이전 내용
[Gen AI] 랭체인을 활용한 챗봇 업그레이드 - 1
이전 내용 [Gen AI] 그라디오로 제작한 챗봇 허깅 페이스에 업로드하기이전 내용 [Gen AI] 그라디오로 챗봇 제작하기 - 3 (소설봇)이전 내용 [Gen AI] 그라디오로 챗봇 제작하기 - 1 (상담봇)이전 내용
puppy-foot-it.tistory.com
모델 I/O
3. 리트리블(Retrieval)
LLM 모델 사용 시 창의적인 답변이 아닌, 도메인 지식이나 전문성이 필요한 질문에 대해서는 정확도가 떨어지는 답변을 해주는 경우가 있는데, 이러한 경우에 사용하는 것이 바로 RAG(Retrieval Augmented Generation)이다.
RAG는 외부 소스에서 검색하거나 가져온 정보를 LLM 모델의 인풋으로 적용하여 정확하고 맥락에 맞는 답을 할 수 있도록 LLM의 능력을 보완해 주는 역할을 한다.
[LLM]검색 증강 생성(RAG)이란?
AG (Retrieval-Augmented Generation) 소개최근 인공지능 분야에서 가장 주목받고 있는 기술 중 하나는 RAG, 즉 Retrieval-Augmented Generation이다. 이 기술은 전통적인 생성 모델과 검색 모델의 장점을 결합하여
puppy-foot-it.tistory.com
랭체인에서는 Data connection 모듈을 사용하여 외부 데이터를 활용하여 LLM에서 결과를 받아볼 수 있다.
1) Document Loading
문서 로더는 다양한 소스(문서)에서 데이터를 추출할 수 있으며, 100개 이상의 로더를 사용할 수 있으므로 다양한 문서 유형, 앱 및 소스(공개 웹사이트, 데이터베이스)에서 데이터를 가져올 수 있다.
[대표적인 로더들]
◆ Text File Loader
txt 파일을 불러올 때 사용한다.
from langchain.document_loaders import TextLoader
# txt 파일 경로 지정
file_path = "C:/Users/niceq/Desktop/롤러코스터.txt"
loader = TextLoader(file_path, encoding = 'UTF-8')
document= loader.load()
print(document[0].page_content)
◆ CSV Loader
csv 파일을 불러올 때 사용한다.
from langchain.document_loaders.csv_loader import CSVLoader
file_path = "C:/Users/niceq/Documents/DataScience/Python_data_touch/data/01. CCTV_in_Seoul.csv"
csv_loader = CSVLoader(file_path=file_path, encoding = 'UTF-8')
document = csv_loader.load()
document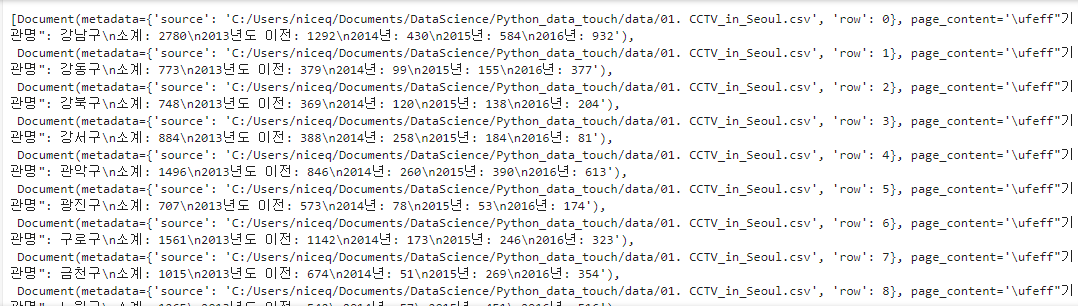
◆ PDF Loaders
랭체인을 통해 PDF 파일에서 텍스트를 로드할 수 있다. 랭체인을 사용하기 위해서는 pypdf 라이브러리를 설치해야 한다.
pip install pypdf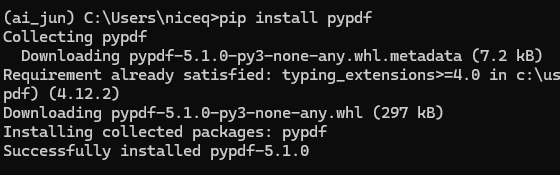
from langchain.document_loaders import PyPDFLoader
file_path = "C:/Users/niceq/Desktop/롤러코스터.pdf"
loader = PyPDFLoader(file_path)
pages = loader.load_and_split()
pages
이 밖에도 피그마(Figma), 슬랙(Slack), 노션(Notion) 등을 로더를 통해 불러올 수 있다.
2) Document Transformers
문서를 사용할 대 책 등의 대용량의 문서는 한 번에 LLM에 입력할 수 없다. 문서 변환기는 문서 로더를 통해 불러온 긴 문서를 더 작은 묶음으로 쪼개거나 결합할 때 사용한다. 이는 문서를 LLM 모델의 입력에 맞추거나 앱의 입력 크기에 맞추는 데 문서 변환기를 사용하는 것이다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
file_path = "C:/Users/niceq/Desktop/차은우_비주얼_나무위키.txt"
text_loader = TextLoader(file_path, encoding = 'UTF-8')
document = text_loader.load()
document_content = document[0].page_content
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=0,
)
texts = text_splitter.create_documents([document_content])
print(len(texts))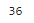
- 문서를 불러오기 위해 TextLoader를 사용하여 text_loader 변수에 txt 문서를 불러와 저장
- text_splitter는 RecursiveCharacterTextSplitter 클래스의 객체로 chunk의 크기를 100개로 쪼개도록 함. ( RecursiveCharacterTextSplitter는 문서를 chunk로 분할할 때 최대한 비슷한 의미를 가진 모든 단락을 길게 유지하려고 하는 특징을 가지고 있음.)
- text_splitter.create_documents()에 불러온 문서를 넣어 실행하면 총 36개의 단락으로 나누어짐.
texts 변수를 출력해보면
texts
◆ Text Embedding Models
텍스트 임베딩 모델은 OpenAI나 허깅 페이스와 같은 곳에서 제공하는 임베딩을 사용할 수 있도록 표준화된 인터페이스를 제공한다. 텍스트 임베딩 모델로 텍스트를 벡터로 변환하면 벡터의 유사도 검색과 같은 작업을 할 수 있다.
OpenAI 임베딩을 하기 위해서는 먼저 OpenAI의 오픈소스 라이브러리인 틱토큰(tiktoken)을 설치해야 한다.
pip install tiktoken
OpenAI 임베딩을 위해 필요한 모듈을 import한 후 객체를 생성하고, openai_embedding.embed_documents() 함수에 벡터로 변환할 텍스트를 리스트로 입력한다.
from langchain.embeddings import OpenAIEmbeddings
openai_embedding = OpenAIEmbeddings()
embeddings = openai_embedding.embed_documents(
["안녕하세요", "무엇을 도와드릴까요?", "어서오세요", "도움이 필요해요"]
)
print("임베딩 수:", len(embeddings))
print("임베딩 차원:", len(embeddings[0]))
print("임베딩 차원:", len(embeddings[1]))
print("embeddings[0]:", embeddings[0])
벡터로 변환 시 단일 문장을 임베딩할 때는 openai_embedding.embed_query()를 사용한다.
embeddings = openai_embedding.embed_query("안녕")
embeddings[:5]
3) Vector Store
벡터 스토어는 랭체인을 통해 생성된 벡터를 벡터 DB에 효율적으로 저장하고 검색하는 기능을 제공한다.
랭체인은 50개 이상의 벡터 DB(Chroma, FAISS 등)를 지원하고 있는데, 벡터 DB에 텍스트를 저장하기 위해서는 먼저 벡터 DB를 설치해야 한다. (여기서는 Chroma DB 사용)
pip install chromadb
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
openai_embedding = OpenAIEmbeddings()
db = Chroma.from_texts(
texts = ["안녕", "안녕하세요", "반갑습니다", "반가워요"],
embedding = openai_embedding
)
similar_texts = db.similarity_search("안녕")
similar_texts
- Chroma DB에 텍스트 데이터를 벡터 데이터로 저장하기 위해서 Chroma.from_texts()를 사용하여 texts 매개변수에 저장할 텍스트 리스트를 입력
- embedding 매개변수에 벡터 변환을 위해 사용한 임베딩을 인작밧으로 넣어 Chroma DB 벡터에 저장
- db.similarity_search("검색어")를 통해 입력한 검색어 벡터와 유사한 내용의 텍스트를 Chroma DB에서 가져와 출력 (기본적으로 유사한 5개의 결과 전달)
4) 리트리버
사용자가 LLM 모델에 관한 질문을 하면 관련된 문서를 반환하는 인터페이스로, 검색을 쉽게 할 수 있는 기능을 가진 모듈이다.
https://python.langchain.com/v0.2/docs/concepts/#retrievers
Conceptual guide | 🦜️🔗 LangChain
This guide provides explanations of the key concepts behind the LangChain framework and AI applications more broadly.
python.langchain.com
4. 에이전트(Agent)
에이전트는 랭체인을 사용하여 LLM을 활용할 때 사용하는 중요한 모듈로, 사용자가 입력한 프롬프트에 근거해서 다양한 도구(Tool)를 호출할 수 있으며, 반복적인 작업을 결정하거나 작업을 실행하며 지시가 완료될 때까지 결과를 관찰하는 체인으로, 챗GPT의 플러그인과 비슷한 역할을 한다.
1) 에이전트
◆ 에이전트 실행 사이클
에이전트의 실행 사이클: Input ▶ Action ▶ Observation ▶ Thought ▶ Answer
- Input: Agent에게 작업 할당
- Action: 사용 툴 결정
- Observation: 툴에서 출력된 결과 확인
- Thought: Agent에 최정 답변을 얻기 위해 작업 할당
- Answer: 최종 답변
에이전트는 최종 답변에 도달할 때까지 위 과정을 반복한다.
◆ 랭체인에서 사용할 수 있는 에이전트 타입
- Zero-shot ReAct: 작업과 도구 설명을 보고 사용할 도구 결정
- Structured input ReAct: input이 여러 개인 툴을 사용할 때 사용
- Conversational: 대화 + ReAct로 대화를 저장하기 위한 메모리 필요
- Self-ask with search: 인터넷 검색 후 답변하는 에이전트, 검색 툴 필요
- ReAct document store: 문서 저장소 + 리액트(ReAct)로 문서 검색 툴 필요
기본적으로는 Zero-shot ReAct 사용
2) Tool
랭체인에서는 많은 툴을 지원하고 있다.
Tools | 🦜️🔗 LangChain
Tools are utilities designed to be called by a model: their inputs are designed to be generated by models, and their outputs are designed to be passed back to models.
python.langchain.com
[주요 사용 툴의 기능]
- Python REPL Tool: Python 코드를 언어 모델 내에서 실행할 수 있는 도구로, 계산 및 데이터 처리를 위한 스크립트 실행이 가능하며, 모델이 Python 코드를 생성하고 직접 실행할 수 있다.
- SerpAPI: 구글 검색 API를 이용하여 실시간 검색 결과를 가져올 수 있는 도구로, 검색 쿼리를 실시간으로 처리하여 최신 정보를 모델에게 제공할 수 있다.
- Wikipedia: Wikipedia에서 정보를 검색하고 문서를 가져올 수 있는 도구로, 언어 모델이 백과사전의 방대한 자료를 이용하여 학습하거나 질의 응답 형태로 사용할 수 있다.
- Wolfram Alpha: 수학적 계산 및 다양한 지식 기반의 질의 응답을 처리할 수 있는 도구로, 복잡한 계산을 해결하거나 데이터베이스에서 정보를 검색하는 데 유용하다.
- Google Search: 구글 검색을 통해 실시간으로 웹 검색 결과를 가져올 수 있는 도구로, 실시간으로 최신 정보를 검색하여 모델의 응답에 반영할 수 있다.
- DuckDuckGo Search: DuckDuckGo 검색 엔진을 통해 검색 결과를 가져올 수 있는 도구로, 개인정보 보호를 중시하면서도 실시간 검색을 수행할 수 있다.
- OpenWeatherMap: 날씨 정보를 실시간으로 검색할 수 있는 도구로, 특정 지역의 현재 날씨 및 예보를 가져올 수 있어, 다양한 애플리케이션에서 활용 가능하다.
- NewsAPI: 최신 뉴스 기사를 검색하고 가져올 수 있는 도구로, 특정 주제나 키워드에 대한 최신 뉴스를 실시간으로 확인할 수 있다.
- Twilio: SMS 및 전화 기능을 통해 언어 모델이 사용자와의 상호작용을 강화할 수 있는 도구로, 메시지를 보내거나 전화를 걸고 받을 수 있어, 고객 서비스 등에서 활용할 수 있다.
- Slack: Slack과 통합하여 메시지 기반의 상호작용을 할 수 있는 도구로, Slack 채널을 통해 실시간으로 대화하고 알림을 보낼 수 있다.
- Zapier: 다양한 앱과 서비스 간의 자동화를 구현할 수 있는 도구로, 언어 모델이 다양한 서비스와 통합되어 자동으로 작업을 수행할 수 있게 한다.
- Requests: 특정 사이트에서 정보를 가져와야 할 때 사용하는 도구로, 입력은 URL이어야 하며 출력은 웹 페이지의 텍스트가 된다.
- Terminal: 터미널에서 명령 실행.
- pal-math: 수학 문제를 해결할 때 사용하는 언어 모델.
- llm-math: 수학에 대한 질문에 답할 때 사용.
- open-meteo-api: OpenMeteo API에서 날씨 정보를 얻고자 할 때 유용한 도구로, 입력은 이 API가 답변할 수 있는 자연어로 된 질문이어야 한다.
- tmdb-ap: 영화 정보를 얻고자 할 때 사용한다.
3) Agent and Tool 사용법
구글 검색을 통해 마이클 조던의 현재 나이를 검색하고 나이를 '10'으로 나누는 것을 랭체인으로 실행해 본다. 먼저 구글 검색에 사용할 SerpApi 툴을 사용하기 위해 사이트에 가입하여 API 키를 발급받는다.
SerpApi: Google Search API
SerpApi is a real-time API to access Google search results. We handle proxies, solve captchas, and parse all rich structured data for you.
serpapi.com
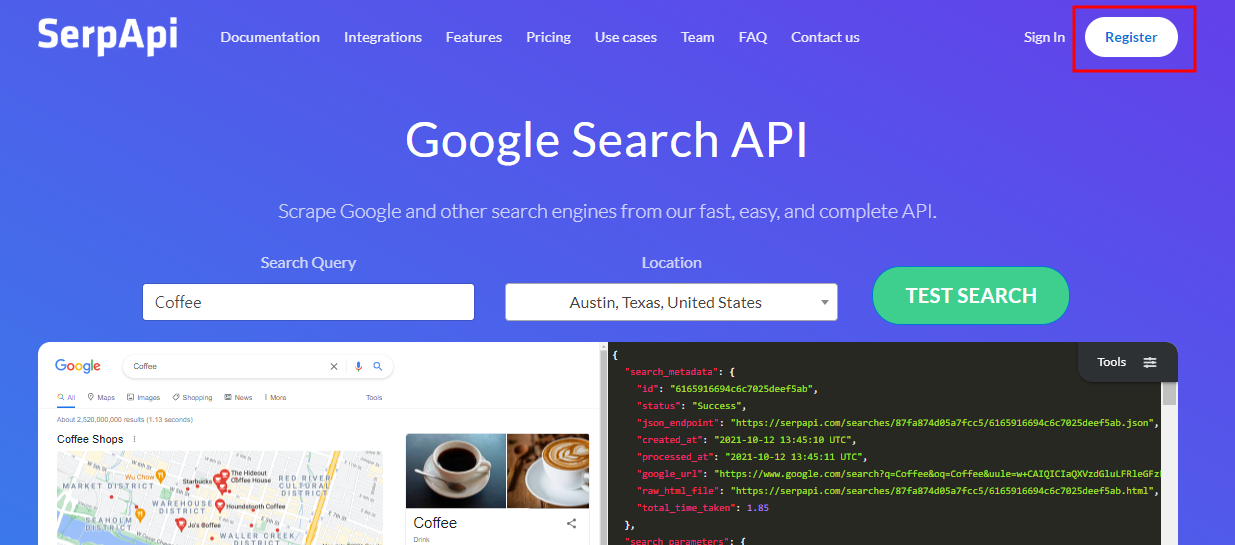
해당 사이트에 접속한 후 [Register] 버튼을 눌러 회원 가입을 한다. 필자의 경우 구글 계정으로 연동했으며,
구글 계정 연동 후 구글 메일에 들어가 메일 인증을 하고, 휴대전화 인증을 한 뒤 [Subcribe] 버튼을 눌렀다. (무료 플랜)
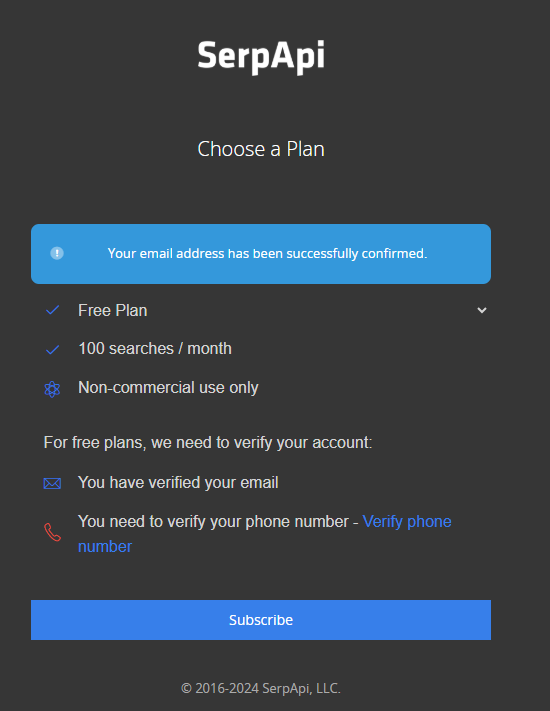
전화 인증까지 하고 구독 버튼을 누르면 API 키를 확인할 수 있다. (노출되지 않게 복사하여 잘 보관한다.)

그리고 시스템 환경 변수 편집으로 들어가서 환경 변수에 해당 키를 등록해놔도 좋다.
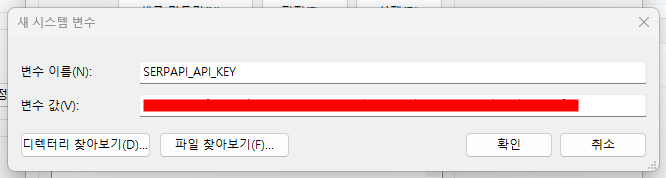
그보다 더 간단하게 환경 변수에 등록하려면 주피터노트북에서 하단의 코드를 입력한다.
os.environ["SERPAPI_API_KEY"] = "발급받은 키"
그 후에 serpapi 툴을 사용하기 위해 google-search-results 라이브러리도 설치한다.
pip install google-search-results
또한, llm-math를 사용하기 위해 numexpr 라이브러리도 설치해준다.
pip install numexpr
이제 주피터노트북으로 넘어가서 코드를 작성해 본다.
from langchain.agents import (
load_tools,
initialize_agent,
AgentType
)
from langchain.chat_models import ChatOpenAI
# 환경 변수에서 SerpAPI API 키 가져오기
SERPAPI_API_KEY = os.getenv('SERPAPI_API_KEY')
# 환경 변수 설정 확인
if not SERPAPI_API_KEY:
raise ValueError("SerpAPI API 키가 설정되지 않았습니다. 환경 변수 SERPAPI_API_KEY를 설정해주세요.")
chat = ChatOpenAI(temperature=0)
tools = load_tools(['serpapi', 'llm-math'], llm=chat, serpapi_api_key=SERPAPI_API_KEY)
agent = initialize_agent(tools, llm=chat, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True)
agent.run("마이클 조던의 나이를 10으로 나누면?")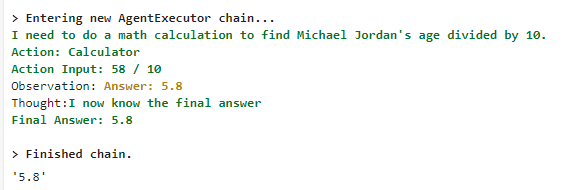
▶ 검색을 통해 마이클 조던의 나이가 58세인 것을 찾고 이 값을 10으로 나누어 최종 결과로 5.8을 전달하였다.
이제 인터넷 검색과 유튜브 검색을 사용해 본다. API 키가 필요 없는 DuckDuckGO 툴을 사용한다.
두 개의 툴(유튜브 검색, DuckDuckGo)을 사용하기 위해 라이브러리를 먼저 설치한다.
# 아나콘다 프롬프트에서 한 줄씩 입력
pip install youtube_search
pip install duckduckgo-search
아래 예제는 검색을 통해 BTS Dynamite 곡을 찾고 뮤직비디오를 보여 주는 유튜브 링크를 찾는 예제이다.
from langchain.tools import YouTubeSearchTool
from langchain.chat_models import ChatOpenAI
from langchain.agents import (
load_tools,
initialize_agent,
AgentType
)
llm = ChatOpenAI(temperature=0)
tools = load_tools(["ddg-search"]) + [YouTubeSearchTool()]
agent = initialize_agent(
tools,
llm,
agent= AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
result = agent("BTS Dynamite 뮤직비디오를 찾아 유튜브 링크를 알려줘")
답변을 받은 링크를 클릭해보면
https://www.youtube.com/watch?v=gdZLi9oWNZg&pp=ygUMQlRTIER5bmFtaXRl
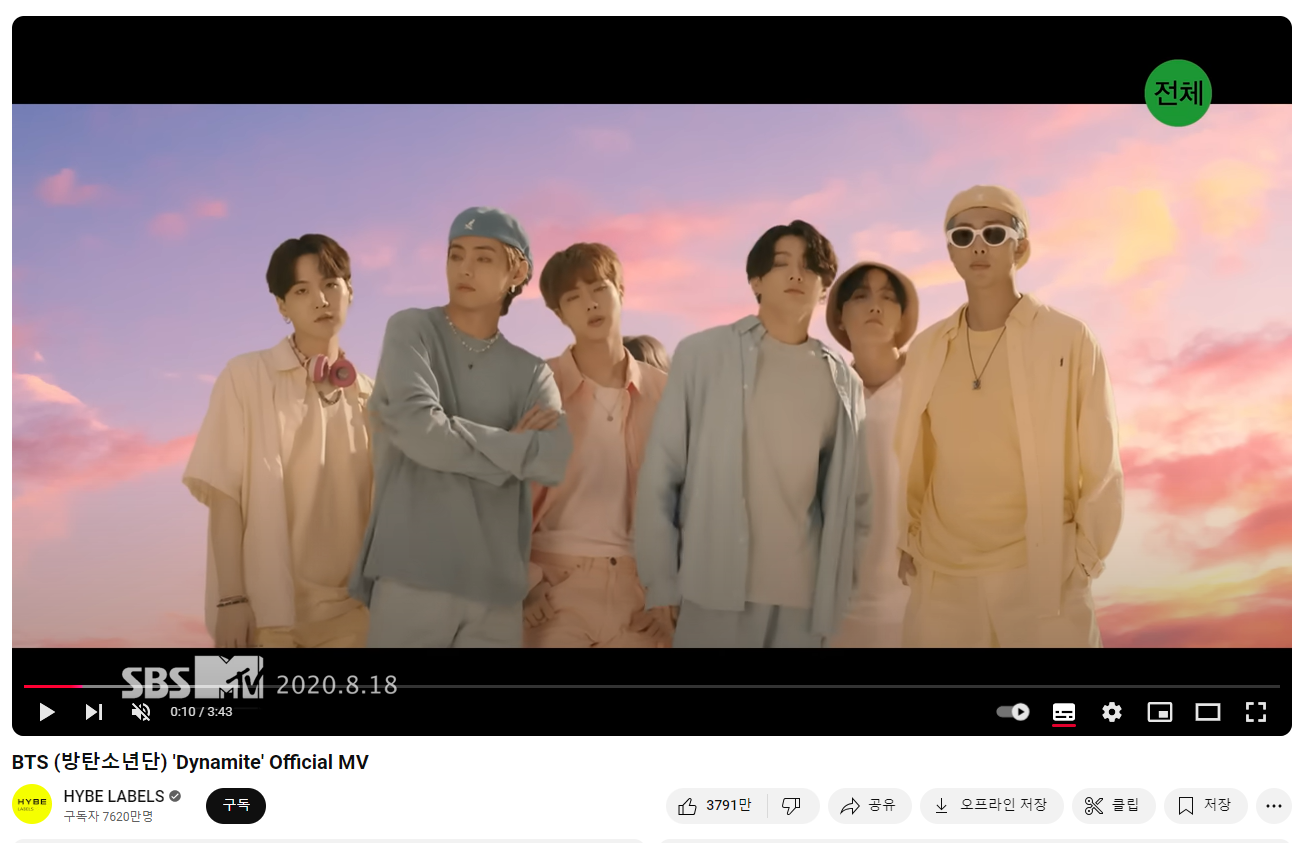
BTS (방탄소년단)의 Dynamite 공식(!) 뮤직비디오가 나온다.
다음 내용
[Gen AI] 랭체인을 활용한 챗봇 업그레이드 - 3
이전 내용 [Gen AI] 랭체인을 활용한 챗봇 업그레이드 - 2이전 내용 [Gen AI] 랭체인을 활용한 챗봇 업그레이드 - 1이전 내용 [Gen AI] 그라디오로 제작한 챗봇 허깅 페이스에 업로드하기이전 내용 [Ge
puppy-foot-it.tistory.com
[출처]
Hey, 파이썬! 생성형 AI 활용 앱 만들어줘
랭체인 공식 홈페이지
https://stackoverflow.com/questions/76600384/unable-to-read-text-data-file-using-textloader-from-langchain-document-loaders-l
'[파이썬 Projects] > <파이썬 Gen AI, LLM>' 카테고리의 다른 글
| [Gen AI] 그라디오 챗봇 업그레이드 (2) | 2024.12.19 |
|---|---|
| [Gen AI] 랭체인을 활용한 챗봇 업그레이드 - 3 (2) | 2024.12.13 |
| [Gen AI] 랭체인을 활용한 챗봇 업그레이드 - 1 (0) | 2024.12.13 |
| [Gen AI] 그라디오로 제작한 챗봇 허깅 페이스에 업로드하기 (1) | 2024.12.13 |
| [Gen AI] 그라디오로 챗봇 제작하기 - 3 (소설봇) (1) | 2024.12.12 |



