결정 트리(Decision Tree)
◆ 결정 트리 알고리즘
: 데이터 있는 규칙을 학습을 통해 자동으로 찾아내 트리(Tree) 기반의 분류 규칙을 만드는 것.
일반적으로 룰 기반의 프로그램에 적용되는 if, else 를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘이다.
▶ 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우
[결정 트리의 구조]
- 규칙 노드(Decision Node): 규칙 조건
- 리프 노드(Leaf Node): 결정된 클래스 값
- 서브 트리(Sub Tree): 새로운 규칙 조건 마다 생성
데이터 세트에 피처가 있고 이러한 피처가 결합해 규칙 조건을 만들 때마다 규칙 노드가 생성되나,
트리의 깊이가 깊어질수록 과적합 발생 우려가 높아져 결정 트리의 예측 성능이 저하될 가능성이 높다.
▶ 최대한 균일한 데이터 세트를 구성할 수 있도록 트리를 분할하는 것이 중요.
[정보의 균일도를 측정하는 방법]
- 엔트로피를 이용한 정보 이득 지수
- 지니 계수
◆ 엔트로피는 주어진 데이터 집합의 혼잡도를 의미하는데, 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮다. (정보 이득 지수는 1-엔트로피 지수)
결정 트리는 정보 이득이 높은 속성을 기준으로 분할한다. (정보 이득 지수로 분할 기준을 정함)
◆ 지니 계수는 경제학에서 불평등 지수를 나타낼 때 사용하는 계수이다. (0: 가장 평등, 1로 갈수록 불평등)
머신러닝에 적용될 때는 지니 계수가 낮을수록 데이터 균일도가 높은 것으로 해석해 지니 계수가 낮은 속성을 기준으로 분할.
기본적으로 DecisionTreeClassifier 클래스는 지니 계수를 사용하지만 criterion 매개변수를 'entropy'로 지정하여 엔트로피를 사용할 수도 있다.
지니 불순도(계수)와 엔드로피는 실제로는 큰 차이가 없고 둘 다 비슷한 트리를 만들어내는데, 지니 불순도가 조금 더 계산이 빠르게 때문에 기본값으로 좋다. 그러나 다른 트리가 만들어지는 경우 지니 불순도는 가장 빈도 높은 클래스를 한쪽 가지로 고립시키는 경향이 있는 반면 엔트로피는 조금 더 균형 잡힌 트리를 만든다.
결정 트리 모델의 특징
◆ 장점
- '균일도'라는 룰을 기반으로 하고 있어 쉽고 직관적
- 피처의 스케일링이나 정규화 등의 사전 가공 영향도가 크지 않음
◆ 단점
- 과적합으로 알고리즘 성능(정확도)이 떨어짐.
(이를 극복하기 위해 트리의 크기를 사전에 제한하는 튜닝 필요)
결정 트리는 직관적이고 결정 방식을 이해가 쉬운 화이트박스 모델이다.
결정 트리 파라미터
사이킷런은 결정 트리 알고리즘을 구현한 클래스를 제공
- DecisionTreeClassifier ; 분류를 위한 클래스
- DecisionTreeRegressor: 회귀를 위한 클래스
사이킷런의 결정 트리 구현은 CART(Classification And Regressor Trees) 알고리즘 기반인데,
CART는 분류뿐만 아니라 회귀에서도 사용될 수 있다.
[결정 트리 파라미터]
| 파라미터 명 | 설명 |
| min_samples_split | - 노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는 데 사용 - 디폴트는 2이고 작게 설정할수록 분할되는 노드가 많아져서 과적합 가능성 증가 |
| min_samples_leaf | - 분할이 될 경우 왼쪽과 오른쪽의 브랜치 노드에서 가져야 할 최소한의 새믈 데이터 수 - 큰 값으로 설정될수록, 분할될 경우 왼쪽과 오른쪽의 브랜치 노드에서 가져야 할 최소한의 샘플 데이터 수 조건을 만족시키기가 어려우므로 노드 분할을 상대적으로 덜 수행 - min_samples_split과 유사하게 과적합 제어 용도, 그러나 비대칭적 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 이 경우는 작게 설정 필요 |
| max_features | - 최적의 분할을 위해 고려할 최대 피처 개수. 디폴트는 None으로 데이터 세트의 모든 피처를 사용해 분할 수행 - int 형으로 지정하면 대상 피처의 개수, float 형으로 지정하면 전체 피처 중 대상 피처의 퍼센트 - 'sqrt'는 전체 피처 중 sqrt(전체 피처 개수) 만큼 선정 - 'auto'로 지정하면 sqrt와 동일 - 'log'는 전체 피처 중 log2(전체 피처 개수) 선정 - 'None'은 전체 피처 선정 |
| max_depth | - 트리의 최대 깊이를 규정 - 디폴트는 None, None으로 설정하면 완벽하게 클래스 결정 값이 될 때까지 깊이를 계속 키우며 분할하거나 노드가 가지는 데이터 개수가 min_samples_split 보다 작아질 때까지 계속 깊이를 증가시킴 - 깊이가 깊어지면 min_samples_split 설정대로 최대 분할하여 과적합할 수 있으므로 적절한 값으로 제어 필요 |
| max_leaf_nodes | - 말단 노드(Leaf)의 최대 개수 |
결정 트리 모델의 시각화 (Graphviz 패키지 설치)
Graphviz 패키지를 사용하면 결정 트리 알고리즘이 어떠한 규칙을 가지고 트리를 생성하는지 시각적으로 보여줄 수 있다.
사이킷런은 이러한 Graphviz 패키지와 쉽게 인터페이스할 수 있도록 export_graphviz( ) API를 제공한다.
Graphviz는 파이썬 용으로 개발 된 패키지가 아니기 때문에 이를 파이썬 기반의 모듈과 인터페이스하기 위해서는 먼저 Graphviz 를 설치한 뒤 파이썬과 인터페이스할 수 있는 파이선 래퍼(Wrapper) 모듈을 별도로 설치해야 한다.
[Graphviz 설치]
1. 하단 링크에 접속하여 설치 파일을 다운로드 한다.
https://graphviz.org/download/
Download
Graph Visualization Software
graphviz.org

2. 설치 파일을 클릭하여 설치 수행 (+시스템 PATH 변수 설정)
★ 설치 시에는 반드시 로컬 PC의 시스템 PATH 변수를 설정해야 하므로, 설치 옵션에서 하단의 옵션을 선택하여 설치 수행.
'Add Graphviz to the system PATH for all users'
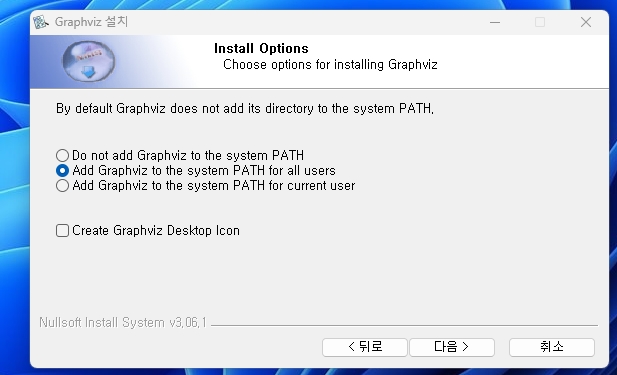
설치 후에 시스템 PATH 변수가 제대로 설치되었는지 확인
(검색에서 '환경 변수' 검색하여 확인하면 된다)
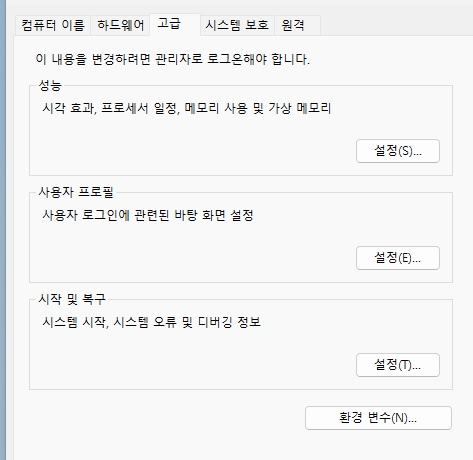
나는 시스템 PATH 설정이 안 되어 있어 새로 만들기를 클릭하여 경로를 추가하였다.
(C드라이브 → Program Files → Graphviz → bin 클릭)

3. Graphviz 파이썬 래퍼 모듈 설치
Graphviz 파이썬 래퍼 모듈을 pip (또는 conda) 명령어를 이용해 설치
나의 경우는 아나콘다 콘솔에서 conda install graphviz 명령어로 설치하였다.
(콘솔 생성 시 '자세히 → 관리자 권한으로 실행'으로 생성)
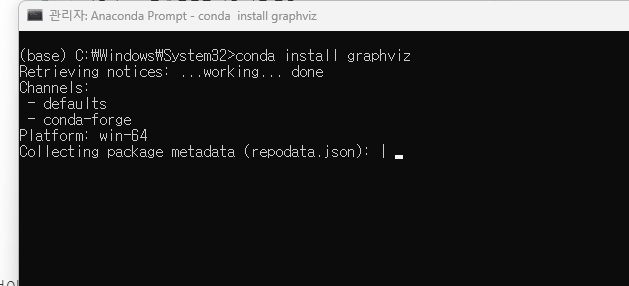
4. 주피터 노트북 실행
Graphviz를 이용한 시각화 (붓꽃 데이터 세트)
설치가 완료된 Graphviz 를 이용해 붓꽃 데이터 세트에 결정 트리를 적용할 때 어떻게 서브 트리가 구성되고 만들어지는지 시각화 해본다.
먼저, 필요한 라이브러리를 import 하고 분류기 생성, 데이터 로딩, 데이터 분할 등의 기초 세팅 작업을 한다.
# importing libraries
from sklearn.tree import DecisionTreeClassifier #결정트리 분류기 불러오
from sklearn.datasets import load_iris #붓꽃 데이터 세트 불러오기
from sklearn.model_selection import train_test_split #데이터 분할
import warnings #경고 모듈 불러오기(모든 경고 무시)
warnings.filterwarnings('ignore')
#DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state = 156)
#붓꽃 데이터 로딩, 학습과 테스트 데이터 세트로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state = 11)
#DecisionTreeClassifier 학습
dt_clf.fit(X_train, y_train)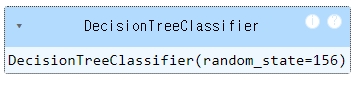
사이킷런의 Graphviz를 이용하기 위해 export_graphviz() 함수를 불러온다.
export_graphviz() 는 Graphviz가 읽어 들여서 그래프 형태로 시각화할 수 있는 출력 파일을 생성하는데,
해당 함수에 인자로 학습이 완료된 estimator, output 파일 명, 결정 클래스의 명칭, 피처의 명칭을 입력해주면 된다.
# graphviz 함수 불러오기
from sklearn.tree import export_graphviz
# export_graphviz 호출 결과로 out_file로 지정된 tree.dot 파일 생성
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names,
feature_names = iris_data.feature_names, impurity=True, filled=True)
생성된 출력 파일 'tree.dot'을 Graphviz의 파이썬 래퍼 모듈을 호출해 결정 트리의 규칙을 시각적으로 표현
import graphviz
#위에서 생성된 tree.dot 파일을 Graphviz가 읽어서 시각화
with open("tree.dot")as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
만약 하단과 같이 graphviz 모듈이 없다는 메시지가 나온다면,
ModuleNotFoundError: No module named 'graphviz'
graphviz 설치 명령어를 입력하여 수행 후 다시 진행하면 된다.
pip install graphviz
[붓꽃 데이터 세트의 결정 트리 구조]
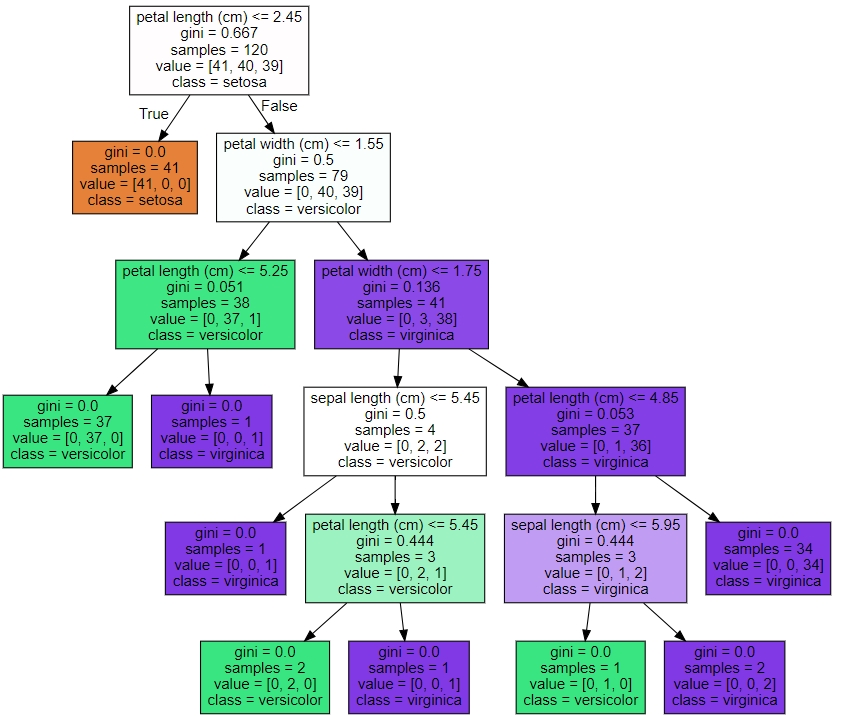
★ 결정 트리 규칙의 구성 요소
- 리프 노드: 더 이상 자식 노드가 없는 노드. 최종 클래스(레이블) 값이 결정
(리프 노드가 되려면 오직 하나의 클래스 값으로 최종 데이터가 구성되거나 리프 노드가 될 수 있는 하이퍼 파라미터 조건을 충족하면 된다.)
- 브랜치 노드: 자식 노드가 있는 노드. 자식 노드를 만들기 위한 분할 규칙 조건을 가지고 있다.
다음 글
[파이썬] 머신러닝 알고리즘: 결정 트리 - 2
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 이전 내용 [파이썬] 머신러
puppy-foot-it.tistory.com
[출처]
파이썬 머신러닝 완벽 가이드
핸즈 온 머신러닝
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 결정 트리 - 3 (0) | 2024.06.23 |
|---|---|
| [머신러닝] 결정 트리 - 2 (0) | 2024.06.23 |
| [머신러닝] 분류와 분류 관련 머신러닝 알고리즘 (1) | 2024.06.11 |
| [머신러닝] 피마 인디언 당뇨병 예측 (0) | 2024.06.11 |
| [머신러닝] 성능 평가 지표 - 3 (F1 스코어, ROC 곡선, AUC) (1) | 2024.06.10 |



