[목차]
[빅데이터 분석기사] 시험 과목 및 주요 내용 (필기)
빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터 분석 기획 빅데이터의 이해 빅데이터 개요 및 활용 빅데이
puppy-foot-it.tistory.com
빅데이터 분석 기획 - 데이터 수집 및 저장 계획
< 데이터 수집 및 전환>
2. 데이터 유형 및 속성 파악
(1) 데이터 유형
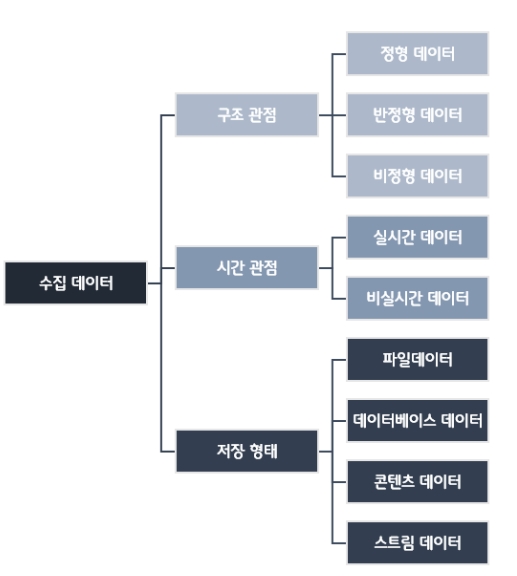
[구조관점]
1) 정형 데이터
- 정형화된 스키마 구조 기반의 형태를 가지고 고정된 필드에 저장되며 값과 형식에서 일관성을 가지는 데이터
- 컬럼과 로우 구조를 가지며, 설계된 구조 기반 목적에 맞는 정보들
- 종류: 관계형 데이터베이스, 스프레드시트
2) 반정형 데이터
- 스키마 구조 형태를 가지고 메타데이터를 포함하며, 값과 형식에서 일관성을 가지지 않는 데이터
- XML, HTML 과 같은 웹 데이터가 Node 형태의 구조를 가짐
- 종류: XML, HTML, 웹 로그, 알람, 시스템 로그, JSON, RSS, 센서데이터
3) 비정형 데이터
- 스키마 구조 형태를 가지지 않고 고정된 필드에 저장되지 않는 데이터
- 텍스트: 문자/문자열 형태로 저장
- 이미지: RGB 형태로 저장
- 오디오: 시간에 따른 진폭 형태로 저장
- 비디오: 이미지 스트리밍으로 저장
[시간 관점}
1) 실시간 데이터
- 생성된 이후 수 초~수 분 이내에 처리되어야 의미가 있는 현재 데이터
- 종류: 센서 데이터, 시스템 로그, 네트워크 장비 로그, 알람, 보안 장비 로그
2) 비실시간 데이터
- 생성된 데이터가 수 시간 또는 수 주 이후에 처리되어야 의미가 있는 과거 데이터
- 종류: 통계, 웹 로그, 구매 정보, 서비스 로그, 디지털 헬스케어 정보
[저장형태 관점]
1) 파일 데이터: 시스템 로그, 서비스 로그, 텍스트, 스프레드시트 등과 같이 파일 형식으로 파일 시스템에 저장되는 데이터이며, 파일 크기가 대용량이거나 파일의 개수가 다수인 데이터
2) 데이터베이스 데이터: 관계형 데이터베이스, NoSQL, 인메모리 데이터베이스 등에 의해서 데이터의 종류나 성격에 따라 데이터베이스의 컬럼 또는 테이블 등에 저장된 데이터
3) 콘텐츠 데이터: 텍스트, 이미지, 오디오, 비디오 등과 같이 개별적으로 데이터 객체로 구분될 수 있는 미디어 데이터
4) 스트림 데이터: 센서 데이터, HTTP 트랜잭션, 알람 등과 같이 네트워크를 통해서 실시간으로 전송되는 데이터
(2) 데이터 변환 기술
| 변환 기술 | 설명 |
| 평활화 (Smoothing) | - 데이터로부터 잡음을 제거하기 위해 데이터 추세에 벗어나는 값들을 변환하는 기법 - 데이터 집합에 존재하는 잡음으로 인해 거칠게 분포된 데이터를 매끄럽게 만들기 위해 구간화, 군집화 등의 기법 적용 |
| 집계 (Aggregation) | - 다양한 차원의 방법으로 데이터를 요약하는 기법 - 여러 개의 표본을 하나의 표본으로 줄이는 방법, 함수를 이용해서 한꺼번에 변수 변환을 적용하여 새로운 변수로 값을 생성하는 방법 활용 |
| 일반화 (Generalization) | - 특정 구간에 분포하는 값으로 스케일을 변화시키는 기법 - 일부 특정 데이터만 잘 설명하는 것이 아니라 범용적인 데이터에 적합한 모델을 만드는 기법 - 잘된 일반화는 이상값이나 노이즈가 들어와도 크게 흔들리지 않아야 함 |
| 정규화 (Normalization) | - 데이터를 특정 구간으로 바꾸는 척도법 - 정규화의 유형에는 최소-최대 정규화, Z-점수 정규화 등 |
| 속성 생성 (Attribute / Feature Construction) | - 데이터 통합을 위해 새로운 속성이나 특징을 만드는 방법 - 주어진 여러 데이터 분포를 대표할 수 있는 새로운 속성/특징을 활용하는 기법 -선택한 속성을 하나 이상의 새 속성으로 대체하여 데이터를 변경 처리 |
3. 데이터 비식별화
(1) 데이터 비식별화
- 특정 개인을 식별할 수 없도록 개인정보의 일부 또는 전부를 변환하는 일련의 방법
- 데이터를 안전하게 활용하기 위해서는 수집된 데이터의 개인정보 일부 또는 전부를 삭제하거나 다른 정보로 대체함으로써 다른 정보와 결합하여도 특정 개인을 식별하기 어렵게 데이터 비식별화 조치를 해야 함.
[적용 대상]
| 적용 대상 | 대상 | 예시 |
| 그 자체로 개인을 식별할 수 있는 정보 | 개인을 식별할 수 있는 정보 | 이름, 전화번호, 주소, 생년월일 등 |
| 고유식별 정보 | 주민등록번호 등 | |
| 생체 정보 | 지문, 홍채 등 | |
| 기관, 단체 등의 이용자 계정 | 계좌번호 등 | |
| 다른 정보와 함께 결합하여 개인을 알아볼 수 있는 정보 | 개인 특성 | 성별, 생년, 생일, 나이, 국적, 고향, 거주지, 우편번호 등 |
| 신체 특성 | 혈액형, 신장, 몸무게, 허리둘레, 혈압 등 | |
| 신용 특성 | 세금 납부액, 신용등급 등 | |
| 경력 특성 | 학교명, 직장명, 학과명, 학년, 직업 등 | |
| 전자적 특성 | 비밀번호, 쿠키 정보, 접속일시 등 | |
| 가족 특성 | 배우자, 자녀, 부모 등 | |
| 위치 특성 | GPS 데이터 , 인테넛 접속, 핸드폰 사용기록 등 |
[처리 기법]
가명처리, 총계처리, 데이터값 삭제, 범주화, 데이터 마스킹
1) 가명처리
- 개인 식별이 가능한 데이터에 대하여 직접 식별할 수 없는 다른 값으로 대체하는 기법
- 그 자체로는 완전 비식별화가 가능하며 데이터의 변형, 변질 수준이 낮음
- 일반화된 대체 값으로 가명처리함으로써 성명을 기준으로 하는 분석에 한계 존재
2) 총계처리
- 개인정보에 대하여 통곗값을 적용하여 특정 개인을 판단할 수 없도록 하는 기법
- 민감한 정보에 대하여 비식별화가 가능하며 다양한 통계분석 (전체, 부분) 용 데이터 세트 작성에 유리
- 집계 처리된 데이터를 기준으로 정밀한 분석이 어려우며 집계 수량이 적을 경우 데이터 결합 과정에서 개인정보 추출 또는 예측 가능
- 총계처리 적용 시 개인정보를 묶어서 관리
3) 데이터값 삭제
- 개인정보 식별이 가능한 특정 데이터값 삭제 처리 기법
- 민감한 개인 식별 정보에 대하여 완전한 삭제처리가 가능하여 예측, 추론 등이 어렵도록 함
- 데이터 삭제로 인한 분석의 다양성, 분석 결과의 유효성, 분석 정보의 신뢰성을 저하시킬 수 있음
4) 범주화
- 단일 식별 정보를 해당 그룹의 대푯값으로 변환(범주화)하거나 구간 값으로 변환(범위화) 하여 고유 정보 추적 및 식별 방지 기법
- 범주나 범위는 통계형 데이터 형식이므로 다양한 분석 및 가공 가능
- 범주, 범위로 표현됨에 따라 정확한 수치에 따른 분석, 특정한 분석 결과 도출이 어려우며, 데이터 범위 구간이 좁혀질 경우 추적, 예측 가능
5) 데이터 마스킹
- 개인 식별 정보에 대하여 전체 또는 부분적으로 대체 값(공백, '*', 노이즈 등)으로 변환 기법
- 완전 비식별화가 가능하며 원시 데이터의 구조에 대한 변형이 적음
- 과도한 마스킹 적용 시 필요한 정보로 활용하기 어려우며, 마스킹의 수준이 낮을 경우 특정한 값의 추적 예측 가능
[재현 데이터]
실제로 측정된 원본 자료를 활용하여 통계적 방법이나 기계학습 방법 등을 이용하여 새롭게 생성한 모의 데이터
1) 특징
- 원본 자료와 최대한 유사한 통계적 성질을 보이는 가상의 데이터를 생성하기 위해서 개인정보의 특성을 분석하여 새로운 데이터 생성
- 원본 자료와 다르지만, 원본 자료와 동일 분포를 따르도록 통게적으로 생성한 자료
- 모집단의 통계적 특성들을 유지하면서도 민감한 정보를 외부에 직접 공개하지 않음
2) 유형
| 유형 | 설명 |
| 완전 재현 데이터 (Fully Synthetic Data) | - 원본 자료의 속성 (Label; Feature) 정보 모두를 재현 데이터로 생성한 데이터 - 정보보호 측면에서 가장 강력한 보안성 가짐 |
| 부분 재현 데이터 (Partially Synthetic Data) | - 모든 속성자료를 재현 데이터로 만들기가 현실적으로 어렵기 때문에, 민감하지 않은 정보는 그대로 두고, 민감한 정보에 대해서만 재현 데이터로 대체한 데이터 |
| 복합 재현 데이터 (Hybrid Synthetic Data) | - 일부 변수들의 값을 재현 데이터로 생성하고 생성된 재현 데이터와 실제 변수를 모두 이용하여 또 다른 일부 변수들의 값을 다시 도출하는 방법으로 생성한 데이터 |
(2) 개인정보 익명 처리 기법
- 가명처리: 개인 식별이 가능한 데이터에 대하여 직접 식별할 수 없는 다른 값으로 대체
- 일반화: 더 일반화된 값으로 대체하는 것
- 섭동: 원래 데이터를 동일한 확률적 정보를 가지는 변형된 값으로 대체
- 치환: 특정 컬럼의 데이터를 무작위로 순서를 변경
(3) 개인정보 비식별 조치 가이드라인
사전 검토 → 비식별 조치 → 적정성 평가 → 사후관리
| 사전검토: 개인정보 해당 여부를 검토하고, 개인정보에 해당하지 않는 경우에는 별도 조치 없이 활용 |
| 비식별 조치 기준 | 설명 |
| 식별자 조치 기준 | 정보 집합물에 표함된 식별자는 원칙적으로 삭제 조치 |
| 속성자 조치 기준 | 데이터 이용 목적과 관련이 없는 속성자의 경우 원칙적으로 삭제 |
| 비식별 조치 방법 | 여러 비식별 조치 방법을 이용하여 단독 또는 복합적 활용 |
| 적정성 평가 기준 | 설명 |
| 기초 자료 작성 | 적정성 평가가 필요한 기초자료를 작성 |
| 평가단 구성 | 개인정보보호 책임자가 3명 이상의 관련 분야 전문가로 구성 |
| 평가 수행 | 여러 프라이버시 보호 모델 활용하여 비식별 수준 적정성 평가 |
| 추가 비식별 조치 | 평가결과가 '부적정'인 경우, 추가 비식별 조치 실시 |
| 데이터 활용 | 평가결과가 '적정'인 경우, 해당 데이터를 빅데이터 분석에 이용하거나 제3자에게 제공 |
| 사후 관리 기준 | 설명 |
| 비식별 정보 안전 조치 | 비식별 조치된 정보가 유출되는 경우 다른 정보와 결합하여 식별될 우려가 존재하므로 필수적 보호조치 이행 |
| 재식별 가능성 모니터링 | 비식별 정보를 이용하여 제3자에게 제공하는 경우, 정보의 재식별 가능성을 정기적으로 모니터링 수행 |
이전글
다음글
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터 분석기사] 1과목 빅데이터 분석 기획 (3-2) (0) | 2024.03.12 |
|---|---|
| [빅데이터 분석기사] 1과목 빅데이터 분석 기획 (3-1-3) (0) | 2024.03.12 |
| [빅데이터 분석기사] 1과목 빅데이터 분석 기획 (3-1-1) (1) | 2024.03.11 |
| [빅데이터 분석기사] 1과목 빅데이터 분석 기획 (2-2) (1) | 2024.03.11 |
| [빅데이터 분석기사] 1과목 빅데이터 분석 기획 (2-1) (0) | 2024.03.11 |
