시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
네이버 도서
책으로 만나는 새로운 세상
search.shopping.naver.com
사이킷런(sickit-learn) 이란?
사이킷런은 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리이다.
그러나 최근에는 텐서플로, 케라스 등 딥러닝 전문 라이브러리의 강세로 인해 대중적인 관심이 줄어들고 있으나 여전히 대표적인 파이썬 머신러닝 라이브러리이다.
Anaconda를 설치하면 기본으로 사이킷런까지 설치가 완료된다.
[사이킷런 특징]
- 쉽고 가장 파이썬스러운 API 제공(파이썬 기반의 다른 머신러닝 패키지도 사이킷런 스타일의 API 지향)
- 머신러닝을 위한 매우 다양한 알고리즘과 개발을 위한 편리한 프레임워크와 API 제공
- 오랜 기간 실전 환경에서 검증됐으며, 매우 많은 환경에서 사용되는 성숙한 라이브러리
사이킷런은 매우 많은 머신러닝 알고리즘을 제공할 뿐만 아니라, 쉽고 직관적인 API 프레임워크, 편리하고 다양한 모듈 지원 등으로 파이썬 계열의 대표적인 머신러닝 패키지로 자리 잡았다.
머신러닝 애플리케이션은 데이터의 가공 및 변환 과정의 전처리 작업, 데이터를 학습 데이터와 테스트 데이터로 분리하는 데이터 세트 분리 작업을 거친 후에 학습 데이터를 기반으로 머신러닝 알고리즘을 적용해 모델을 학습시킨다.
그리고 학습된 모델을 기반으로 테스트 데이터에 대한 예측을 수행하고, 이렇게 예측된 결괏값을 실제 결괏값과 비교해 머신러닝 모델에 대한 평가를 수행하는 방식으로 구성된다.
데이터의 전처리 작업은 다양한 데이터 클렌징 작업(오류 데이터의 보정이나 결손값 처리 등), 인코딩 작업(레이블 인코딩, 원-핫 인코딩 등), 데이터의 스케일링/정규화 작업 등으로 머신러닝 알고리즘이 최적으로 수행될 수 있게 데이터를 사전 처리하는 것이다.
머신러닝 모델은 학습 데이터 세트로 학습한 뒤 반드시 별도의 테스트 데이터 세트로 평가되어야 한다.
반복적인 모델의 학습 평가는 해당 테스트 데이터 세트에만 치우친 빈약한 머신러닝 모델을 만들 가능성이 있으므로 학습 데이터 세트를 학습 데이터와 검증 데이터로 구성된 여러 개의 폴드 세트로 분리해 교차 검증을 수행할 수 있다.
(KFold, StratifiedKFold, cross_val_score 등의 다양한 클래스와 함수 제공)
(또한, 최적의 하이퍼 파라미터를 교차 검증을 통해 추출하기 위해 GridSearchCV 제공)
사이킷런은 다양한 개발 환경에서 오랜 기간동안 라이브러리의 안정성과 유용성이 검증된 패키지이다.
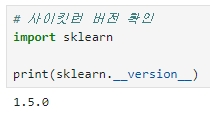
사이킷런 최신 버전 설치 및 버전 확인
Anaconda Prompt에서 'pip install -U scikit-learn' 명령어를 통해 사이킷런 최신버전 설치
붓꽃 품종 예측하기(feat. 지도학습)
붓꽃 데이터 세트는 꽃잎의 길이와 너비, 꽃받침의 길이와 너비 피처(Feature)를 기반으로 꽃의 품종을 예측하기 위한 것이다.
분류(Classification)는 대표적인 지도학습(Supervised Learning) 방법의 하나인데, 지도학습은 명확한 정답이 주어진 데이터를 먼저 학습한 뒤 미지의 정답을 예측하는 방식이다.
이때 학습을 위해 주어진 데이터 세트를 학습 데이터 세트, 머신러닝 모델의 예측 성능을 평가하기 위해 별도로 주어진 데이터 세트를 테스트 데이터 세트로 지칭한다.
◆ 사이킷런 모듈 임포트
# sklearn.datasets: 사이킷런에서 자체 제공하는 데이터 세트 생성 모듈
from sklearn.datasets import load_iris
# sklearn.tree: 트리 기반 ML 알고리즘을 구현한 클래스의 모임
from sklearn.tree import DecisionTreeClassifier
# sklearn.model_selection: 데이터 분리(학습, 검증, 평가) 또는 최적의 하이퍼 파라미터로 평가하기 위한 모듈 모임
from sklearn.model_selection import train_test_split<코드 설명>
|
붓꽃 데이터 세트 DataFrame 생성
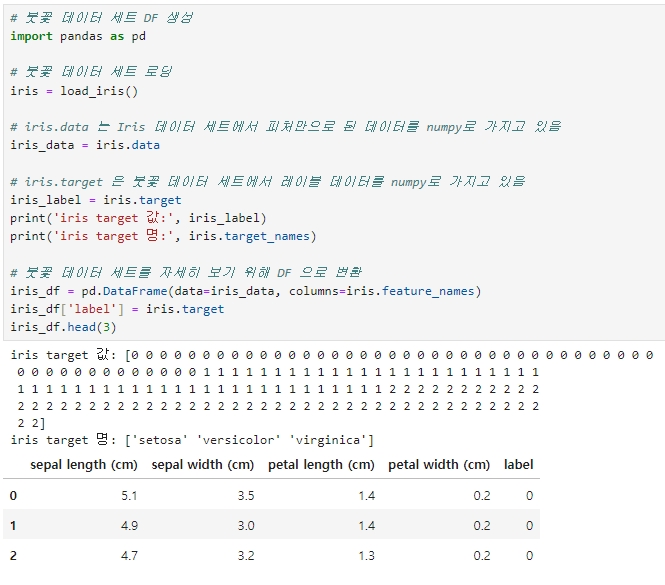
▶ 피처: sepal length, sepal width, petal length, petal width
▶ 레이블: 0, 1, 2 (0 - Setosa 품종, 1 - versicolor 품종, 2 - virginica 품종 의미)
학습용 데이터와 테스트용 데이터 분리
학습 데이터로 학습된 모델이 얼마나 뛰어난 성능을 가지는지 평가하려면 테스트 데이터 세트가 필요하기 때문에 학습용 데이터와 테스트용 데이터는 반드시 분리해야 한다.
train_test_split( ) 을 이용하면 학습 데이터와 테스트 데이터를 test_size 파라미터 입력값의 비율로 쉽게 분할한다.
(예. test_size = 0.2 ▶ 전체 데이터 중 테스트 데이터 20%, 학습 데이터 80%로 데이터 분할)

<코드 설명>
|
|
학습과 예측 수행 (feat. 의사 결정 트리)
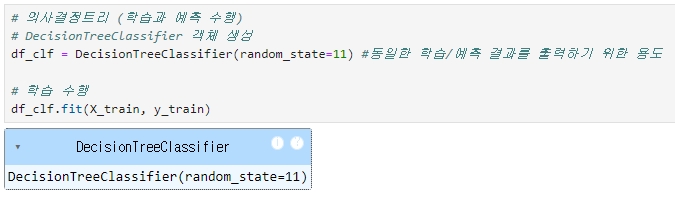
◆ 학습 수행
먼저 의사 결정 트리 클래스 (DecisionTreeClassifier) 를 객체로 생성하고,
생성된 DecisionTreeClassifier rorcpdml fit( ) 메서드에 학습용 피처 데이터 속성과 결정 값 데이터 세트를 입력해 호출하면 학습 수행
◆ 예측 수행
의사 결정 트리 기반의 DecisionTreeClassifier 객체는 학습 데이터를 기반으로 학습이 완료되었다. 이렇게 학습된 객체를 이용해 예측을 수행하는데, 예측은 반드시 학습 데이터가 아닌 다른 데이터를 이용해야 하며, 일반적으로 테스트 데이터 세트를 이용한다.
DecisionTreeClassifier 객체의 predict( ) 메서드에 테스트용 피처 데이터 세트를 입력해 호출하면 학습된 모델 기반에서 테스트 데이터 세트에 대한 예측값을 반환하게 된다.

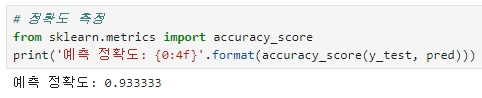
◆ 정확도 측정
예측 결과를 기반으로 의사 결정 트리 기반의 DecisionTreeClassifier의 예측 성능 평가 (정확도 평가)
※ 정확도는 예측 결과가 실제 레이블 값과 얼마나 정확하게 맞는지를 평가하는 지표
예측한 붓꽃 품종과 실제 테스트 데이터 세트의 붓꽃 품종이 얼마나 일치하는지 확인 (accuracy_score( ) 함수)
※ accuracy_score(실제 레이블 데이터 세트, 예측 레이블 데이터 세트)
예측 프로세스 정리
앞의 붓꽃 데이터 세트로 분류를 예측한 프로세스를 정리하면 다음과 같다
- 데이터 세트 분리: 데이터를 학습 데이터와 테스트 데이터로 분리
- 모델 학습: 학습 데이터를 기반으로 ML 알고리즘을 적용해 모델을 학습 시킴
- 예측 수행: 학습된 ML 모델을 이용해 테스트 데이터의 분류(붓꽃 종류)를 예측
- 평가: 예측된 결과값과 테스트 데이터의 실제 결과값을 비교해 ML 모델 성능 평가
정리
- 사이킷런은 매우 많은 머신러닝 알고리즘을 제공할 뿐만 아니라, 쉽고 직관적인 API 프레임워크, 편리하고 다양한 모듈 지원 등으로 파이썬 계열의 대표적인 머신러닝 패키지로 자리 잡았다.
- 머신러닝 애플리케이션은 데이터의 가공 및 변환 과정의 전처리 작업, 데이터를 학습 데이터와 테스트 데이터로 분리하는 데이터 세트 분리 작업을 거친 후에 학습 데이터를 기반으로 머신러닝 알고리즘을 적용해 모델을 학습시킨다. 그리고 학습된 모델을 기반으로 테스트 데이터에 대한 예측을 수행하고, 이렇게 예측된 결괏값을 실제 결괏값과 비교해 머신러닝 모델에 대한 평가를 수행하는 방식으로 구성된다
- 데이터의 전처리 작업은 오류 데이터의 보정이나 결손값(Null) 처리 등의 다양한 데이터 클렌징 작업, 레이블 인코딩이나 원-핫 인코딩과 같은 인코딩 작업, 데이터의 스케일링/정규화 작업 등으로 머신러닝 알고리즘이 최적으로 수행될 수 있게 데이터를 사전 처리 하는 것이다.
- 머신러닝 모델은 학습 데이터 세트로 학습한 뒤 반드시 별도의 테스트 데이터 세트로 평가되어야 한다.
- 테스트 데이터의 건수 부족이나 고정된 테스트 데이터 세트를 이용한 반복적인 모델의 학습과 평가는 해당 테스트 데이터 세트에만 치우친 빈약한 머신러닝 모델을 만들 가능성이 높다
- 학습 데이터 세트를 학습 데이터와 검증 데이터로 구성된 여러 개의 폴드 세트로 분리해 교차 검증을 수행하여 위의 문제를 해결할 수 있으며, 사이킷런은 이러한 교차 검증을 지원하기 위해 KFold, StratifiedKFold, cross_val_score() 등의 다양한 클래스와 함수를 제공한다.
- 머신러닝 모델의 최적의 하이퍼 파라미터를 교차 검증을 통해 추출하기 위해 GridSearchCV 를 제공한다
[관련 상세 글 및 프로젝트]
[파이썬] 사이킷런의 model_selection 모듈
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 사이킷런의 model_selection 모듈 (0) | 2024.06.07 |
|---|---|
| [머신러닝] 사이킷런에 내장된 예제 데이터 세트 (0) | 2024.05.30 |
| [머신러닝] 사이킷런 주요 모듈 (0) | 2024.05.30 |
| [머신러닝] 주요 패키지 (0) | 2024.05.25 |
| [머신러닝] 머신러닝과 생태계 이해 (0) | 2024.05.17 |



