해당 내용은 유튜버 '디플와플'님의 ADsP 최신 기출 문제 풀이(40회) 유튜브 영상을 토대로 작성하였습니다.
(하단에 원본 영상 링크 있음) ※ 단, 풀이 해설은 필자가 직접 작성
5번. 데이터의 특징 (비트 / 바이트)
- 비트(bit) - 컴퓨터에서 사용하는 가장 작은 데이터 단위, 하나의 비트는 2진수 1 또는 0으로 표현되어
데이터를 처리, 저장, 전송 할 때 사용된다.
- 바이트(Byte) - 데이터 파일의 크기, 디스크 또는 그 외 저장 매체의 공간, 그리고 네트워크를 통하여
전송 되는 데이터의 양을 표현하는데 사용 되는 측정 단위, 1바이트는 8비트 (1Byte = 8bit) 와 같다.
7번. 빅데이터 활용 기법 (군집 - 예측)
▶ 군집분석은 비지도 학습 방법으로, 군집의 수 (속성-Label)가 사전에 알려져 있지 않을 때 사용하는 분석 방법.
따라서, 각 개체가 어떤 군집에 들어갈까 예측하기 보다는 분류하는 것에 목적을 두었다. (유사도 정의)
군집분석 알고리즘의 예시로는 k-means 알고리즘, h-cluster 알고리즘 등이 있다.
9번. 가트너 데이터 사이언티스트 역량 (조직관리)
▶ 데이터 사이언티스트가 갖춰야 할 역량
요구 역량 1. Hard Skill(빅데이터에 대한 이론적 지식, 기술)
* 빅데이터에 대한 이론적 지식 : 관련 기법에 대한 이해와 방법론 습득
* 분석 기술에 대한 숙련 : 최적의 분석 설계 및 노하우 축적
요구 역량 2. Soft Skill(통찰력 있는 분석, 설득력, 커뮤니케이션)
* 통찰력 있는 분석 : 창의적 사고, 호기심, 논리적 비판
* 설득력 있는 전달 : 스토리텔링, 비주얼라이제이션(시각화)
* 다분야간 협력 : 커뮤니케이션(대화 능력)
※ 호기심 : 문제의 이면을 파고들고, 질문을 찾고, 검증 가능한 가설을 세우는 능력을 의미
가트너가 제시한 데이터 사이언티스트가 갖춰야할 역량 (데이터 관리, 분석모델링, 비즈니스 분석, 소프트 스킬)
* 데이터관리[Data Management] : 데이터에 대한 이해
* 분석모델링[Analytics Modeling] : 분석론에 대한 지식
* 비즈니스 분석[Business Analysis] : 비즈니스 요소에 초점
* 소프트 스킬[Soft Skill] : 커뮤니케이션, 협력, 리더십, 창의력, 규율 등
12번. 데이터 분석 조직 구조 (출처: 블로그 '데이터를 위한 공간' )
- 분석조직 및 인력구성 시 고려사항
| 구분 | 주요 고려사항 |
| 조직구조 | 1. 비즈니스 질문을 선제적으로 찾아낼 수 있는 구조인가? 2. 분석 전담조직과 타 부서간 유기적인 협조와 지원이 원활한 구조인가? 3. 효율적인 분석업무를 수행하기 위한 분석조직의 내부 조직구조는? 4. 전사 및 단위부서가 필요시 접촉하여 지원할 수 있는 구조인가? 5. 어떤 형태의 조직(중앙집중형, 분산형) 으로 구성하는 것이 효율적인가? |
| 인력구성 | 1. 비즈니스 및 IT 전문가의 조합으로 구성되어야 하는가? 2. 어떤 경험과 어떤 스킬을 갖춘 사람으로 구성해야 하는가? 3. 통계적 기법 및 분석 모델링 전문인력을 별도로 구성해야 하는가? 4. 전사 비즈니스를 커버하는 입력이 없다면? |
- 조직구조의 3가지 유형
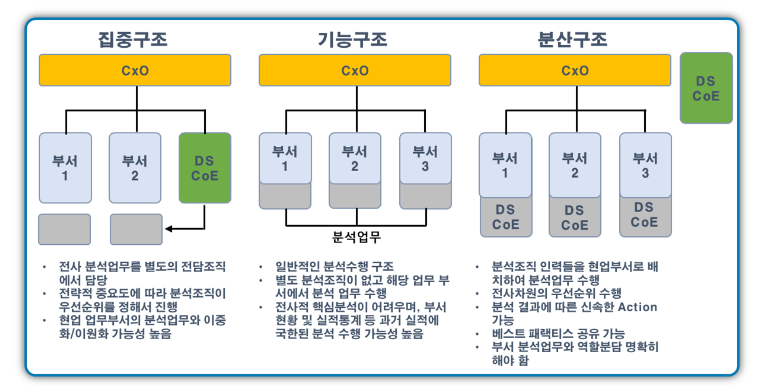
◆ 집중형 조직구조
- 조직 내에 별도의 독립적인 분석 전담조직을 구성하고, 회사의 모든 분석업무를 전담조직에서 담당
- 분석 전담조직 내부에서 전사 분석과제의 전략적 중요도에 따라 우선순위를 정하여 추진
- 일부 협업부서와 분석업무 중복 또는 이원화될 가능성 있음
◆ 기능중심형 조직구조
- 일반적으로 분석을 수행하는 형태이며, 별도의 분석조직을 구성하지 않고 각 해당 업무 부서에서 직접 분석하는 형태
- 전사관점에서 핵심분석이 어려우며, 특정 업무부서에 국한된 분석을 수행할 가능성이 높거나 일부 중복된 분석업무를 수행할 수 있는 조직구조
◆ 집중형 조직구조
- 분석 조직의 인력들을 협업부서에 배치해 분석업무를 수행하는 형태
- 전사차원에서 분석과제의 우선순위를 선정해 수행 가능하며, 분석결과를 신속하게 실무에 적용할 수 있는 장점
13번. 프로젝트 범위 정의서 (SOW) - 출처: 블로그 '슈르의 오피스라이프'
작업 지시서(SOW; Statement of Work)
▶ 고객의 요구 사항 및 프로젝트의 결과 등을 상세히 기술해 놓은 명세서.
상호 기대 사항을 공유하고 의사소통을 증진시키기 위한 것으로서, 프로젝트 계획서의 일부 혹은 전부가 포함될 수 있다.
SOW는 수행사가 작성하며,
과업에 대해 이해한 내용, 수행 범위, 수행 방법 등에 차례대로 기술한다.
SOW는 워드 같은 프로그램으로 작성하며, 양식은 고객사에서 제공하거나 자체 서식으로 쓴다.
[빅데이터 분석 방법론 (5단계)] - 출처: 블로그 'wandajeong.log'
◆ 분석 기획 → 데이터 준비 → 데이터 분석 → 시스템 구현 → 평가 및 전개
1단계: 분석 기획
- 비즈니스 이해 및 범위 설정
- SOW(State of Work): 프로젝트에 참여하는 관계자들이 이해를 일치시키기 위해 작성하는 것
- 프로젝트 정의 및 계획 수립
- 프로젝트 위험 계획 수립 : 데이터 분석 위험 식별, 위험 대응 계획 수립
- 회피, 전이, 완화, 수용
2단계: 데이터 준비
- 필요 데이터 정의
- 데이터 스토어 설계
- 데이터 수집 및 정합성 점검
3단계: 데이터 분석
- 분석용 데이터 준비
- 텍스트 분석, 탐색적 분석
- 모델링 : 데이터 분할, 데이터 모델링, 모델 적용 및 운영 방안
- - 알고리즘 설명서 작성 : 필요시 의사 코드 수준의 상세한 작성 필요
- - 모델의 안정적 운영을 위한 모니터링 방안 수립
- 모델 평가 및 검증
4단계: 시스템 구현
- 설계 및 구현
- 시스템 테스트 및 운영 : 단위 테스트, 통합 테스트, 시스템 테스트(품질 관리 차원)
5단계: 평가 및 전개
- 모델 발전 계획 수립
- 프로젝트 평가 및 보고 : 모든 산출물 및 프로세스를 지식 자산화
14번. CRISP-DM 각 단계에서 수행하는 업무
CRISP-DM (Cross Industry Standard Process for Data Mining) 분석 방법론
[개념]
비즈니스의 이해를 바탕으로 데이터 분석 목적의 6단계로 진행되는 데이터 마이닝 방법론
1996년 EU의 ESPRIT 프로젝트에서 시작한 방법론으로 1997년 SPSS 등이 참여하였으나 현재에는 중단
[구성]
| 구성 | 설명 |
| 단계 | 최상위 레벨 |
| 일반화 태스크 | 데이터 마이닝의 단일 프로세스를 완전하게 수행하는 단위 |
| 세분화 태스크 | 일반화 태스크를 구체적으로 수행하는 레벨 |
| 프로세스 | 실행 데이터 마이닝을 위한 구체적인 실행 |
[절차]
crisp-dm 분석 방법론 및 절차
: 업무 이해 → 데이터 이해 → 데이터 준비 → 모델링 → 평가 → 전개
1) 업무 이해
- 각종 참고 자료와 현업 책임자와의 커뮤니케이션을 통해 비즈니스를 이해하는 단계
- 업무 목적 파악, 상황 파악, 데이터 마이닝 목표 설정, 프로젝트 계획 수립
2) 데이터 이해
- 분석을 위한 데이터를 수집 및 속성을 이해하고, 문제점을 식별하며 숨겨져 있는 인사이트를 발견하는 단계
- 초기 데이터 수집, 데이터 기술 분석, 데이터 탐색, 데이터 품질 확인
3) 데이터 준비
- 데이터 정제, 새로운 데이터 생성 등 자료를 분석 가능한 상태로 만드는 단계
- 데이터 준비에 많은 시간이 소요
- 분석용 데이터 세트 선택, 데이터 정제, 데이터 통합, 학습/검증 데이터 분리 등 수행
4) 모델링
- 다양한 모델링 기법과 알고리즘을 선택하고 매개변수를 최적화하는 단계
- 모델링 기법 선택, 모델 테스트 계획 설계, 모델 작성, 모델 평가를 수행
5) 평가
- 모형의 해석 결과가 프로젝트 목적에 부합하는지 평가하고 결과의 수용 여부를 판단하는 단계
- 평가에 많은 시간이 소요
- 분석 결과 평가, 모델링 과정 평가, 모델 적용성 평가 수행
6) 전개
- 모델링과 평가 단계를 통해 완성된 모델을 업무에 적용하기 위한 계획을 수립하는 단계
- 전개에 많은 시간이 소요
- 전개 계획 수립, 모니터링과 유지보수 계획 수립, 프로젝트 종료 보고서 작성, 프로젝트 리뷰
17번. 과제중심적/마스터플랜
| 과제중심적(단기) | 비교 | 마스터 플랜(중장기) |
| Speed & Test | 1차 목표 | Accuracy & Deploy |
| Quick - Win | 과제의 유형 | Long Term View |
| Problem-Solving | 접근 방식 | Problem Definition |
<3과목>
21. 다음이 설명하는 표본추출방법으로 알맞은 것은?
모집단을 상이한 집단으로 나누고 각 집단에서 무작위로 표본을 추출하는 방법
1) 단순무작위 추출법
2) 계통 추출법
3) 군집 추출법
4) 층화 추출법
▶ [표본추출방법]
- 단순무작위 추출: 모집단에서 정해진 규칙 없이 표본 추출 (표본의 크기가 커질수록 정확도가 높아지며, 추정값이 모수에 근접하므로 추정값의 분산 감소)
- 계통 추출: 모집단을 일정한 간격으로 추출하는 방식
- 군집 추출: 모집단을 여러 군집으로 나누고, 일부 군집의 전체를 추출하는 방식 (집단 내부는 이질적, 집단 외부는 동질적)
- 층화 추출: 모집단을 여러 계층으로 나누고, 계층별로 무작위 추출을 수행 (층내는 동질적, 층간은 이질적)
22. 주성분 수의 선택 방법에 대한 설명으로 가장 옳지 않은 것은?
1) 주성분들이 설명하는 총 분산의 비율이 70~90% 사이가 되는 주성분의 개수를 선택할 수도 있다.
2) 고윳값이 1에 가까운 값을 선택한다.
3) 스크리 플랏(Scree Plot)을 통해서 주성분의 분산의 감소가 급격하게 줄어들어 주성분의 개수를 늘릴 때 얻게 되는 정보의 양이 상대적으로 미미한 지점에서 주성분의 개수를 정할 수 있다.
4) 전체변이 공헌도 방법은 고윳값 평균 및 스크리 플랏 방법보다 항상 우수하다.
▶ 각 방법에는 장점이 있고 다양한 상황에 적합할 수 있지만 주성분 수를 선택하는 데 있어 보편적으로 우수한 방법은 없다. 이는 종종 데이터의 특성과 분석의 구체적인 목표에 따라 달라진다.
- 상관관계가 있는 고차원 자료를 자료의 변동을 최대한 보존하는 저차원 자료로 변환하는 차원축소 방법
- 고윳값, 고유벡터를 통해 분석 (고윳값이 1에 가까운 값 선택)
- 주성분 분석의 목적 중 하나는 데이터를 이해하기 위한 차원 축소
- 주성분 분석에서 누적 기여율이 70% ~ 90% 사이가 되는 주성분의 수로 결정
- 스크리 산점도의 기울기가 완만해지기 전까지 주성분의 수로 결정할 수 있다
- 차원 축소 시 변수 추출 방법 사용
23. 의사결정나무 분리기준인 엔트로피 지수의 계산식은?
Entropy= −∑i=1npilog2(pi)
[출처: 블로그 '귀퉁이 서재']
먼저 확률 p는 전체 데이터에서 특정 데이터가 차지하는 비율을 말한다. 쉽게 말하면 주머니에서 파란색 공을 뽑을 확률. 우리가 아는 그것 맞다.
엔트로피를 구하는 식은 확률 p를 곱해서 더하는 구조를 가지고 있는데 이것은 정보의 기댓값(평균값)을 뜻한다.
그리고 확률에 log2를 취한다는 것은 데이터의 정보를 표현하기 위해서 필요한 비트 수를 확인할 수 있다는 뜻이다.
(비트는 0과 1로 나타남)
즉, 다시 말하자면 이 공식은 데이터가 몇 개의 비트로 나타낼 수 있는지, 필요한 정보의 크기가 얼마만큼인지 알아보는 것이다. 필요한 정보의 공간이 크다는 말은 엔트로피가 크다는 것이다. 정보가 복잡할 수록 필요한 정보를 저장할 공간이 더 커야하니까 말이다. 정리하자면 필요한 모든 비트 수를 평균한 값이 엔트로피가 된다. 그리고 맨 앞의 마이너스(-)는 지수를 양수로 만들기 위해서 사용되었다.
24. 확률에 대한 설명으로 가장 적합하지 않은 것은?
1) 각 사건의 확률은 0~1이다. (확률은 0 이상의 값을 가진다.)
2) 표본 공간(s)에서 발생 가능한 모든 사건의 확률의 합은 1이다.
3) A와 B가 독립사건인 경우, 각 독립사건들의 확률의 합은 합집합의 확률과 동일하다.
4) 전체 표본 중 독립적인 것을 근원사건이라 한다.
▶ 독립 사건 A와 B에 대해, 각각의 확률의 합은 합집합 확률과 같지 않다.
독립 사건 A와 B의 확률을 각각 P(A)와 P(B)라고 할 때, 각각의 확률의 합은 P(A) + P(B)이지만,
합집합 확률인 P(A ∪ B)은 P(A) + P(B) - P(A ∩ B)와 같다.
25. 아래 데이터는 닭의 성장률에 대한 다양한 사료 보충제의 효과를 측정하고 비교하기 위한 사료유형별 닭의 무게 데이터이다. summary 함수 결과에 대한 해석 중 옳지 않은 것은?
| > data("chickwts") > summary(chickwts) weight feed Min: 108.0 casein: 12 1st Qu: 204.5 horsebean: 10 Median: 258.0 linseed:12 Mean: 261.3 meatmeal: 11 3rd Qu: 323.5 soybean: 14 Max: 423.0 sunflower: 12 |
1) feed는 범주형 데이터이다.
2) feed의 사료 중 soybean 수가 가장 많다
3) range(chickwts$weight)의 결과는 108 423 이다.
4) weight의 평균값은 258.0이다.
▶ feed는 범주형 변수이며, 빈도와 함께 각 범주의 개수를 표시.
weight의 평균값은261.3이다.
Min: 최소값 / 1st Qu: 1사분위수 / Median: 중위값 / Mean; 평균값 / 3rd Qu: 3사분위수 / Max: 최대값
범위는 최소값 ~ 최대값: 108~423
26. 계층적 군집 방법으로 가장 알맞지 않은 것은?
1) 단일연결법
2) 완전연결법
3) 평균연결법
4) 편차연결법
▶ 군집 간의 거리를 측정하는 방법
1. 평균 연결법: 모든 항목에 대한 거리를 평균을 구하면서 가장 유사성이 큰 군집을 병합해 나가는 방법 (계산량이 불필요하게 많아질 수 있음. 이상치에 덜 민감)
2. 와드 연결법: 군집 내의 오차 제곱합에 기초하여 군집을 수행하는 방법
3. 최단 연결법: n * n 거리행렬에서 거리가 가장 가까운 데이터를 묶어서 군집 형(단일연결법)
4..중심 연결법: 두 군집의 중심 간의 거리 측정 (계산량이 적고, 중심 사이의 거리를 한 번만 계산)
5. 최장연결법: 두 군집 사이의 거리를 각 군집에서 하나씩 관측값을 뽑았을 때 나타날 수 있는 거리의 최댓값으로 측정(완전연결법)
27. 분해시계열의 요인으로 알맞지 않은 것은?
1) 추세요인
2) 계절요인
3) 환경요인
4) 순환요인
▶ 시계열 구성요소: 추세 요인, 계절 요인, 순환 요인, 불규칙 요인
28. 다음 수식으로 구할 수 있는 데이터간 거리는?
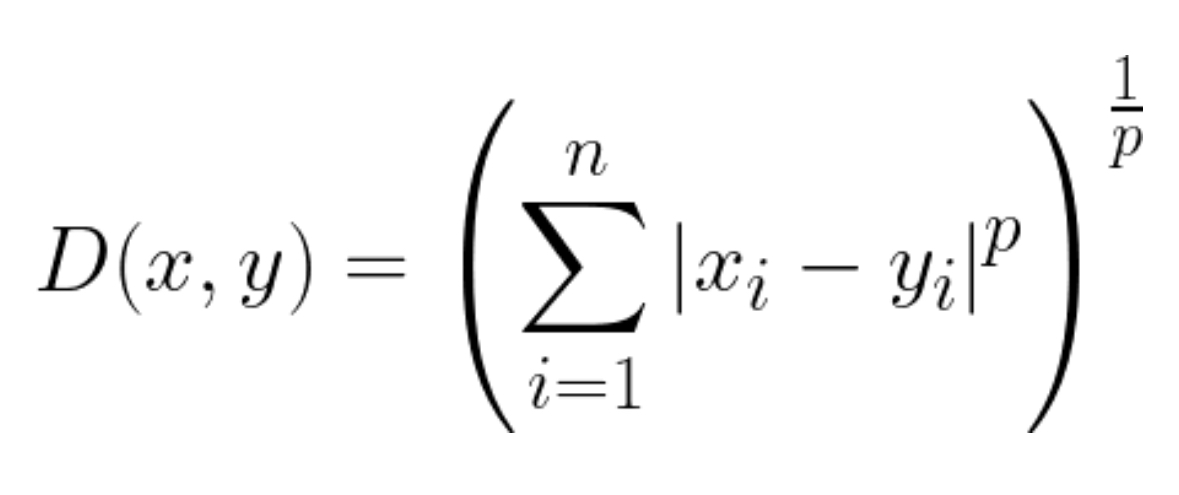
1) 유클리드 거리
2) 표준화 거리
3) 마할라노비스 거리
4) 민코프스키 거리
<데이터 유사성 측정방법>
[출처: 블로그 '이것저것 기록' https://anweh.tistory.com/54]
1. Euclidean Distance
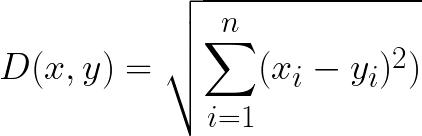
- 두 점 p, q사이의 유클리디안 거리를 구하면 이 두 점의 최단거리가 된다.
2. Manhattan Distance
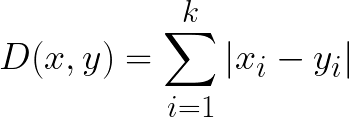
- 맨하탄 거리는 두 점 p, q가 있을 때, 가상 체스보드가 있다고 생각하고 오직 수평, 수직 이동만 하여 p에서 q까지 이동할 때 최단으로 걸리는 거리이다.
3. Chebyshev Distance

- 두 점 p, q간 좌표 차원을 따라 가장 긴 거리를 거리값으로 선택하는 방식이다.
- 식에서도 볼 수 있다시피 max(p, q)라고 써있다. (가장 긴 거리를 사용)
- 유클리디안이나 맨하탄에 비해 사용하는 케이스가 매우 한정적이다.
- 예를 들어, 최소한의 움직임 횟수를 도출하고자 할때 용이할 수 있다.
4. Minkowski Distance
- 민코프스키 거리는 유클리디안 거리와 맨해튼 거리를 일반화한 거리 공식이다.
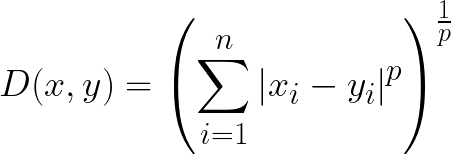
29. 다음 중 의사결정나무와 가장 관련 없는 용어는?
1) 카이제곱 통계량
2) 지니 지수
3) 엔트로피 지수
4) 퍼셉트론
▶ 퍼셉트론은 인공신경망과 관련 있다.
30. 두 개의 확률변수 X, Y의 공분산에 대한 설명 중 옳지 않은 것은?
1) 공분산이 양수이면 X가 증가할 때 Y도 증가한다.
2) 공분산이 음수이면 X가 증가할 때 Y는 감소한다.
3) 공분산의 크기는 상관계수와 동일하게 -1 ~ 1 사이의 범위를 갖는다.
4) 공분산이 0이면 두 변수간에는 아무런 선형관계가 없으며 두 변수는 서로 독립적인 관계이다.
▶ 공분산의 크기는 -1부터 1까지의 상관계수와 달리 음의 무한대부터 양의 무한대까지 가능하다.
공분산의 크기는 변수의 크기에 따라 달라지므로 절대적 크기로 판단이 어려움.
따라서, 공분산을 -1 ~ 1 범위로 표준화 시킨 것이 상관계수이다.
31. 아래의 F-Beta Score(지표) 에 대한 설명으로 옳은 것은?
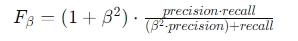
1) Beta 값이 1.0보다 크면 Precison에 비중을 두고 계산한다.
2) Beta 값이 1.0보다 작으면 Recall에 비중을 두고 계산한다
3) Beta 값이 0.5 일 경우 Precison에 2배 가중치하여 평균한다.
4) Recall 값과 Precison 값이 정확히 같다면 Beta에 관계없이 다른 결과가 나온다.
▶ f-beta score는 precision과 recall의 가중 조화 평균이며, beta가 1일 때 F1 score에 해당한다.
여기서, precision은 정밀도이고, recall은 재현율이다. beta는 정밀도에 대한 가중치를 조절하는 파라미터이다.
[보기 해설]
- 베타 값이 1.0보다 큰 경우 F-베타 점수는 계산에서 재현율보다 정밀도를 더 강조한다.
- 베타 값이 1.0보다 작으면 F-베타 점수는 정밀도보다 재현율을 우선시한다.
- 구체적으로 베타값이 0.5인 경우 F-베타점수 계산시 정밀도는 재현율 대비 2배의 가중치를 부여한다.
- 정밀도와 재현율 값이 정확히 동일하면 베타 값에 관계없이 F-베타 점수는 동일한 결과를 산출한다.
32. 앙상블 기법에 대한 설명으로 알맞은 것은?
1) 앙상블 기법을 사용하게 되면 각 모형의 상호 연관성이 높을수록 정확도가 향상된다.
2) 대표적인 앙상블 기법은 배깅, 부스팅이 있다
3) 전체적인 예측값의 분산을 유지하여 정확도를 높일 수 있다.
4) 랜덤 포레스트는 앙상블 기법 중 유일한 비지도학습 기법이다
▶ 앙상블 기법은 여러 개의 모델을 조합하여 더 강력한 모델을 만드는 기법이다.
대표적인 앙상블 기법으로는 배깅(Bagging)과 부스팅(Boosting)이 있다.
배깅은 각각의 모델을 병렬적으로 학습시켜 결합하는 방식이며, 부스팅은 이전 모델의 오차를 보완하면서 순차적으로 학습하는 방식이다.
33. 다음 중 통계적 가설검정에 대한 설명으로 옳지 않은 것은?
1) 귀무가설이 사실일 때, 이 귀무가설을 기각함으로써 발생하는 오류를 유의수준이라 한다.
2) 귀무가설이 거짓일 경우, 이를 옳지 않다고 판단하는 확률을 검정력이라 한다.
3) 사실인 귀무가설을 기각했을 때 발생하는 오류를 제 2종 오류라 한다.
4) p-value(유의확률)이 클수록 귀무가설을 채택하는 것으로 해석한다.
▶ 제1종오류: 귀무가설이 참인데 잘못하여 이를 기각하게 되는 오류
- 제2종오류: 귀무가설이 거짓인데 잘못하여 이를 채택하게 되는 오류
34. k-means 군집분석에 대한 설명으로 옳은 것은?
1) 군집에서 가장 중심에 위치한 객체를 사용하여 k개의 군집을 찾게 된다.
2) K-Medoids 알고리즘에 비해 노이즈 처리에 우수하고 연산량이 많다.
3) 초승달 모양 (Crescent Shaped) 데이터 셋에 적합하다
4) 군집 절차 수행 시 군집 수 K는 초기에 설정되어야 한다.
▶ k-means 군집분석에서는 군집 수 K를 초기에 설정해야 한다. 이는 알고리즘이 시작될 때 각 데이터 포인트를 K개의 군집 중 하나로 할당하기 위해 필요한 정보이기 때문이다. 초기에 잘못된 K 값을 선택하면 결과가 좋지 않을 수 있으므로 K 값 설정이 중요하다.
35. 아래 오분류표에서 재현율(Recall)로 가장 알맞은 것은?
| 예측값 | 합계 | |||
| True | False | |||
| 실제값 | True | 30 | 70 | 100 |
| False | 60 | 40 | 100 | |
| 합계 | 90 | 110 | 200 | |
1) 3/10 2) 2/5 3) 1/3 4) 7/11
36. 확률질량함수의 확률변수 X의 기대값은?
| x | 1 | 2 | 3 |
| f(x) | 1/6 | 3/6 | 2/6 |
1) 10/6 2) 11/6 3) 12/6 4) 13/6
▶ (1*1/6) + (2*3/6) + (3*2/6) = 13/6
37. 군집분석 시 데이터의 단위가 다를 경우 사용하는 기법으로 알맞은 것은?
1) Elimination
2) Sampling
3) Averaging
4) Scailing
▶ 데이터의 단위가 다를 경우, 군집분석에 사용되는 기법으로는 스케일링이 적합하다.
스케일링은 데이터의 단위를 조정하여 서로 다른 변수들 간에 공정한 비교를 가능하게 한다.
일반적으로 사용되는 스케일링 방법에는 normalization(정규화)과 standardization(표준화)이 있다.
이러한 스케일링 기법을 사용하여 데이터의 범위를 일정하게 조절할 수 있어 군집분석 결과를 향상시킨다.
1) 제거 2) 샘플링(표본추출) 3)평균화
38. 다음 중 통계 용어에 대한 설명으로 옳지 않은 것은?
1) 다른 변수의 영향을 받는 변수를 설명변수라고 한다.
2) 모집단의 평균을 추정하기 위해 표본 평균을 계산한다.
3) 표준 편차는 데이터가 평균으로부터 떨어진 정도를 나타내는 척도이다.
4) 사분위수범위는 데이터의 25%, 50%, 75% 위치 중 75%에서 25%의 값을 뺀 값이다.
▶ 독립변수 / 종속변수
| 원인 (조작 - 제어) | 결과 (측정 결과) | |
| 독립변수 | 종속변수 | |
| 설명변수 | 반응변수 | |
| 예측변수 | 결과변수 | |
| 위험인자 | 표적변수 | |
| 공변량 (연속형 자료) | 요인(범주형 자료) | |
39. 다음 중 시계열 모형에 대한 설명으로 옳은 것은?
1) ARIMA의 약어는 AutoRegressiv Imporved Moving Average 이다
2) ARIMA 모형에서 p=0 일 때, IMA(d,q) 모형이라고 부르고, d번 차분하면 MA(q) 모형을 따른다.
3) 분해시계열은 일반적인 요인을 분리하여 분석하는 방법으로 회귀분석적인 방법과는 다르게 사용한다.
4) ARIMA 모형에서는 정상성을 확인할 필요가 없다.
▶ 분해 시계열이란 시계열에 영향을 주는 일반적인 요인들을 시계열에서 분리시켜 분석하는 방법을 말하며, 회귀분석적인 방법을 주로 사용한다.
- ARIMA model (Autoregressive Integrated Moving average Model)
d=0일 경우 ARMA(p,q)모형이라 부르는 것이고 이때 ARMA모형은 정상성을 만족한다.
그리고 ARMA모형은 단순하게 AR과 MA모형이 공존하는 형태이다.
p=0이면 IMA(d,q)모형이라 부르며, 이 모형을 d번 차분하면 MA(q)모형이 된다.
마찬가지로 q=0일 경우 ARI(p,d)모형이며 이를 d번 차분했을 때 시계열 모형이 AR(p)를 따른다.
즉, ARIMA는 비정상 시계열로 정상시계열 자료형태인 AR/MA/ARMA로 d번 차분하여 변환시키는 모형이다.
40. 다음 중 데이터의 정규성을 확인하기 위한 방법으로 알맞지 않은 것은?
1) Q_Q Plot
2) 결정계수
3) 히스토그램
4) 첨도와 왜도
▶ 결정계수는 데이터의 선형 관계의 적합도를 평가하는 지표로 사용되며, 정규성을 확인하는 데 사용되지 않는다.
결정계수는 주로 회귀 분석에서 사용되며, 0과 1 사이의 값을 가지며, 값이 클수록 회귀선이 데이터에 더 잘 적합됨을 나타낸다. 따라서 이는 데이터의 정규성을 확인하는 방법으로 부적절하다.
41. 다음 중 선형회귀모형이 통계적으로 유의미한지 평가하는 통계량으로 옳은 것은?
1) F-Statistics
2) Chi-Statistics
3) T- Statistics
4) R-Square
▶ F-Statistics는 회귀 모델 전체의 설명력을 평가하는 지표로, 회귀식이 종속 변수에 대해 통계적으로 유의미한지를 판단하는 데 사용된다. 일반적으로 F-Statistics의 p-value가 유의수준보다 작으면 회귀 모델은 통계적으로 유의미하다고 간주된다.
[보기 해석]
1) F-통계량 2) 카이제곱 3) T-통계량 4) 결정계수
42. 데이터의 양이 가장 많이 발생하는 유형의 척도로 알맞은 것은?
1) 명목척도
2) 순서척도
3) 등간척도
4) 비율척도
▶ 데이터의 양이 가장 많이 발생하는 유형의 척도는 비율척도이다. 비율척도는 간격척도와 달리 절대적인 0점을 가지며, 이로써 비율을 계산할 수 있다. 예를 들어, 길이나 무게 등의 측정에서 0은 '아무것도 없음'을 나타내며, 0을 기준으로 상대적인 크기와 비율을 측정할 수 있다.
43. 상관계수에 대한 설명으로 옳지 않은 것은?
1) 피어슨 상관계수는 두 변수 간의 선형적인 관계의 강도를 측정한다
2) 피어슨 상관계수는 두 변수의 원래 값을 사용하여 계산한다
3) 스피어만 상관계수는 모수적 관계에서 두 변수 간의 단조적인 관계의 강도를 측정한다
4) 피어슨 상관계수가 0이면 선형관계가 없다
▶ 스피어만 상관계수는 모수적이지 않은 방법으로 순서적 관계를 평가한다. 즉, 순서 데이터에 대한 상관성을 측정하며, 단조적인 관계의 강도를 나타낸다.
44. 시계열 데이터의 정상성(Stationary)에 대한 설명으로 옳지 않은 것은?
1) 평균이 일정하다
2) 시계열 자료는 독립성을 충족해야 한다
3) 분산이 시점에 의존하지 않는다
4) 공분산은 단지 시차에만 의존하고 시점 자체에는 의존하지 않는다
▶ 시계열 데이터는 일반적으로 독립성을 충족하지 않는다. 시계열 데이터는 시간에 따라 관측치 간에 일정한 상관 관계를 가지고 있기 때문에 독립성의 가정을 만족하지 않을 수 있다.
45. 다음 중 회귀분석에서 모형의 설명력을 확인하기 위해 사용되는 결정계수의 특성으로 옳지 않은 것은?
1) 결정계수는 0에서 1의 값을 가진다
2) 높은 값을 가질수록 측정된 회귀식의 설명력이 높다
3) 총 변동에서 추정된 회귀식에 의해 설명되는 변동의 비율로 나타낼 수 있다
4) 종속변수와 독립변수 사이의 표본 상관계수값과 같다
▶ 결정계수는 종속변수의 분산 중 회귀식으로 설명되는 비율을 나타내며, 표본 상관계수와는 관련이 없다.
46. 선형회귀모형의 오차항에 대한 가정조건으로 옳은 것은?
1) 독립성, 선형성, 등분산성
2) 독립성, 등분산성, 정규성
3) 정규성, 효율성, 등분산성
4) 정규성, 편의성, 독립성
▶ 선형회귀모형의 오차항에 대한 가정은
독립성(오차항 간의 상관관계가 없음),
등분산성(오차항의 분산이 동일함),
정규성(오차항이 정규분포를 따름)을 만족해야 한다.
47. 아래 설명에 해당하는 용어로 알맞은 것은?
다중 신경망 모형에서 은닉 층의 개수를 너무 많이 설정하면 역전파 과정에서 앞쪽 은닉층의 가중치가 조정되지 않아, 신경망에 대한 학습이 제대로 되지 않는 현상
1) 기울기소실 문제
2) 과적합
3) 활성화 함수
4) 신경망 레이어 소실
48. 아래 보기의 회귀모델에 대한 설명 중 옳지 않은 것은?
| > library(MASS) > data(ChickWeight) > Chick = ChickWeight(ChickWeight$Diet==1 & ChickWeight$Chick==1,) > model = lm(weight ~ Time, Chick) > summary(model) Call: lm(formula = weight ~ Time, data = Chick) Residuals: Min 1Q Median 3Q Max -14.3203 -11.3081 -0.4444 11.1162 17.5346 Coefficients: Estimate Std.Error t value Pr(>|t|) (intercept) 24.4654 6.7279 3.636 0.00456 ** Time 7.9879 0.5236 15.225 2.97e-08 *** --- Signif. codes: 0 *** 0.001 ** 0.01 ** 0.05 * '.' 0.1 '' 1 Residual standard error: 12.29 on 10 degrees of freedom Multiple R-squred: 0.9588, Adjusted R-squared: 0.9547 F-Statistic: 232.7 on 1 and 10 DF, p-value: 2.974e-08 |
1) 추정된 회귀식은 weight = 24.4654 + 7.9879*time 과 같다
2) F 통계량: 232.7, p>값: 2.974e-08로 보아 유의수준 5% 하에서 추정된 회귀 모형이 통계적으로 매우 유의하다
3) time 이 1 증가할 때, weight 이 5.99 만큼 증가한다.
4) 결정계수 또한 0.9588로 매우 높은 값을 보이므로 이 회귀식이 데이터를 약 96% 정도로 설명하고 있다.
▶ time 이 1 증가할 때, weight 이 7.9879 만큼 증가
49. 카이제곱 통계량의 예측 표본과 실제 표본의 차이와 검정 통계량에 따른 유의확률의 변화로 옳은 것은?
1) 카이제곱 통계량을 이용한 적합도 검정은 여러 범주형 변수에 대해 관측 값들이 어떤 이론이나 이론적 분포를 따르고 있는지를 검정하는 방법이다
2) 데이터의 정규성을 검정하기 위해 오차항이 정규분포를 추종하는지 알아보는 검정방법이다.
3) 예측 표본과 실제 표본의 차이가 많을 때, 도수가 낮아지고 검정 통계량이 높아져 유의확률이 낮아진다.
4) 각 데이터 포인트와 이론적인 분포 간의 차이를 측정하여 이 차이를 기반으로 검정 통계량을 계산한다.
▶
1) 카이제곱 적합도 검정은 변수가 지정된 분포에서 추출될 가능성이 있는지 여부를 확인하는 데 사용되는 통계적 가설 검정이다. 대개 표본 데이터가 전체 모집단을 대표하는지 평가하는 데 사용된다. (여러 범주형 변수 X)
2) 데이터의 정규성을 검정하기 위해 오차항이 정규분포를 추종하는지 알아보는 검정방법은 크루스칼 왈리스 검정
4) 카이제곱 적합도 검정에서는 관찰된 값과 기대되는 값 사이의 차이를 제곱한 후 합산하여 카이제곱 통계량을 구하고, 이를 통해 가설을 검정
50. 인공신경망 함수에 대한 설명으로 옳지 않은 것은?
1) 인공신경망 함수는 여러 개의 뉴런이 연결된 구조를 가지고 있으며, 각 뉴런은 입력값에 따라 비선형적인 변환을 수행한다.
2) 쌍곡탄젠트 함수는 0~1 사이의 값을 출력하며 시그모이드 함수와 관련이 있다
3) 인공신경망 함수는 활성화 함수를 사용하여 입력값을 출력값으로 변환한다
4) 대표적인 인공신경망 함수로는 시그모이드 함수, 쌍곡탄젠트 함수, 렐루 함수 등이 있다.
▶ 쌍곡탄젠트 함수 (하이퍼볼릭 탄젠트)
: 이 함수는 실수 값을 (-1, 1) 범위로 압축하는 활성화 함수이다. 원점을 중심으로 하여 값이 양의 무한대로 갈수록 1에 수렴하고, 값이 음의 무한대로 갈수록 -1에 수렴한다. 이 함수는 그 형태가 S자를 닮았기 때문에 'Sigmoid 함수'의 일종으로 간주되며, 이런 특징 덕분에 비선형성을 모델에 부여할 수 있다.
[문제 해설 영상 보기]
1과목 & 2과목
3과목(1)
3과목(2)
'자격증 > ADsP' 카테고리의 다른 글
| [ADsP] 시험 후기 (독학) (0) | 2024.05.11 |
|---|---|
| [ADsP] 제38회 기출문제 [풀이] (0) | 2024.05.04 |
| [ADsP] 제38회 기출문제 (1) | 2024.05.03 |
| [ADsP] 예상 기출 문제 (1) | 2024.05.02 |
| [ADsP] 시험의 주요 내용 (0) | 2024.05.02 |


