시작에 앞서
해당 내용은 <파이썬으로 데이터 주무르기> -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.
보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.
이전 분석 보기
[파이썬] 시카고 맛집 분석-1
시작에 앞서 해당 내용은 -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다. 보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다. 시카고 매거진 홈페이지에 접속해서 가게 정
puppy-foot-it.tistory.com
※ 시작에 앞서, 작업을 중단하신 분이 있다면 먼저 모듈을 import 해야 한다
from bs4 import BeautifulSoup
from urllib.request import urlopen
import pandas as pd
그리고나서, 지난 시간에 데이터를 만들어서 CSV 포맷으로 저장한 파일을 불러온다
df = pd.read_csv('../data/03. best_sandwiches_list_chicago.csv', index_col=0,)
df.head()
url 컬럼에 있는 내용을 읽어 각 페이지에서 정보 얻기
URL 컬럼에 있는 내용을 50개 읽어서 각 페이지에서 가게 주소, 대표 샌드위치 가격, 가게 전화번호를 얻는다
시험삼아 첫 번째 URL 정보 읽어보기
df['URL'][0]
시카고 매거진의 또 다른 페이지인데, 이 주소를 Beautiful Soup로 읽음
html = urlopen(df['URL'][0])
soup_tmp = BeautifulSoup(html, "html.parser")
soup_tmp※ 단, 상단 처럼 코드를 작성하면 또 'HTTPError: HTTP Error 403: Forbidden' 오류가 뜨므로, 아래 코드로 넣어야 한다.
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
# User-Agent 설정을 포함한 요청 보내기
req = Request(df['URL'][0], headers={'User-Agent': 'Mozilla/5.0'})
html = urlopen(req)
# BeautifulSoup을 사용하여 HTML 파싱
soup_tmp = BeautifulSoup(html, "html.parser")
soup_tmp
HTTPError: HTTP Error 403: Forbidden
해당 오류는 웹 사이트가 접근을 거부하고 있는 HTTP 403 Forbidden 오류입니다. 이는 웹 사이트에서 웹 스크래핑을 막거나 요청한 페이지에 대한 액세스 권한이 없는 경우 발생할 수 있습니다.
샌드위치 가게의 주소, 전화번호, 홈페이지 url 얻어오기
첫번째 뜨는 사이트에 접속한 후 개발자도구를 켠다
1. Old Oak Tap BLT
www.chicagomag.com
ctrl + shift + c 를 누르고 해당 영역을 클릭하면

p 태그에 addy class 인 것을 알 수 있다

이 태그를 find 명령을 통해 찾은 다음에
print(soup_tmp.find('p', 'addy'))

텍스트로 가지고 와서 빈 칸으로 나눈다
# 텍스트로 가져오기
price_tmp = soup_tmp.find('p', 'addy').get_text()
price_tmp
# 빈칸으로 나누기
price_tmp.split()
가격 불러오기 (맨 뒤에 '.' 이 붙으므로, 제거하기)

join 명령으로 나눠진 텍스트를 하나의 문장으로 만들기
텍스트로 불러온 내용을 기준으로 두 번째부터 맨 마지막에서 세 번째까지를 선택하여 하나의 문장으로 만들기
' '.join(price_tmp.split()[1:-2])
가격과 주소를 불러오는 코드(하단) 를 작성하면 또 ' HTTPError: HTTP Error 403: Forbidden' 에러가 뜬다.
(시카고 매거진에서 한국인들이 하도 웹 스크래핑해서 단단히 화가 난듯)
price = []
address = []
for n in tqdm_notebook(df.index):
url = Request(df['URL'][n], headers={'User-Agent':'Mozilla/5.0'})
html = urlopen(url)
soup_tmp = BeautifulSoup(html, "lxml")
gettings = soup_tmp.find('p','addy').get_text()
price.append(gettings.split()[0][:-1])
address.append(' '.join(gettings.split()[1:-2]))
이 코드의 에러를 해결하기 위해 진짜 진짜 진짜 고생을 했고, 결국 해결을 했다. (구글링과 챗gpt의 도움으로)
그 전에, 상태를 알려주는 tqdm 모듈을 설치하고
pip install tqdm
해결 방법
1) pip install fake-useragent 모듈 설치
2) 하단의 코드를 입력
import re
from tqdm import tqdm
from urllib.error import HTTPError
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
price = []
address = []
for idx, row in tqdm(df.iterrows()): # tqdm : 진행률 보여줌
ua = UserAgent()
try:
url = row["URL"]
req = Request(url, headers={"user-agent": ua.ie}) # fake user-agent
response = urlopen(req)
except HTTPError as e:
price.append(None)
address.append(None)
print(e) # HTTP Error 403: Forbidden
continue
soup = BeautifulSoup(response, "html.parser")
try:
detail = soup.find("em").text
detail_parts = detail.split(",") # 쉼표로 분리하여 리스트로 변환
if re.search("\$\d+(\.\d+)?", detail_parts[0]):
price.append(re.search("\$\d+(\.\d+)?", detail_parts[0]).group())
address.append(detail_parts[0].split()[1:]) # 주소 추출
else:
price.append(None)
address.append(None)
except AttributeError:
price.append(None)
address.append(None)
tqdm 모듈 설치로 인해 진행상황이 주르륵 뜬다. (49번 진행때까지 또 오류난 줄 알고 절망할 뻔 했다..)
다행히도 가격과 주소를 잘 스크래핑 해왔다! (뿌듯)


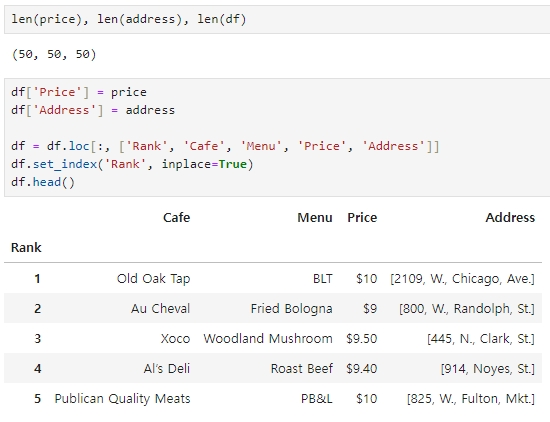
다시 한 번 가격, 주소와 기존에 작업하던 df와 크기가 같은지 확인하고,
df에 가격과 주소 추가 (Rank를 인덱스로 잡음)
df['Price'] = price
df['Address'] = address
df = df.loc[:, ['Rank', 'Cafe', 'Menu', 'Price', 'Address']]
df.set_index('Rank', inplace=True) #Rank를 index로 잡음
df.head()
소중하게(!) 작업한 결과물을 csv 파일로 저장한다
df.to_csv('../data/03. best_sandwiches_list_chicago2.csv', sep=',', encoding='utf-8')다음글
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 주유소 가격 비교하기 - 1 (0) | 2024.04.20 |
|---|---|
| [파이썬] 시카고 맛집 분석-3 (2) | 2024.04.18 |
| [파이썬] 시카고 맛집 분석-1 (1) | 2024.04.16 |
| [파이썬] 서울시 범죄 현황 분석 - 2 (0) | 2024.04.15 |
| [파이썬] 서울시 범죄 현황 분석 - 1 (0) | 2024.04.14 |



