시작에 앞서
해당 내용은 <파이썬으로 데이터 주무르기> -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.
보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.
데이터 획득하기
하단 링크에 접속하여 서울시 5대범죄 발생 검거 현황 csv 파일 다운로드
경찰청 서울특별시경찰청_경찰서별 5대범죄 발생 검거 현황_20221231
2022년 서울경찰청 관할 경찰서별 살인, 강도, 강간 및 추행, 절도, 폭력 발생 검거 현황 (2022년 관서별 5대범죄 발생 검거 현황)
www.data.go.kr

※ 단, 책이 작성된 시점이 현재(2024년)로부터 지났으므로, 저자가 git hub에 올려둔 자료를 활용하여 분석
모듈 불러오기 (numpy, pandas)
데이터 불러오기
먼저 다운로드 받은 csv 파일을 pandas로 불러온다
crime_anal_police = pd.read_csv('../data/02. crime_in_Seoul.csv', thousands=',',
encoding='euc-kr')
crime_anal_police.head()
※ 해당 데이터 중 구 이름과 다른 경찰서 등이 있어 확인 및 변경이 필요
관서별로 되어 있는 경찰서 목록을 확인 하기
경찰청 홈페이지에 접속하면 서울시 관서별 경찰서 목록을 알 수 있다
전국경찰관서안내 : HOME > 기관소개 > 조직안내 > 전국경찰관서안내
HOME > 기관소개 > 조직안내 > 전국경찰관서안내 PDF 파일 [별표 2] 경찰서의 명칭ㆍ위치 및 관할구역(제30조제2항 관련)(경찰청과 그 소속기관 직제 시행규칙).pdf [363381 byte] 바로보기 PDF 다운로드 HOM
www.police.go.kr
Google Maps 를 통해 지도 정보 얻기
Google Maps API 홈페이지에 접속
Google Maps Platform | Google for Developers
Google Maps Platform 설명
developers.google.com
Google Maps API를 받기 위해서는 계정이 있어야 하는데,
해당 절차는 아래 링크를 통해 확인
웹 페이지에 구글 지도 띄우기 (구글 Maps API)
Engineering Blog by Dale Seo
www.daleseo.com
Anaconda prompt를 켜고 googlemaps 모듈을 설치하고,
다시 jupyter notebook에서 googlemaps 모듈을 import 해온다
import googlemaps
gmaps = googlemaps.Client(key="구글로부터 부여 받은 API 키")
※ 구글 API Key 발급 받기 (하단 링크 참고)
구글 지오코딩 API 키 발급 받는 방법 (Geocoding API) - 코스모스팜 블로그
구글 지도 위에 정확한 위치에 마커를 찍어 표시하기 위해서는 GPS 좌표가 필요합니다. Geocoding API 사용 설정과 API 키 발급 과정에 대해서 설명하겠습니다. 과정은 조금 복잡할 수도 있기지만 쉽
blog.cosmosfarm.com
[Python/실습] 구글 맵 지리정보 활용하기1.
1. 설명 구글에서 제공하는 지리정보 서비스임. 지도 이미지 뿐만 아니라 주소별 좌표, 주소, 건물이름 등...
blog.naver.com
구글 맵 API - Geocoding API 설정하는 방법
구글 맵 API - Geocoding API 설정하는 방법 웹사이트 개발 또는 앱 개발을 할때 위치 기반 서비스를 받기 위해 구글 맵 API를 설정해야 할 때가 있습니다. 그 방법을 알아보도록 하겠습니다. 1. 아나콘
python-programming-diary.tistory.com
서울중부경찰서 위치정보 불러오기
import한 google maps 모듈을 활용하여 서울중부경찰서 위치를 조회한다.
gmaps.geocode('서울중부경찰서', language='ko')
lng와 lat 명령: 위도와 경도 정보 확인
관서명에 '+경찰서' 붙여주기
데이터 상의 경찰서 이름과 구글맵의 경찰서 이름이 일치하지 않는 경우가 있기 때문에, 서울**경찰서로 만들어줌
station_name = []
for name in crime_anal_police['관서명']:
station_name.append('서울' + str(name[:-1]) + '경찰서')
station_name
경찰서 주소 받아오기
station_addreess = []
station_lat = []
station_lng = []
for name in station_name:
tmp = gmaps.geocode(name, language='ko')
station_addreess.append(tmp[0].get("formatted_address"))
tmp_loc = tmp[0].get("geometry")
station_lat.append(tmp_loc['location']['lat'])
station_lng.append(tmp_loc['location']['lng'])
print(name + '-->' + tmp[0].get("formatted_address"))

위도와 경도 확인하기
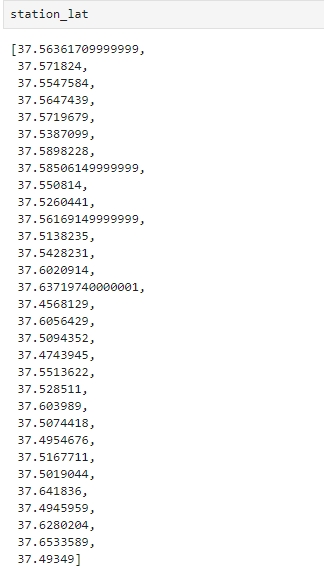
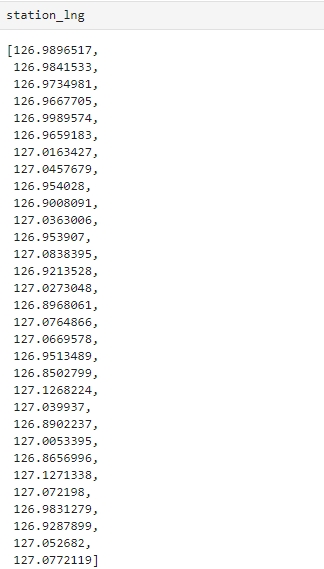
주소 정보를 이용하여 '구별' 컬럼 생성
gu_name = []
for name in station_addreess:
tmp = name.split()
tmp_gu = [gu for gu in tmp if gu.endswith('구')]
gu_name.append(tmp_gu)
crime_anal_police['구별'] = gu_name
crime_anal_police.head()
※ 금천경찰서는 관악구에 위치해 있으므로, 금천서는 예외처리 필요 ('구별' 컬럼에서 '관악구' > '금천구'로 변경)
crime_anal_police.loc[crime_anal_police['관서명']=='금천서', ['구별']] = '금천구'
crime_anal_police[crime_anal_police['관서명']=='금천서']
◆ 파일 저장 하기 (to_csv)
crime_anal_police.to_csv('../data/02. crime_in_Seoul_include_gu_name.csv',
sep=',', encoding='utf-8')

pandas 의 pivot_table 을 이용하여 원 데이터를 관서별에서 구별로 바꿔주기
crime_anal_raw = pd.read_csv('../data/02. crime_in_Seoul_include_gu_name.csv',
encoding='utf-8', index_col=0)
crime_anal = pd.pivot_table(crime_anal_raw, index='구별', aggfunc=np.sum)
crime_anal.head()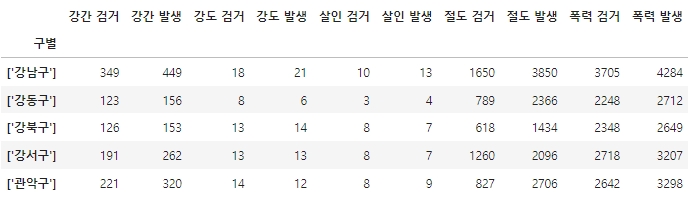
각 범죄별 검거율 계산하기 (+각 검거 건수 삭제하기)
# 각 범죄별 검거율 계산
crime_anal['강간검거율'] = crime_anal['강간 검거'] / crime_anal['강간 발생'] * 100
crime_anal['강도검거율'] = crime_anal['강도 검거'] / crime_anal['강도 발생'] * 100
crime_anal['살인검거율'] = crime_anal['살인 검거'] / crime_anal['살인 발생'] * 100
crime_anal['절도검거율'] = crime_anal['절도 검거'] / crime_anal['절도 발생'] * 100
crime_anal['폭력검거율'] = crime_anal['폭력 검거'] / crime_anal['폭력 발생'] * 100
del crime_anal['강간 검거']
del crime_anal['강도 검거']
del crime_anal['살인 검거']
del crime_anal['절도 검거']
del crime_anal['폭력 검거']
crime_anal.head()
※ 검거율이 100 넘는 경우에는, 그냥 다 100으로 처리
con_list = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
for column in con_list:
crime_anal.loc[crime_anal[column] > 100, column] = 100
crime_anal.head()

각 범죄 컬럼의 '발생' 단어 삭제 (rename 명령)
crime_anal.rename(columns = {'강간 발생':'강간',
'강도 발생':'강도',
'살인 발생':'살인',
'절도 발생':'절도',
'폭력 발생':'폭력'}, inplace=True)
crime_anal.head()

데이터 표현을 위한 정규화
살인 사건은 두 자릿수, 절도와 폭력은 네 자릿수이므로 각각을 비슷한 범위에 놓고 비교하는 것이 분석에는 편리.
각 항목의 최대를 1로 두면 추후 범죄 발생 건수를 종합적으로 비교할 때 편리하기 때문에,
각 컬럼별로 정규화(Normalization)
from sklearn import preprocessing
col = ['강간', '강도', '살인', '절도', '폭력']
x = crime_anal[col].values
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x.astype(float))
crime_anal_norm = pd.DataFrame(x_scaled, columns = col, index = crime_anal.index)
col2 = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm[col2] = crime_anal[col2]
crime_anal_norm.head()※ 머신러닝에 관한 모듈로 유명한 scikit learn 에 있는 전처리 (preprocessing) 도구에는 최소값, 최대값을 이용하여 정규화 시키는 함수 있음

※ 구별 데이터에 ['구'] 로 되어있어, 일일이 수정을 했는데, 혹시 데이터를 일괄적으로 수정하시는 방법 아시는 분 댓글 부탁 드립니다!
기존 작업 CCTV.csv 불러와서 구별 인구수와 CCTV 개수 합치기
result_CCTV = pd.read_csv('../data/01. CCTV_result.csv', encoding='utf-8', index_col='구별')
crime_anal_norm[['인구수', 'CCTV']] = result_CCTV[['인구수', '소계']]
crime_anal_norm.head()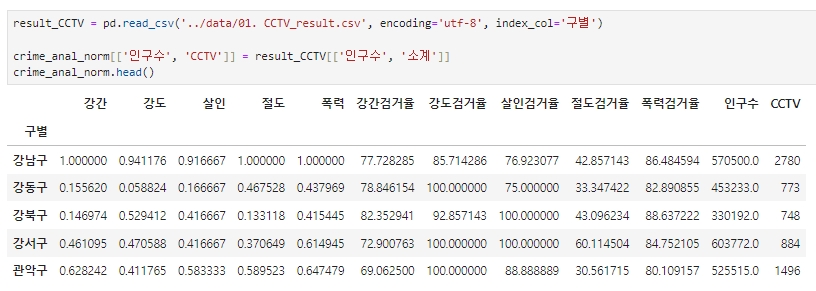
각 범죄 발생건수를 합하고, 이를 '검거'라는 컬럼 생성 (검거율도 통합)
col = ['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율']
crime_anal_norm['검거'] = np.sum(crime_anal_norm[col], axis=1)
crime_anal_norm
이렇게 구별 각 범죄 건수, 그 검거율 및 인구수, CCTV 데이터를 통합하였다.
다음 시간에는 이를 시각화 하려고 한다.
다음글
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 시카고 맛집 분석-1 (1) | 2024.04.16 |
|---|---|
| [파이썬] 서울시 범죄 현황 분석 - 2 (0) | 2024.04.15 |
| [파이썬] 서울시 구별 CCTV 현황 분석-4 (1) | 2024.04.14 |
| [파이썬] 서울시 구별 CCTV 현황 분석-3 (0) | 2024.04.13 |
| [파이썬] 서울시 구별 CCTV 현황 분석-2 (0) | 2024.04.13 |



