텍스트 분석이란?
[머신러닝] 텍스트 분석
이전 내용 [머신러닝] 군집화 (Clustering)군집화(Clustering) [군집]군집은 비슷한 샘플을 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업으로, 데이터 분석, 고객 분류, 추천 시스템, 검색 엔
puppy-foot-it.tistory.com
이전 내용
[머신러닝] 텍스트 분석: 토픽 모델링
텍스트 분석이란? [머신러닝] 텍스트 분석이전 내용 [머신러닝] 군집화 (Clustering)군집화(Clustering) [군집]군집은 비슷한 샘플을 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업으로, 데이
puppy-foot-it.tistory.com
문서 군집화(Document Clustering)
◆ 문서 군집화:
비슷한 텍스트 구성의 문서를 군집화하는 것. 문서 군집화는 동일한 군집에 속하는 문서를 같은 카테고리 소속으로 분류할 수 있으므로 텍스트 분류 기반의 문서 분류와 유사하지만, 텍스트 분류 기반의 문서 분류는 사전에 결정 카테고리 값을 가진 학습 데이터 세트가 필요한 데 반해, 문서 군집화는 학습 데이터 세트가 필요 없는 비지도학습 기반으로 동작한다.
Opinion Review 데이터 세트를 이용한 문서 군집화
하단의 링크 (UCI Machine Learning Repository)에 접속하여 해당 데이터 세트를 다운로드한다.
UCI Machine Learning Repository
This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license. This allows for the sharing and adaptation of the datasets for any purpose, provided that the appropriate credit is given.
archive.ics.uci.edu

이 데이터 세트에는 주어진 주제에 대한 사용자 리뷰에서 추출한 문장이 포함되어 있다. 예시 주제는 "Toyota Camry의 성능"과 "ipod nano의 음질" 등입니다. 총 51개의 주제가 있으며 각 주제는 약 100개의 문장(평균)을 가지고 있다. 리뷰는 Tripadvisor(호텔), Edmunds.com(자동차), Amazon.com(다양한 전자 제품) 등 다양한 출처에서 얻었다. 데이터 세트 파일에는 Opinosis 요약 논문에 사용된 골드 스탠다드 요약도 함께 제공된다.
다운로드 받은 압축 파일을 압축 해제하면 하단의 폴더 리스트가 보이며,

이중 'topics' 디렉터리 안에 51개의 파일로 구성되어 있다.

해당 파일들은 다양한 전자 제품과 호텔 서비스 등에 대한 리뷰 내용을 담고 있으며, 이번 실습에서는 여러 개의 파일을 한 개의 DataFrame으로 로딩해 데이터 처리를 할 예정이다.
[디렉터리 내의 파일을 DataFrame으로 로드하여 리뷰 확인]
여러 개의 파일을 DataFrame으로 로딩하는 로직
- 해당 디렉터리 내의 모든 파일에 대해 각각 for 반복문으로 반복하면서 개별 파일명을 파일명 리스트에 추가
- 개별 파일은 DataFrame으로 읽은 후 다시 문자열로 반환한 뒤 파일 내용 리스트에 추가
- 파일명 리스트와 파일 내용 리스트를 이용해 새롭게 파일명과 파일 내용을 칼럼으로 가지는 DataFrame 생성
import pandas as pd
import glob, os
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', 700)
path = r"C:/Users/niceq/Documents/DataScience/Python ML Guide/Data/OpinosisDataset1.0/topics"
# path로 지정한 디렉터리 밑에 있는 모든 .data 파일들의 파일명을 리스트로 취합
all_files = glob.glob(os.path.join(path, "*.data"))
filename_list = []
opinion_text = []
# 개별 파일들의 파일명은 filename_list 로 취합
# 개별 파일들의 파일 내용은 DataFrame 로딩 후 다시 String으로 변환하여 opnion_text 리스트로 취합
for file_ in all_files:
# 개별 파일을 읽어서 DataFrame으로 생성
df = pd.read_table(file_, index_col=None, header=0, encoding='latin1')
#절대 경로로 주어진 파일명 가공. 확장자(.data) 제거
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
# 파일명 리스트와 파일 내용 리스트에 파일명과 파일 내용 추가
filename_list.append(filename)
opinion_text.append(df.to_string())
# 파일명 리스트와 파일 내용 리스트를 DataFrame으로 생성
document_df = pd.DataFrame({'filename':filename_list, 'opinion_text':opinion_text})
document_df.head()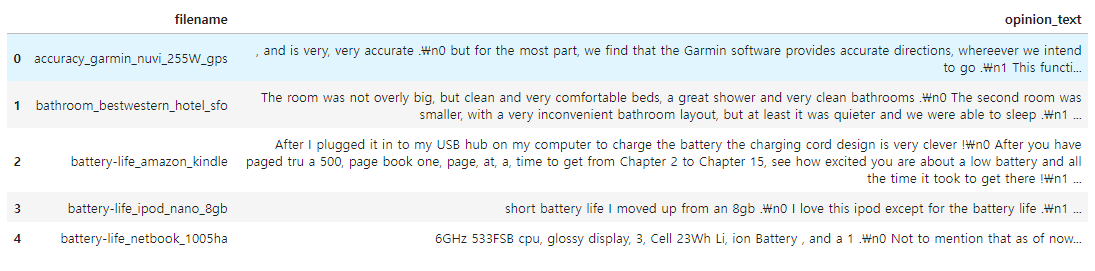
▶ 각 파일 이름을 토대로 어떠한 제품/서비스에 대한 리뷰인지 알 수 있다.
[문서를 TF-IDF 형태로 피처 벡터화]
TfidfVectorizer는 Lemmatization 같은 어근 변환을 직접 지원하진 않으나, tokenizer 인자에 커스텀 어근 변환 함수를 적용해 어근 변환을 수행할 수 있다. 이를 위해 LemNormalize() 함수를 만든다.
from nltk.stem import WordNetLemmatizer
import nltk
import string
# 단어 원형 추출 함수
lemmar = WordNetLemmatizer()
def LemTokens(tokens):
return [lemmar.lemmatize(token) for token in tokens]
# 특수 문자 사전 생성: {33: None ...}
# ord(): 아스키 코드 생성
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
# 특수 문자 제거 및 단어 원형 추출
def LemNormalize(text):
# 텍스트 소문자 변경 후 특수 문자 제거
text_new = text.lower().translate(remove_punct_dict)
# 단어 토큰화
word_tokens = nltk.word_tokenize(text_new)
# 단어 원형 추출
return LemTokens(word_tokens)
LemNormalize() 함수를 생성하고 어근변환을 수행한다.
ngram은 (1,2)로 하고, min_df와 max_df를 설정해 피처의 개수를 제한한다.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english',
ngram_range=(1,2), min_df=0.05, max_df=0.85)
# opinion_text 칼럼값으로 feature vectorization 수행
feature_vect = tfidf_vect.fit_transform(document_df['opinion_text'])
[변환된 피처 벡터화 행렬 데이터에 군집화 수행]
문서별 텍스트가 TF-IDF 변환된 피처 벡터화 행렬 데이터에 대해서 군집화를 수행해 어떤 문서끼리 군집되는지 K-평균 기법을 적용하여 확인해 본다.
먼저 5개의 중심(Centroid) 기반으로 어떻게 군집화되는지 확인해 보는데, 최대 반복 횟수 max_iter는 10000으로 설정한다.
KMeans를 수행한 후 군집의 Label 값과 중심별로 할당된 데이터 세트의 좌표 값을 구한다.
from sklearn.cluster import KMeans
# 5개 집합으로 군집화 수행.
km_cluster = KMeans(n_clusters=5, max_iter=10000, random_state=0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
cluster_centers = km_cluster.cluster_centers_
각 데이터별로 할당된 군집의 레이블을 파일명과 파일 내용을 가지고 있는 document_df DataFrame에 'cluster_label' 칼럼을 추가해 저장하고, 군집이 각 주제별로 유사한 형태로 잘 구성됐는지 확인한다.
document_df['cluster_label'] = cluster_label
document_df.head()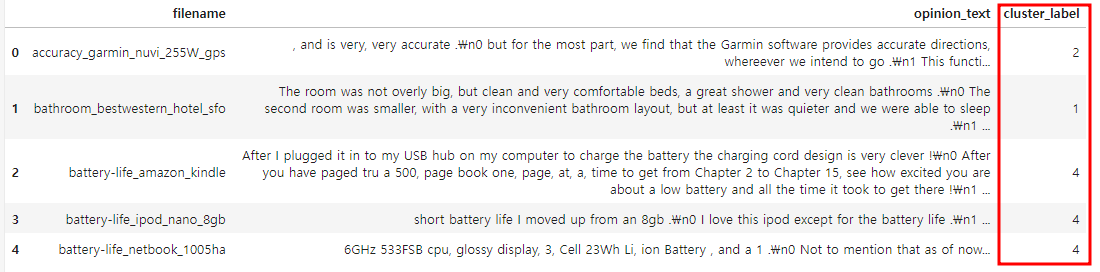
[데이터 정렬 후 cluster_label 별 데이터 확인]
판다스 DataFrame의 sort_values(by=정렬칼럼명)를 수행하면 인자로 입력된 '정렬칼럼명'으로 데이터를 정렬할 수 있다.
cluster_label로 어떤 파일명으로 매칭됐는지 보면서 각 cluster_label 별 군집화 결과를 확인해 본다.
◆ Cluster #0
document_df[document_df['cluster_label']==0].sort_values(by='filename')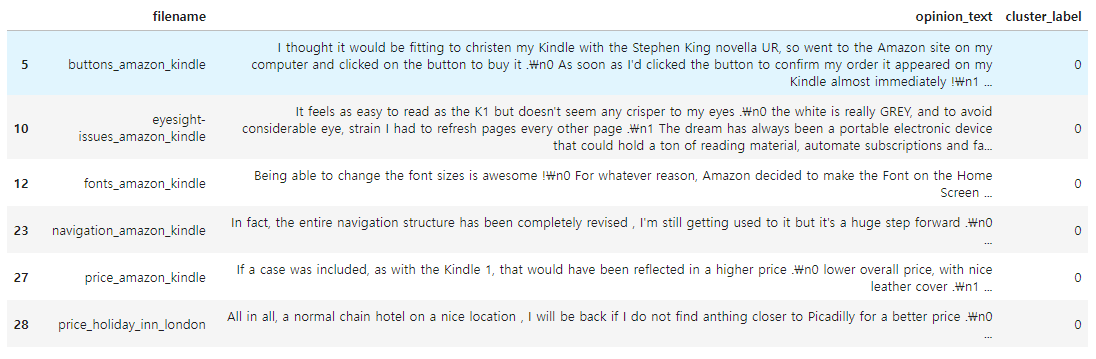
▶ 호텔과 킨들에 대한 리뷰로 군집화되어 있다.
나머지 clsuter_label도 확인해 본다. (코드는 '['cluster_label']==숫자 만 label에 맞게 바꿔주면 되므로 생략)
◆ Cluster #1
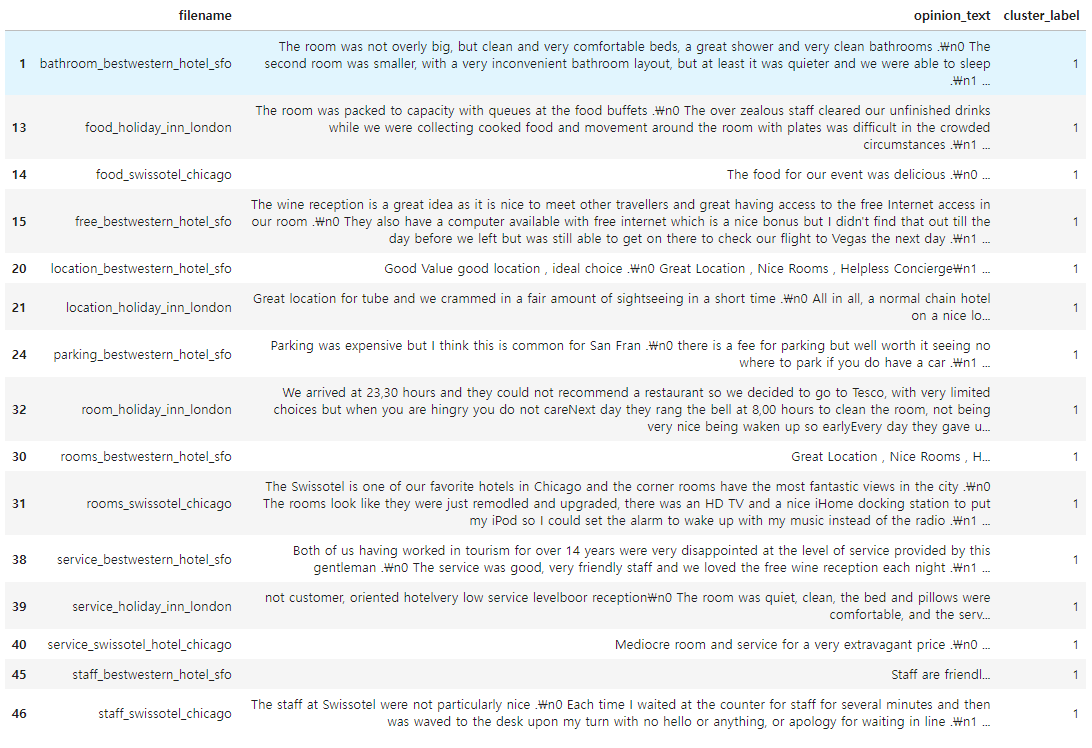
▶ 호텔에 대한 리뷰로 군집화 되어 있다.
◆ Cluster #2

▶ 차량용 네비게이션, 아이팟, 노트북 등에 대한 리뷰로 군집화 되어 있다.
◆ Cluster #3

▶ 토요타, 혼다와 같은 차량에 대한 리뷰로 군집화 되어 있다.
◆ Cluster #4
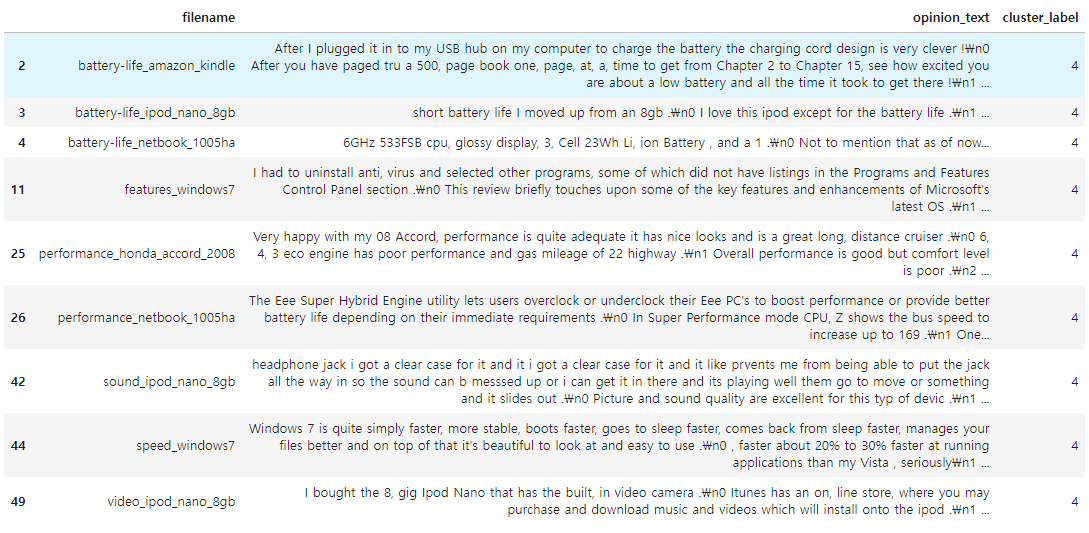
▶ 혼다 어코드에 대한 리뷰가 하나 있긴 하나, 대부분 배터리, 아이팟 등의 포터블 전자기기 및 구성요소(배터리 등)에 대한 리뷰로 군집화 되어 있다.
전반적인 군집화 결과는 보다 정확하지 못하여, 군집개수를 줄여서 군집화 해 볼 필요가 있다.
[3개 그룹으로 군집화]
중심 개수를 3개로 줄여서 3개 그룹으로 군집화한 뒤 결과를 확인해 본다.
# 3개 집합으로 군집화 수행.
km_cluster = KMeans(n_clusters=3, max_iter=10000, random_state=0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
# 소속 클러스터를 cluster_label 칼럼으로 할당하고 cluster_label 값으로 정렬
document_df['cluster_label'] = cluster_label
document_df.sort_values(by='cluster_label')
document_df.head()
◆ Cluster #0
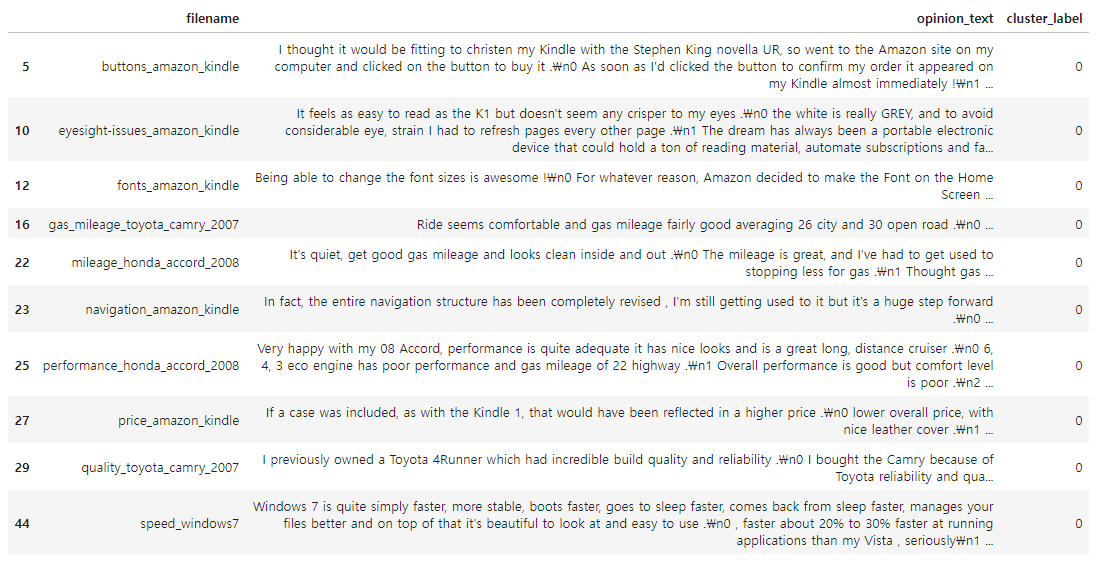
▶ 자동차, 킨들 등에 대한 리뷰가 섞여 있다. (군집화가 잘 되지 못했다)
◆ Cluster #1
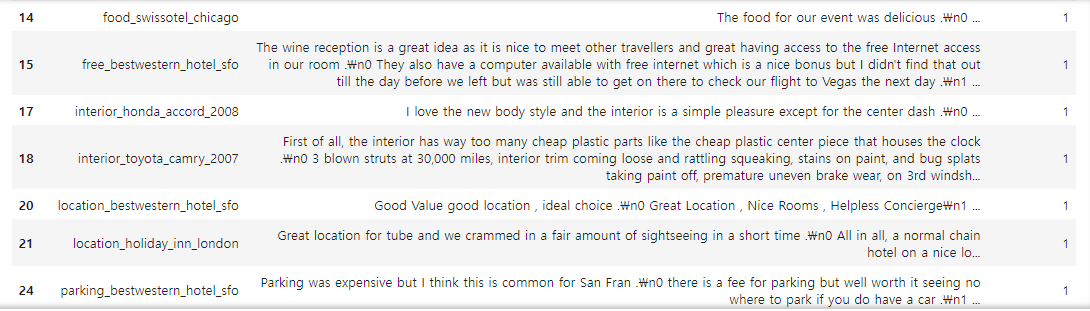
▶ 자동차 리뷰가 소량으로 있긴 하나, 대부분 호텔에 대한 리뷰로 군집화가 되었다.
◆ Cluster #2
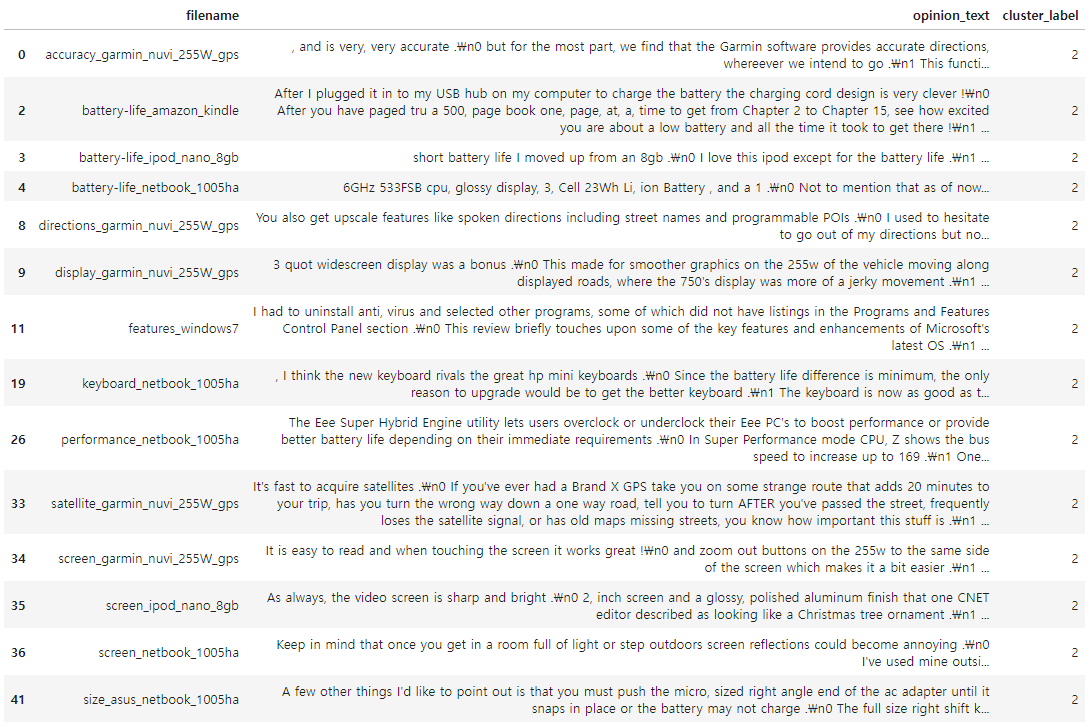
▶ 전자제품, 전자기기에 대한 리뷰로 군집화가 잘 되었다.
군집별 핵심 단어 추출하기
각 군집에 속한 문서는 핵심 단어를 주축으로 군집화 되어 있으므로, 각 군집을 구성하는 핵심 단어가 어떤 것이 있는지 확인해 본다.
KMeans 객체는 각 군집을 구성하는 단어 피처가 군집의 중심(Centroid)을 기준으로 얼마나 가깝게 위치해 있는지 cluster_centers_ 라는 속성으로 제공하는데, clsuter_centers_는 배열 값으로 제공되며, 행은 개별 군집, 열은 개별 피처를 의미한다. 또한, 각 배열 내의 값은 개별 군집 내의 상대 위치를 숫자 값으로 표현한 일종의 좌표 값이다.
앞서 군집 3개로 생성한 KMeans 객체인 km_cluster 에서 cluster_centers_ 속성값을 가져온 뒤 값을 확인해본다.
cluster_centers = km_cluster.cluster_centers_
print('cluster_centers shape:', cluster_centers.shape)
print(cluster_centers)
▶ cluster_centers_ 는 (3, 4611) 배열이며, 이는 군집이 3개, word 피처가 4611개로 구성되었다는 의미이다.
각 행의 배열 값은 각 군집 내의 4611개의 피처의 위치가 개별 중심과 얼마나 가까운가를 상대 값으로 나타낸 것이며, 0에서 1까지의 값을 가질 수 있고 1에 가까울수록 중심과 가까운 값을 의미한다.
[cluster_centers_ 속성값을 이용해 각 군집별 핵심 단어 찾기]
cluster_centers_ 속성은 넘파이의 ndarray 이며, ndarray의 argsort()[:, ::-1]를 이용하면 cluster_centers 배열 내 값이 큰 순으로 정렬된 위치 인덱스 값을 반환한다.(큰 값을 가진 배열 내 위치 인덱스 값 반환)
새로운 함수 get_cluster_details() 를 생성해 cluster_centers_ 배열 내에서 가장 값이 큰 데이터의 위치 인덱스를 추출한 뒤, 해당 인덱스를 이용해 핵심 단어 이름과 그때의 상대 위치 값을 추출해 cluster_details라는 Dict 객체 변수에 기록하고 반환한다.
# 군집별 top n 핵심 단어, 그 단어의 중심 위치 생댓값, 대상 파일명 반환
def get_cluster_details(cluster_model, cluster_data, feature_names, clusters_num,
top_n_features=10):
cluster_details = {}
# cluster_centers array 의 값이 큰 순으로 정렬된 인덱스 값 반환
# 군집 중심점(centroid) 별로 할당된 word 피처들의 거리값이 큰 순으로 값을 구하기 위함
centroid_feature_ordered_ind = cluster_model.cluster_centers_.argsort()[:, ::-1]
# 개별 군집별로 반복하면서 핵심 단어, 그 단어의 중심 위치 상대값, 대상 파일명 입력
for cluster_num in range(clusters_num):
cluster_details[cluster_num] = {}
cluster_details[cluster_num]['cluster'] = cluster_num
# cluster_centers_.argsort()[:, ::-1]로 구한 인덱스를 이용해 top n 피처 단어 구함
top_feature_indexes = centroid_feature_ordered_ind[cluster_num, :top_n_features]
top_features = [ feature_names[ind] for ind in top_feature_indexes]
# top_feature_indexes를 이용해 해당 피처 단어의 중심 위치 상댓값 구함
top_feature_values = cluster_model.cluster_centers_[cluster_num, top_feature_indexes].tolist()
# cluster_details 딕셔너리 객체에 개별 군집별 핵심단어와 중심위치 상댓값, 해당 파일명 입력
cluster_details[cluster_num]['top_features'] = top_features
cluster_details[cluster_num]['top_features_value'] = top_feature_values
filenames = cluster_data[cluster_data['cluster_label'] == cluster_num]['filename']
filenames = filenames.values.tolist()
cluster_details[cluster_num]['filenames'] = filenames
return cluster_details
get_cluster_details()를 호출하면 dictionary 를 원소로 가지는 리스트인 cluster_details를 반환하는데, 이 cluster_details에는 개별 군집번호, 핵심 단어, 핵심단어 중심 위치 상댓값, 파일명 속성 값 정보가 있다.
이를 좀 더 보기 좋게 표현하기 위해 별도의 print_cluster_details() 함수를 만든다.
def print_cluster_details(cluster_details):
for cluster_num, cluster_detail in cluster_details.items():
print('#### Cluster {0}'.format(cluster_num))
print('Top features:', cluster_detail['top_features'])
print('Reviews 파일명:', cluster_detail['filenames'][:7])
print('=================================================')
[위에서 생성한 get_cluster_details(), print_cluster_details() 함수를 호출]
get_cluster_details() 호출 시 인자는 KMeans 군집화 객체, 파일명 추출을 위한 document_df DataFrame, 핵심 단어 추출을 위한 피처명 리스트, 전체 군집 개수, 핵심 단어 추출 개수 이다.
피처명 리스트는 앞에서 TF-IDF 변환된 tfidf_vect 객체에서 get_feature_names_out()으로 추출.
feature_names = tfidf_vect.get_feature_names_out()
cluster_details = get_cluster_details(cluster_model=km_cluster, cluster_data=document_df,
feature_names=feature_names, clusters_num=3, top_n_features=10)
print_cluster_details(cluster_details)
▶ Cluster #0 은 군집화가 잘 되지 못했으므로 생략.
Cluster #1은 호텔에 대한 리뷰 군집으로, 'room', 'hotel', 'service', 'interior' 등이 핵심 단어로 군집화되었다.
Cluster #2는 포터블 전자제품 리뷰 군집으로, 'screen', 'battery', 'keyboard', 'video', 'direction' 등이 핵심 단어로 군집화되었다.
문서 군집화가 잘 되지 않을 경우
1. 문서 전처리 개선: 군집화가 잘 안 되는 원인 중 하나는 불필요한 단어나 특수문자, 중복 단어가 포함되었기 때문일 수 있다. TF-IDF 벡터화 전에 텍스트를 클리닝하고 불용어(stop words)를 제거하며, 어간 추출(stemming)이나 표제어 추출(lemmatization)도 고려.
2. 적절한 군집 수 설정: K-means와 같은 알고리즘을 사용할 때, 최적의 군집 수(K)를 설정하지 않으면 정확한 군집화가 어렵다. 엘보우 방법(Elbow method) 또는 실루엣 계수(Silhouette Score)를 사용해 최적의 K를 찾는 것이 좋다.
3. 고차원 축소 적용: TF-IDF 벡터화는 차원이 매우 커질 수 있어 성능에 영향을 미친다. 차원 축소 기법인 PCA 또는 TSNE를 사용하여 차원을 줄여 본다.
4. 다른 군집화 알고리즘 시도: K-means 외에 DBSCAN, Hierarchical Clustering과 같은 군집화 알고리즘을 사용해본다. 특히 DBSCAN은 밀도 기반 군집화로, 데이터의 밀도에 따라 더 나은 군집을 형성할 수 있다.
5. TF-IDF 파라미터 조정: max_df 및 min_df 파라미터를 조정해 너무 흔하게 또는 너무 드물게 나타나는 단어를 무시하여 보다 효과적인 벡터화를 시도할 수 있다.
이러한 방법들을 통해 문서 군집화의 성능을 향상시킬 수 있다.
다음 내용
[머신러닝] 텍스트 분석: 문서 유사도
텍스트 분석이란? [머신러닝] 텍스트 분석이전 내용 [머신러닝] 군집화 (Clustering)군집화(Clustering) [군집]군집은 비슷한 샘플을 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업으로, 데이
puppy-foot-it.tistory.com
[출처]
파이썬 머신러닝 완벽 가이드
분석 공부 블로그 - 깃허브
medium.com - Python에서 TF-IDF를 사용한 텍스트 클러스터링
kaggle.com - TFIDF 및 KMeans를 사용하여 문서 클러스터링
scikit-learn.org - TfidfVectorizer — scikit-learn 1.5.2 문서
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 텍스트 분석: 한글 텍스트 처리 (6) | 2024.10.31 |
|---|---|
| [머신러닝] 텍스트 분석: 문서 유사도 (6) | 2024.10.31 |
| [머신러닝] 텍스트 분석: 토픽 모델링 (4) | 2024.10.31 |
| [머신러닝] 텍스트 분석: 감성 분석 (3) | 2024.10.30 |
| [머신러닝] 텍스트 분석: 분류 실습 (0) | 2024.10.30 |



