시작에 앞서
해당 내용은 <파이썬으로 데이터 주무르기> -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.
보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.
시카고 매거진 홈페이지에 접속해서 가게 정보 얻기
해당 기사가 2012년에 작성됐으므로, 구글에서 "시카고 샌드위치 50개" 를 검색하면 해당 사이트가 나온다.
The 50 Best Sandwiches in Chicago
Our list of Chicago’s 50 best sandwiches, ranked in order of deliciousness
www.chicagomag.com
개발자도구를 이용하여 BLT 클릭

실제로 사용해야 할 태그는 div 태그에 class sammy 또는 sammyListing

from bs4 import BeautifulSoup
from urllib.request import urlopen
url_base = "
http://www.chicagomag.com
"
url_sub = '/chicago-magazine/november-2012/best-sandwiches-chicago/'
url = url_base + url_sub
# headers={'User-Agent': "Mozilla/5.0"} -> 크롤링 방지로 인한 봇이 아니에요
url = Request(url_base + url_sub, headers={'User-Agent': "Mozilla/5.0"})
html = urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
soup
※ 교재에서 나온대로 하면 'HTTPError: HTTP Error 403: Forbidden' 오류가 뜨므로,
반드시 'url = Request(url_base + url_sub, headers={'User-Agent': "Mozilla/5.0"})'
부분을 꼭 넣어야 한다.
HTTPError: HTTP Error 403: Forbidden
해당 오류는 웹 사이트가 접근을 거부하고 있는 HTTP 403 Forbidden 오류입니다. 이는 웹 사이트에서 웹 스크래핑을 막거나 요청한 페이지에 대한 액세스 권한이 없는 경우 발생할 수 있습니다.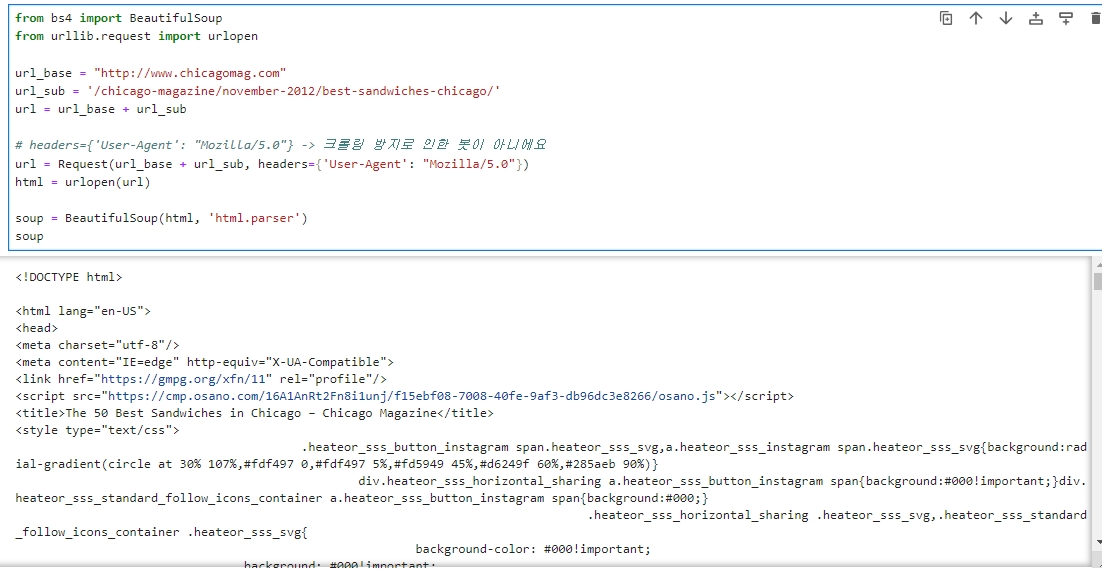
find_all 명령을 이용해서 div 의 sammy 태그 찾기
print(soup.find_all('div', 'sammy'))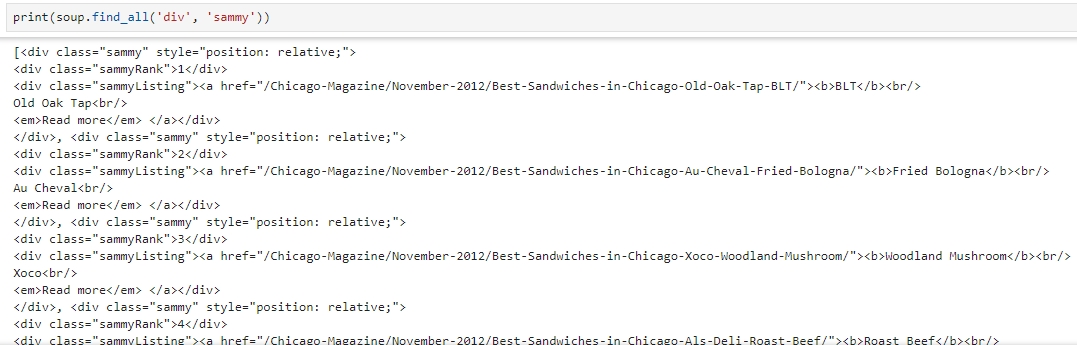
찾는 태그가 맞는지 확인하기 위해 len 명령으로 글자수 조회하기
len(soup.find_all('div','sammy'))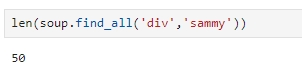
첫번째 것을 확인해보니 원하는 정보가 다 있는 것으로 보인다

div의 sammy 태그를 통해 원하는 정보 얻기
find_all로 찾은 결과는 bs4.elemet.Tag 라고 하는 형태
다시 태그로 sammyRank 찾고, get_text 로 랭킹 얻기
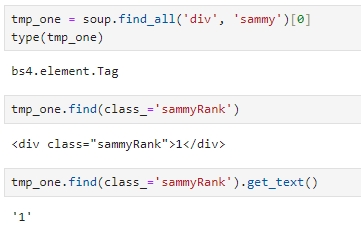
sammyListing 으로 가게 이름 얻고,
a 태그에서 href 정보를 조회하여 url 얻기
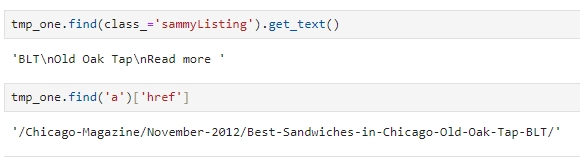
정규식으로 메뉴 이름과 가게 이름 분리하기
import re
tmp_string = tmp_one.find(class_='sammyListing').get_text()
re.split(('\n|\r\n'), tmp_string)
print(re.split(('\n|\r\n'), tmp_string)[0])
print(re.split(('\n|\r\n'), tmp_string)[1])
나머지 데이터의 경로를 얻기 위한 urljoin 명령
url을 얻는 코드가 다른 49개에 적용했을 때 항상 동일하지 않기 때문에, urllib 에 있는 urljoin 명령을 사용해야 함.
urljoin 명령을 사용하면 절대경로로 잡힌 url 은 그대로 두고 상대경로로 잡힌 url 은 절대경로로 변경
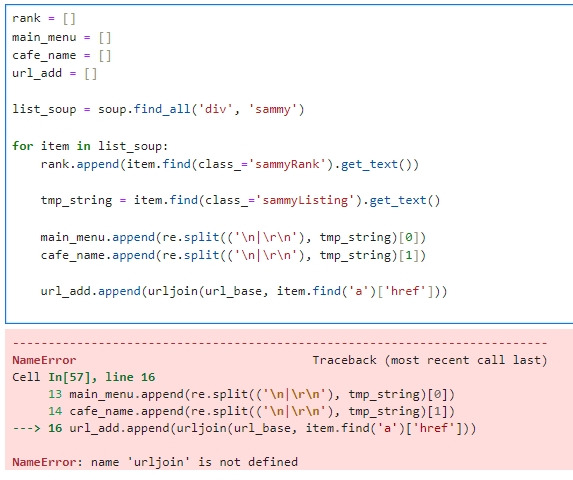
※ NameError: name 'urljoin' is not defined 이라는 오류가 뜨는 것은 urljoin 이라는 모듈이 설치되지 않았기 때문이므로, 해당 함수를 사용하려면 urllib.parse 모듈을 임포트해야 한다.
from urllib.parse import urljoin # urllib.parse 모듈에서 urljoin 함수를 임포트합니다.
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all('div', 'sammy')
for item in list_soup:
rank.append(item.find(class_='sammyRank').get_text())
tmp_string = item.find(class_='sammyListing').get_text()
main_menu.append(re.split(('\n|\r\n'), tmp_string)[0])
cafe_name.append(re.split(('\n|\r\n'), tmp_string)[1])
# urljoin 함수를 사용하여 절대 URL을 생성하고 url_add 리스트에 추가합니다.
url_add.append(urljoin(url_base, item.find('a')['href']))
# 수정된 코드로 정상적으로 동작할 것입니다.
순위, 순위에 따른 메뉴, 순위에 따른 카페를 잘 받아왔는지 확인
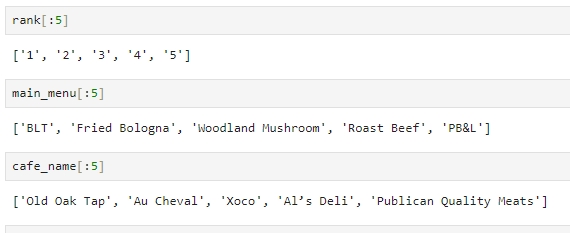
url 도 잘 받아왔는지 확인

네 개의 변수(순위, 메뉴, 카페명, url) 조회하기

pandas를 이용하여 data로 만들어보기
import pandas as pd
data = {'Rank':rank, 'Menu':main_menu, 'Cafe':cafe_name, 'URL':url_add}
df = pd.DataFrame(data)
df.head()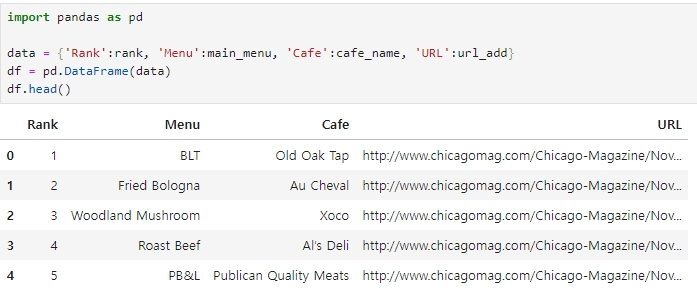
컬럼 순서 정리하기
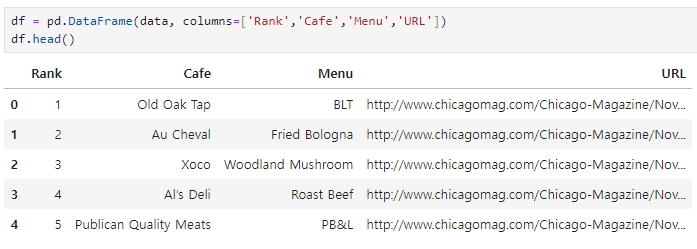
df = pd.DataFrame(data, columns=['Rank','Cafe','Menu','URL'])
df.head()
CSV 파일로 저장하기
df.to_csv('../data/03. best_sandwiches_list_chicago.csv', sep=',',encoding='utf-8')다음글
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 시카고 맛집 분석-3 (2) | 2024.04.18 |
|---|---|
| [파이썬] 시카고 맛집 분석-2 (1) | 2024.04.17 |
| [파이썬] 서울시 범죄 현황 분석 - 2 (0) | 2024.04.15 |
| [파이썬] 서울시 범죄 현황 분석 - 1 (0) | 2024.04.14 |
| [파이썬] 서울시 구별 CCTV 현황 분석-4 (1) | 2024.04.14 |



