시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
이전 내용
[파이썬] 성능 평가 지표 - 1
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 평가 머신러닝은 데이터 가
puppy-foot-it.tistory.com
정밀도/재현율 트레이드오프
'정밀도/재현율의 트레이드오프(Trade-off)'
정밀도와 재현율은 상호 보완적인 평가 지표이기 때문에 어느 한 쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉽다.
◆ predict_proba( ) 메서드: 개별 데이터별로 예측 확률을 반환하는 메서드. 학습이 완료된 사이킷런 Classifier 객체에서 호출이 가능하며 테스트 피처 데이터 세트를 파라미터로 입력해주면 테스트 피처 레코드의 개별 클래스 예측 확률을 반환한다.
(predict 메서드와 유사하지만 단지 반환 결과가 예측 결과 클래스값이 아닌 예측 확률 결과이다.)
◆ predict( ) 메서드: predict_proba() 메서드에 기반해 생성된 API이다.
predict()는 predict_proba() 호출 결과로 반환된 배열에서 분류 결정 임계값보다 큰 값이 들어 있는 칼럼의 위치를 받아서 최종적으로 예측 클래스를 결정하는 API이다.
사이킷런은 분류 결정 임곗값을 조절해 정밀도와 재현율의 성능 수치를 상호 보완적으로 조정할 수 있다.
[predict_proba 메서드 수행하고 predict 메서드 결과와 비교]
LogisticRegression 객체에서 predict_proba() 메서드를 수행한 뒤 반환 값을 확인하고, preidct() 메서드의 결과와 비교

▶ ndarray는 0과 1에 대한 확률을 나타내므로 첫 번째 칼럼 값과 두 번째 칼럼 값을 더하면 1이 된다.
두 개의 칼럼 중에서 더 큰 확률 값으로 preidct() 메서드가 최종 예측하고 있다.
[Binarizer 클래스]
연속형 변수를 특정 기준값 이하(equal or less the threshold)이면 '0', 특정 기준값 초과(above the threshold)이면 '1'의 두 개의 값만을 가지는 변수로 변환

▶ 입력된 X 데이터 세트에서 Binarizer의 threshold 값이 1.1보다 같거나 작으면 0, 크면 1로 변환
[Binarizer를 이용해 사이킷런 predict()의 의사(pseudo) 코드 생성]
앞서 구한 pred_proba 객체 변수에 분류 결정 임곗값(threshold)을 0.5로 지정한 Binarizer 클래스를 적용해 최종 예측값을 구하고, 최종 예측값에 대해 get_clf_eval() 함수를 적용해 평가 지표도 출력

▶ 이 의사 코드로 계산된 평가 지표는 앞 예제의 predict()로 계산된 지표값과 정확히 같다. 이를 통해 predict()가 predict_proba() 에 기반함을 알 수 있다.
※ 의사코드(pseudocode) [출처: 네이버 코뮤니티 카페]
자연어보다 간략하게 표현할 수 있는 코드. 프로그래밍 언어의 코드를 흉내내었다.
<의사코드의 예>
통장잔고 확인 ①
만약 (통장잔고 > 2만원) 이라면 ②
치킨 시키기 ③
(통장잔고 > 2만원)이 아니라면 ④
집밥이나 먹기 ⑤
<조금 더 정확한 의사코드의 예>
통장잔고 확인 ①
if (통장잔고 > 2만원) ②
치킨 시키기 ③
else ④
집밥이나 먹기 ⑤
[임곗값을 낮추면 평가 지표는 어떻게 될까?]
분류 결정 임곗값을 0.4로 낮추면 어떻게 되는지 확인

▶ 임곗값을 낮추니 재현율 값이 올라가고 정밀도가 떨어짐을 확인할 수 있다.
이는 분류 결정 임곗값은 Positive 예측값을 결정하는 확률의 기준이 되기 때문인데, 확률이 0.5가 아닌 0.4부터 Positive로 예측을 더 너그럽게 하기 때문에 임곗값을 낮출수록 True 값이 더 많아지게 된다.
[임곗값을 0.4부터 0.6까지 0.05씩 증가시키며 평가 지표 조사]
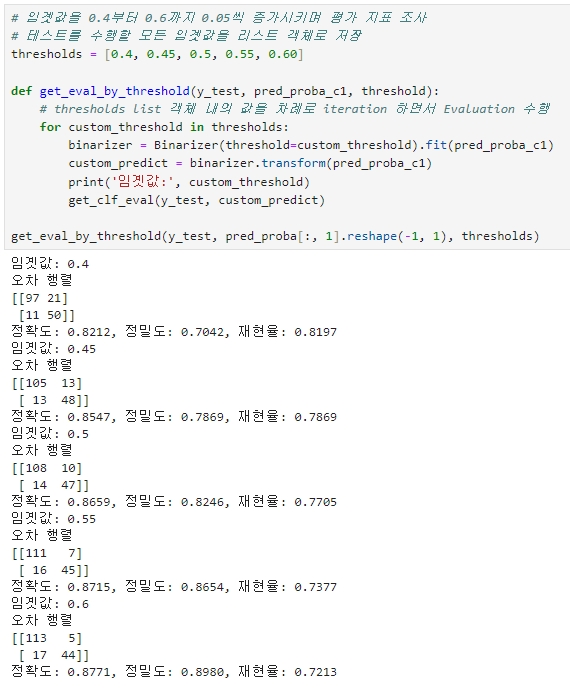
| 평가지표 | 분류 결정 임곗값 | ||||
| 0.4 | 0.45 | 0.5 | 0.55 | 0.6 | |
| 정확도 | 0.8212 | 0.8547 | 0.8659 | 0.8715 | 0.8771 |
| 정밀도 | 0.7042 | 0.7869 | 0.8246 | 0.8654 | 0.8980 |
| 재현율 | 0.8197 | 0.7869 | 0.7705 | 0.7377 | 0.7213 |
▶ 임곗값이 0.45일 경우 디폴트(0.5)와 비교하여 정확도는 비슷하나 정밀도는 약간 떨어지고 재현율이 올랐다.
◆ precision_recall_curve() API: 정밀도와 재현율을 구할 수 있는 API
[precision_recall_curve() 의 입력 파라미터와 반환 값]
1. 입력 파라미터
y_true: 실제 클래스값 배열(배열 크기=[데이터 건수])
probas_pred: Positive 칼럼의 예측 확률 배열(배열 크기=[데이터 건수])
2. 반환 값
정밀도: 임곗값별 정밀도 값을 배열로 반환
재현율: 임곗값별 재현율 값을 배열로 반환
147건의 데이터 중 샘플로 10건만 추출, 임곗값을 15 단계로 추출해 좀 더 큰 값의 임곗값과 그때의 정밀도와 재현율 값 체크

▶ 임곗값이 증가할수록 정밀도 값은 동시에 높아지나 재현율 값은 낮아진다.
[정밀도와 재현율 곡선 시각화]

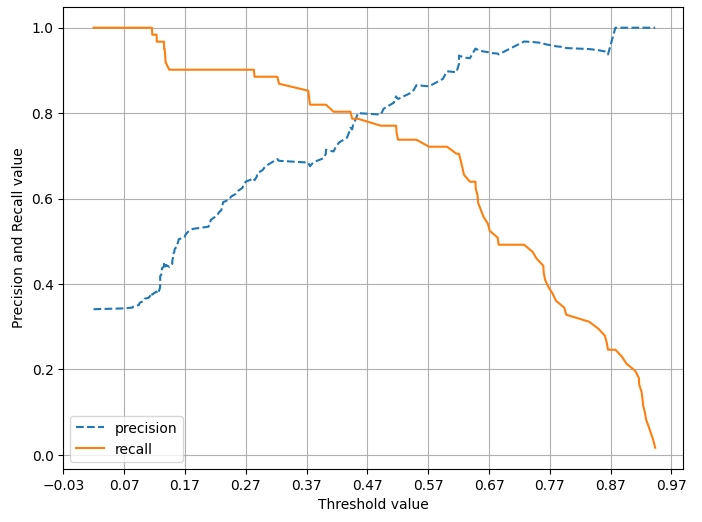
▶ 임곗값이 낮을수록 많은 수의 양성 예측으로 인해 재현율 값이 극도로 높아지고 정밀도 값이 극도로 낮아진다.
임곗값이 약 0.45 지점에서 재현율과 정밀도가 비슷해지는 모습을 보인다.
Positive 예측의 임곗값 변경에 따라 정밀도와 재현율의 수치가 변경되므로, 임곗값의 변경은 업무 환경에 맞게 두 개의 수치를 상호 보완할 수 있는 수준에서 적용돼야 한다.
다음글
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 피마 인디언 당뇨병 예측 (0) | 2024.06.11 |
|---|---|
| [머신러닝] 성능 평가 지표 - 3 (F1 스코어, ROC 곡선, AUC) (1) | 2024.06.10 |
| [머신러닝] 성능 평가 지표 - 1 (정확도, 정밀도, 재현율, 오차 행렬) (1) | 2024.06.09 |
| [머신러닝] 타이타닉 생존자 예측 (1) | 2024.06.09 |
| [머신러닝] 데이터 전처리 (1) | 2024.06.09 |



