트의 효율적인 학습을 돕는다.
- 주요 특징:
- 내부 보상: 에이전트는 예측할 수 없는 상태 전이로부터 보상을 얻는다. 예를 들어, 예측 모델이 새로운 상태를 잘 예측하지 못할 때 더 많은 보상을 받는다.
- 다양성 추구: 에이전트가 다양한 상태와 행동을 탐험하도록 유도한다.
◆ 개방형 학습 (Open-Ended Learning)
개방형 학습은 사전 정의된 목표가 없는 상태에서 에이전트가 스스로 목표를 설정하고, 환경을 탐험하면서 지속적으로 학습하는 방법이다.
- 주요 특징:
- 자율적인 목표 설정: 에이전트는 자신만의 목표를 설정하고 달성하기 위해 학습한다.
- 지속적인 학습: 환경이 변하거나 에이전트가 새로운 것을 배워야 할 때도 지속적으로 학습한다.
개방형 학습은 예측 불가능한 상황이나 복잡한 과제에서 에이전트의 적응성을 높이는 데 유용하다.
다음 내용
[딥러닝] 강화 학습(RL): Q-러닝
이전 내용 강화 학습(Reinforcement Learning, RL)은 기계 학습의 한 분야로, 에이전트가 환경과 상호작용하여 보상을 최대화할 수 있는 행동을 학습하는 방법이다. 다양한 상황에서 의사 결정을 하는
puppy-foot-it.tistory.com
[출처]
핸즈 온 머신러닝
생활 코딩(https://opentutorials.org/course/4548/28949)
'[파이썬 Projects] > <파이썬 딥러닝, 신경망>' 카테고리의 다른 글
| [딥러닝] RNN을 사용한 자연어 처리: 감성분석 (0) | 2024.12.05 |
|---|---|
| [문제 해결] 주피터노트북에 GPU 연결하기 (2) | 2024.12.04 |
| [딥러닝] 비지도 학습: 확산 모델 (3) | 2024.12.04 |
| [딥러닝] 비지도 학습: 적대적 생성 신경망(GAN) (1) | 2024.12.04 |
| [딥러닝] 비지도 학습: 오토인코더 (1) | 2024.12.03 |



