시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
앙상블 학습(Ensemble Learning)
[파이썬] 분류: 앙상블 학습(Ensemble Learning) - 1
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.앙상블 학습(Ensemble Learning)
puppy-foot-it.tistory.com
[파이썬] 분류 > 앙상블 - 3 : GBM
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.앙상블 학습(Ensemble Learning) [
puppy-foot-it.tistory.com
XG Boost (eXtra Gradient Boost)
XG Boost는 GBM에 기반하고 있지만, GBM의 단점인 느린 수행 시간 및 과적합 규제 부재 등의 문제를 해결하고, 특히 병렬 CPU 환경에서 병렬 학습이 가능해 기존 GBM보다 빠르게 학습을 완료할 수 있어 트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나이다.
[XG Boost의 주요 장점]
- 뛰어난 예측 성능: 일반적으로 분류와 회귀 영역에서 뛰어난 예측 성능 발휘
- GBM 대비 빠른 수행 시간: 병렬 수행 및 다양한 기능으로 GBM에 비해 빠른 수행 성능 보장. (그러나, 타 머신러닝 알고리즘보다 빠르지는 않음.)
- 과적합 규제(Regularization): 자체에 과적합 규제 기능으로 과적합에 좀 더 강한 내구성을 가짐 (GBM의 경우 과적합 규제 기능 없음)
- 나무 가지치기(Tree Pruning): Tree Pruning으로 더 이상 긍정 이득이 없는 분할을 가지치기 해서 분할 수를 더 줄이는 추가적인 장점 가짐.
- 자체 내장된 교차 검증: 반복 수행 시마다 내부적으로 학습 데이터 세트와 평가 데이터 세트에 대한 교차 검증을 수행해 최적화된 반복 수행 횟수를 가짐.
- 결손값 자체 처리: 자체적으로 결손값을 처리할 수 있는 기능 가짐.
또한, XGBoost는 자체적으로 교차 검증, 성능 평가, 피처 중요도 등의 시각화 기능을 가지고 있다.
XG Boost의 파이썬 패키지명은 "xgboost". 해당 패키지는 출시 초기에 사이킷런과 호환되지 않았으나, 파이썬 기반의 머신러닝 이용자들이 사이킷런을 많이 사용하고 있었기 때문에 사이킷런과 연동할 수 있는 래퍼 클래스(Wrapper class)를 제공하게 됨.
(XGBClassifier, XGBRegressor)
XGBoost 설치하기(Windows 기반)
아나콘다 command(관리자 권한) 실행 후 'conda install -c anaconda py-xgboost' 입력
conda install -c anaconda py-xgboost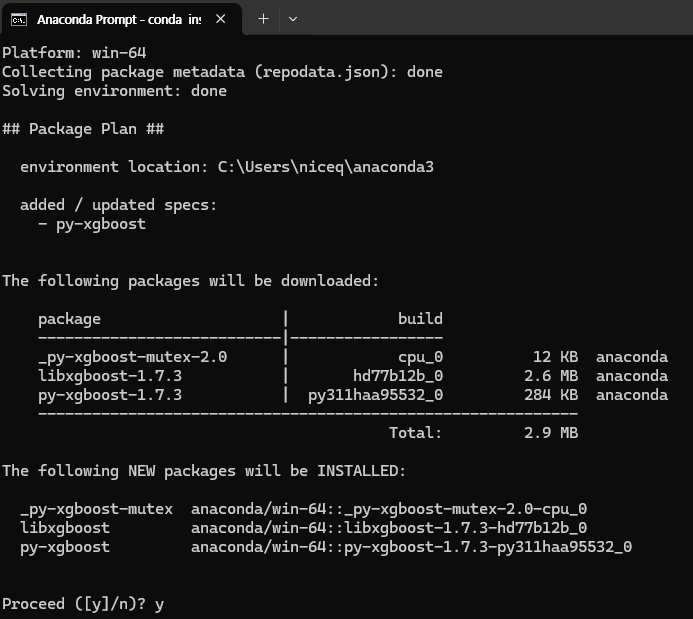
설치 완료 후, 주피터 노트북을 켜고 xgboost 모듈이 정상적으로 import 되는지 확인
# XGBoost
import xgboost as xgb
from xgboost import XGBClassifier※ 'no module named xgboost' 등과 같은 에러 메시지가 나오지 않는다면 설치 완료
XGBoost의 버전은 다음과 같이 확인할 수 있다.
# XGBoost 버전 확인
print(xgb.__version__)
파이썬 래퍼 XGBoost 하이퍼 파라미터
XGBoost는 GBM과 유사한 하이퍼 파라미터를 동일하게 가지고 있으며, 조기 중단(early stopping), 과적합 규제 하이퍼 파리미터 등이 추가되었다.
XGBoost 는 조기 중단 기능이 있어서 n_estimators에 지정한 부스팅 반복 횟수에 도달하지 않더라도 예측 오류가 더 이상 개선되지 않으면 반복을 끝까지 수행하지 않고 중지해 수행 시간을 개선할 수 있다.
[파이썬 래퍼 XGBoost 하이퍼 파라미터 ≠사이킷런 래퍼 XGBoost 하이퍼 파라미터]
- 동일한 기능을 의미하는 하이퍼 파라미터이나, 사이킷런 파라미터의 범용화된 이름 규칙에 따라 파라미터 명이 달라진다.
◆ 유형별 파이썬 래퍼 XGBoost 하이퍼 파라미터
- 일반 파라미터: 일반적으로 실행 시 스레드의 개수나 silent 모드 드으이 선택을 위한 파라미터로서 디폴트 파라미터 값을 바꾸는 경우는 거의 없다
- booster: gbtree(tree based model) 또는 gblinear (linear model) 선택. 디폴트는 gbtree
- silent: 디폴트는 0, 출력 메시지를 나타내고 싶지 않을 경우 1
- nthread: CPU의 실행 스레드 개수를 조정하며, 디폴트는 CPU의 전체 스레드를 다 사용하는 것. 멀티코어/스레드 CPU 시스템에서 전체 CPU를 사용하지 않고 일부 CPU만 사용해 ML 애플리케이션을 구동하는 경우에 변경
- 부스터 파라미터: 트리 최적화, 부스팅, 정규화 규제 등과 관련 파라미터 등을 지칭 (대부분의 하이퍼 파라미터)
- eta [default=0.3, alias:learning_rate]: GBM의 학습률과 같은 파라미터. 파이썬 래퍼 기반의 xgboost 이용 시 디폴트는 0.3, 사이킷런 래퍼 클래스를 이용할 경우 learning_rate 파라미터로 대체(디폴트는 0.1). 보통은 0.1~0.2 사이의 값 선호
- num_boost_rounds: GBM의 n_estimators와 같은 파라미터
- min_child_weight[default=1]: 트리에서 추가적으로 가지를 나눌지를 결정하기 위해 필요한 데이터들의 weight 총합. (클수록 분할을 자제). 과적합을 제지하기 위해 사용
- gamma [default=0, alias: min_split_loss]: 트리의 리프 노드를 추가적으로 나눌지를 결정할 최소 손실 감소 값. 해당 값보다 큰 손실(loss)이 감소된 경우에 리프 노드를 분리. 값이 클수록 과적합 감소 효과 있음.
- max_depth [default=6]: 트리 기반 알고리즘의 max_depth와 동일. 0을 지정하면 깊이에 제한 없음.보통 3~10 사이의 값 선호
- sub_sample [default=1]: GBM의 subsample과 동일. 트리가 커져서 과적합되는 것을 제어하기 위해 데이터를 샘플링하는 비율 지정.일반적으로 0.5~1 사이의 값 선호. (sub_sample=0.5로 지정할 경우, 전체 데이터의 절반을 트리를 생성하는 데 사용)
- clsample_bytree[default=1]: GBM의 max_features와 유사. 트리 생성에 필요한 피처(컬럼)를 임의로 샘플링 하는 데 사용. 매우 많은 피처가 있는 경우 과적합을 조정하는 데 적용.
- lambda [default=1, alias: reg_lambda]: L2 Regularization(Ridge, 릿지) 적용 값. 피처 개수가 많을 경우 적용을 검토하며 값이 클수록 과적합 감소 효과 있음.
- alpha [default=0, alias: reg_alpha]: L1 Regularization(Lasso, 라쏘) 적용 값. 피처 개수가 많을 경우 적용을 검토하며 값이 클수록 과적합 감소 효과 있음.
- scale_pos_weight [default=1]: 특정 값으로 치우친 비대칭한 클래스로 구성된 데이터 세트의 균형을 유지하기 위한 파라미터.
- 학습 태스크 파라미터: 학습 수행 시의 객체 함수, 평가를 위한 지표 등을 설정하는 파라미터
- objective: 최솟값을 가져야 할 손실 함수를 정의. 주로 사용되는 손실함수는 이진 분류인지, 다중 분류인지에 따라 달라짐. (XGBoost는 많은 유형의 손실함수 사용 가능)
- binary:logistic: 이진 분류일 때 적용
- multi:softmax: 다중 분류일 때 적용. 손실함수가 multi:softmax 일 경우, 레이블 클래스의 개수인 num_class 파라미터를 지정해야 함
- multi:softprob: multi:softmax 와 유사하나, 개별 레이블 클래스의 해당되는 예측 확률을 반환
- eval_metric: 검증에 사용되는 함수 정의. 기본값은 회귀인 경우 rmse, 분류일 경우 error
< eval_metric의 값 유형>
| rmse | Root Mean Sqaure Error |
| mae | Mean Absolute Error |
| logloss | Negative log-likelihood |
| error | Binary classification error rate(0.5 threshold) |
| merror | Multiclass classification error rate |
| mlogloss | Multiclass logloss |
| auc | Area under the curve |
▶ 뛰어난 알고리즘 일수록 파라미터를 튜닝할 필요가 적다. 피처의 수가 많거나, 피처 간 상관되는 정도가 많거나 데이터 세트에 따라 파라미터를 튜닝하게 된다.
만약, 과적합 문제가 심각할 경우, 아래의 방법을 적용해볼 수 있다.
- eta 값을 낮춘다 (0.01 ~ 0.1) > 낮출 경우 num_round 또는 n_estimators는 반대로 높여줘야 한다
- max_depth 값을 낮춘다
- min_child_weight 값을 높인다
- gamma 값을 높인다
- subsample과 colsample_bytree를 조정하는 것도 트리가 너무 복잡하게 생성되는 것을 막아 과적합 문제에 도움
다음 글
[파이썬] 분류 > 앙상블 - 4 : XG Boost (2)
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.앙상블 학습(Ensemble Learning) [
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 앙상블 : XG Boost (3) (0) | 2024.07.04 |
|---|---|
| [머신러닝] 앙상블: XG Boost (2) (0) | 2024.07.01 |
| [머신러닝] 앙상블 : GBM (0) | 2024.06.30 |
| [머신러닝] 앙상블 : 랜덤 포레스트 (0) | 2024.06.27 |
| [머신러닝] 앙상블 학습(Ensemble Learning) (0) | 2024.06.27 |



