시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
캐글 신용카드 사기 검출
Kaggle의 신용카드 데이터 세트를 이용한 신용카드 사기 검출 분류 실습
데이터 다운로드
하단의 사이트(캐글)에 들어가서 로그인 후 'creditcard.csv' 파일 다운로드
(캐글 경연 규칙 준수 화면으로 이동하면 해당 규칙 준수에 동의하면 다운로드 실행)
https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
Credit Card Fraud Detection
Anonymized credit card transactions labeled as fraudulent or genuine
www.kaggle.com

다운로드 한 파일의 압축을 풀어 csv파일을 ML을 수행하고자 하는 디렉터리에 옮겨놓는다.
기본 모듈 로딩 및 데이터 로딩
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
card_df = pd.read_csv("C:/Users/niceq/Documents/DataScience/Python ML Guide/Data/04. creditcard.csv")
card_df.head()
데이터 개요
print(card_df['Class'].value_counts())
fraud_cnt = card_df[card_df['Class'] == 1].Class.count()
total_cnt = card_df.Class.count()
print('fraud 비율은 {0:.5f}'.format((fraud_cnt / total_cnt)))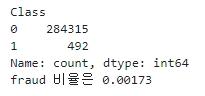
▶ 해당 데이터 세트의 레이블인 Class 속성은 매우 불균형한 분포를 가지고 있다. Class는 0과 1로 분류되는데 0이 사기가 아닌 정상적인 신용카드 트랜잭션 데이터, 1은 신용카드 사기 트랜잭션을 의미한다. 전체 데이터의 약 0.173%만이 레이블 값이 1인 사기 트랜잭션이다.
앞서 DataFrame으로 로딩한 creidtcard.csv 파일의 피처들을 살펴보면,
- V로 시작하는 피처들의 의미는 알 수가 없다
- Time 피처의 경우는 데이터 생성 관련한 작업용 속성 (제거 예정)
- Amount 피처는 신용카드 트랜잭션 금액
- Class 는 레이블로서 0은 정상, 1은 사기 트랜잭션
card_df.info()
▶ 전체 284,807 개 레코드에서 결측치는 없으며 Class 레이블만 int형이고, 나머지 피처들은 모두 float형이다.
언더 샘플링과 오버 샘플링의 이해
레이블이 불균형한 분포를 가진 데이터 세트를 학습시킬 때 예측 성능의 문제가 발생할 수 있는데, 이는 이상 레이블을 가지는 데이터 건수가 정상 레이블을 가진 데이터 건수에 비해 너무 적기 때문에 발생한다.
즉, 이상 레이블을 가진 데이터 건수는 매우 적기 때문에 제대로 다양한 유형을 학습하지 못하는 반면, 정상 레이블을 가지는 데이터 건수는 매우 많기 때문에 일방적으로 정상 레이블로 치우친 학습을 수행해 제대로 도니 이상 데이터 검출이 어려워지기 쉽다.
지도학습에서 극도로 불균형한 레이블 값 분포로 인한 문제점을 해결하기 위해서는 적절한 학습 데이터를 확보하는 방안이 필요한데, 대표적으로 오버 샘플링(Oversampling)과 언더 샘플링(Undersampling) 방법이 있으며, 오버 샘플링 방식이 예측 성능상 조금 유리한 경우가 많아 상대적으로 더 많이 사용된다.
특히, 대표적으로 SMOTE(Synthetic Minority Over-sampling Technique) 방법이 있는데,
SMOTE는 적은 데이터 세트에 있는 개별 데이터들의 K 최근접 이웃을 찾아서 이 데이터와 K개 이웃들의 차이를 일정 값으로 만들어서 기존 데이터와 약간 차이가 나는 새로운 데이터들을 생성하는 방식이다.
[오버 샘플링과 언더 샘플링]
- 오버 샘플링: 적은 레이블을 가진 데이터 세트를 많은 레이블을 가진 데이터 세트 수준으로 증식. 동일한 데이터를 단순히 증식하는 방식은 과적합이 되기 때문에 의미가 없으므로 원본 데이터의 피처 값들을 아주 약간만 변경하여 증식.
- 언더 샘플링: 많은 레이블을 가진 데이터 세트를 적은 레이블을 가진 데이터 세트 수준으로 감소. 정상 레이블 데이터를 이상 레이블 데이터 수준으로 줄여 버린 상태에서 학습을 수행하면 과도하게 정상 레이블로 학습/예측 하는 부작용을 개선할 수 있지만, 너무 많은 정상 레이블 데이터를 감소시켜 정상 레이블의 경우 제대로된 학습을 수행할 수 없는 문제가 발생할 수 있으므로 유의.
◆ SMOTE를 대표적으로 구현한 파이썬 패키지는 imbalanced-learn 이며, 이는 아나콘다를 이용해 설치가 가능하다.
아나콘다 프롬프트를 관리자 권한으로 실행하고 하단의 명령어를 입력하면 자동으로 설치된다.
conda install -c conda-forge imbalanced-learn
데이터 일차 가공 및 모델 학습/예측/평가
보다 다양한 데이터 사전 가공과 이에 따른 예측 성능 비교를 위해 인자로 입력된 DataFrame을 복사한 뒤, 이를 가공하여 반환하는 get_preprocessed_df() 함수와 데이터 가공 후 학습/테스트 데이터 세트를 반환하는 get_train_test_dataset() 함수를 생성.
# get_preprocessed_df 함수 생성
from sklearn.model_selection import train_test_split
# 인자로 입력받은 DF 복사 후 Time 칼럼만 삭제하고 복사된 DF 반환
def get_preprocessed_df(df=None):
df_copy = df.copy()
df_copy.drop('Time', axis=1, inplace=True)
return df_copy
get_train_test_dataset() 함수는 get_preprocessed_df() 를 호출한 뒤 학습 피처/레이블 데이터 세트, 테스트 피처/레이블 데이터 세트를 반환한다. 해당 함수는 내부에서 train_test_split() 함수를 호출하며, 테스트 데이터 세트를 전체의 30%인 Stratified 방식으로 추출해 학습 데이터 세트와 테스트 데이터 세트의 레이블 값 분포도를 서로 동일하게 만든다.
# get_train_test_dataset() 함수 생성
# 사전 데이터 가공 후 학습과 테스트 데이터 세트를 반환하는 함수
def get_train_test_dataset(df=None):
# 인자로 입력된 DF의 사전 데이터 가공이 완료된 복사 DF 반환
df_copy = get_preprocessed_df(df)
# DF의 맨 마지막 칼럼이 레이블, 나머지는 피처들
X_features = df_copy.iloc[:, :-1]
y_target = df_copy.iloc[:, -1]
# train_test_split()으로 학습과 테스트 데이터 분할. stratify=y_target으로 Stratified 기반 분할
X_train, X_test, y_train, y_test = \
train_test_split(X_features, y_target, test_size=0.3, random_state=0, stratify=y_target)
# 학습과 테스트 데이터 세트 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
생성한 학습 데이터 세트와 테스트 데이터 세트의 레이블 값 비율을 백분율로 환산해서 서로 비슷하게 분할됐는지 확인.
print('학습 데이터 레이블 값 비율')
print(y_train.value_counts()/y_train.shape[0] * 100)
print('테스트 데이터 레이블 값 비율')
print(y_test.value_counts() / y_test.shape[0] * 100)
▶ 학습 데이터 레이블의 경우 1값이 약 0.172%, 테스트 데이터 레이블의 경우 1값이 약 0.173%로 큰 차이 없이 잘 분할되었다.
◆ 로지스틱 회귀와 LightGBM 기반의 모델을 통한 예측 성능 파악
[로지스틱 회귀를 이용한 신용 카드 사기 여부 예측]
먼저 get_clf_eval() 함수 생성
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix, roc_auc_score, f1_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, pred)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC: {4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter=1000)
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
lr_pred_proba = lr_clf.predict_proba(X_test)[:, 1]
# get_clf_eval () 함수 이용해 평가 수행
get_clf_eval(y_test, lr_pred, lr_pred_proba)
▶ 테스트 데이터 세트로 측정 시 재현율 0.6149, ROC-AUC가 0.9723
[LightGBM을 이용한 신용 카드 사기 여부 예측]
LightGBM 모델을 만들기에 앞서, 반복적으로 모델을 변경해 학습/예측/평가하기 위해 get_model_train_eval() 함수 생성.
인자로 사이킷런의 Estimator 객체와 학습/테스트 데이터 세트를 입력받아서 학습/예측/평가 수행.
# get_model_train_eval() 함수 생성
# 인자로 사이킷런 Estimator 객체와 학습/테스트 데이터 세트를 입력받아 학습/예측/평가 수행
def get_model_train_eval(model, ftr_train=None, ftr_test=None, tgt_train=None, tgt_test=None):
model.fit(ftr_train, tgt_train)
pred = model.predict(ftr_test)
pred_proba = model.predict_proba(ftr_test)[:, 1]
get_clf_eval(tgt_test, pred, pred_proba)※ 본 데이터 세트는 극도로 불균형한 레이블 값을 분포도를 가지고 있으므로 LGBMClassifier 객체 생성 시 boost_from_average=False 로 파라미터를 설정해야 한다.
LightGBM이 버전업 되면서 기본값이 False에서 True로 바뀌어 레이블 값이 극도로 불균형한 분포를 이루는 경우 True 설정은 재현률 및 ROC-AUC 성능을 매우 크게 저하시킨다.
따라서, LGBMClassifier 객체 생성 시 boost_from_average=False 로 파라미터를 설정해야 한다.
LightGBM으로 모델을 학습한 뒤, 별도의 테스트 데이터 세트에서 예측 평가 수행
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1, boost_from_average=False)
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
▶ 재현율 0.7568, ROC-AUC 0.9790으로 로지스틱 회귀보다 높은 수치를 나타낸다.
데이터 분포도 변환 후 모델 학습/예측/평가가
왜곡된 분포도를 가지는 데이터를 재가공 후 모델을 다시 테스트.
◆ creditcard.csv 파일의 중요 피처 값의 분포도를 파악
로지스틱 회귀는 선형 모델이며, 대부분의 선형 모델은 중요 피처들의 값이 정규 분포 형태를 유지하는 것을 선호한다.
Amount 피처는 시뇽 카드 사용 금액으로 정상/사기 트랜잭션을 결정하는 매우 중요한 속성일 가능성이 높으므로, 해당 피처의 분포도를 확인한다.
# Amount 피처 중요 분포도 파악
import seaborn as sns
plt.figure(figsize=(8, 4))
plt.xticks(range(0, 30000, 1000), rotation=60)
sns.histplot(card_df['Amount'], bins=100, kde=True)
plt.show()<주요 코드 설명>
이 코드는 Amount 데이터의 분포를 히스토그램과 커널 밀도 추정을 통해 시각화하여 데이터를 더 잘 이해할 수 있도록 도움.
- plt.figure(figsize=(8, 4)) : 그림의 크기를 가로 8인치, 세로 4인치로 설정.
- plt.xticks(range(0, 30000, 1000), rotation=60): x축의 눈금을 0에서 30000까지 1000 단위로 설정하고, 눈금 레이블을 60도 회전
- sns.histplot(card_df['Amount'], bins=100, kde=True): card_df 데이터프레임의 Amount 열에 대한 히스토그램 생성. bins=100은 데이터를 100개의 구간으로 나누고, kde=True는 커널 밀도 추정을 추가하여 데이터의 분포를 부드러운 곡선으로 표시.
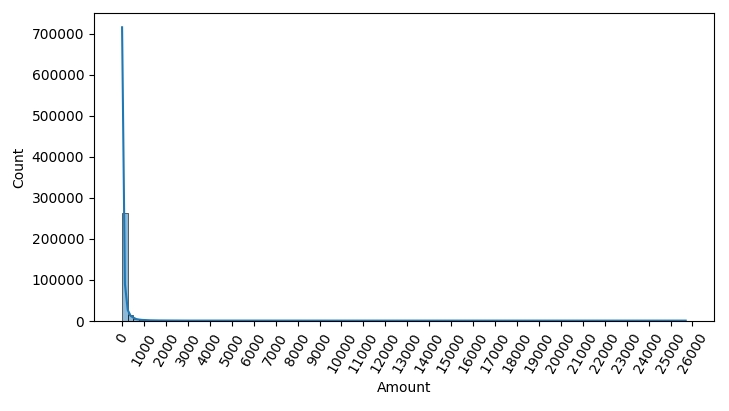
▶ 카드 사용금액이 1000불 이하인 데이터가 대부분이며,
26,000불까지 드물지만 많은 금액을 사용한 경우가 발생하면서 꼬리가 긴 형태의 분포 곡선을 가지고 있다.
◆ Amount를 표준 정규 분포 형태로 변환 후 로지스틱 회귀 예측 성능 측정
앞에서 만든 get_preprossed_df() 함수를 사이킷런의 StandardScaler 클래스를 이용해 Amount 피처를 정규 분포 형태로 변환하는 코드로 변경
from sklearn.preprocessing import StandardScaler
# 사이킷런의 StandardScaler를 이용해 정규 분포 형태로 Amount 피처값 변환하는 로직으로 수정
def get_preprocessed_df(df=None):
df_copy = df.copy()
scaler = StandardScaler()
amount_n = scaler.fit_tranform(df_copy['Amount'].values.reshape(-1, 1))
# 변환된 Amount를 Amount_Scaled로 피처명 변경후 DF 맨 앞 칼럼으로 입력
df_copy.insert(0, 'Amount_Scaled', amount_n)
# 기존 Time, Amount 피처 삭제
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
return df_copy
함수 수정 후 get_train_dataset()를 호출해 학습/테스트 데이터 세트를 생성한 후에 get_model_train_eval()을 이용해 로지스틱 회귀와 LightGBM 모델을 각각 학습/예측/평가.
# Amount를 정규 분포 형태로 변환 후 로지스틱 회귀와 LGBM 수행
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
lr_clf = LogisticRegression()
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1, boost_from_average=False)
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)

▶ 정규 분포 형태로 Amount 피처값을 변환한 후 테스트 데이터 세트에 적용한
로지스틱 회귀의 경우 - 정밀도와 재현율 저하
LightGBM의 경우 - 정밀도와 재현율이 저하되었지만 큰 성능상의 변경은 없음
◆ 로그 변환 수행
로그 변환은 데이터 분포도가 심하게 왜곡되어 있을 경우 적용하는 중요 기법 중 하나인데, 원래 값을 log 값으로 변환해 원래 큰 값을 상대적으로 작은 값으로 변환하기 때문에 데이터 분포도의 왜곡을 상당 수준 개선.
로그 변환은 Numpy의 log1p() 함수를 이용해 간단히 변환이 가능하다.
# 로그 변환
def get_preprocessed_df(df=None):
df_copy = df.copy()
# 넘파이의 log1p()를 이용해 Amount를 로그 변환
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
# 기존 Time, Amount 피처 삭제
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
return df_copy
Amount 피처를 로그 변환 후 다시 로지스틱 회귀와 LightGBM 모델 적용 한 뒤 예측 성능 확인
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)

▶ 로지스틱 회귀의 경우 - 원본 대비 정밀도 향상, 재현율 저하
LightGBM의 경우 - 재현율 향상
※ 레이블이 극도로 불균일한 데이터 세트에서 로지스틱 회귀는 데이터 변환 시 약간은 불안정한 성능 결과 보여줌.
이상치 데이터 제거 후 모델 학습/예측/평가
◆ 이상치 데이터와 박스 플롯 개요
이상치 데이터(Outlier): 전체 데이터의 패턴에서 벗어난 이상 값을 가진 데이터. 머신러닝 모델의 성능에 영향을 줄 수 있음.
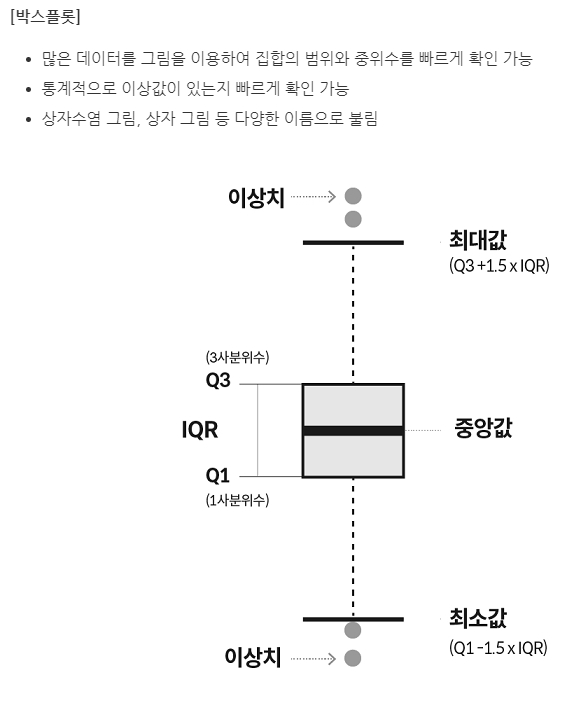
IQR(Inter Quantile Range) 방식을 적용하여 이상치를 찾는다.
IQR은 사분위 값의 편차를 이용하는 기법으로 흔히 박스 플롯 방식으로 시각화할 수 있다.
※ 사분위: 전체 데이터를 값이 높은 순으로 정렬하고, 이를 1/4(25%)씩으로 구간을 분할하는 것을 지칭한다.
IQR은 25% 구간인 Q1, 75% 구간인 Q3의 범위를 뜻한다.
IQR을 이용해 이상치 데이터를 검출하는 방식은 보통 IQR에 1.5를 곱해서 생성된 범위를 이용해 최댓값과 최솟값을 결정한 뒤 최댓값을 초과하거나 최솟값에 미달하는 데이터를 이상치로 간주하는 것이다.
Q3에 IQR*1.5를 더해 최댓값을, Q1에 IQR*1.5를 빼서 최솟값으로 가정한다. (1.5가 아닌 다른 값을 적용할 수 있다)
IQR 방식을 시각화한 도표가 박스 플롯이다.
◆ IQR을 이용한 이상치 데이터 제거
먼저 어떤 피처의 이상치 데이터를 검출할 것인지에 대한 선택이 필요하다.
매우 많은 피처가 있을 경우 이들 중 결정값과 가장 상관성이 높은 피처들을 위주로 이상치를 검출하는 것이 좋다.
DataFrame의 corr()을 이용해 각 피처별로 상관도를 구한 뒤 Seaborn의 heatmap을 통해 시각화를 해본다.
import seaborn as sns
plt.figure(figsize=(9, 9))
corr = card_df.corr()
sns.heatmap(corr, cmap='RdBu')※ 상관관계 히트맵에서 cmap을 RdBu로 설정해 양의 상관관계가 높을수록 색깔이 진한 파란색에 가까우며, 음의 상관관계가 높을수록 색깔이 진한 빨간색에 가깝게 표현된다.
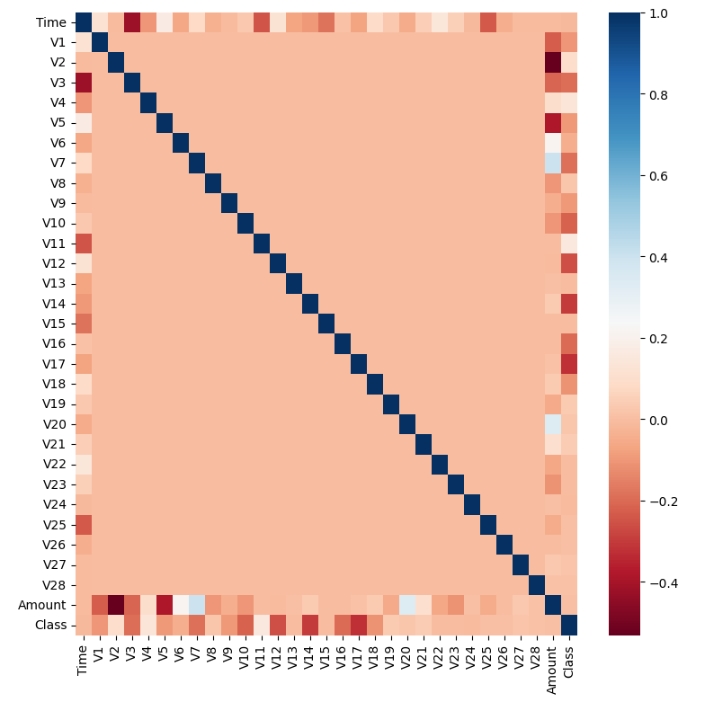
▶ 상관관계 히트맵에서 맨 아래에 위치한 결정 레이블인 Class 피처와 음의 상관관계가 가장 높은 피처는 V14, V17
◆ 이상치 파악하여 제거(V14 피처 중)
IQR을 이용해 이상치를 검출하는 함수를 생성한 뒤, 이를 이용해 검출된 이상치를 삭제.
get_outlier() 함수는 인자로 DataFrame과 이상치를 검출한 칼럼을 입력받는다.
함수 내에서 넘파이의 percentile()을 이용해 1/4분위와 3/4분위를 구하고, 이에 기반해 IQR을 계산한다.
계산된 IQR에 1.5를 곱해서 최댓값과 최솟값 지점을 구한 뒤, 최댓값보다 크거나 최솟값보다 작은 값을 이상치로 설정하고 해당 이상치가 있는 DataFrame Index를 반환한다.
import numpy as np
def get_outlier(df=None, column=None, weight=1.5):
# 사기에 해당하는 column 데이터만 추출, 1/4분위와 3/4분위 지점을 구함(np.percentile)
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
# IQR을 구하고, IQR에 1.5를 곱해 최댓값, 최솟값 지점 구함
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight #1.5
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
#최댓값보다 크거나, 최솟값보다 작은 값 = 이상치, DF 반환
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_index
get_outlier() 함수를 이용해 V14 칼럼에서 이상치 데이터 추출.
outlier_index = get_outlier(df=card_df, column='V14', weight=1.5)
print('이상치 인덱스:', outlier_index)
▶ 총 4개의 데이터 8296, 8615, 9035, 9252 번 인덱스가 이상치 데이터로 추출되었다.
get_outlier() 를 이용해 이상치를 추출하고 이를 삭제하는 로직을 get_preprocessed_df() 함수에 추가해 데이터를 가공한 뒤 이 데이터 세트를 이용해 로지스틱 회귀와 LightGBM 모델을 다시 적용.
# get_preprocessed_df()를 로그 변환 후 V14 피처의 이상치 데이터를 삭제하는 로직으로 변경
def get_preprocessed_df(df=None):
df_copy = df.copy()
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
return df_copy
# 이상치 데이터 삭제하는 로직 추가
outlier_index = get_outlier(df=card_df, column='V14', weight=1.5)
df_copy.drop(outlier_index, axis=0, inplace=True)
return df_copy
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)

▶ 이상치를 제거한 뒤, 두 모델 모두 예측 성능이 크게 향상되었다.
SMOTE 오버 샘플링 적용 후 모델 학습/예측/평가
SMOTE는 앞서 설치한 imbalanced-learn 패키지의 SMOTE 클래스를 이용해 간단하게 구현이 가능하다.
SMOTE를 적용할 때는 반드시 학습 데이터 세트만 오버 샘플링을 해야 한다. 만약 검증 데이터 세트나 테스트 데이터 세트를 오버 샘플링할 경우 결국은 원본 데이터 세트가 아닌 데이터 세트에서 검증 또는 테스트를 수행하기 때문에 올바른 검증/테스트가 될 수 없다.
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)
print('SMOTE 적용 전 학습용 피처/레이블 데이터 세트:', X_train.shape, y_train.shape)
print('SMOTE 적용 후 학습용 피처/레이블 데이터 세트:', X_train_over.shape, y_train_over.shape)
print('SMOTE 적용 후 레이블 값 분포: \n', pd.Series(y_train_over).value_counts())
▶ SMOTE 적용 후, 적용 전의 학습 데이터 세트에 비해 약 2배 가까운 데이터로 증식되었고, 레이블 값이 0과 1의 분포가 동일하게 199,020 건으로 생성되었다.
◆ 학습된 데이터 세트를 기반으로 로지스틱 회귀 모델 학습
lr_clf = LogisticRegression(max_iter=1000)
# ftr_train과 tgt_train 인자값이 SMOTE 증식된 X_train_over와 y_train_over로 변경
get_model_train_eval(lr_clf, ftr_train=X_train_over, ftr_test=X_test, tgt_train=y_train_over, tgt_test=y_test)
▶ SMOTE 로 오버 샘플링된 데이터로 학습할 경우 재현율이 89.86%로 크게 증가하나, 정밀도가 6.32%로 급격하게 저하된다. (저조한 정밀도는 현실 업무에 적용할 수 없다)
이는 로지스틱 회귀 모델이 오버 샘플링으로 인해 실제 원본 데이터의 유형보다 너무나 많은 Class=1 데이터를 학습하면서 실제 데이터 세트에서 예측을 지나치게 Class=1로 적용해 정밀도가 급격히 떨어진 것이다.
분류 결정 임곗값에 따른 정밀도와 재현율 곡선을 통해 SMOTE로 학습된 로지스틱 회귀 모델에 어떠한 문제가 발생하고 있는지 시각적으로 확인해 본다.
먼저 precision_recall_curve_plot() 함수를 생성하고
# 정밀도와 재현율 곡선 시각화
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
from sklearn.metrics import precision_recall_curve
def precision_recall_curve_plot(y_test, pred_proba_c1):
# threshold ndarray와 이 threshold에 따른 정밀도, 재현율 ndarray 추출
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_c1)
# X축을 threshold 값으로, Y축은 정밀도, 재현율 값으로 각각 Plot 수행. 정밀도는 점선으로 표시
plt.figure(figsize=(8, 6))
threshold_boundary = thresholds.shape[0]
plt.plot(thresholds, precisions[0:threshold_boundary], linestyle='--', label='precision')
plt.plot(thresholds, recalls[0:threshold_boundary], label='recall')
# threshold 값 X축의 Scale을 0.1 단위로 변경
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
# X축, y축 label과 legend, 그리고 grid 설정
plt.xlabel('Threshold value'); plt.ylabel('Precision and Recall value')
plt.legend(); plt.grid()
plt.show()precision_recall_curve_plot(y_test, lr_clf.predict_proba(X_test)[:, 1])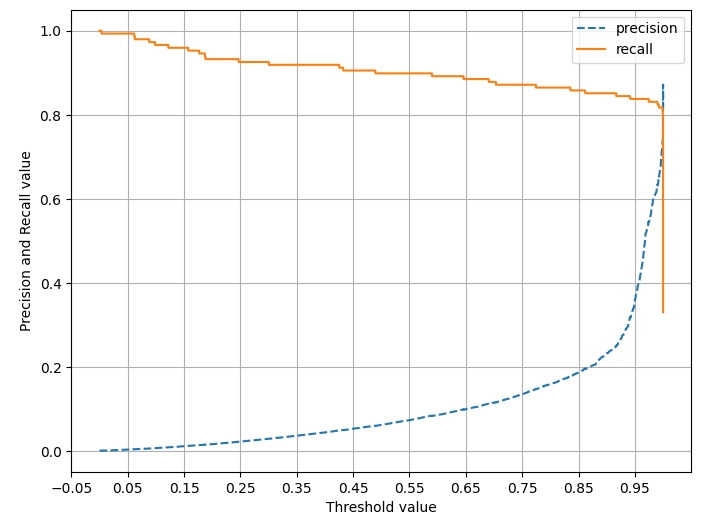
▶ 임곗값이 9.99 이하에서는 재현율이 매우 좋고, 정밀도가 극단적으로 낮다가 0.99 이상에서는 재현율이 대폭 떨어지고 정밀도가 높아진다. 따라서, 로지스틱 회귀 모델의 경우 SMOTE 적용 후 올바른 에측 모델이 생성되지 못했다.
◆ 학습된 데이터를 기반으로 LightGBM 모델 학습
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1, boost_from_average=False)
get_model_train_eval(lgbm_clf, ftr_train=X_train_over, ftr_test=X_test, tgt_train=y_train_over, tgt_test=y_test)
교재 상에는 SMOTE를 적용하면 재현율은 높아지나, 정밀도를 낮아지는 것이 일반적이라고 되어있는데,현재 내 결과는 정밀도와 재현율 모두 낮아졌다... 0_0(머신러닝 모델의 주요한 목표가 정밀도 지표보다는 재현율 지표를 높이는 것일 경우 SMOTE를 적용하면 좋다.)
전체 코드
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 머신러닝에 적합한 도구, Pytorch 설치하기(CPU버전) (1) | 2024.09.08 |
|---|---|
| [머신러닝] 차원의 저주(Curse of Dimensionality)란? (1) | 2024.09.03 |
| [머신러닝] 분류 - 캐글 산탄데르 고객 만족 예측 (0) | 2024.07.07 |
| [머신러닝] 분류 - 베이지안 최적화 (2) (0) | 2024.07.07 |
| [머신러닝] 분류 - 베이지안 최적화 (1) (0) | 2024.07.07 |



