이전 내용
[LLM] 텍스트 분류 모델 학습시키기
이전 내용 [LLM] 허깅페이스 라이브러리 사용법 익히기허깅페이스 [AI 플랫폼] 허깅페이스: AI와 머신러닝의 새로운 지평허깅페이스란? 허깅페이스(Hugging Face)는 자연어 처리(NLP)와 머신러닝(ML)
puppy-foot-it.tistory.com
GPU 효율적인 학습 (feat. 구글 코랩)
GPU(Graphic Processing Unit)은 딥러닝 모델처럼 연산을 빠르게 처리하는데 특화된 장치로, 최근 LLM의 등장과 함께 주목받고 있다. GPU는 한정된 메모리를 갖고 있어 LLM처럼 모델의 크기가 크면 더 많은 GPU가 필요해진다. 그러나 GPU는 가격이 비싸 풍부하게 사용이 어려워 최근에는 더 많은 사람이 발전된 AI 기술을 사용할 수 있도록 GPU를 효율적으로 활용할 수 있는 방법을 찾기 위한 기술 발전이 빠르게 이뤄지고 있다.
이번에는
- 딥러닝 모델의 저장과 연산에 사용하는 데이터 타입
- GPU에서 딥러닝 연산을 수행할 경우 어떤 데이터가 메모리를 사용하는지
- GPU를 1개 사용할 때도 메모리를 효율적으로 사용할 수 있는 방법인 그레이디언트 누적과 그레이디언트 체크포인팅
- 분산 학습과 분산 학습 시 같은 데이터가 여러 GPU에 저장돼 비효율적으로 사용되는 문제를 해결한 마이크로소프트의 딥스피드 제로
- 모델을 학습시킬 때 전체 모델을 업데이트하지 않고 모델의 일부만 업데이트하면서도 뒤어난 학습 성능을 보이는 LoRA
- 모델을 적은 비트를 사용하는 데이터 타입으로 저장해 메모리 효율성을 높인 QLoRA
에 대해 알아본다.
실습을 위해 구글 코랩에서 아래의 명령어를 통해 라이브러리들을 설치한다.
!pip install transformers==4.40.1 datasets==2.19.0 accelerate==0.30.0 peft==0.10.0 bitsandbytes==0.43.1 -qqqGPU에 올라가는 데이터 살펴보기
◆ OOM(Out of Memory) 에러: 한정된 GPU 메모리에 데이터가 가득차 더 이상 새로운 데이터를 추가하지 못해 생기는 에러.
과거에는 딥러닝 모델을 32비트 부동소수점 형식을 사용했으나, 성능을 높이기 위해 점점 더 파라미터가 높은 모델을 사용하기 시작했고 모델의 용량이 커지게 되었다. 이런 문제를 해결하기 위해 성능은 유지하면서 점점 더 적은 비트의 데이터 타입을 사용하는 방향으로 딥러닝 분야가 발전해 최근에는 주로 16비트로 수를 표현하는 fp16이나 bf16을 주로 사용한다.
모델 파라미터의 데이터 타입이 더 많은 비트를 사용할수록 모델의 용량이 커지기 때문에 더 적은 비트로 모델을 표현하는 양자화(quantization) 기술이 개발됐다. 양자화 기술에는 더 적은 비트를 사용하면서도 원본 데이터의 정보를 최대한 소실 없이 유지하는 것이 핵심 과제라고 할 수 있다.
GPU 메모리에는 다음과 같은 데이터가 저장되는데,
- 모델 파라미터
- 그레이디언트
- 옵티마이저 상태
- 순전파 상태
사용하려는 모델마다 학습과 추론에 어느 정도의 GPU 메모리가 필요한지 계산하기 어려울 수 있는데, 허깅페이스는 모델 메모리 계산기를 제공해 허깅페이스 모델 허브의 모델을 활용할 때 GPU 메모리가 얼마나 필요한지 알려주고 있다.
https://huggingface.co/docs/accelerate/usage_guides/model_size_estimator
Model memory estimator
One very difficult aspect when exploring potential models to use on your machine is knowing just how big of a model will fit into memory with your current graphics card (such as loading the model onto CUDA). To help alleviate this, Accelerate has a CLI int
huggingface.co

사용하려는 모델을 입력하고 모델의 데이터 타입을 설정하면 모델의 파라미터 수에 따라 모델의 크기, 학습에 필요한 메모리를 제공해 준다.
여기서는 EleutherAI가 제공하는 한국어 모델인 EleutherAI/polyglot-ko-1.3b 를 활용하여 실제로 코드를 통해 모델을 불러오고 학습을 수행하면서 얼마나 많은 GPU 메모리를 사용하는지 확인해 본다.
# 메모리 사용량 측정을 위한 함수 구현
import torch
def print_gpu_utilization():
if torch.cuda.is_available():
used_memory = torch.cuda.memory_allocated() / 1024**3
print(f"GPU 메모리 사용량: {used_memory:.3f} GB")
else:
print("런타임 유형을 GPU로 변경하세요.")
print_gpu_utilization()
▶ 파이토치의 메모리 확인 함수인 torch.cuda.memory_allocated() 를 사용해 메모리 사용량을 기가바이트 단위로 반환하는 함수인 print_gpu_utilization을 정의한다.
- 모델과 토크나이저를 불러오는 함수 정의
다음으로 모델과 토크나이저를 불러오는 함수를 정의한다.
이 함수는 사용할 모델과 토크나이저의 아이디(model_id)와 효율적인 모델 학습을 사용할지와 어떤 방식을 사용할지 입력받는 peft 인자를 받는다.
# 모델을 불러오고 GPU 메모리와 데이터 타입 확인
from transformers import AutoModelForCausalLM, AutoTokenizer
from huggingface_hub import login
from google.colab import userdata
token = userdata.get('HUGGINGFACE_TOKEN')
login(token=token)
def load_model_and_tokenizer(model_id, peft=None):
tokenizer = AutoTokenizer.from_pretrained(model_id)
if peft is None:
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
print_gpu_utilization()
return model, tokenizer
# Corrected model identifier
model_id = "EleutherAI/polyglot-ko-1.3b"
model, tokenizer = load_model_and_tokenizer(model_id)
print("모델 파라미터 데이터 타입: ", model.dtype)
- 그레이디언트의 메모리 사용량, 옵티마이저 상태의 메모리 사용량을 확인하는 함수 정의
이번에는 그레이디언트의 메모리 사용량을 확인하는 함수 estimate_memory_of_gradients, 옵티마이저 상태의 메모리 사용량을 확인하는 함수 estimate_memory_of_optimizer 를 정의한다.
- estimate_memory_of_gradients 함수는 인자로 모델을 받아 모델에 저장된 그레이디언트 값의 수, 값의 데이터 크기를 통해 전체 메모리 사용량을 계산한다.
- estimate_memory_of_optimizer 함수는 인자로 옵티마이저를 받아 옵티마이저에 저장된 값의 수, 값의 데이터 크기를 곱해 전체 메모리 사용량을 계산한다.
# 그레이디언트와 옵티마이저 상태의 메모리 사용량을 계산하는 함수
from transformers import AdamW
from torch.utils.data import DataLoader
def estimate_memory_of_gradient(model):
total_memory = 0
for param in model.parameters():
if param.grad is not None:
total_memory += param.grad.nelement() * param.element_size()
return total_memory
def estimate_memory_of_optimizer(optimizer):
total_memory = 0
for state in optimizer.state_values():
for k, v in state.items():
if torch.is_tensor(v):
total_memory += v.nelement() * v.element_size()
return total_memory
- 모델 학습 중간 메모리 사용량 확인하는 함수 정의
이번에는 모델을 학습시키며 중간에 메모리 사용량을 확인하는 train_model 함수를 정의한다.
# 모델의 학습 과정에서 메모리 사용량을 확인하는 train_model 정의
def train_model(model, dataset, training_args):
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
train_dataloader = DataLoader(dataset, batch_size=training_args.per_device_train_batch_size)
optimizer = AdamW(model.parameters())
model.train()
gpu_utilization_printed = False
for step, batch in enumerate(train_dataloader, start=1):
batch = {k: v.to(model.device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss = loss / training_args.gradient_accumulation_steps
loss.backward()
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
gradients_memory = estimate_memory_of_gradient(model)
optimizer_memory = estimate_memory_of_optimizer(optimizer)
if not gpu_utilization_printed:
print_gpu_utilization()
gpu_utilization_printed = True
optimizer.zero_grad()
print(f"옵티마이저 상태의 메모리 사용량: {optimizer_memory / (1024**3):.3f} GB")
print(f"그레이디언트의 메모리 사용량: {gradients_memory / (1024**3):.3f} GB")- training_args.gradient_checkpointing 설정이 있는데, 이 부분은 그레이디언트 체크포인팅 기능을 사용할지 설정하는 부분으로, True (켜기) 또는 False(끄기)를 입력할 수 있다. (기본값은 False)
- training_args.gradient_accumulation_steps 설정은 그레이디언트 누적 기능을 사용여부를 결정하는 것으로, 누적할 스텝 수에 따라 2 또는 4 등으로 설정하면 된다. (기본값은 1)
- 랜덤 데이터를 생성하는 함수 정의
모델을 학습시키기 위해서는 데이터가 필요한데, 학습 과정에서 필요한 메모리 사용량에 집중하기 위해 랜덤 데이터를 생성하는 make_dummy_dataset 함수를 정의한다.
# 랜덤 데이터셋을 생성하는 make_dummy_dataset 함수 정의
import numpy as np
from datasets import Dataset
def make_dummy_dataset():
seq_len, dataset_size = 256, 64 # 텍스트의 길이가 256이고 데이터가 64개인 더미 데이터
dummy_data = {
"input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
"labels": np.random.randint(100, 30000, (dataset_size, seq_len)),
}
dataset = Dataset.from_dict(dummy_data)
dataset.set_format("pt")
return dataset
- GPU 메모리의 데이터 삭제하는 함수 정의
GPU 메모리 데이터를 삭제하는 cleanup 함수를 정의한다. cleanup 함수에서는 전역 변수 중 GPU 메모리에 올라가는 모델의 변수와 데이터셋 변수를 삭제하고 gc.collect 함수를 통해 사용하지 않는 메모리를 회수하는 가비지 컬렉션(garbage collection)을 수동으로 수행한다. torch.cuda.empty_cache() 함수는 더 이상 사용하지 않는 GPU 메모리를 반환한다.
# 더 이상 사용하지 않는 GPU 메모리를 반환하는 cleanup 함수
import gc
def cleanup():
if 'model' in globals():
del globals()['model']
if 'dataset' in globals():
del globals()['dataset']
gc.collect()
torch.cuda.empty_cache()
- 앞서 정의한 함수를 종합한 함수 정의
마지막으로 앞서 정의한 함수를 종합해 배치 크기, 그레이디언트 누적, 그레이디언트 체크포인팅, peft 설정 등에 따라 GPU 사용량을 확인하는 gpu_memory_experiment 함수를 정의한다.
# GPU 사용량을 확인하는 gpu_memory_experiment 함수 정의
from transformers import TrainingArguments, Trainer
def gpu_memory_experiment(batch_size,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
model_id="EleutherAI/polyglot-ko-1.3b",
peft=None):
print(f"배치 크기: {batch_size}")
model, tokenizer = load_model_and_tokenizer(model_id, peft=peft)
if gradient_checkpointing == True or peft == 'qlora':
model.config.use_cache = False
dataset = make_dummy_dataset()
training_args = TrainingArguments(
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=gradient_checkpointing,
output_dir="./result",
num_train_epochs=1
)
try:
train_model(model, dataset, training_args)
except RuntimeError as e:
if "CUDA out of memory" in str(e):
print(e)
else:
raise e
finally:
del model, dataset
gc.collect()
torch.cuda.empty_cache()
print_gpu_utilization()- load_model_and_tokenizer 함수와 make_dummy_dataset 함수로 모델, 토크나이저, 데이터셋을 불러온다.
- 실험하려는 설정에 따라 학습에 사용할 인자를 설정한다
- 모델, 데이터셋, 학습 인자 준비를 마치고 train_model 함수를 통해 학습을 진행하면서 GPU 메모리 사용량을 확인한다.
- 실험이 끝난 모델과 데이터셋을 삭제하고 사용하지 않는 GPU 메모리를 반환한다.
이제 아래 코드를 실행하여 배치 크기를 늘리면서 GPU 메모리 사용량이 어떻게 변하는지 확인해 본다.
# 배치 크기를 변경하며 메모리 사용량 측정
cleanup()
print_gpu_utilization()
for batch_size in [4, 8, 16]:
gpu_memory_experiment(batch_size)
torch.cuda.empty_cache()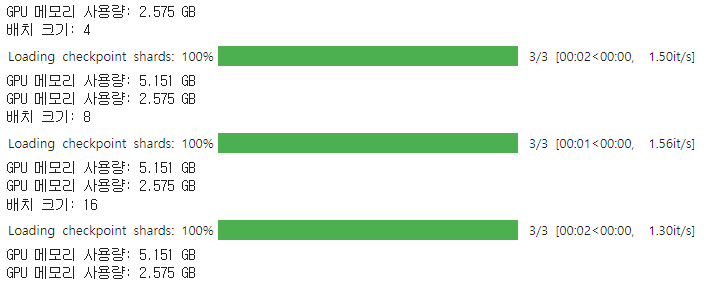
▶ 배치 크기가 증가해도 모델, 그레이디언트, 옵티마이저 상태를 저장하는 데 필요한 GPU 메모리는 동일하다.
단일 GPU 효율적으로 활용하기
이번에는 단일 GPU를 사용하면서 GPU를 더 효율적으로 사용할 수 있는 그레이디언트 누적과 그레이디언트 체크포인팅에 대해 알아본다.
- 그레이디언트 누적: 딥러닝 모델을 학습시킬 때 각 배치마다 모델을 업데이트하지 않고 여러 배치의 학습 데이터를 연산한 후 모델을 업데이트해 마치 더 큰 배치 크기를 사용하는 것 같은 효과를 내는 방법
- 그레이디언트 체크포인팅: 순전파의 계산 결과를 모두 저장하지 않고 일부만 저장해 학습 중 GPU 메모리의 사용량을 줄이는 학습 방법.
▶ 두 방법 모두 모델 학습 시에 배치 크기를 키워 모델의 학습을 더 빠르고 안정적으로 만들어 준다.
- 그레이디언트 누적을 사용하는 경우 적은 GPU 메모리로도 더 큰 배치 크기와 같은 효과를 얻을 수 있지만, 추가적인 순전파 및 역전파 연산을 수해하기 때문에 학습 시간이 증가된다.
- 딥러닝 모델에서는 모델 업데이트를 위한 그레이디언트를 계산하기 위해 순전파와 역전파를 수행하는데, 이때 역전파 계산을 위해 순전파의 결과를 저장하고 있어야 한다. 기본적인 저장 방식은 '모두' 저장하는 것인데, 이렇게 되면 GPU 메모리를 많이 차지하게 되어 역전파를 진행하면서 메모리를 절약하기 위해 사용이 끝난 데이터는 삭제한다.
그리고 메모리를 절약하기 위해 역전파를 계산할 때 필요한 최소 데이터만 저장하고 나머지는 필요할 때 다시 계산하는 방식도 사용할 수 있는데, 이 방식은 메모리를 효율적으로 사용할 수 있으나 한 번의 역전파를 위해 순전파를 반복적으로 계산해야 한다는 단점이 있다.
그레이디언트 체크포인팅은 이 두 가지 방식을 절충하기 위한 방법으로, 순전파의 전체를 저장하거나 마지막만 저장하는게 아니라, 중간중간에 값들을 저장해서 메모리 사용을 줄이고 필요한 경우 체크포인트부터 다시 계산해 순전파 계산량도 줄인다.
- 그레이디언트 누적과 그레이디언트 체크포인팅은 GPU를 1개 사용하는 학습에서도 적용할 수 있는 GPU 효율화 기법이다.
분산 학습과 ZeRO
◆ 분산 학습(distributed training): 2개 이상의 GPU를 사용해 모델을 학습시키는 방법.
- 분산 학습의 목적
- 모델 학습 속도 향상
- 1개의 GPU로 학습이 어려운 모델 다루기
※ 데이터 병렬화(data parallelism): 모델이 작아 하나의 GPU에 올릴 수 있는 경우 여러 GPU에 각각 모델을 올리고 학습 데이터를 병렬로 처리해 학습 속도를 높이는 것.
※ 모델 병렬화(model parallelism): 하나의 GPU에 올리기 어려운 큰 모델의 경우 모델을 여러 개의 GPU에 나눠서 올리는 방식.
- 파이프라인 병렬화: 딥러닝 모델의 층(layer) 별로 나눠 GPU에 올리는 것. ▶ 딥러닝 모델의 각 층별로 나눠 GPU에 올리기 때문에 딥러닝 모델의 층 순서에 맞춰 순차적으로 연산하면 결과를 얻을 수 있다.
- 텐서 병렬화: 한 층의 모델로 나눠서 GPU에 올리는 것. ▶ 하나의 층을 나눠 서로 다른 GPU에 올리며, 행렬을 분리해도 동일한 결과를 얻을 수 있도록 행렬 곱셈을 적용한다.
분산 학습을 사용하는 경우 모델이 작으면 데이터 병렬화를 통해 모델 학습 속도를 높일 수 있고, 모델이 클 경우 모델을 여러 GPU에 올려 하나의 GPU로는 불가능했던 학습을 가능하게 할 수 있다. 그러나 동일한 모델을 여러 GPU에 올리기 때문에 중복으로 모델을 저장하면서 메모리 낭비가 발생한다.
◆ 데이터 병렬화에서 중복 저장 줄이기(ZeRO)
ZeRO(Zero Redundancy Optimizer)는 2019년 마이크로소프트에서 개발되었으며, 하나의 모델을 하나의 GPU에 올리지 않고 마치 모델 병렬화처럼 모델을 나눠 여러 GPU에 올리고 각 GPU에서는 자신의 모델 부분의 연산만 수행하고 그 상태를 저장하면 메모리를 효율적으로 사용하면서 속도도 빠르게 유지할 수 있다.
허깅페이스 트랜스포머에서 ZeRO를 사용하는 방법은 하단의 링크를 확인하면 된다.
https://huggingface.co/docs/accelerate/usage_guides/deepspeed
DeepSpeed
Concepts and fundamentals
huggingface.co
효율적인 학습 방법(PEFT): LoRA
※ PEFT(Parameter Efficient Fine-Tuning): 일부 파라미터만 학습하는 방법
- LoRA(Low-Rank Adaptation): 모델 파라미터를 재구성해 더 적은 파라미터를 학습함으로써 GPU 메모리 사용량을 줄이는 방법. 학습하는 파라미터 수가 줄어들면 모델 업데이트에 사용하는 옵티마이저 상태의 데이터가 줄어드는데, LoRA를 통해 GPU 메모리 사용량이 줄어드는 부분은 바로 그레이디언트와 옵티마이저 상태를 저장하는 데 필요한 메모리가 줄어들기 때문이다.
- QLoRA(Quantized LoRA): 모델 파라미터를 양자화하는 방법.
◆ LoRA
- LoRA 설정 살펴보기
모델 학습에 LoRA를 적용할 대 결정해야 할 사항
- 파라미터 W에 더할 행렬 A와 B를 만들 때 차원r을 몇으로 할것인지: r을 작게 설정하면 학습시켜야 하는 파라미터 수가 줄어들어 GPU 메모리 사용량을 줄일 수 있으나, 그만큼 모델이 학습할 수 있는 용량이 작아져 학습 데이터의 패턴을 충분히 학습하지 못할 수 있다.
- 추가한 파라미터를 기존 파라미터에 얼마나 많이 반영할지 결정하는 알파: 알파가 커질수록 새롭게 학습한 파라미터의 중요성을 크게 고려한다고 볼 수 있다.
- 모델에 있는 많은 파라미터 중에서 어떤 파라미터를 재구성할지 결정
- 코드로 LoRA 학습하기
허깅페이스는 peft 파라이브러리를 통해 LoRA와 같은 효율적인 학습 방식을 쉽게 활용할 수 있는 기능을 제공한다.
# 모델을 불러오면서 LoRA 적용하기
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
from huggingface_hub import login
from google.colab import userdata
token = userdata.get('HUGGINGFACE_TOKEN')
login(token=token)
def load_model_and_tokenizer(model_id, peft=None):
tokenizer = AutoTokenizer.from_pretrained(model_id)
if peft is None:
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
elif peft == 'lora':
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.50,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
print_gpu_utilization()
return model, tokenizer앞서 정의했던 load_model_and_tokenizer 함수에 peft 인자를 'lora'로 설정할 경우 모델에 LoRA를 적용하는 부분을 추가했다.
- peft 라이브러리에서 LoraConfig 클래스를 사용하면 LoRA 적용 시 사용할 설정을 정의할 수 있다.
- target_modules는 LoRA를 어떤 가중치에 적용할지 정하는 것으로, 쿼리, 키, 값 가중치로 설정했다.
- get_peft_model 함수는 불러온 모델에 lora_config를 적용해 파라미터를 재구성한다.
- print_trainable_parameters() 메서드는 모델 재구성 후에 학습 파라미터의 수와 비중을 확인한다.
이제 LoRA를 적용했을 때 GPU 메모리 사용량이 어떻게 달라지는지 코드를 실행하여 확인해 본다.
# LoRA 적용 시 GPU 메모리 사용량 확인
cleanup()
print_gpu_utilization()
gpu_memory_experiment(batch_size=16, peft='lora')
torch.cuda.empty_cache()
◆ QLoRA
- QLoRA 개념:
QLoRA 는 LoRA에 양자화를 추가해 메모리 효율성을 한 번 더 높인 학습 방법인데, 양자화란 기존 데이터를 더 적은 메모리를 사용하는 데이터 형식으로 변환하는 방법을 말한다. 양자화의 핵심 과제는 기존 데이터의 정보를 최대한 유지하면서 더 적은 비트를 사용하는 데이터 형식으로 변환하는 것이다.
QLoRA는 4비트 형식으로 모델을 저장하며 (LoRA는 16비트), 학습 도중 OOM 에러가 발생하지 않고 안정적으로 진행할 수 있도록 페이지 옵티마이저(page optimizer) 기능을 활용했다.
- 4비트 양자화와 2차 양자화
변환하려는 데이터 타입의 경우 적은 비트 수를 사용하기 때문에 하나하나의 수가 낭비되지 않고 사용되는 것이 좋은데, 입력이 정규 분포라는 가정을 활용하면 모델의 성능을 거의 유지하면서도 빠른 양자화가 가능해진다.
2차 양자화(double quantization)는 QLoRA 논문에서 제안된 양자화를 수행한 4비트 부동소수점 데이터 형식인 NF4 양자화 과정에서 생기는 32비트 상수도 효율적으로 저장하고자 한다. 2차 양자화를 수행하면 이전에는 양자화 상수를 저장하기 위해 32비트 데이터 256개를 저장했지만 이후에는 8비트 데이터 256개와 양자화 상수 c를 저장하기 위한 32비트 데이터 1개만 저장하면 된다.
- 페이지 옵티마이저
페이지 옵티마이저: 엔비디아의 통합 메모리를 통해 GPU가 CPU 메모리(RAM)를 공유하는 것을 말한다.
GPU가 처리해야 할 데이터가 많을 때 모든 데이터를 GPU 메모리에 담을 수 없다면 일부 데이터를 CPU의 메모리에 보관했다가 해당 데이터가 필요해지면 CPU 메모리에서 GPU 메모리로 옮겨 처리한다.
※ 페이징: 가상 메모리에서 운영체제가 램이 가득찰 때 일부 데이터를 디스크로 옮기고 필요할 때 다시 램으로 데이터를 불러오는 것.
- 코드로 QLoRA 학습하기
허깅페이스 코드를 통해 QLoRA 학습을 진행하기 위해 허깅페이스와 통합돼 있는 bitsandbytes 라이브러리를 활용하면 모델을 불러올 때 4비트 양자화를 간단히 수행할 수 있다.
# 4비트 양자화 모델 불러오기
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4vit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
그리고 앞서 보완했던 load_model_and_tokenizer 함수에 QRoLA 모델을 불러오는 부분도 추가한다.
# 모델을 불러오면서 LoRA 적용하기
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from huggingface_hub import login
from google.colab import userdata
token = userdata.get('HUGGINGFACE_TOKEN')
login(token=token)
def load_model_and_tokenizer(model_id, peft=None):
tokenizer = AutoTokenizer.from_pretrained(model_id)
if peft is None:
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
elif peft == 'lora':
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.50,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
elif peft == 'qlora':
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.50,
bias="none",
task_type="CAUSAL_LM"
)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4vit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
print_gpu_utilization()
return model, tokenizer- 4비트 양자화와 2차 양자화를 수행하기 위해 BitsAndBytesConfig 클래스를 사용해 양자화 설정 정의
- 양자화 설정인 bnb_config를 사용해 모델 불러오기
- prepare_model_for_kbit_training 함수는 모델을 학습시키기 위한 준비 과정
- get_peft_model 함수는 LoRA 설정을 적용하기 위한 함수
- print_trainable_parameters() 메서드는 학습 가능한 파라미터 수를 확인하기 위함
새롭게 추가한 함수로 QRoLA 모델을 불러와 배치 크기 16일 때 메모리 사용량을 확인해 본다.
# QLoRA 적용 시 GPU 메모리 사용량 확인
cleanup()
print_gpu_utilization()
gpu_memory_experiment(batch_size=16, peft='qlora')
torch.cuda.empty_cache()
다음 내용
[출처]
LLM을 활용한 실전 AI 어플리케이션 개발
허깅페이스
'[파이썬 Projects] > <파이썬 Gen AI, LLM>' 카테고리의 다른 글
| [LLM] 모델 가볍게 만들기 (0) | 2025.01.02 |
|---|---|
| [LLM] sLLM 학습하기 (0) | 2024.12.30 |
| [LLM] 텍스트 분류 모델 학습시키기 (2) | 2024.12.27 |
| [LLM] 허깅페이스 라이브러리 사용법 익히기 (4) | 2024.12.27 |
| [Gen AI] 스테이블 디퓨전 API (이 아닌 stability.ai API 사용법) (3) | 2024.12.22 |



