시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
사이킷런으로 수행하는 타이타닉 생존자 예측
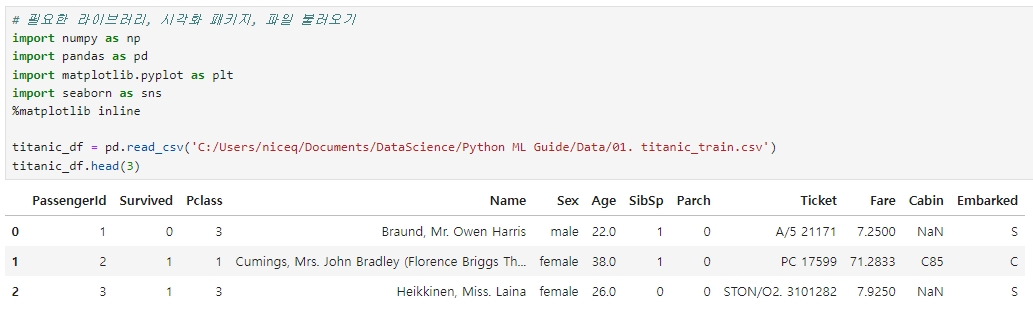
1. 분석에 필요한 라이브러리, 시각화 패키지, 파일 불러오기
또는, csv 파일 다운로드 없이 seaborn을 통해 데이터를 불러올 수도 있다. (단, 실습용 csv 데이터와 컬럼 수 등의 차이가 있다.)
df_titanic = sns.load_dataset('titanic')
df_titanic.info()
2. 데이터 칼럼 타입 확인하기
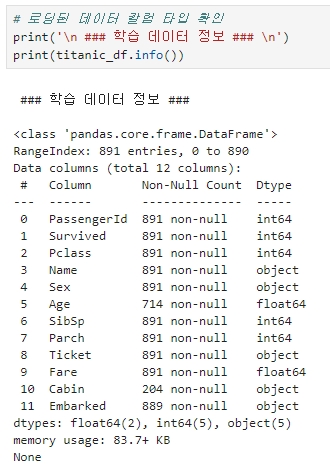
- Range Index: DataFrame 인덱스의 범위 (전체 로우 수)
- Data Columns: 전체 칼럼 수
- dtypes: 데이터 타입
- 판다스의 object 타입 = string 타입
- 판다스는 넘파이 기반으로 만들어졌고 넘파이의 String 타입이 길이 제한이 있어서 이에 대한 구분을 위해 object 타입으로 명기
- 전체 891개 데이터 중 Null 값이 있는 칼럼은 'Age', 'Cabin', 'Embarked'
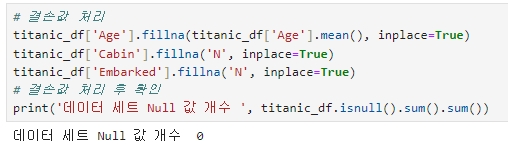
3. 결손값 처리
사이킷런 머신러닝 알고리즘은 Null 값을 허용하지 않으므로 Null 값을 어떻게 처리할지 결정해야 한다.
DataFrame 의 fillna( ) 함수를 사용: Null 값을 평균 또는 고정 값으로 변경
(Age의 경우는 평균 나이, 나머지 칼럼은 'N' 값)
4. 남아 있는 문자열 피처들의 값 분류 파악
현재 남아 있는 문자열 피처는 Sex, Cabin, Embarked 인데, 먼저 이 피처들의 값 분류를 살펴본다.
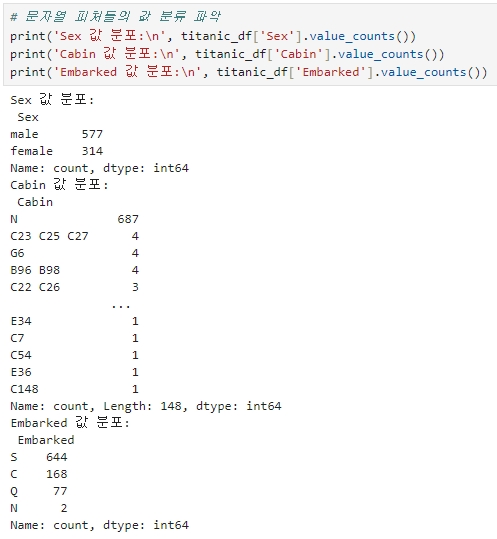
Sex, Embarked 값은 별문제가 없으나,
Cabin의 경우 N이 687건으로 가장 많고, 속성값도 제대로 정리가 되지 않은 듯 하다.
4-1. Cabin 속성의 앞 문자만 추출
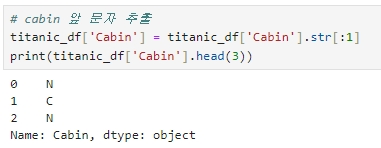
타이타닉 생존자 데이터 탐색하기
[어떤 유형의 승객이 생존 확률이 높았는지 확인하기]
1. 성별
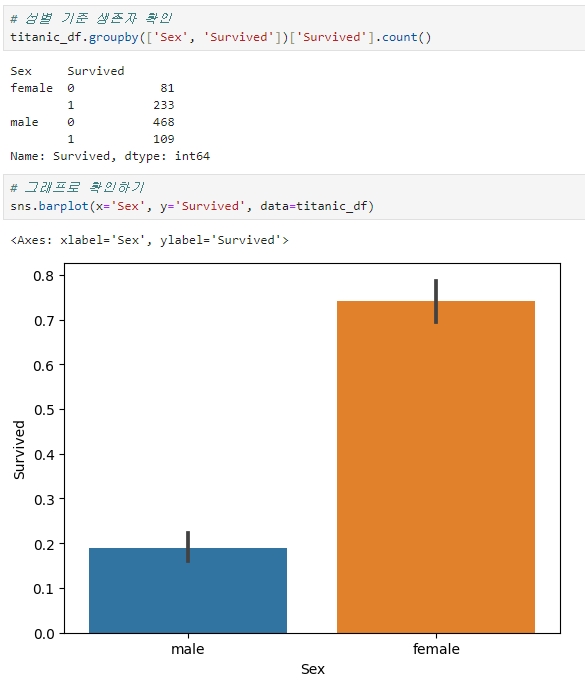
2. 성별 + 부자와 가난한 사람
성별과 객실 등급(Cabin)에 따라 생존 확률 확인하기
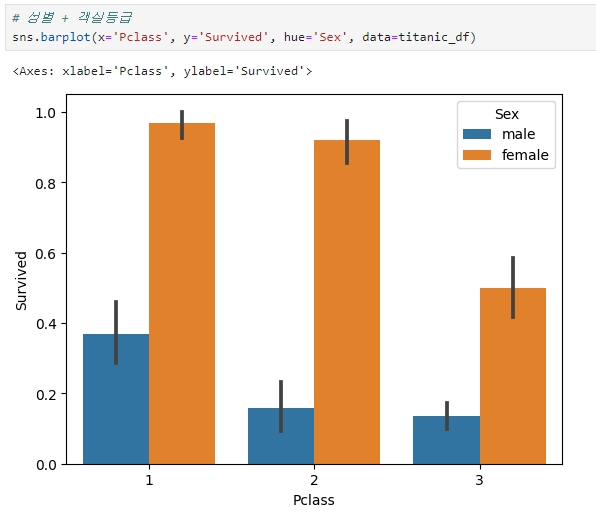
3. 성별 + 연령
Age의 경우 값 종류가 많기 때문에 범위별로 분류해 카테고리 값을 할당
- 0~5세: Baby
- 6~12세: Child
- 13~18세: Teenager
- 19~25세: Student
- 26~35세: Young Adult
- 36~60세: Adult
- 61세~: Elderly
- -1 이하의 오류 값: Unknown

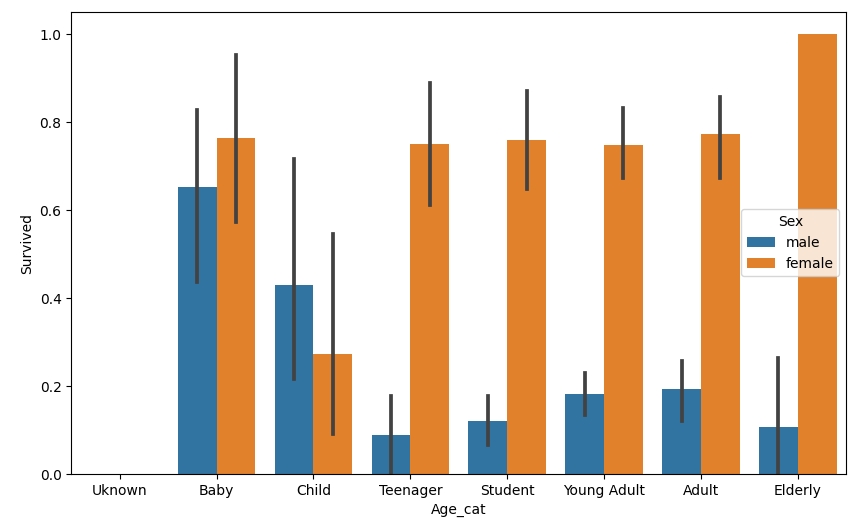
▶ 분석 결과 Sex, Age, PClass 등이 중요하게 생존을 좌우하는 피처임을 확인할 수 있다.
데이터 전처리: 남아있는 문자열 카테고리 피처를 숫자형으로 변환
인코딩은 사이킷런의 LabelEncoder 클래스를 이용해 레이블 인코딩 적용
(LabelEncoder 객체는 카테고리 값의 유형 수에 따라 0~ (카테고리 유형 수 -1) 까지의 숫자 값으로 변환)
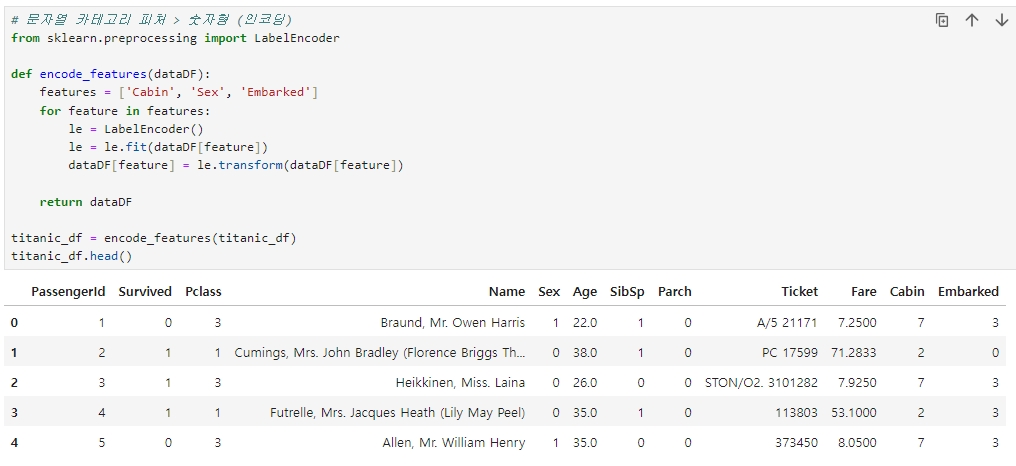
피처를 가공한 내역을 정리하고 함수로 만들기
지금까지 피처를 가공한 내역을 정리하고 이를 함수로 만들어 쉽게 재사용할 수 있도록 만든다.
- transform_features( ): 데이터의 전처리를 전체적으로 호출하는 함수
- Null 처리
- 인코딩 수행
- drop_features(): 불필요한 피처 제거 (단순한 식별자 수준의 피처: PassengerID, Name, Ticket)

Survived 속성 처리 + 테스트 데이터 세트 추출
1. Survived 속성만 별도 분리해 클래스 결정값 데이터 세트로 만들고 Survived 속성을 드롭해 피처 데이터 세트 만들기.
그리고 이렇게 생성된 피처 데이터 세트에 transform_features( )를 적용해 데이터 가공

2. 내려받은 학습 데이터 세트를 기반으로 train_test_split( ) API를 이용해 별도의 테스트 데이터 세트 추출(전체의 20%)

ML 알고리즘 사용하여 타이타닉 생존자 예측
ML 알고리즘인 의사 결정 나무, 랜덤 포레스트, 로지스틱 회귀를 이용해 타이타닉 생존자 예측
※ 로지스틱 회귀는 분류 알고리즘이다.
[각 클래스]
- 의사 결정 나무: DecisionTreeClassifier
- 랜덤 포레스트: RandomForestClassifier
- 로지스틱 회귀: LogisticRegression
▶ 각 클래스를 이용해 train_test_split( ) 으로 분리한 학습 데이터와 테스트 데이터를 기반으로 머신러닝 모델을 학습하고(fit), 예측(predict)
▶ 예측 성능 평가는 정확도로 진행: accuracy_score() API 사용
▶ DecisionTreeClassifier, RandomForestClassifier 에 사용된 random_state=11 은 크게 중요치 않음.
▶ LogisticRegression의 생성 인자로 입력된 solver='liblinear' : 로지스틱 회귀와 최적화 알고리즘을 liblinear로 설정

※ 아직 최적화 작업을 수행하지 않았고, 데이터양도 충분하지 않기 때문에 어떤 알고리즘이 가장 성능이 좋다고 평가할 수 없다.
교차 검증을 통한 의사 결정 나무 평가
model_selection 패키지의 KFold 클래스, cross_val_score( ), GridSearchCV 클래스를 모두 사용하여 교차 검증 수행
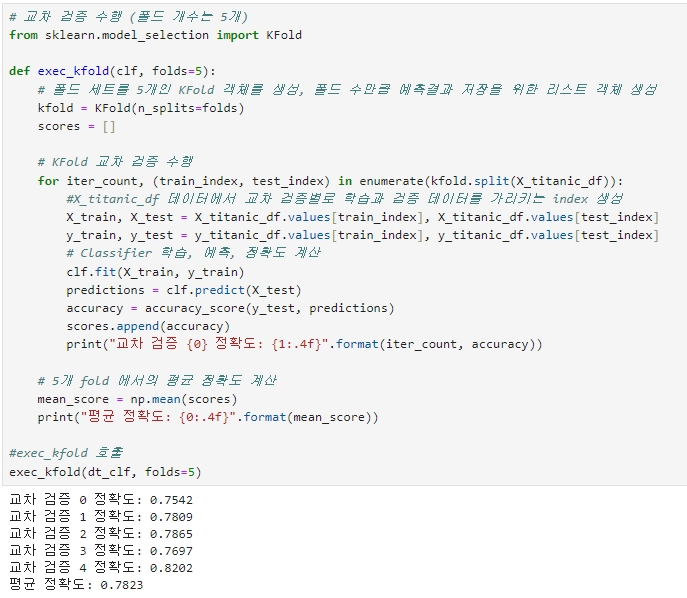
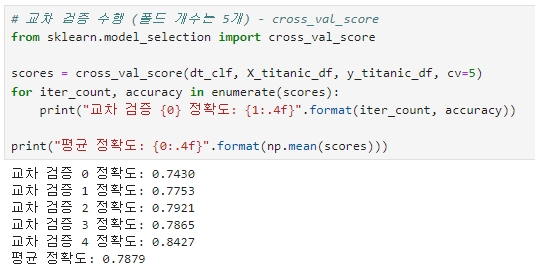
※ KFold 와 cross_val_score 의 평균 정확도가 약간 다른데, 이는 cross_val_score( ) 가 StratifiedKFold를 이용해 폴드 세트를 분할하기 때문이다.
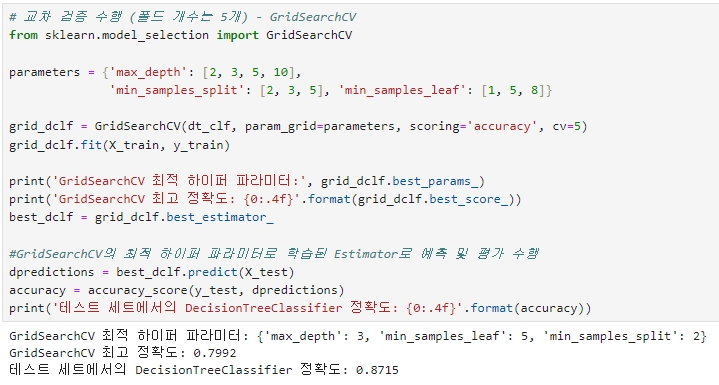
▶ 최적화된 하이퍼 파라미터인 max_depth=3, min_samples_leaf=5, min_samples_split=2로 DecisionTreeClassifier를 학습시킨 뒤 예측 정확도가 87.15%로 향상되었다.
※ 하이퍼 파라미터 변경 전보다 약 8% 이상이 증가했는데, 이는 테스트용 데이터가 작기 때문에 수치상으로 예측 성능이 많이 증가한 것으로 보이며 일반적으로 이정도 수준으로 증가하기는 어렵다.
다음 내용
[머신러닝] 성능 평가 지표 - 1 (정확도, 정밀도, 재현율, 오차 행렬)
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 평가 머신러닝은 데이터 가
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 성능 평가 지표 - 2 (정밀도, 재현율) (0) | 2024.06.10 |
|---|---|
| [머신러닝] 성능 평가 지표 - 1 (정확도, 정밀도, 재현율, 오차 행렬) (1) | 2024.06.09 |
| [머신러닝] 데이터 전처리 (1) | 2024.06.09 |
| [머신러닝] 사이킷런의 model_selection 모듈 (0) | 2024.06.07 |
| [머신러닝] 사이킷런에 내장된 예제 데이터 세트 (0) | 2024.05.30 |



