시작에 앞서
해당 내용은 '<Do it! 점프 투 파이썬> 박응용 지음. 이지스 퍼블리싱' 을 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
이전 내용
[파이썬] 파이썬기초: 정규 표현식(Regular Expressions) - 2
시작에 앞서해당 내용은 ' 박응용 지음. 이지스 퍼블리싱' 을 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.이전 내용 [파이썬]
puppy-foot-it.tistory.com
정규 표현식 심화 - 메타 문자
◆ | : or(또는)
A|B = A or B (A 또는 B)
# | : or(또는)
p = re.compile('Crow|Eagle')
m = p.match('CrowHello')
print(m)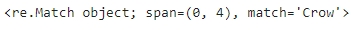
◆ ^: 맨 처음과 일치
※ re.M(또는 MULTILINE) 과 사용 시에는 여러 줄의 문자열의 각 줄의 처음과 일치
# ^: 맨 처음과 일치
print(re.search('^Life', 'Life is too short'))
print(re.search('^Life', 'Music is my Life'))
◆ $: 맨 끝과 일치
# $: 맨 끝과 일치
print(re.search('Life$', 'Life is too short'))
print(re.search('Life$', 'Music is my Life'))
◆ \A: 문자열의 처음과 매치
※ ^ 메타 문자와 동일하나, re.M 옵션을 사용할 경우
^은 각 줄의 처음
\A는 줄과 상관없이 전체 문자열의 처음하고만 매치
# \A: 문자열의 처음과 매치
# ^와의 차이
data = """one
life is too short
python two
you need python
python three"""
print(re.search('^python', data, re.M))
print(re.search('\Apython', data, re.M))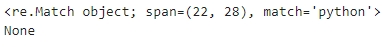
◆ \Z: 문자열의 끝과 매치
※ $ 메타 문자와 동일하나, re.M 옵션을 사용할 경우
$은 각 줄의 끝
\Z는 줄과 상관없이 전체 문자열의 끝 하고만 매치
# \Z: 문자열의 끝과 매치
# $와의 차이
data = """
I like music
We like music
Do you like music?
"""
print(re.search('music$', data, re.M))
print(re.search('\Zmusic', data, re.M))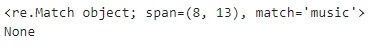
◆ \b: 단어 구분자(word boundary)
# \b: 단어 구분자(word boundary)
p = re.compile(r'\bclass\b') #백슬래시 raw string 사용
print(p.search('no class at all'))
print(p.search('the declassified algorithm'))
print(p.search('one subclass is'))
▶ '\bclass\b' 정규식은 앞뒤가 '(공백)class(공백)' 으로 된 문자와 매치됨을 의미
※ \b를 사용할 경우에는 백스페이스가 아닌 단어 구분자임을 알려주기 위해 Raw String을 알려주는 기호 r을 반드시 붙여 주어야 한다.
◆ \B: whitespace로 구분된 단어가 아닌 경우에만 매치 ↔ \b
# \B: whitespace로 구분된 단어가 아닌 경우에만 매치 ↔ \b
p = re.compile(r'\Bclass\B') #백슬래시 raw string 사용
print(p.search('no class at all'))
print(p.search('the declassified algorithm'))
print(p.search('this is unclassfied'))
그루핑
그룹을 만들어주는 메타 문자는 '( )' 이다.
만약, ABC 문자열이 계속해서 반복되는지 조사하는 정규식을 작성하려면
'(ABC)+' 처럼 그루핑을 사용하여 작성할 수 있다.
# 그루핑
p = re.compile('(ABC)+')
m = p.search('ABCABCABC OK?')
print(m)
print(m.group(0))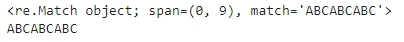
◆ group 메서드의 인덱스
| group(인덱스) | 설명 |
| group(0) | 매치된 전체 문자열 |
| group(1) | 첫 번째 그룹에 해당하는 문자열 |
| group(2) | 두 번째 그룹에 해당하는 문자열 |
| group(n) | n 번째 그룹에 해당하는 문자열 |
예를 들어, '이름 + ' '전화번호' 형태의 문자열을 찾는 정규식이 있을 때, 매치된 문자열 중 이름만 뽑아내고 싶다면
# group 메서드의 인덱스
p = re.compile(r"\w+\s+\d+[-]\d+[-]\d+")
m = p.search("Song 010-5678-1234")
print(m)
q = re.compile(r"(\w+)\s+\d+[-]\d+[-]\d+") #첫 번째 그룹(이름)을 그루핑
n = q.search("Song 010-5678-1234")
print(n.group(1))
▶ "\w+\s+\d+[-]\d+[-]\d+" 중 이름에 해당하는 \w 부분을 그룹(\w)으로 만들면 그룹핑된 부분의 문자열만 추출할 수 있다.
그렇다면, 다음을 수행해보자.
Q1. 전화 번호 부분만 추출
Q2. 국번 부분만 추출
# 전화번호 부분만 추출
p = re.compile(r"(\w+)\s+(\d+[-]\d+[-]\d+)")
m = p.search("Song 010-5678-1234")
print(m.group(2))
#국번 부분만 추출
q = re.compile(r"(\w+)\s+((\d+)[-]\d+[-]\d+)")
n = q.search("Song 010-5678-1234")
print(n.group(1)) #이름
print(n.group(2)) #전화번호
print(n.group(3)) #국번
▶ 그룹이 중첩되어 있는 경우는 바깥쪽부터 시작하여 안쪽으로 들어갈수록 인덱스가 증가한다.
◆ 그루핑된 문자열 재참조하기: \1
(*\1은 정규식의 그룹 중 첫 번째 그룹을 가리킴)
# 그루핑된 문자열 재참조하기
p = re.compile(r'(\b\w+)\s+\1')
p.search('Paris in the the spring').group()
▶ 정규식 '(\b\w+)\s+\1' 은 '(그룹) + " " +그룹과 동일한 단어'와 매치됨을 의미 (2개의 동일한 단어를 연속적으로 사용해야만 매치)
그루핑된 문자열에 이름 붙이기
정규식은 그룹을 만들 때 그룹이름을 지정할 수 있게 했다.
(?P<그룹 이름>...)
# 그루핑된 문자열에 이름 붙이기
# (?P<name>\w+)\s+((\d+)[-]\d[-]\d+)
p = re.compile(r"(?P<name>\w+)\s+((\d+)[-]\d+[-]\d+)")
m = p.search("Song 010-5678-1234")
print(m.group("name"))
▶ (\w+) 그룹에 name이라는 이름을 붙여주었다.
그룹이름을 사용하면 정규식 안에서 재참조하는 것도 가능하다.
# 정규식 안에서 그룹 이름 재참조하기
p = re.compile(r'(?P<word>\b\w+)\s+(?P=word)')
p.search('Paris in the the spring').group()
▶ 재참조시에는 (?P=그룹이름)이라는 확장 구문을 사용해야 한다.
다음 내용
[파이썬] 파이썬기초: 정규 표현식(Regular Expressions) - 4
시작에 앞서해당 내용은 ' 박응용 지음. 이지스 퍼블리싱' 을 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.이전 내용 [파이썬]
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 기초>' 카테고리의 다른 글
| [파이썬] konlpy 설치 관련 JVM 오류 해결 (1) | 2024.07.03 |
|---|---|
| [파이썬] 파이썬기초: 정규 표현식(Regular Expressions) - 4 (0) | 2024.06.22 |
| [파이썬] 파이썬기초: 정규 표현식(Regular Expressions) - 2 (0) | 2024.06.22 |
| [파이썬] 파이썬기초: 정규 표현식(Regular Expressions) - 1 (0) | 2024.06.21 |
| [파이썬] 파이썬기초: 내장 함수(Built-in Functions) (0) | 2024.06.20 |



