시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적을 참고해 주시기 바랍니다.
네이버 도서
책으로 만나는 새로운 세상
search.shopping.naver.com
넘파이 (NumPy)
머신러닝의 주요 알고리즘은 선형대수와 통계 등에 기반하며, 특히 선형대수는 수학 뿐만 아니라 다른 영역의 자연과학, 공학에서 널리 사용되고 있다.
Numerical Python을 의미하는 넘파이는 파이썬에서 선형대수 기반의 프로그램을 쉽게 만들 수 있도록 지원하는 대표적인 패키지이다. 루프를 사용하지 않고 대량 데이터의 배열 연산을 가능하게 하므로 빠른 배열 연산 속도를 보장한다.
넘파이는 또한 C/C++과 같은 저수준 언어 기반의 호환 API를 제공한다. 기존 C/C++ 기반의 타프로그램과 데이터를 주고받거나 API를 호출해 쉽게 통합할 수 있는 기능을 제공한다.
넘파이는 매우 빠른 배열 연산을 보장해 주지만, 파이썬 언어 자체가 가지는 수행 성능의 제약이 있으므로 수행 성능이 매우 중요한 부분은 C/C++ 기반의 코드로 작성하고 이를 넘파이에서 호출하는 방식으로 쉽게 통합할 수 있다. (구글의 대표적인 딥러닝 프레임워크인 텐서플로는 이러한 방식으로 배열 연산 수행 속도를 개선하고 넘파이와도 호환될 수 있게 작성되었다.)
넘파이는 배열 기반의 연산은 물론이고 다양한 데이터 핸들링 기능을 제공한다. 많은 파이썬 기반의 패키지가 넘파이를 이용해 데이터 처리를 수행하지만, 편의성과 다양한 API 지원 측면에서 아쉬운 부분이 있고 파이썬의 대표적인 데이터 처리 패키지인 판다스의 편리성에는 미치지 못한다.
넘파이는 매우 방대한 기능을 지원하고 있기에 이를 마스터하기에는 상당한 시간과 코딩 경험이 필요하나, 머신러닝 알고리즘이나 사이파아와 같은 과학, 통계 지원용 패키지를 직접 만드는 개발자가 아니라면 넘파이를 상세하게 알 필요는 없다. 그럼에도 불구하고, 넘파이를 이해하는 것은 파이썬 기반의 머신러닝에서 매우 중요하다. 왜냐하면 많은 머신러닝 알고리즘이 넘파이 기반으로 작성돼 있으며, 이들 알고리즘의 입력 데이터와 출력 데이터를 넘파이 배열 타입으로 사용하기 때문이다. 또한, 판다스와 같은 다른 데이터 핸들링 패키지를 이해하는 데도 많은 도움이 된다.
넘파이 ndarray 개요 - np.array
넘파이 기반 데이터 타입은 ndarray 이다. ndarray를 이용해 넘파이에서 다차원(Multi-dimension) 배열을 쉽게 생성하고 다양한 연산을 수행할 수 있다.
넘파이 array() 함수는 파이썬의 리스트와 같은 다양한 인자를 입력받아서 ndarray로 변환하능 기능을 수행한다. 생성된 ndarray 배열의 shape 변수는 ndarray의 크기, 즉 행과 열의 수를 튜플 형태로 가지고 있으며 이를 통해 ndarray 배열의 차원까지 알 수 있다.
[np.array() 사용법]
ndarray로 변환을 원하는 객체를 인자로 입력하면 ndarray를 반환한다.
ndarray.shape: ndarray의 차원과 크기를 튜플 형태로 나타내 준다.

<데이터 풀이>
▶ [1,2,3]인 array1의 shape는 (3,) - 이는 1차원 array로 3개의 데이터를 가지고 있음을 의미.
▶ [[1,2,3], [2,3,4]]인 array2의 shape는 (2,3) - 이는 2차원 array로, 2개의 로우와 3개의 칼럼으로 구성되어 2*3=6개의 데이터를 가지고 있음을 의미.
▶ [[1,2,3]]인 array3의 shape는 (1,3) - 이는 1개의 로우와 3개의 칼럼으로 구성된 2차원 데이터를 가지고 있음을 의미.
※ array3은 array1과 동일한 데이터 건수를 가지고 있지만, array1은 명확하게 1차원임을, array3 은 명확하게 로우와 칼럼으로 이뤄진 2차원 데이터임을 표현.
이 차이를 이해하는 것은 매우 중요한데, 머신러닝 알고리즘과 데이터 세트 간의 입출력과 변환을 수행하다 보면 명확히 1차원 데이터 또는 다차원 데이터를 요구하는 경우가 있다. 분명히 데이터값으로는 서로 동일하나 차원이 달라 오류가 발생하는 경우가 빈번하다. 이 경우 명확히 차원의 차수를 변환하는 방법을 알아야 이런 오류를 막을 수 있다.
ndarray.ndim을 통한 각 array의 차원 확인
array() 함수의 인자로는 파이썬의 리스트 객체가 주로 사용되며, 리스트 [ ] 는 1차원, 리스트의 리스트 [[ ]]는 2차원과 같은 형태로 배열의 차원과 크기를 쉽게 표현할 수 있기 때문이다.
# 각 배열의 차원 수 표시
print('array1: {0}차원, array2: {1}차원, array3: {2}차원'.format(array1.ndim, array2.ndim, array3.ndim))
ndarray의 데이터 타입
ndarray 내의 데이터값은 숫자 값, 문자열 값, 불 값 등이 모두 가능하다. 숫자형의 경우 int형(8bit, 16bit, 32bit), unsigned int형(8bit, 16bit, 32bit), float형(16bit, 32bit, 64bit, 128bit), 그리고 이보다 더 큰 숫자 값이나 정밀도를 위해 complex 타입도 제공한다.
ndarray내의 데이터 타입은 그 연산의 특성상 같은 데이터 타입만 가능하다. 즉, 한 개의 ndarray 객체에 int와 float가 함께 있을 수 없다. ndarray내의 데이터 타입은 dtype 속성으로 확인할 수 있다.
list1 = [1,2,3] #리스트 생성
print(type(list1)) #리스트 출력
array1 = np.array(list1) #리스트를 넘파이 배열로 변환하여 array1에 저장
print(type(array1)) #array1의 자료형 출력
print(array1, array1.dtype) #넘파이 배열 값과 데이터 타입 출력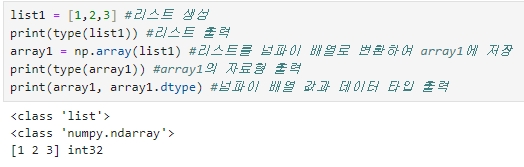
▶ 리스트 자료형인 list1은 integer 숫자인 1, 2, 3을 값으로 가지고 있으며, 이를 ndarray로 쉽게 변경할 수 있다. 이렇게 변경된 ndarray 내의 데이터값은 모두 int32 형이다.
다른 유형이 섞여 있는 리스트 내의 값 통일하기 (feat. ndarray)
ndarray 내의 데이터 타입은 그 연산의 특성상 같은 데이터 타입만 가능하다고 했는데, 만약 다른 데이터 유형이 섞여 있는 리스트를 ndarray로 변경하면 데이터 크기가 더 큰 데이터 타입으로 형 변환을 일괄 적용한다.
[int형과 string형이 섞여있는 리스트와 int형과 float형이 섞여 있는 리스트를 ndarray로 변경해보기]
#int형 + string형 리스트
list2 = [1, 2, 'test']
array2 = np.array(list2)
print(array2, array2.dtype)
#int형 + float형 리스트
list3 = [1, 2, 3.0]
array3 = np.array(list3)
print(array3, array3.dtype)
▶ int+string 형의 list2 - 숫자형 값 1, 2가 모두 문자열 값인 '1', '2'로 변경
▶ int+float 형의 list3 - int 1, 2가 모두 float64 형으로 변환 (참고로, float은 실수)
다른 유형이 섞여 있는 리스트 (feat. astype)
ndarray 내 데이터값의 타입 변경도 astype() 메서드를 이용해 할 수 있다.
astype()에 인자로 원하는 타입을 문자열로 지정하면 된다. 이렇게 데이터 타입을 변경하는 경우는 대용량 데이터의 ndarray를 만들 때 많은 메모리가 사용되는데, 메모리를 더 절약해야 할 때 보통 이용된다.
가령 int형으로 충분한 경우인데, 데이터 타입이 float 라면 int 형으로 바꿔서 메모리를 절약할 수 있는 식이다.
[int32형 데이터를 float64로 변환하고, float64를 int32로 변경하기]
# int 32 > float 64
array_int = np.array([1, 2, 3])
array_float = array_int.astype('float64') #array_int를 float64 타입으로 변환
print(array_float, array_float.dtype)
# float 64> int 32
array_int1 = array_float.astype('int32') #데이터 타입을 int32로 변경
print(array_int1, array_int1.dtype)
#float 64> int 32
array_float1 = np.array([1.1, 2.1, 3.1])
array_int2 = array_float1.astype('int32') #int32 타입으로 변환
print(array_int2, array_int2.dtype)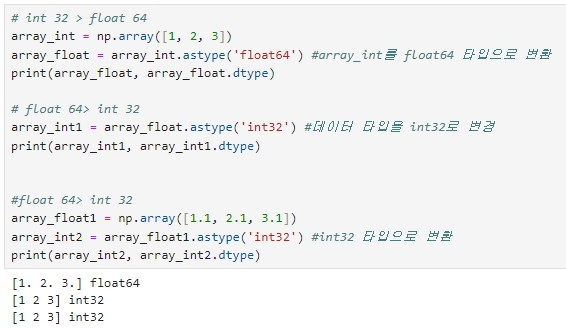
ndarray를 편리하게 생성하기 (feat. arange, zeros, ones)
특정 크기와 차원을 가진 ndarray를 연속값이나 0또는 1로 초기화해 쉽게 생성해야 할 필요가 있는 경우,
arange( ), zeros( ), ones( ) 를 이용해 쉽게 ndarray를 생성할 수 있다. 주로 테스트용으로 데이터를 만들거나 대규모의 데이터를 일괄적으로 초기화해야 할 경우에 사용된다.
◆ arange( ): 파이썬 표준 함수인 range( )와 유사한 기능. array를 range( )로 표현하는 것. 0부터 함수 인자 값 -1까지의 값을 순차적으로 ndarray의 데이터값으로 변환.
sequence_array = np.arange(10) #0부터 9까지의 연속적인 정수로 이루어진 배열을 생성
print(sequence_array)
print(sequence_array.dtype, sequence_array.shape)
▶ 출력 결과는 int32 (10,). 여기서 int32는 데이터 타입이 32비트 정수임을 의미하고, (10,)은 배열이 10개의 요소를 가진 1차원 배열임을 의미
◆ zeros( ): 함수 인자로 튜플 형태의 shape 값을 입력하면 모든 값을 0으로 채운 해당 shape를 가진 ndarray를 반환.
◆ ones( ): 함수 인자로 튜플 형태의shape 값을 입력하면 모든 값을 1로 채운 해당 shape를 가진 ndarray를 반환.
※ 함수 인자로 dype을 정해주지 않으면 default 로 float64 형의 데이터로 ndarray를 채움.
# 0으로 채워진 배열 생성
zero_array = np.zeros((3, 2), dtype='int32') #3x2 형태의 배열을 생성하며, 이 배열은 모두 0으로 채워짐
print(zero_array)
print(zero_array.dtype, zero_array.shape) #0으로 채워진 배열의 내용, 데이터 타입, 형태 출력
# 1로 채워진 배열 생성
one_array = np.ones((3, 2)) #3x2 형태의 배열을 생성하며, 이 배열은 모두 1로 채워짐
print(one_array)
print(one_array.dtype, one_array.shape) #1로 채워진 배열의 내용, 데이터 타입, 형태 출력
reshape( ): ndarray의 차원과 크기를 변경
reshape( ) 메서드는 ndarray를 특정 차원 및 크기로 변환한다. 변환을 원하는 크기를 함수 인자로 부여하면 된다.
[0~9까지의 1차원 ndarray를 2rows * 3columns 과, 5rows * 2columns 형태로 2차원 ndarray로 변환]
# 1차원 배열 생성
array1 = np.arange(10)
print('array1:\n', array1)
# 2차원 배열로 재구성 (2x5)
array2 = array1.reshape(2, 5)
print('array2:\n', array2) #2행 5열의 배열로 변환된 결과를 확인
#2차원 배열로 재구성 (5x2)
array3 = array1.reshape(5, 2)
print('array3:\n', array3) #5행 2열의 배열로 변환된 결과를 확인
※ reshape( )는 지정된 사이즈로 변경이 불가능하면 오류를 발생하는데, (10,) 데이터를 (4,3) Shape 형태로 변경할 수는 없다.
◆ reshape( )를 실전에서 더욱 효율적으로 사용하는 경우 1
인자로 -1을 적용하는 경우, -1을 인자로 사용하면 원래 ndarray와 호환되는 새로운 shape로 변환해 준다.
즉, reshape 함수의 -1 인수는 매우 유용한 기능으로, 다른 차원의 크기를 알고 있을 때, 남은 차원의 크기를 자동으로 계산한다.
[reshape( )에 -1값을 인자로 적용한 경우 어떻게 ndarray의 size를 변경하는지 확인]
# 1차원 배열 생성
array1 = np.arange(10)
print(array1)
#함수의 첫 번째 인수로 -1을 사용하면, 자동으로 적절한 차원 크기를 계산
array2 = array1.reshape(-1,5) #두 번째 인수 5는 새로운 배열의 두 번째 차원의 크기를 나타냄
print('array2 shape:', array2.shape)
#함수의 두 번째 인수도 -1을 사용하면, 자동으로 적절한 차원 크기를 계산
array3 = array1.reshape(5,-1) #첫 번째 인수 5는 새로운 배열의 첫 번째 차원의 크기를 나타냄
print('array3 shape:', array3.shape)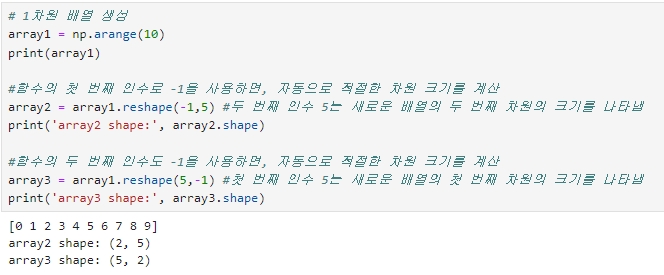
※ 물론 -1을 사용하더라도 호환될 수 없는 형태는 변환할 수 없다. 이를테면, 10개의 1차원 데이터를 고정된 4개의 칼럼을 가진 로우로는 변경될 수 없기에 reshape(-1, 4)는 에러 발생.
◆ reshape( )를 실전에서 더욱 효율적으로 사용하는 경우 2
-1 인자는 reshape(-1,1)와 같은 형태로 자주 사용된다. reshape(-1,1)은 원본 ndarray가 어떤 형태라도 2차원이고, 여러 개의 로우를 가지되 반드시 1개의 칼럼을 가진 ndarray로 변환됨을 보장한다.
여러 개의 넘파이 ndarray는 stack이나 concat으로 결합할 때 각각의 ndarray의 형태를 통해 유용하게 사용된다.
[reshape(-1,1)을 이용해 3차원 > 2차원, 1차원>2차원으로 변경]
※ ndarray는 tolist( ) 메서드를 이용해 리스트 자료형으로 변환할 수 있다.
array1 = np.arange(8)
array3d = array1.reshape((2, 2, 2))
print('array3d:\n', array3d.tolist()) #tolist()는 리스트 자료형으로 변환
# 3차원 > 2차원
array5 = array3d.reshape(-1,1)
print('array5:\n', array5.tolist())
print('array5 shape:', array5.shape)
# 1차원 > 2차원
array6 = array1.reshape(-1,1)
print('array6:\n', array6.tolist())
print('array6 shape:', array6.shape)
다음글
'[파이썬 Projects] > <파이썬 기초>' 카테고리의 다른 글
| [파이썬] 넘파이(NumPy) - 3 (0) | 2024.05.25 |
|---|---|
| [파이썬] 넘파이(NumPy) - 2 (0) | 2024.05.25 |
| [파이썬] Selenium 라이브러리 사용하기 (1) | 2024.04.18 |
| [파이썬] 크롬 개발자 도구를 이용해서 원하는 태그 찾기 (0) | 2024.04.16 |
| [파이썬] Beautiful Soup 익히기 (1) | 2024.04.16 |



