시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적을 참고해 주시기 바랍니다.
네이버 도서
책으로 만나는 새로운 세상
search.shopping.naver.com
기존 내용
[파이썬] 넘파이(NumPy) - 1
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적을 참고해 주시기 바랍니다.넘파이 (NumPy) 머신러닝의 주요 알고리즘은 선형대수와
puppy-foot-it.tistory.com
인덱싱(Indexing): 넘파이의 ndarray의 데이터 세트 선택하기
인덱싱: 넘파이에서 ndarray 내의 일부 데이터 세트나 특정 데이터만을 선택할 수 있도록 한다.
- 특정한 데이터만 추출: 원하는 위치의 인덱스 값을 지정하면 해당 위치의 데이터가 반환
- 슬라이싱(Slicing): 슬라이싱은 연속된 인덱스상의 ndarray를 추출하는 방식. ':' 기호 사이에 시작 인덱스와 종료 인덱스를 표시하면 시작 인덱스에서 종료 인덱스-1 위치에 있는 데이터의 ndarray를 반환. (예. 1:5 > 시작 인덱스 1과 종료 인덱스 4까지에 해당하는 ndarray 반환
- 팬시 인덱싱(Fancy Indexing): 일정한 인덱싱 집합을 리스트 또는 ndarray 형태로 지정해 해당 위치에 있는 데이터의 ndarray 반환
- 불린 인덱싱(Boolean Indexing): 특정 조건에 해당하는지 여부인 True/False 값 인덱싱 집합을 기반으로 True에 해당하는 인덱스 위치에 있는 데이터의 ndarray 반환
단일 값 추출
1개의 데이터값을 선택하려면 ndarray 객체에 해당하는 위치의 인덱스 값을 [ ] 안에 입력하면 된다.
# 1부터 9까지의 1차원 ndarray 생성
array1 = np.arange(start=1, stop=10)
print('array1:', array1)
#index는 0부터 시작하므로 array1[2]는 3번째 index 위치의 데이터값 의미
value = array1[2]
print('value:', value)
print(type(value))
인덱스는 0부터 시작하므로 array1[2]는 3번째 인덱스 위치의 데이터값을 의미.
인덱스에 마이너스 기호를 이용하면 맨 뒤에서부터 데이터를 추출할 수 있다.
인덱스 -1은 맨 뒤의 데이터값을 의미하고, -2는 맨 뒤에서 두 번째에 있는 데이터값이다.
단일 인덱스를 이용해 ndarray 내의 데이터값도 간단히 수정 가능하다.
array1[0] = 9
array1[8] = 0
print('array1:', array1)
다차원 ndarray에서 단일 값 추출
1차원과 2차원 ndarray에서 데이터 접근의 차이는 2차원의 경우 콤마(,) 로 분리된 로우와 칼럼 위치의 인덱스를 통해 접근하는 것이다.
※ 3차원 이상의 ndarray 에서의 데이터 추출도 2차원 ndarray와 큰 차이가 없다.
[1차원 ndarray를 2차원의 3x3 ndarray로 변환한 후 [row, col]을 이용해 2차원 ndarray에서 데이터 추출]
array1d = np.arange(start=1, stop=10) #1부터 9까지 숫자 범위 생성
array2d = array1d.reshape(3,3) # 로우3, 컬럼3 형태
print(array2d)
# 값 찾아내기
print('(row=0, col=0) index 가리키는 값:', array2d[0, 0])
print('(row=0, col=1) index 가리키는 값:', array2d[0, 1])
print('(row=1, col=0) index 가리키는 값:', array2d[1, 0])
print('(row=2, col=2) index 가리키는 값:', array2d[2, 2])※ axis 0 은 로우 방향의 축, axis 1은 칼럼 방향의 축을 의미
상단 코드에서 지칭한 로우와 칼럼은 넘파이 ndarray에서 사용되지 않는 방식이며, 정확한 표현은 axis 0, axis 1이 맞다.
즉, [row=0, col=0] 인덱싱은 [axis 0=0, axis 1=0] 이 정확한 표현이다.
3차원 ndarray의 경우는 axis 0, aixs 1, aixs 2로 3개의 축을 가지게 된다. (행, 열, 높이)
축 기반의 연산에서 axis 가 생략되면 axis 0을 수행한다.
슬라이싱
':' 기호를 이용하여 연속한 데이터를 슬라이싱해서 추출할 수 있다. 단일 데이터값 추출을 제외하고 슬라이싱, 팬시 인덱싱, 불린 인덱싱으로 추출된 데이터 세트는 모두 ndarray 타입이다.
시작 인덱스:종료 인덱스
시작 인덱스에서 종료 인덱스 -1의 위치에 있는 데이터의 ndarray 값 반환
array1 = np.arange(start=1, stop=10)
array3 = array1[0:3]
print(array3)
print(type(array3))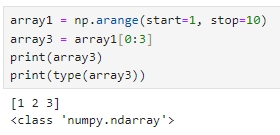
※ 슬라이싱 기호인 ':' 사이의 시작, 종료 인덱스는 생략 가능
- ':' 기호 앞에 시작 인덱스를 생략하면 자동으로 맨 처음 인덱스인 0으로 간주
- ':' 기호 뒤에 종료 인덱스를 생략하면 자동으로 맨 마지막 인덱스로 간주
- ':' 기호 앞/뒤에 시작/종료 인덱스를 생략하면 자동으로 맨 처음/맨 마지막 인덱스로 간주
array1 = np.arange(start=1, stop=10)
array4 = array1[:3] #시작 인덱스 생략
print(array4)
array5 = array1[3:] #종료 인덱스 생략
print(array5)
array6 = array1[:] #시작, 종료 인덱스 생략
print(array6)
◆ 2차원 ndarray에서 슬라이싱으로 데이터에 접근하기
2차원 ndarray에서 슬라이싱도 1차원 ndarray에서의 슬라이싱과 유사하며, 단지 콤마(,)로 로우와 칼럼 인덱스를 지칭하는 부분만 다르다.
#2차원 ndarray 슬라이싱
array1d = np.arange(start=1, stop=10) #1차원 수 생성
array2d = array1d.reshape(3, 3) #2차원으로 형태 생성
print('array2d:\n', array2d)
print('array2d[0:2, 0:2] \n', array2d[0:2, 0:2])
print('array2d[1:3, 0:3] \n', array2d[1:3, 0:3])
print('array2d[1:3, :] \n', array2d[1:3, :])
print('array2d[:, :] \n', array2d[:, :])
print('array2d[:2, 1:] \n', array2d[:2, 1:])
print('array2d[:2, 0] \n', array2d[:2, 0])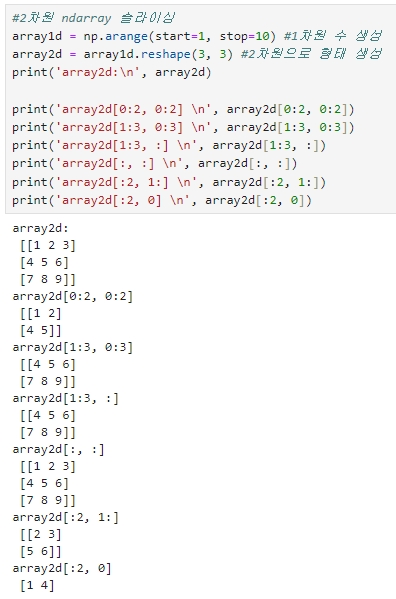
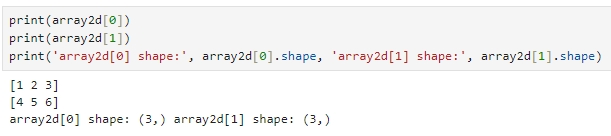
※ 2차원 ndarray에서 뒤에 오는 인덱스를 없애면 1차원 ndarray 반환.
즉, array2d[0] 과 같이 2차원에서 뒤에 오는 인덱스를 없애면 로우 축(axis 0)의 첫 번째 로우 ndarray를 반환
(반환되는 array는 1차원)
3차원 ndarray에서 뒤에 오는 인덱스를 없애면 2차원 ndarray를 반환
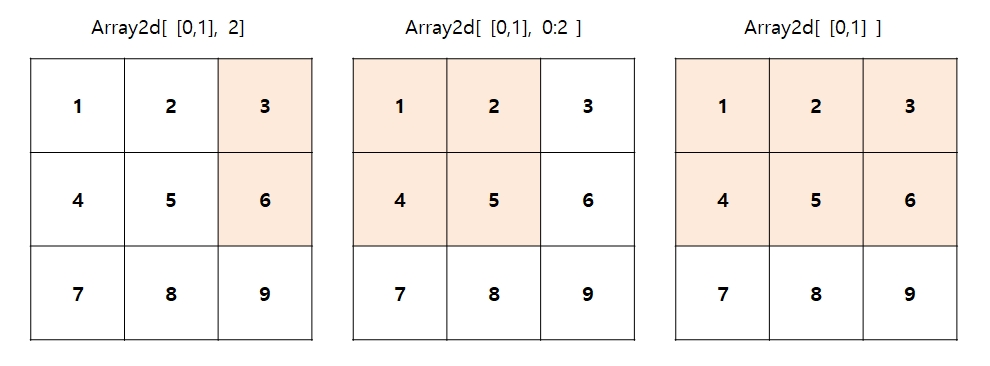
팬시 인덱싱(Fancy Indexing)
팬시 인덱싱은 리스트나 ndarray로 인덱스 집합을 지정하면 해당 위치의 인덱스에 해당하는 ndarray를 반환하는 인덱스 방식이다.
array1d = np.arange(start=1, stop=10)
array2d = array1d.reshape(3, 3)
array3 = array2d[[0, 1], 2] #로우 측에 팬시 인덱싱 적용, 칼럼 축은 단일 값 적용
print('array2d[[0, 1], 2] =>', array3.tolist())
# (row, col)인덱스가 (0,2),(1,2)로 적용
array4 = array2d[[0, 1], 0:2]
print('array2d[[0, 1], 0:2] =>', array4.tolist())
# ((0,0),(0,1)), ((1,0),(1,1)) 인덱싱 적용
array5 = array2d[[0, 1]]
print('array2d[[0, 1]] =>', array5.tolist())
# ((0, : ), (1, : )) 인덱싱 적용
불린 인덱싱(Boolean Indexing)
불린 인덱싱은 조건 필터링과 검색을 동시에 할 수 없기 때문에 매우 자주 사용되는 인덱싱 방식이다.
1차원 ndarray [1,2,3,4,5,6,7,8,9]에서 데이터값이 5보다 큰 데이터만 추출하려고 할 경우,
불린 인덱싱은 이용하면 for loop/if else (if '추출값' > 5) 를 돌면서 값을 하나씩 비교할 필요 없이 훨씬 간단하게 이를 구현할 수 있다.
불린 인덱싱은 ndarray의 인덱스를 지정하는 [ ] 내에 조건문을 그대로 기재하기만 하면 된다.
array1d = np.arange(start=1, stop=10)
# [ ] 안에 array1d > 5 Boolean Indexing 적용
array3 = array1d[array1d > 5]
print('array1d >5 불린 인덱싱 결과 값:', array3)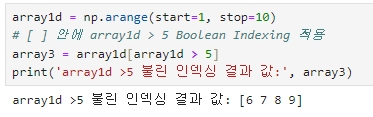

단지 ndarray 객체에 조건식만 붙였을 뿐인데 False, True로 이뤄진 ndarray 객체가 반환되었다.
반환된 객체를 살펴보면 5보다 큰 데이터가 있는 위치는 True 값이, 그렇지 않은 경우는 False 값이 반환됨을 확인할 수 있다.
조건으로 반환된 ndarray 객체를 인덱싱을 지정하는 [ ] 내에 입력하면 False 값은 무시하고 True 값이 있는 위치 인덱스 값으로 자동 변환해 해당하는 인덱스 위치의 데이터만 반환하게 된다.
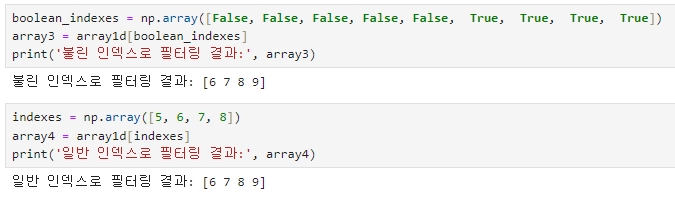
불린 인덱싱은 내부적으로 여러 단계를 거쳐서 동작하지만, 코드 자체는 단순히 [ ] 내에 원하는 필터링 조건만 넣으면 해당 조건을 만족하는 ndarray 데이터 세트를 반환하기 때문에 사용자는 내부 로직에 크게 신경쓰지 않고 쉽게 코딩할 수 있다.
다음글
'[파이썬 Projects] > <파이썬 기초>' 카테고리의 다른 글
| [파이썬] 판다스 (Pandas) - 1 (0) | 2024.05.25 |
|---|---|
| [파이썬] 넘파이(NumPy) - 3 (0) | 2024.05.25 |
| [파이썬] 넘파이(NumPy) - 1 (0) | 2024.05.25 |
| [파이썬] Selenium 라이브러리 사용하기 (1) | 2024.04.18 |
| [파이썬] 크롬 개발자 도구를 이용해서 원하는 태그 찾기 (0) | 2024.04.16 |



