시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
이전 내용
[파이썬] 머신러닝 알고리즘: 결정 트리 (+시각화)
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 결정 트리(Decision Tree) ◆ 결
puppy-foot-it.tistory.com
시각회된 결정 트리 분석
앞서 시각화했던 결정 트리에 대해 상세히 설명하면,
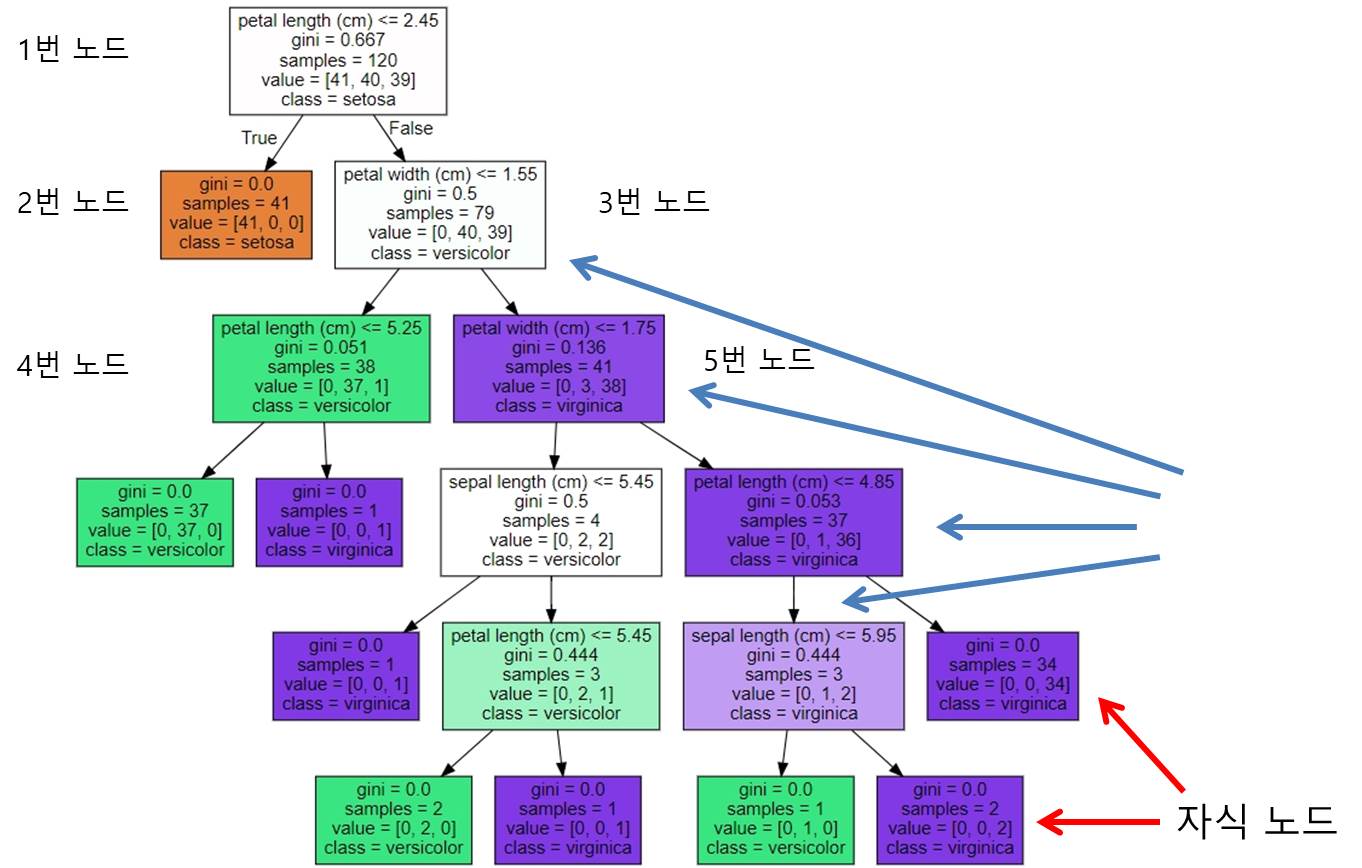
[노드 내에 기술된 지표의 의미]
- petal length(cm) <= 2.45와 같이 피처의 조건이 있는 것은 자식 노드를 만들기 위한 규칙 조건.
(이 조건이 없으면 자식 노드이다.)
- gini는 다음의 value=[]로 주어진 데이터 분포에서의 지니 계수
- samples는 현 규칙에 해당하는 데이터 건수
- value = [] 는 클래스 값 기반의 데이터 건수. 붓꽃 데이터 세트는 클래스 값으로 0, 1, 2를 가지고 있으며,
0: Setosa, 1:Versicolor, 2:Virginica 품종을 가리킨다.
만일 value=[41, 40, 39] 라면 클래스 값의 순서로 Setosa 41개, Versicolor 40개, Virginica 39개로 데이터가 구성되어 있다는 의미이다.
[각 노드의 지표 설명]
<1번 노드>
- samples = 120개는 전체 데이터가 120개라는 의미
- value = [41, 40, 39]는 Setosa 41개, Versicolor 40개, Virginica 39개로 데이터가 구성
- samples 120개가 value = [41, 40, 39] 분포도로 구성되어 있으므로 지니 계수는 0.667
- petal length(cm) <= 2.45 규칙으로 자식 노드 생성
- class = setosa는 하위 노드를 가질 경우 setosa 의 개수가 41개로 제일 많다는 의미
peta length(cm) <= 2.45 규칙이 True, 또는 False로 분기하게 되면 2번, 3번 노드 생성
<2번 노드>
- 모든 데이터가 Setosa로 결정되므로 클래스가 결정된 리프 노드가 되고 더 이상 2번 노드에서 규칙을 만들 필요가 없음.
- 41개의 샘플 데이터 모두 Setosa 이므로 예측 클래스는 Setosa로 결정
- 지니 계수는 0
<3번 노드>
- Petal length <= 2.45가 False인 규칙 노드
- 79개의 데이터 중 Versicolor 40개, Virginica 39개로 여전히 지니 계수는 0.5로 높으므로 다음 자식 브랜치 노드로 분기할 규칙 필요
- petal width <= 1.55 규칙으로 자식 노드 생성
<4번 노드>
- petal width <= 1.55가 True인 규칙 노드
- 38개의 샘플 데이터 중 Versicolor 37개, Virginica 1개로 대부분이 Versicolor
- 지니 계수는 0.051로 매우 낮으나 여전히 Versicolor 와 Virginica 가 혼재되어 있으므로 petal length <= 5.25 라는 규칙으로 다시 자식 노드 생성
<5번 노드>
- Petal width <= 1.55가 False인 규칙 노드
- 41개의 샘플 데이터 중 Versicolor 3개, Virginica 38개로 대부분이 Virginica
- 지니 계수는 0.136으로 낮으나 여전히 Versicolor 와 Virginica 가 혼재되어 있으므로 petal length <= 1.75 라는 규칙으로 다시 자식 노드 생성
◆ 각 노드의 색깔 : 붓꽃 데이터의 레이블 값
주황색 ▶ 0: Setosa
초록색 ▶ 1: Versicolor
보라색 ▶ 2: Virginica
※ 색깔이 짙어질수록 지니 계수가 낮고 해당 레이블에 속하는 샘플 데이터가 많다는 의미
결정 트리는 규칙 생성 로직을 미리 제어하지 않으면 완벽하게 클래스 값을 구별해내기 위해 트리 노드를 계속해서 만들어 가며, 이로 인해 매우 복잡한 규칙 트리가 만들어져 모델이 쉽게 과적합되는 문제점을 가지게 된다.
이 때문에 결정 트리 알고리즘을 제어하는 대부분 하이퍼 파라미터는 복잡한 트리가 생성되는 것을 막기 위한 용도이다.
하이퍼 파라미터에 따른 규칙 트리의 변화
[max_depth를 3으로 설정한 결정 트리]
#DecisionTree Classifier 생성 (트리 최대 깊이 설정)
dt_clf = DecisionTreeClassifier(random_state = 156, max_depth=3)
#붓꽃 데이터 로딩, 학습과 테스트 데이터 세트로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state = 11)
#DecisionTreeClassifier 학습
dt_clf.fit(X_train, y_train)
# export_graphviz 호출 결과로 out_file로 지정된 tree.dot1 파일 생성
export_graphviz(dt_clf, out_file="tree.dot1", class_names=iris_data.target_names,
feature_names = iris_data.feature_names, impurity=True, filled=True)
#위에서 생성된 tree.dot1 파일을 Graphviz가 읽어서 시각화
with open("tree.dot1")as f1:
dot_graph = f1.read()
graphviz.Source(dot_graph)
▶ 트리 깊이가 설정된 max_depth(3)에 따라 줄어들면서 더 간단한 결정 트리가 된다.
[min_sample_split 하이퍼 파라미터]
min_sample_split 하이퍼 파라미터는 자식 규칙 노드를 분할해 만들기 위한 최소한의 샘플 데이터 개수이다.
예를 들어 min_sample_split=4 로 설정하면,
#DecisionTree Classifier 생성 (최소한의 샘플 데이터 개수 설정)
dt_clf = DecisionTreeClassifier(random_state = 156, min_samples_split=4)
#붓꽃 데이터 로딩, 학습과 테스트 데이터 세트로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state = 11)
#DecisionTreeClassifier 학습
dt_clf.fit(X_train, y_train)
# export_graphviz 호출 결과로 out_file로 지정된 tree.dot2 파일 생성
export_graphviz(dt_clf, out_file="tree.dot2", class_names=iris_data.target_names,
feature_names = iris_data.feature_names, impurity=True, filled=True)
#위에서 생성된 tree.dot2 파일을 Graphviz가 읽어서 시각화
with open("tree.dot2")as f2:
dot_graph = f2.read()
graphviz.Source(dot_graph)
[min_samples_leaf 하이퍼 파라미터]
min_samples_leaf 하이퍼 파라미터 변경에 따른 결정 트리의 변화를 살펴본다.
리프 노드는 더 이상 분할될 수 없어 클래스 결정 갑시 되는데, min_samples_leaf 는 분할될 경우 왼쪽과 오른쪽 자식 노드 각각이 가지게 될 최소 데이터 건수를 지정한다.
▶ 어떤 노드가 분할할 경우, 왼쪽과 오른쪽 자식 노드 중에 하나라도 min_sample_leaf로 지정된 최소 데이터 건수보다 더 작은 샘플 데이터 건수를 갖게 된다면, 해당 노드는 더 이상 분할하지 않고 리프 노드가 된다.
min_sample_leaf 의 값을 키우면 분할될 수 있는 조건이 어렵게 되므로, 리프 노드가 될 수 있는 조건이 상대적으로 완화된다.
예를 들어, 기본값이 1인 min_sample_leaf를 4로 변경하면
노드가 분할할 때 왼쪽, 오른쪽 노드가 모두 샘플 데이터 건수 4 이상을 가진 노드가 되어야 하므로 기본값이 1일 때보다 상대적으로 조건을 만족하기가 어려워 보다 적은 횟수로 분할을 수행하게 된다.
#DecisionTree Classifier 생성 (최소 데이터 건수를 지정)
dt_clf = DecisionTreeClassifier(random_state = 156, min_samples_leaf=4)
#붓꽃 데이터 로딩, 학습과 테스트 데이터 세트로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state = 11)
#DecisionTreeClassifier 학습
dt_clf.fit(X_train, y_train)
# export_graphviz 호출 결과로 out_file로 지정된 tree.dot3 파일 생성
export_graphviz(dt_clf, out_file="tree.dot3", class_names=iris_data.target_names,
feature_names = iris_data.feature_names, impurity=True, filled=True)
#위에서 생성된 tree.dot3 파일을 Graphviz가 읽어서 시각화
with open("tree.dot3")as f3:
dot_graph = f3.read()
graphviz.Source(dot_graph)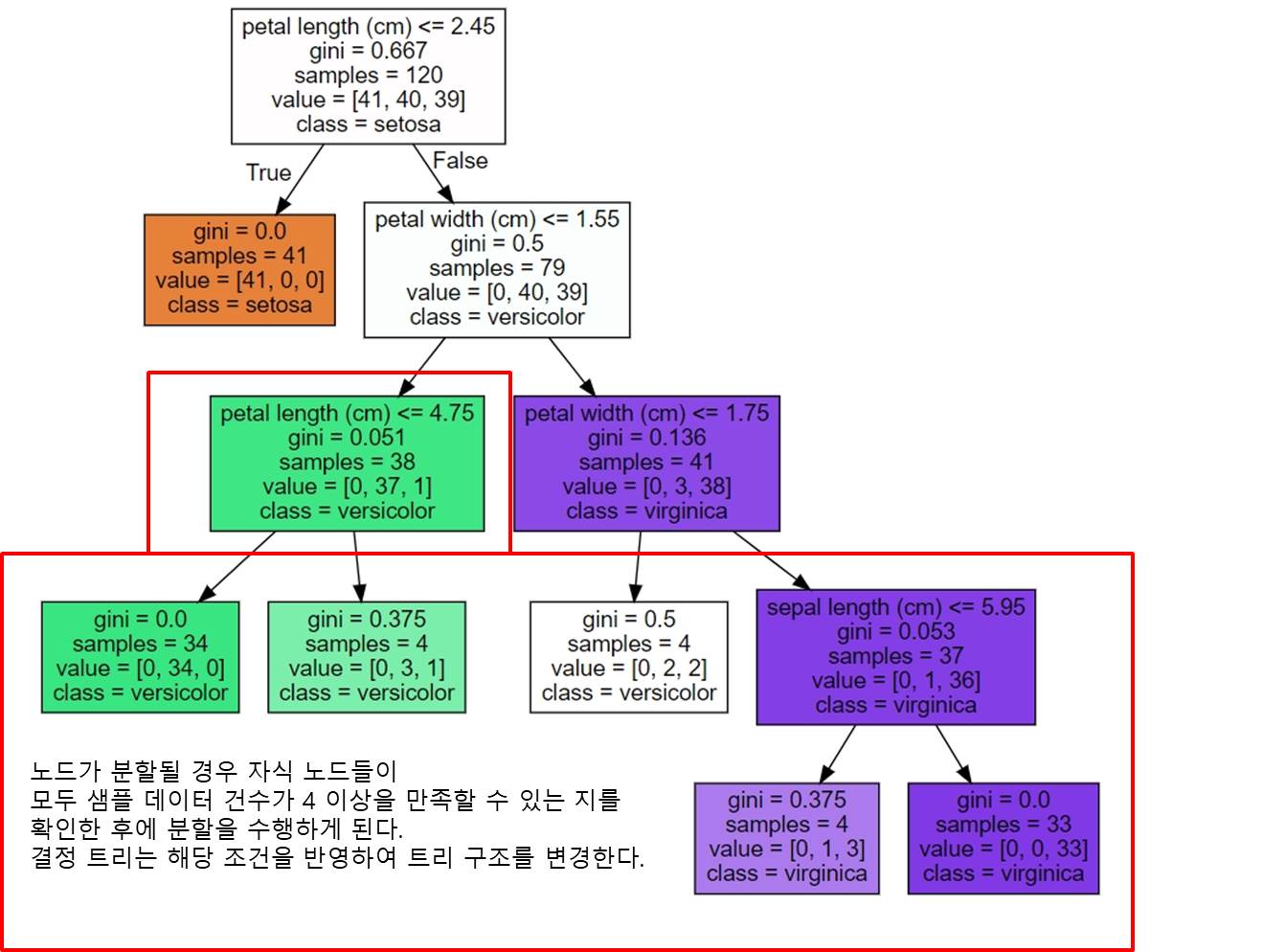
▶ 브랜치 노드가 줄어들고 결정 트리가 더 간결하게 만들어진다.
다음글
[머신러닝] 결정 트리 - 3
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 이전 내용 [파이썬] 머신러
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 결정트리 - 사용자 행동 인식 데이터 세트 (0) | 2024.06.23 |
|---|---|
| [머신러닝] 결정 트리 - 3 (0) | 2024.06.23 |
| [머신러닝] 결정 트리 (+시각화) (0) | 2024.06.23 |
| [머신러닝] 분류와 분류 관련 머신러닝 알고리즘 (1) | 2024.06.11 |
| [머신러닝] 피마 인디언 당뇨병 예측 (0) | 2024.06.11 |



