시작에 앞서
해당 내용은 <파이썬으로 데이터 주무르기> -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.
보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.
지난 챕터
[파이썬] 자연어 처리(NLP) - 여자친구 선물 고르기 : 1
시작에 앞서해당 내용은 -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.지난 챕터 [파이썬] 자연어 처리(NLP) 시작하기
puppy-foot-it.tistory.com
※ 이번 챕터는 실패 (+ 포기) 한 챕터이므로, 성공 버전은 아래 링크로 넘어가시면 됩니다.
[파이썬] 자연어 처리(NLP) - 여자친구 선물 고르기 : 2(재도전)
시작에 앞서해당 내용은 -민형기 저, BJPUBLIC 출판사 의 내용을 토대로 작성되었습니다.보다 자세한 내용은 해당 교재를 확인하여 주시기 바랍니다.지난 챕터 [파이썬] 자연어 처리(NLP) - 여자친
puppy-foot-it.tistory.com
여자친구 선물 고르기 (feat. 네이버 지식인 웹크롤링)
지난 챕터에서는 네이버 지식인의 "여자 친구 선물" 이라는 검색어 결과에 나오는 값들을 리스트로 저장하는 과정을 수행했는데, 403 forbidden 에러 로 인하여 분석이 난관에 부딪혔었다. (물론 현재 진행형)
※ 403 forbidden 에러: 서버에서 설정해 둔 권한과 맞지 않는 접속 요청이 들어오면 접근을 거부하고 접근거부 코드를 반환
여러가지 방법을 시도하다가 결국엔 403 forbidden 에러 메시지를 받는데 성공했으나,
리스트에 저장된 값이 없는 코드를 생성하여 다시 한 번 이를 해결해야 할 상황에 놓였다.
다시 여태까지 시도했던 여러 코드를 조합하여, 성공!
(그런데 10000개를 하면 로딩 시간이 너무 길어서 1000개로 갯수를 줄였다.)
from tqdm import tqdm_notebook
import urllib.request
# 검색할 질의어 설정
query = "여자 친구 선물"
# 검색 결과 페이지 URL
url = f"https://kin.naver.com/search/list.naver?query={query}"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
# 여자친구 선물에 대한 후보 텍스트를 저장할 리스트를 초기화.
present_candi_text = []
# 범위 내에서 페이지를 반복하여 검색 결과를 가져오는 반복문.
for n in tqdm_notebook(range(1, 1000, 10)):
# 현재 페이지 URL
page_url = f"{url}&start={start_num}"
# HTTP GET 요청 보내고 응답 받기
response = requests.get(page_url)
# BeautifulSoup을 사용하여 HTML을 파싱.
soup = BeautifulSoup(response.text, "html.parser")
# HTML에서 모든 <div> 태그를 찾아서 가져옴.
tmp = soup.find_all('div')
# 각 태그에서 텍스트를 추출하여 present_candi_text 리스트에 추가.
for line in tmp:
present_candi_text.append(line.text)
# 서버에 부담을 주지 않기 위해 0.5초의 간격을 두고 잠시 대기.
time.sleep(0.5)
네이버 크롤링 관련 403 오류 발생 원인과 이를 해결할 수 있었던 것은
1) urlopen 함수는 네이버 차단 프로그램에 의해 무조건 잡힌다
▶ f 포맷팅을 활용, url 주소 앞에 f 를 붙임
2) pip install fake-useragent 명령을 통해 fake-useragent 를 설치하고 import 한 것
이 두 가지가 주요한 것으로 생각된다.
아무튼, 몇 시간동안 포기않고 끈질기고 집요하게 매달려서 해결한 나 칭찬해!

지식인 검색 결과 자연어 처리하기
이제 자연어 처리에 사용할 도구를 import 하고
import nltk
from konlpy.tag import Okt; o = Okt()
하나의 글로 present_text 라는 변수에 저장
# present_candi_text 리스트에서 처음 1000개의 요소를 가져와서 하나의 문자열인 present_text에 추가
#present_text 변수를 빈 문자열('')로 초기화
present_text = ''
# for 루프를 사용하여 present_candi_text의 각 요소를 순회
for each_line in present_candi_text[:1000]: # present_candi_text 리스트의 처음 1000개의 요소를 가져옴
# 각 요소를 present_text 문자열에 추가(줄바꿈 문자('\n')를 추가하여 한 줄씩 새로운 텍스트로 구분)
present_text = present_text + each_line + '\n'
형태소 분석을 하고, 분석을 마친 단어를 가지고 token을 가져옴
tokens_ko = o.morphs(present_text)
tokens_ko
토큰으로 모은 단어를 조회해보고, 중복된 단어를 뺀 단어수도 조회해본다.
ko = nltk.Text(tokens_ko, name='여자친구 선물')
print(len(ko.tokens))
print(len(set(ko.tokens)))
그리고 '여자친구 선물'이라는 이름의 한국어 텍스트 데이터에서 가장 빈도가 높은 상위 100개의 단어를 추출하는 작업을 해본다.
ko = nltk.Text(tokens_ko, name='여자친구 선물')
ko.vocab().most_common(100)
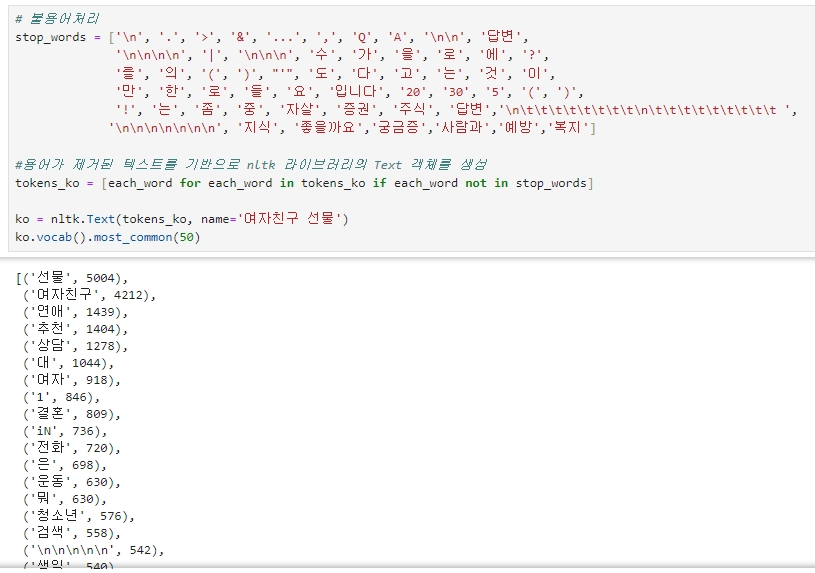
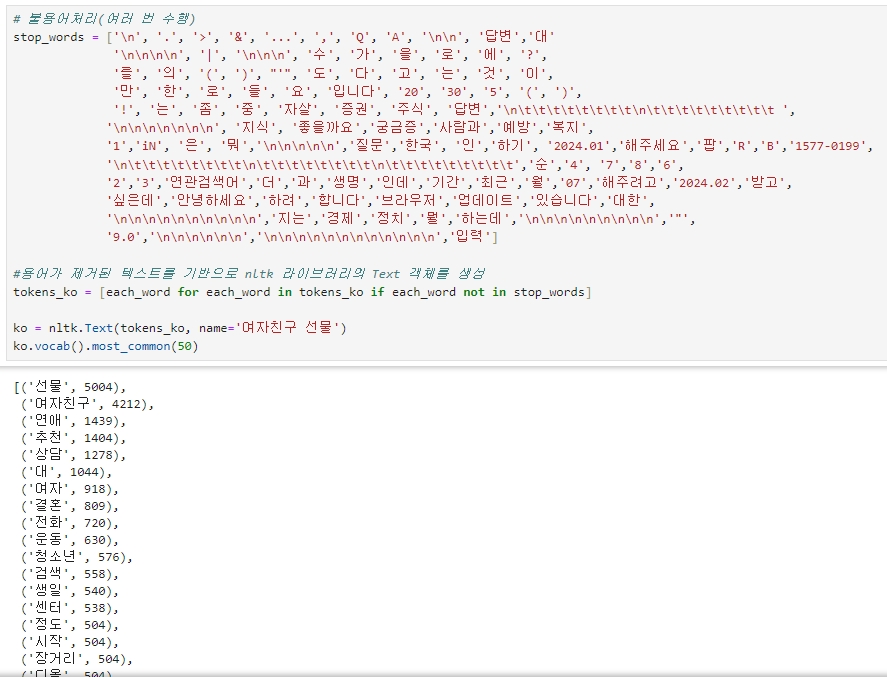
불용어 처리
빈도수 분석을 통해 나타난 단어들을 보면 의미 없는 단어들이 많이 보인다. 그래서 이 단어들을 제거해준다.
그리고 불용어가 처리된 텍스트를 기반으로 다시 객체를 생성하고, 빈도수가 가장 높은 50개의 단어를 표시한다.
# 불용어처리
stop_words = ['\n', '.', '>', '&', '...', ',', 'Q', 'A', '\n\n', '답변',
'\n\n\n\n', '|', '\n\n\n', '수', '가', '을', '로', '에', '?',
'를', '의', '(', ')', "'", '도', '다', '고', '는', '것', '이',
'만', '한', '로', '들', '요', '입니다', '20', '30', '5', '(', ')',
'!', '는', '좀', '중', '자살', '증권', '주식', '답변','\n\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t\t ',
'\n\n\n\n\n\n\n', '지식', '좋을까요','궁금증','사람과','예방','복지']
#불용어가 제거된 텍스트를 기반으로 nltk 라이브러리의 Text 객체를 생성
tokens_ko = [each_word for each_word in tokens_ko if each_word not in stop_words]
ko = nltk.Text(tokens_ko, name='여자친구 선물')
ko.vocab().most_common(50)
등장 빈도에 따른 빈도수 그래프 그리기
plt.figure(figsize=(15,6))
ko.plot(50)
plt.show()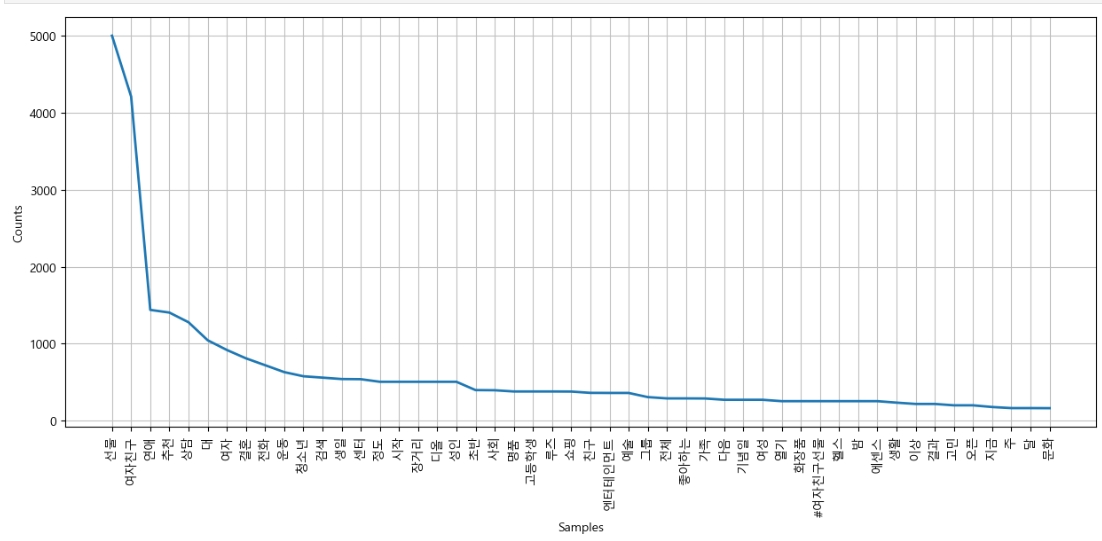
워드 클라우드 그리기
워드 클라우드를 그리기 위해 필요한 모듈을 import
from wordcloud import WordCloud, STOPWORDS
from PIL import Image
빈도수가 높은 단어 300개를 활용하여 워드 클라우드 그리기
# 가장 빈번하게 등장하는 단어 300개를 추출
data = ko.vocab().most_common(300)
# 워드클라우드 객체 생성 (폰트 지정)
wordcloud = WordCloud(font_path="c:/Windows/Fonts/malgun.ttf",
relative_scaling=0.5, # 상대적인 크기 조정값 설정
background_color='white', # 배경은 흰색
width=800, height=400 # 이미지의 가로와 세로 크기 설정
).generate_from_frequencies(dict(data)) # data 변수에서 얻은 단어 빈도 기반으로 워드클라우드 생성
plt.figure(figsize=(16, 8))
plt.imshow(wordcloud, interpolation='bilinear') # 객체를 이미지로 표시
plt.axis('off') # 그래프의 축을 비활성화
plt.show()
그런데..... 'ValueError: anchor not supported for multiline text' 라는 에러 메시지를 받는다.
이 에러는 워드클라우드의 텍스트가 여러 줄로 구성되어 있을 때 발생하는 것인데,
챗gpt에 검색(그래서 교재와는 다른 코드를 입력하였다) 해보고, 구글링을 해봐도 도통 해결책을 모르겠다..
네이버 웹 크롤링에 이어 찾아온 2차 난관이다.
그래서 우선 이것은 넘어가고...(추후 성공하면 그때 수정하겠다. 지금은 너무 지쳤으므로..)
하트 그림에 워드 클라우드 그려보기
먼저 하단의 하트 그림을 다운받고
이미지 마스크를 사용하여 워드클라우드를 생성
#이미지 마스크 생성 (이미지 파일을 열어 Numpy 배열로 변환 후 mask 변수에 저장)
mask = np.array(Image.open('../data/09. heart.jpg')) #이미지 마스크 생성
# 워드클라우드의 색상을 지정하기 위해 이미지 색상 생성기 import
from wordcloud import ImageColorGenerator
# 마스크 이미지의 색상 정보를 가져와서 ImageColorGenerator 객체 생성
image_colors = ImageColorGenerator(mask)
※ 결국 여기까지만 하고, 지식인부터 다시 해보기로 결정!
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 자연어 처리(NLP) - 여자친구 선물 고르기 : 3(진행불가) (0) | 2024.05.15 |
|---|---|
| [파이썬] 자연어 처리(NLP) - 여자친구 선물 고르기 : 2(재도전 - 성공) (2) | 2024.05.15 |
| [파이썬] 자연어 처리(NLP) - 여자친구 선물 고르기 : 1 (1) | 2024.05.15 |
| [파이썬] 자연어 처리(NLP) 시작하기 - 8 (0) | 2024.05.14 |
| [파이썬] 자연어 처리(NLP) 시작하기 - 7 (0) | 2024.05.13 |




{kind=link}