프로젝트 개요
2차 프로젝트를 시작하게 되었다.
이번에 해야할 프로젝트는 데이터를 이용한 대시보드 웹 페이지를 구축하는 것인데, 해당 대시보드에는 데이터를 분석하여 시각화 하는 작업이 포함되어야 하고, 그중 반드시 하나 이상의 머신러닝을 통한 분석이 포함되어야 한다.
기반이 되는 데이터에는
- 고객 관련 데이터
- 판매 관련 데이터
- 마케팅 관련 데이터
였으며, 그 중 우리 조는 가위바위보에 져서(!) 마케팅 관련 데이터를 기반으로 작업을 진행해야 한다.
첫번째 순서: 데이터를 어떻게 마련할 것인가
가장 먼저 해야할 일은 마케팅 관련 데이터를 수집해야 한다는 것인데, 우선 시각화를 하려면 (적어도 웹페이지에서 구현했을 때 빈약해 보이지 않으려면) 많은 양의 데이터가 필요했다.
데이터를 마련하는 데에는 크게 수집해서 그대로 쓰던지, 수집해서 우리에 맞게 가공을 하던지, 아니면 직접 가상의 데이터를 만들던지 하는 방법들이 있을 것이다.
그 중에서 우리 조는 처음에 상황에 맞는 데이터를 찾아보자 라고 생각해서 찾아봤지만, 마땅한 데이터를 찾기는 어려웠다. (캐글 같은 데이터셋이 많이 있는 사이트를 돌아다녀봤다.)
그래서 온라인 광고 마케터로 근무하고 있는 지인에게 데이터를 요청하여 받았으나, 쓰기에는 가공 작업(특정 상호 등이 노출되지 않게끔 등) 을 거쳐야 하기 때문에 써야할 지에 대해 고민이 많았다.
그러던 중, 우리 조원분께서 하루만에 가상 데이터와 그에 대한 웹페이지 대시보드까지 만들어서 보여줬다. (챗gpt 같은 생성형 AI를 통해 만들었다고 한다.) 이걸 보니.. 한편으로는 대단하면서도, 한편으로는 개발자라는 직무에 대한 현타가 좀 왔다.
아무튼! 해당 데이터와 대시보드는 참고용으로 사용하기로 하고, 마지막 수업 시간에 (보통은 복습 시간을 가진다.) 조원들과 필요 데이터에 대한 합의를 도출하기로 하였다.
[필요 데이터 가정]
- 데이터 기간: 2023년 1월 1일 ~ 2024년 12월 31일 (운영 기간: 2년)
- 해당 기간 동안 오프라인 이벤트, 온라인 (키워드) 광고를 동시 진행하였다고 가정
이렇게 두 가지를 정하고, 내가 그에 맞는 데이터를 생성하기로 정했다.
가상의 데이터 생성하기
1. 온라인 광고 데이터
처음에는 예전에 온라인 광고 업체에서 마케터로 근무할 때 사용했던 보고서를 날짜를 바꾸고, 데이터를 늘려서 사용할까 싶었는데, 그래도 프로그래밍을 배우는 입장에서 직접 코딩으로 만들어보자 생각했다.

◆ 가상의 온라인 키워드 광고 보고서 데이터 생성하기
- 필요한 라이브러리 import
# 필요한 라이브러리 import
import pandas as pd
import numpy as np
import random
- DataFrame 생성하기
- 기준 날짜를 지정하고
- 키워드 광고에는 10개의 키워드만 사용했다고 가정하고, 많이 쓰일 만한 키워드를 지정한다.
- 그리고 반복문을 통해 날짜별로 키워드별 노출수, 클릭수를 random 모듈을 통해 임의의 수를 생성하여 대입해 준다.
- 노출수와 클릭수의 경우, 이중반복문 안에 넣어 키워드별로 수치를 다르게 출력하도록 한다.
# 날짜 범위 생성
date_range = pd.date_range(start="2023-01-01", end="2024-12-31", freq='D')
# 대표 키워드 10개 설정
recycling_keywords = [
"재활용 방법", "재활용 분리 배출", "재활용 쓰레기", "재활용 아이디어",
"재활용 센터", "재활용 법률", "플라스틱 재활용", "재활용의 중요성",
"재활용 교육", "재활용 통계"
]
# 결과를 저장할 리스트 초기화
raw_data = {
"날짜": [],
"키워드": [],
"노출수": [],
"클릭수": []
}
# 날짜별로 여러 개의 키워드를 할당
for date in date_range:
num_keywords = random.randint(1, len(recycling_keywords)) # 키워드 수 무작위 선택
chosen_keywords = random.sample(recycling_keywords, num_keywords) # 무작위로 키워드 선택
for keyword in chosen_keywords:
exposures = random.randint(1, 1000) # 각 키워드에 대해 랜덤으로 노출수 생성
# 클릭수는 노출수 이하로 설정
clicks = random.randint(0, min(exposures, 300)) # 클릭수는 노출수 및 300 이하
# 데이터 추가
raw_data["날짜"].append(date) # 날짜 추가
raw_data["키워드"].append(keyword) # 선택된 키워드 추가
raw_data["노출수"].append(exposures) # 노출수 추가
raw_data["클릭수"].append(clicks) # 클릭수 추가
data = pd.DataFrame(raw_data) # DataFrame 생성
data.head(15) # 상위 15개 데이터 출력
- 클릭률과 클릭비용, 총비율 열 생성
- 클릭률 = 클릭수 / 노출수
- 클릭비용 = 임의의 정수
- 총비용 = 클릭수 * 클릭비용
# 클릭률, 클릭비용, 총비용 열 생성
data["클릭률"] = data["클릭수"] / data["노출수"]
data["클릭비용"] = [random.randint(0, 200) for _ in range(len(data["노출수"]))] # 클릭비용(CPC)의 경우, 랜덤으로 생성
data["총비용"] = data["클릭수"] * data["클릭비용"]
data.head()
몇 개의 행을 가진 데이터가 생성했는지 확인해 본다.
# 데이터 정보 확인
data.info()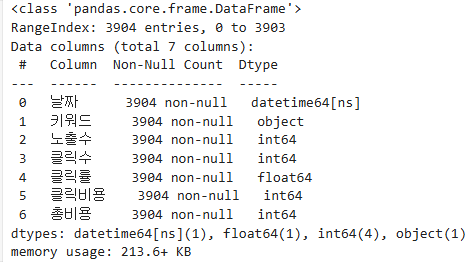
▶ 블로그 포스팅하면서도 몇 번 수정해서 데이터 수가 다르다.
- 전환수와 전환율 구하기
- 전환의 경우, 홈페이지에 접속하여 특정 행위를 한 것을 의미하는 데, 예를 들어 보험회사 웹사이트에 들어가서 상담 버튼을 누르는 것이 전환의 예라고 볼 수 있다.
- 전환율 = 클릭수 / 전환
# 전환수, 전환율 구하기
data["전환수"] = [random.randint(0, min(clicks, 10)) for _ in range(len(data["날짜"]))] # 전환수의 경우, 클릭수보다 낮게
data["전환율"] = (data["전환수"] / data["클릭수"]) * 100 # 전환율은 클릭 나누기 전환
data.tail()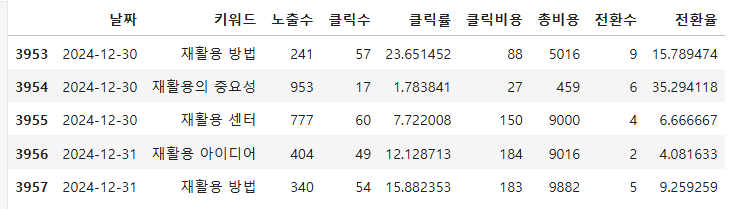
- csv 로 저장
이렇게 생성한 데이터를 csv 파일로 저장하여 팀원에게 공유해 줬다.
# CSV 파일로 저장
data.to_csv("recycling_online.csv", index=False, encoding='utf-8-sig') # index=False는 인덱스 열을 저장하지 않도록 설정가상의 데이터 생성하기
2. 오프라인 이벤트 데이터
이번엔 오프라인 이벤트용 가상의 데이터를 생성해 본다.
- 필요한 라이브러리 import
# 필요한 라이브러리 import
import pandas as pd
import numpy as np
import random
◆ 기존 데이터 불러오기
이전에 우리 조원이 AI를 통해 생성한 데이터를 불러와 본다.
data = pd.read_csv('recycle_campaign.csv',encoding='utf-8-sig')
data.head()
▶ 필자가 생각하기에 오프라인 이벤트를 했다고 가정할 경우, 이 데이터를 쓰기에는 운영 지표로 어떤 것을 말해줘야 할지 감이 안 와서 다시 가공하기로 한다.
◆ 기존 데이터에서 사용할 수 있는 칼럼의 고유값 확인해 보기
기존 데이터에서 지역, 캠페인 홍보 방식, 성별은 활용을 해보는 게 좋을 거 같아 unique() 를 통해 고윳값을 확인해 본다.
# 새로운 데이터 생성 위해 중요 칼럼별 고유값 확인
cities = data["지역"].unique()
cam_methods = data["캠페인 홍보 방식"].unique()
gender = data["성별"].unique()
cols = cities, cam_methods, gender
for i, col in enumerate(cols):
print({i: col})
▶ 최종적으로는 이 데이터를 활용하기 보다는, 이 데이터를 힌트 삼아 새로운 데이터셋을 생성해 보기로 결정했다.
◆ 새로운 데이터프레임 생성하기
- 기간에 맞게 날짜 생성
- 지역은 우리나라 특별시, 광역시, 자치도, 세종시로 기준을 잡기로 한다.
- 연령의 경우, 처음에는 10대~70대 이상으로 나눠서 진행해 봤으나, 생성되는 데이터가 너무 많아서 4개로 줄이기로 했다.
- 성별은 남, 녀
- 재활용 관련 이벤트의 경우, 오프라인 행사로 하면 좋을 게 뭐가 있을지를 챗gpt에게 물어봤다.
- 이제 반복문을 통해 대량의 데이터를 생성한다.
- 여기서는 지역 내에 각 지역별로 성별과 연령대별 방문자가 다 나올 수 있게 해줬고, 이벤트는 각 지역에서 하루 당 하나의 이벤트만 한다는 가정을 했다. (예. 23년 1월 1일 인천에서는 '업사이클링마켓'만 진행)
# 날짜 범위 생성
date_range = pd.date_range(start="2023-01-01", end="2024-12-31", freq='D')
# 지역 설정
cities = [
'부산', '대구', '인천', '대전', '울산', '광주', '서울',
'경기', '강원', '충북', '충남', '전북', '전남', '경북',
'경남', '세종', '제주'
]
# 연령대 설정 - 행이 너무 많아지므로, 연령대 범위 축소
#ages = ['10대', '20대', '30대', '40대', '50대', '60대', '70대 이상']
ages = ['청소년', '청년', '장년', '노년']
genders = ["남", "여"]
# 재활용 캠페인 오프라인 행사 제목 리스트
events = ["워크숍 개최", "재활용 품목 수집 이벤트", "재활용 아트 전시",
"게임 및 퀴즈", "커뮤니티 청소 활동", "업사이클링 마켓", "홍보 부스 운영"]
# 결과를 저장할 리스트 초기화
raw_data = {
"날짜": [],
"지역": [],
"방문자수": [],
"연령대": [],
"성별": [],
"이벤트 종류": [],
}
# 날짜별로 여러 개의 지역 할당
for date in date_range:
num_cities = random.randint(1, len(cities)) # 지역 수 만큼 선택
chosen_cities = random.sample(cities, num_cities) # 무작위로 지역 선택
for city in chosen_cities:
event = random.choice(events) # 랜덤으로 이벤트 선택
# 각 지역에서 모든 연령대와 성별 추가
for age in ages:
for gender in genders:
visitors = random.randint(1, 40) # 각 지역에 대해 랜덤으로 방문자 수 생성 (연령별, 성별로 다르게)
# 데이터 추가
raw_data["날짜"].append(date) # 날짜 추가
raw_data["지역"].append(city) # 선택된 지역 추가
raw_data["방문자수"].append(visitors) # 방문자 수 추가
raw_data["연령대"].append(age) # 연령대 추가
raw_data["성별"].append(gender) # 성별 추가
raw_data["이벤트 종류"].append(event) # 동일한 이벤트 추가
data = pd.DataFrame(raw_data) # DataFrame 생성
data.head(15) # 상위 15개 데이터 출력
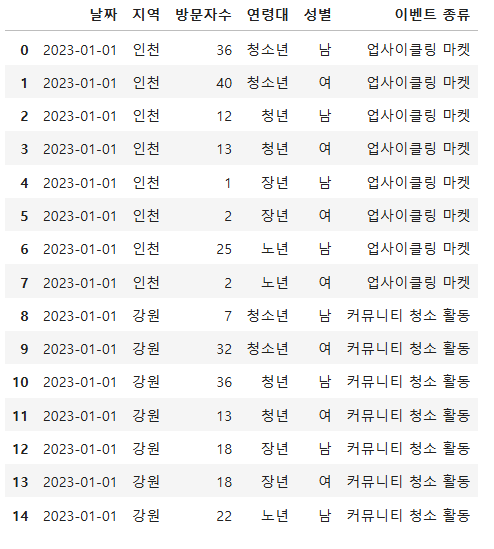
◆ 생성된 데이터의 크기 조회
5만3천여개(!)의 데이터가 생성되었다.
data.info()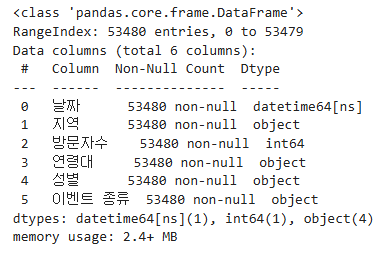
▶ 이 역시도 실습하면서 보완하느라 지금은 다르다.
◆ 이벤트 운영 지표에 추가할 '참여자수', '참여비율' 추가
- 기존의 데이터프레임에 참여자수와 참여비율 칼럼을 추가했다.
- 참여자수는 각 행의 방문자수보다 1보다 작은 수와 20 중에 최솟값을 선택하게 설정했다.
- 참여비율 = 참여자수 / 방문자수 ▶ 100을 곱해 백분율로 볼 수 있도록 하였다.
# 참여자수 추가 (방문자 수에 비해 적게 생성)
data["참여자수"] = [random.randint(0, min(visitors-1, 20)) for visitors in data["방문자수"]]
# 참여비율 계산 (참여자수가 0인 경우 처리)
data["참여비율"] = data.apply(lambda row: row["참여자수"] / row["방문자수"] * 100 if row["참여자수"] > 0 else 0, axis=1)
data.tail()
◆ csv 파일로 저장하여 팀원에게 공유
# CSV 파일로 저장
data.to_csv("recycling_off.csv", index=False, encoding='utf-8-sig') # index=False는 인덱스 열을 저장하지 않도록 설정
이렇게 프로젝트의 첫번째 관문, 분석 데이터 마련 작업이 마무리 되었다.
이제 이를 이용하여 데이터 정제와 전처리를 진행하고, 시각화를 진행하는 작업을 거치면 된다.
데이터 수정 및 보완하기
: 온라인 마케팅
온라인 광고 데이터를 보니, 오프라인에 비해 데이터가 부족하다고 느껴져 보완을 해야겠다고 생각했다. (현재 시간 새벽 6시다 0_0)
필자가 생각하기에 여기서 보완할 수 있는 사항으로는,
- 유입 디바이스: 모바일 / PC
- 유입 경로: 직접 유입, 키워드 검색, 블로그, 이메일, 카카오톡, 페이스북, 인스타그램, 유튜브, 틱톡, 트위터 X, 배너 광고, 기타 SNS
- 체류 시간: 사용자가 웹사이트에서 보낸 평균 시간
- 페이지뷰: 사용자가 조회한 페이지 수
- 이탈수: 웹사이트에 방문 후 다른 페이지로 이동하지 않고 떠난 수
- 이탈률: 웹사이트에 방문 후 다른 페이지로 이동하지 않고 떠난 비율
- 페이지당 평균 뷰: 각 방문자가 몇 개의 페이지를 조회했는지 측정
또한, 전환수 역시 전환의 조건들을 추가하고, 기존의 전환수는 총 전환수로 보완할 수 있다.
- 회원가입 수
- 앱 다운로드 수
- 뉴스레터 구독 수 (모바일의 경우 알람 설정)
그리고 대표 키워드도 변경해주려고 하는 데, 그 이유는 추후 진행할 앱 개발 프로젝트에서 우리 조는 재활용, 플로깅 관련 커뮤니티 앱을 만들기로 하였기 때문이다. 따라서, 변경될 대표 키워드는
- 재활용 앱
- 플로깅
- 쓰레기 줍기
- 환경 보호 앱
- 재활용 가이드
- 플로깅 행사
- 지속 가능한 생활
- 친환경 활동
- 환경 캠페인
- 지역 재활용 센터
이렇게 선정하였고, 해당 데이터는 키워드 검색으로 유입 시에만 나타나도록 해야할 듯 하다.
이제 새롭게 나온 아이디어를 통해 다시 코딩을 시작해 본다.
◆ 키워드 변경, 유입 디바이스 및 유입 경로 변수 설정
# 대표 키워드 10개 설정
keywords = ["재활용 앱", "플로깅", "쓰레기 줍기", "환경 보호 앱", "재활용 가이드",
"플로깅 행사", "지속 가능한 생활", "친환경 활동", "환경 캠페인", "지역 재활용 센터"]
# 유입 디바이스 설정
devices = ["PC", "Mobile"]
# 유입 경로 설정
influx_ways = ["직접 유입", "키워드 검색", "블로그", "카페", "이메일",
"카카오톡", "메타", "인스타그램", "유튜브", "배너 광고",
"트위터 X", "기타 SNS"]
◆ 반복문으로 데이터 생성하는 코드 수정
▶ 앞서 진행했던 온라인 마케팅은 키워드 광고 하나 뿐이었다는 가정 이었으나, 지금은 키워드 광고는 홍보 방법 중의 하나로 변경되었기 때문에 유입 경로가 키워드 광고일 때만 어떤 키워드로 유입이 되었는지 표시되게 하려고 한다.
그리고 노출수의 경우도 키워드 검색, 인스타그램, 유튜브, 배너광고 같은 곳에서만 노출될 경우에만 집계할 수 있는 지표이며, 직접 유입 시에는 노출수가 무의미하므로, 직접 유입 시에는 노출수가 뜨지 않도록 한다.
같은 맥락에서 클릭수 역시 유입수로 변경한다. (그러나 변수명은 clicks 로 유지)
# 날짜 범위 생성
date_range = pd.date_range(start="2023-01-01", end="2024-12-31", freq='D')
# 대표 키워드 10개 설정
keywords = ["재활용 앱", "플로깅", "쓰레기 줍기", "환경 보호 앱", "재활용 가이드",
"플로깅 행사", "지속 가능한 생활", "친환경 활동", "환경 캠페인", "지역 재활용 센터"]
# 유입 디바이스 설정
devices = ["PC", "Mobile"]
# 유입 경로 설정
influx_ways = ["직접 유입", "키워드 검색", "블로그", "카페", "이메일",
"카카오톡", "메타", "인스타그램", "유튜브", "배너 광고",
"트위터 X", "기타 SNS"]
# 결과를 저장할 리스트 초기화
raw_data = {
"날짜": [],
"디바이스": [], # 추가
"유입경로": [], # 추가
"키워드": [],
"노출수": [],
"유입수": [],
"체류시간(min)": [], # 추가
"페이지뷰": [], # 추가
"이탈수": [] # 추가
}
# 날짜별로 데이터 생성
for date in date_range:
for device in devices: # 각 디바이스에 대해 반복
for influx_way in influx_ways: # 각 유입 경로에 대해 반복
if influx_way == "키워드 검색": # 유입 경로가 키워드 검색인 경우
num_keywords = random.randint(1, len(keywords)) # 키워드 수 무작위 선택
chosen_keywords = random.sample(keywords, num_keywords) # 무작위로 키워드 선택
for keyword in chosen_keywords:
exposures = random.randint(1, 1000) # 각 유입 경로에 대해 랜덤으로 노출수 생성
clicks = random.randint(0, min(exposures, 100)) # 클릭수는 노출수 및 100 이하
stay_time = random.randint(0, 500) # 디바이스 및 유입별 총 체류시간 합계
page_view = random.randint(1, 500) # 페이지뷰 총 합
exit = random.randint(0, min(clicks, 10)) # 이탈수는 유입수 이하 또는 10 중 최소값
# 데이터 추가
raw_data["날짜"].append(date) # 날짜 추가
raw_data["디바이스"].append(device) # 디바이스 추가
raw_data["유입경로"].append("키워드 검색") # 유입경로 추가
raw_data["키워드"].append(keyword) # 선택된 키워드 추가
raw_data["노출수"].append(exposures) # 노출수 추가
raw_data["유입수"].append(clicks) # 클릭수 추가
raw_data["체류시간(min)"].append(stay_time) # 체류시간 추가
raw_data["페이지뷰"].append(page_view) # 페이지뷰
raw_data["이탈수"].append(exit) # 이탈수
elif influx_way == "직접 유입": # 유입 경로가 직접 유입인 경우 노출수 표시 X
exposures = random.randint(1, 1000) # 각 유입 경로에 대해 랜덤으로 노출수 생성
clicks = random.randint(0, 100) # 유입수는 100 이하
stay_time = random.randint(0, 500) # 디바이스 및 유입별 총 체류시간 합계
page_view = random.randint(1, 500) # 페이지뷰 총 합
exit = random.randint(0, min(clicks, 10)) # 이탈수는 유입수 이하
# 데이터 추가
raw_data["날짜"].append(date) # 날짜 추가
raw_data["디바이스"].append(device) # 디바이스 추가
raw_data["유입경로"].append("직접 유입") # 유입경로
raw_data["키워드"].append(None) # 키워드 없음
raw_data["노출수"].append(0) # 노출수 없음
raw_data["유입수"].append(clicks) # 클릭수 추가
raw_data["체류시간(min)"].append(stay_time) # 체류시간 추가
raw_data["페이지뷰"].append(page_view) # 페이지뷰
raw_data["이탈수"].append(exit) # 이탈수
else: # 유입 경로가 키워드 검색과 직접 유입이 아닌 경우
exposures = random.randint(1, 1000) # 각 유입 경로에 대해 랜덤으로 노출수 생성
clicks = random.randint(0, min(exposures, 100)) # 클릭수는 노출수 및 100 이하
stay_time = random.randint(0, 500) # 디바이스 및 유입별 총 체류시간 합계
page_view = random.randint(1, 500) # 페이지뷰 총 합
exit = random.randint(0, min(clicks, 10)) # 이탈수는 유입수 이하 또는 10 중 최소값
# 데이터 추가
raw_data["날짜"].append(date) # 날짜 추가
raw_data["디바이스"].append(device) # 디바이스 추가
raw_data["유입경로"].append(influx_way) # 유입경로 추가
raw_data["키워드"].append(None) # 키워드 없음
raw_data["노출수"].append(exposures) # 노출수 추가
raw_data["유입수"].append(clicks) # 클릭수 추가
raw_data["체류시간(min)"].append(stay_time) # 체류시간 추가
raw_data["페이지뷰"].append(page_view) # 페이지뷰
raw_data["이탈수"].append(exit) # 이탈수
data = pd.DataFrame(raw_data) # DataFrame 생성
data.head(20) # 상위 20개 데이터 출력
◆ 다른 지표들을 더 추가하기
노출수, 유입수, 페이지뷰, 그리고 이탈수를 기준으로 유입률, 평균 페이지뷰, 그리고 이탈률 칼럼을 생성한다.
# 유입률, 평균 페이지뷰, 이탈률 열 생성
data["유입률"] = (data["유입수"] / data["노출수"]) * 100 # 컨텐츠 노출 대비 유입률
data["평균페이지뷰"] = data["페이지뷰"] / data["유입수"] # 1유입 당 페이지뷰
data["이탈률"] = (data["이탈수"] / data["유입수"]) * 100 # 유입대비 이탈 비율
data.head()
▶ 직접 유입의 경우, 노출이 0이기 때문에 나누면 숫자가 뜨지 않는다. 따라서 이 부분을 수정해줄 필요가 있다.
수정된 코드
# 유입률, 평균 페이지뷰, 이탈률 열 생성
# 컨텐츠 노출 대비 유입률 : 직접 유입의 경우 노출이 0이므로 에러 뜨지 않게 조건문 사용
data["유입률"] = data.apply(lambda row: (row["유입수"] / row["노출수"]) * 100 if row["노출수"] > 0 else 0, axis=1)
data["평균페이지뷰"] = data["페이지뷰"] / data["유입수"] # 1유입 당 페이지뷰
data["이탈률"] = (data["이탈수"] / data["유입수"]) * 100 # 유입대비 이탈 비율
data.head()

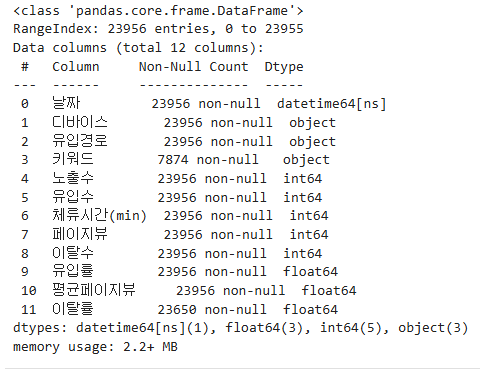
데이터 정보를 확인해 보면, 예전에 3천여 건의 자료에서 2만 3천여 건으로 약 2만여 건이 증가했다.
이렇게 되면 오프라인 쪽 데이티는 사용하지 않아도 될 듯 하다. (파일이 두 개면 나중에 병합하거나 하는 등 번거로운 과정이 생길 것으로 예상되므로)
◆ 전환 조건 추가하여 열 증가시키기
앞서 말한대로, 전환의 조건들을 추가하고 그 조건들의 합을 전환수라는 값에 넣을 생각이다.
또한, 각 전환별로 전환율을 구하고, 모든 전환의 전환율을 구하려고 한다.
앞서 설정한 전환의 조건은 아래 3가지 이다.
- 회원가입 수
- 앱 다운로드 수
- 뉴스레터 구독 수 (모바일의 경우 알람 설정)
# 전환수, 전환율 구하기 - 보완
# 전환수의 경우, 유입수보다 낮게 잡아야 한다.
# 전환율은 유입 나누기 전환
# 1. 회원가입
data["회원가입"] = [random.randint(0, min(clicks, 10)) for _ in range(len(data["날짜"]))]
data["전환율(가입)"] = (data["회원가입"] / data["유입수"]) * 100
# 2. 앱 다운로드
data["앱 다운"] = [random.randint(0, min(clicks, 10)) for _ in range(len(data["날짜"]))]
data["전환율(앱)"] = (data["앱 다운"] / data["유입수"]) * 100
# 3. 뉴스레터 구독 (또는 알람설정)
data["구독"] = [random.randint(0, min(clicks, 10)) for _ in range(len(data["날짜"]))]
data["전환율"] = (data["구독"] / data["유입수"]) * 100
# 총 전환
cols = ["회원가입", "앱 다운", "구독"]
data["전환수"] = [sum(data[col][i] for col in cols) for i in range(len(data))]
data["전환율"] = (data["전환수"] / data["유입수"]) * 100
data.tail()
▶ 프로젝트 진행 중에 각 전환 항목의 전환수가 유입수보다 높은 상황이 있어서 이를 수정해 줘야 한다.
(예, 유입은 5명인데 회원가입이 10건 발생한 경우)
기존의 min(clicks, 10) 이부분을 clicks-exit(이탈수)로 바꿔주면 될 듯하다.
# 1. 회원가입
data["회원가입"] = [random.randint(0, min(clicks-exit, 10)) for _ in range(len(data["날짜"]))]
data["전환율(가입)"] = (data["회원가입"] / data["유입수"]) * 100
# 2. 앱 다운로드
data["앱 다운"] = [random.randint(0, min(clicks-exit, 10)) for _ in range(len(data["날짜"]))]
data["전환율(앱)"] = (data["앱 다운"] / data["유입수"]) * 100
# 3. 뉴스레터 구독 (또는 알람설정)
data["구독"] = [random.randint(0, min(clicks-exit, 10)) for _ in range(len(data["날짜"]))]
data["전환율"] = (data["구독"] / data["유입수"]) * 100
◆ 평균 체류시간 컬럼 추가
마지막으로, 유입 당 평균 체류시간을 구한 칼럼을 추가한다.
# 평균 체류 시간 계산
data["평균체류시간(min)"] = data["체류시간(min)"] / data["유입수"]
data.tail()
◆ 컬럼 정렬
이제 칼럼을 정렬할 필요가 있을 거 같다.
칼럼순은 날짜 | 디바이스 | 유입경로 | 키워드 | 노출수 | 유입수| 유입률(%) | 체류시간(min) | 평균체류시간(min) | 페이지뷰 | 평균페이지뷰 | 이탈수 | 이탈률(%) | 회원가입 | 전환율(가입) | 앱 다운 | 전환율(앱) | 구독 | 전환율(구독) | 전환수 | 전환율
의 순으로 정리하는 게 좋을 거 같다.
# 유입률과 이탈률에 '(%)' 넣기 {기존 이름: 새 이름}
data.rename(columns={"유입률": "유입률(%)", "이탈률": "이탈률(%)"}, inplace=True)
# 칼럼 정렬 순서
column_order = [
"날짜", "디바이스", "유입경로", "키워드", "노출수", "유입수",
"유입률(%)", "체류시간(min)", "평균체류시간(min)", "페이지뷰",
"평균페이지뷰", "이탈수", "이탈률(%)", "회원가입", "전환율(가입)",
"앱 다운", "전환율(앱)", "구독", "전환율(구독)", "전환수", "전환율"
]
# 데이터프레임 칼럼 순서 재정렬
data = data.reindex(columns=column_order)
data.head()
◆ csv 저장 및 깃허브 커밋 후 공유
이제 csv 로 저장하고 깃허브에 다시 업로드해서 조원분들한테 공유하면 끄읏.
# CSV 파일로 저장
data.to_csv("recycling_online.csv", index=False, encoding='utf-8-sig') # index=False는 인덱스 열을 저장하지 않도록 설정
다음 내용
[파이썬] 프로젝트 : 웹 페이지 구축 - 2 (데이터 전처리, 시각화)
이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 1프로젝트 개요 2차 프로젝트를 시작하게 되었다.이번에 해야할 프로젝트는 데이터를 이용한 대시보드 웹 페이지를 구축하는
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 프로젝트 : 웹 페이지 구축 - 3(데이터 시각화) (0) | 2025.03.20 |
|---|---|
| [파이썬] 프로젝트 : 웹 페이지 구축 - 2 (데이터 전처리, 시각화) (0) | 2025.03.20 |
| [파이썬] 자연어 처리 (NLP) - 네이버 뉴스 텍스트 분석(2) (0) | 2024.08.21 |
| [워드클라우드] 코로나 뉴스 기사 (feat.주사기 마스킹) (2) | 2024.08.19 |
| [파이썬] 네이버 뉴스 댓글 추첨 (feat.임영웅) - 2 (0) | 2024.06.29 |



