시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
사용자 행동 인식 데이터 세트
[실습 내용]
결정 트리를 이용해 UCI 머신러닝 리포지토리(Machine Learning Repository)에서 제공하는 사용자 행동 인식(Human Activity Recognition) 데이터 세트에 대한 예측 분류 수행
해당 데이터는 30명에게 스마트폰 센서를 장착한 뒤 사람의 동작과 관련된 여러 가지 피처를 수집한 데이터이며,
수집된 피처 세트를 기반으로 결정 트리를 이용해 어떠한 동작인지 예측해 보는 것이 수행 목표이다.
우선, 하단의 링크로 접속하여 데이터 세트를 다운 받는다.
https://archive.ics.uci.edu/dataset/240/human+activity+recognition+using+smartphones
UCI Machine Learning Repository
This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license. This allows for the sharing and adaptation of the datasets for any purpose, provided that the appropriate credit is given.
archive.ics.uci.edu
압축을 풀고 폴더명 'UCI HAR Dataset' 이 공란이 있는 관계로 폴더명을 'human_activity'로 변경하고 주피터 노트북을 켠다.
[폴더 간략 설명]
- README.txt, features_info.txt 파일: 데이터 세트와 피처에 대한 간략한 설명
- features.txt: 피처의 이름 기술
- activity_labels.txt: 동작 레이블 값에 대한 설명
- train, test: 학습(Train) 용도의 피처 데이터 세트와 레이블 데이터 세트, 테스트(Test)용 피처 데이터 세트와 클래스 값 데이터 세트
- 피처는 모두 561개가 있으며, 공백으로 분리되어 있다
features.txt 파일은 피처 인덱스와 피처 명을 가지고 있으므로 이 파일을 DataFrame으로 로딩해 피처의 명칭 확인
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# features.txt 파일에는 피처 이름 index와 피처명이 공백으로 분리되어 있음
# 이를 DataFrame으로 로드
feature_name_df = pd.read_csv('./human_activity/features.txt',
sep='\s+', header=None, names=['column_index', 'column_name'])
# 피처명 index를 제거하고, 피처명만 리스트 객체로 생성한 뒤 샘플로 10개만 추출
feature_name = feature_name_df.iloc[:, 1].values.tolist()
print('전체 피처명에서 10개만 추출:', feature_name[:10])
▶ 피처명을 보면 인체의 움직임과 관련된 속성의 평균/표준편차가 X, Y, Z 축 값으로 되어 있음을 유추할 수 있다.
전체 피처명에서 10개만 추출: ['tBodyAcc-mean()-X', 'tBodyAcc-mean()-Y', 'tBodyAcc-mean()-Z', 'tBodyAcc-std()-X', 'tBodyAcc-std()-Y', 'tBodyAcc-std()-Z', 'tBodyAcc-mad()-X', 'tBodyAcc-mad()-Y', 'tBodyAcc-mad()-Z', 'tBodyAcc-max()-X']
피처명을 가지고 있는 features.txt 파일은 중복된 피처명을 가지고 있다. 따라서 중복된 피처명에 대해서는 원본 피처명에 _1 또는 _2를 추가로 부여해 변경한 뒤에 이를 이용해서 DataFrame을 로드한다.
※ 중복된 피처명 파악하기
# 중복된 피처명 파악하기
feature_dup_df = feature_name_df.groupby('column_name').count()
print(feature_dup_df[feature_dup_df['column_index'] > 1].count())
feature_dup_df[feature_dup_df['column_index'] > 1].head()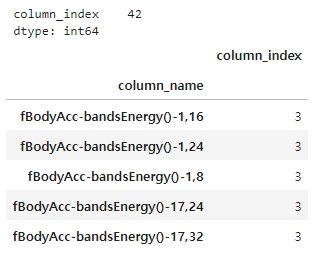
▶ 총 42개의 피처명이 중복되어 있다.
이 중복된 피처명에 원본 피처명_1 또는 _2를 추가해 새로운 피처명을 가지는 DataFrame을 반환하는 함수인 get_new_feature_name_df()를 생성
# 중복된 피처명에 _1 또는 _2 추가하는 함수
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(),
columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1])
if x[1] > 0 else x[0], axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_df
train 디렉터리의 학습용 피처 데이터 세트, 레이블 데이터 세트
test 디렉터리의 테스트용 피처 데이터 파일과 레이블 데이터 파일을 각각 학습/테스트용 DataFrame에 로드
해당 데이터 세트는 get_human_dataset() 이라는 함수로 생성 (DataFrame을 생성하는 로직)
앞서 생성한 get_new_feature_name_df()는 get_human_dataset() 내에서 적용돼 중복된 피처명을 새로운 피처명으로 할당
# get_human_dataset 함수 생성
import pandas as pd
def get_human_dataset():
# 각 데이터 파일은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep로 할당
feature_name_df = pd.read_csv('../human_activity/features.txt',
sep='\s+', header=None, names=['column_index', 'column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DF 생성
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DF에 피처명을 칼럼으로 부여하기 위헤 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터세트와 테스트 피처 데이터를 DF로 로딩. 칼럼명은 feature_name 적용
X_train = pd.read_csv('../human_activity/train/X_train.txt', sep='\s+', names=feature_name)
X_test = pd.read_csv('../human_activity/test/X_test.txt', sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터를 DF로 로딩하고 칼럼명은 action 부여
y_train = pd.read_csv('../human_activity/train/y_train.txt', sep='\s+', header=None,names=['action'])
y_test = pd.read_csv('../human_activity/test/y_test.txt', sep='\s+', header=None, names=['action'])
# 로드된 학습/테스트용 DF 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()
로드한 학습용 피처 데이터 세트를 간략히 살펴 보면
print('## 학습 피처 데이터셋 ##')
print(X_train.info())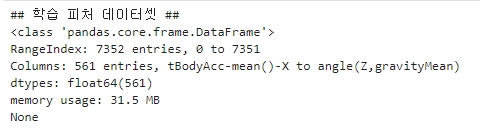
▶ 학습 데이터 세트는 7352개의 레코드로 561개의 피처를 가지고 있으며, 피처가 전부 float 형의 숫자 형이다.
print(y_train['action'].value_counts())
▶ 레이블 값은 1, 2, 3, 4, 5, 6 6개의 값이고 분포도는 특정 값으로 왜곡되지 않고 비교적 고르게 분포되어 있다.
동작 예측 분류 수행
사이킷런의 DecisionTreeClassifier를 이용해 동작 예측 분류를 수행한다.
먼저 하이퍼 파라미터는 모두 디폴트 값으로 설정하여 수행하고, 이때의 하이퍼 파라미터 값을 모두 추출.
# 동작 예측 분류 수행
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 예제 반복 시마다 동일한 예측 결과 도출을 위해 random_state 설정
dt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('결정 트리 예측 정확도: {0:.4f}'.format(accuracy))
# DecisionTreeClassifier의 하이퍼 파라미터 추출
print('DecisionTreeClassifier 기본 하이퍼 파라미터:\n', dt_clf.get_params())결정 트리 예측 정확도: 0.8548
DecisionTreeClassifier 기본 하이퍼 파라미터:
{'ccp_alpha': 0.0, 'class_weight': None, 'criterion': 'gini', 'max_depth': None, 'max_features': None, 'max_leaf_nodes': None, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'monotonic_cst': None, 'random_state': 156, 'splitter': 'best'}
▶ 약 85.48%의 정확도를 나타내고 있다.
◆ 결정 트리의 트리 깊이가 예측 정확도에 주는 영향 측정하기
GridSearchCV를 이용해 사이킷런 결정 트리의 깊이를 조절할 수 있는 하이퍼 파라미터인 max_depth 값을 변화시키면서 예측 성능 확인
min_samples_split은 16으로 고정하고 max_depth를 6, 8, 10, 12, 16, 20, 24로 계속 늘리면서 예측 성능을 측정한다.
교차 검증은 5개 세트.
# 트리 깊이가 예측 정확도에 주는 영향 측정
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6, 8, 10, 12, 16, 20, 24],
'min_samples_split' : [16]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, verbose=1)
grid_cv.fit(X_train, y_train)
print('GridSearchCV 최고 평균 정확도 수치: {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터:', grid_cv.best_params_)
▶ max_depth가 8일 때 5개의 폴드 세트의 최고 평균 정확도 결과가 약 85.49%로 도출되었다.
5개의 CV 세트에서 max_depth 값에 따라 어떻게 예측 성능이 변했는지 GridSearchCV 객체의 cv_results_ 속성을 통해 살펴본다.
# 평균 정확도 수치 추출
# GridSearchCV 객체의 cv_results_ 속성을 DF 로 생성
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
#max_depth 파라미터 값과 그때의 테스트 세트, 학습 데이터 세트의 정확도 수치 추출
cv_results_df[['param_max_depth', 'mean_test_score']]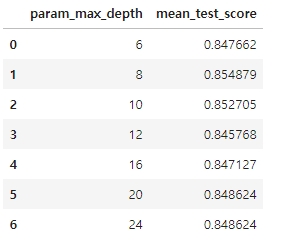
▶ mean_test_score: 5개 CV 세트에서 검증용 데이터 세트의 정확도 평균 수치.
mean_test_socre는 max_depth가 8일때 85.4879%로 정확도가 정점이고, 이를 넘어가면서 정확도가 계속 떨어진다.
별도의 테스트 데이터 세트에서 min_samples_split은 16으로 고정하고 max_depth의 변화에 따른 값을 측정
# 별도의 테스트 데이터 세트에서 min_samples_split은 16으로 고정하고 max_depth의 변화에 따른 값을 측정
max_depths = [6, 8, 10, 12, 16, 20, 24]
# max_depth 값을 변화시키면서 그때마다 학습과 테스트 세트에서의 예측 성능 측정
for depth in max_depths:
dt_clf = DecisionTreeClassifier(max_depth=depth, min_samples_split=16, random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('max_depth = {0} 정확도: {1:.4f}'.format(depth, accuracy))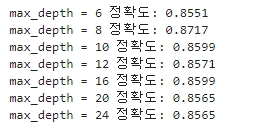
▶max_depth가 8일 경우 약 87.17%로 가장 높은 정확도를 나타낸다. (8을 넘어가면서 정확도 감소)
결정 트리는 깊이가 깊어질수록 과적합의 영향력이 커지므로 하이퍼 파라미터를 이용해 깊이를 제어할 수 있어야 한다.
복잡한 모델보다도 트리 깊이를 낮춘 단순한 모델이 더욱 효과적인 결과를 가져올 수 있다.
◆ max_depth와 min_samples_split을 같이 변경하면서 정확도 성능 튜닝
# max_depth와 min_samples_split을 같이 변경하면서 정확도 성능 튜닝
params = {
'max_depth' : [8, 12, 16, 20],
'min_samples_split' : [16, 24]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, verbose=1)
grid_cv.fit(X_train, y_train)
print('GridSearchCV 최고 평균 정확도 수치: {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터:', grid_cv.best_params_)
▶ max_depth가 8, min_samples_split이 16일 때 가장 최고의 정확도(85.49%)를 나타낸다.
앞 예제의 GridSearchCV 객체인 grid_cv의 속성인 best_estimator_는 최적 하이퍼 파라미터인 max_depth 8, min_samples_split 16으로 학습이 완료된 estimator 객체이다.
이를 이용해 테스트 데이터 세트에 예측 수행
# best_estimator 이용해 예측 수행
best_dt_clf = grid_cv.best_estimator_
pred1 = best_dt_clf.predict(X_test)
acccuracy = accuracy_score(y_test, pred1)
print('결정 트리 예측 정확도: {0:.4f}'.format(accuracy))
▶ max_depth가 8, min_samples_split이 16일 때 테스트 데이터 세트의 예측 정확도는 85.65% 이다.
각 피처의 중요도 시각화하기
마지막으로 결정 트리에서 각 피처의 중요도를 feature_importances_ 속성을 이용해 알아보고, 중요도가 높은 순으로 Top 20 피처를 막대그래프로 표현
# 각 피처의 중요도 시각화하기
import seaborn as sns
ftr_importances_values = best_dt_clf.feature_importances_
# Top 중요도로 정렬을 쉽게 하고, 시본(Seaborn)의 막대그래프로 쉽게 표현하기 위해 Series 변환
ftr_importances = pd.Series(ftr_importances_values, index=X_train.columns)
# 중요도 값 순으로 Series를 정렬
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8, 6))
plt.title('Feature Importances Top 20')
sns.barplot(x=ftr_top20, y= ftr_top20.index)
plt.show()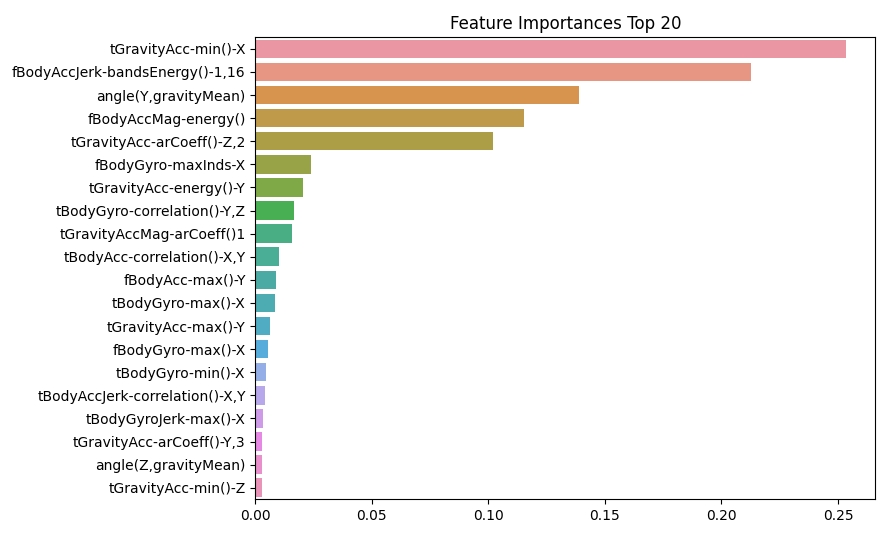
▶ 가장 높은 중요도를 가진 Top 5의 피처들이 매우 중요하게 규칙 생성에 영향을 미치고 있음을 알 수 있다.
전체 코드
다음 내용
[머신러닝] 분류 - 앙상블 학습(Ensemble Learning) 1
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.앙상블 학습(Ensemble Learning)
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 앙상블 : 랜덤 포레스트 (0) | 2024.06.27 |
|---|---|
| [머신러닝] 앙상블 학습(Ensemble Learning) (0) | 2024.06.27 |
| [머신러닝] 결정 트리 - 3 (0) | 2024.06.23 |
| [머신러닝] 결정 트리 - 2 (0) | 2024.06.23 |
| [머신러닝] 결정 트리 (+시각화) (0) | 2024.06.23 |



