파이썬 시각화 도구 기초 관련 글 모음
[데이터 시각화 차트 관련 글]
https://modulabs.co.kr/blog/data-visualization/
데이터 시각화 차트 디자인에 필요한 사례와 종류 알아보기
다양한 데이터 시각화 유형 중 가장 적합한 형태를 어떻게 선택하면 좋을지 사례를 통해 알아봅니다.
modulabs.co.kr
머신러닝을 데이터 분석 시 유용한 시각화 플롯

| 차트 유형 | 설명 |
| 히스토그램 | 연속형 값에 대한 도수 분포를 나타낸다. X축 값은 도수 분포를 원하는 연속형 값의 구간. Y축 값은 해당 구간의 도수 분포(건수)를 나타낸다. |
| 바 플롯 | 특정 칼럼의 이산 값에 따른 다른 칼럼의 연속형 값(평균, 총합 등)을 막대 그래프 형태로 시각화한다. (수직 막대 그래프 적용 시) X축 값은 특정 칼럼의 이산값, Y축 값은 다른 칼럼의 연속형 값으로 나타낸다 |
| 박스 플롯 | 연속형 값의 사분위 IQR와 최대, 최소, 이상치 값을 시각화한다. 보통 단일 칼럼의 연속형 값에 적용하지만, 이 연속형 값의 사분위를 다른 칼럼의 이산값별로 시각화할 때 사용할 수 있다 |
| 바이올릿 플롯 | 히스토그램의 연속 확률 분포 곡선과 박스 플롯을 바이올린 형태로 함께 시각화. 보통 단일 칼럼의 연속형 값에 적용하지만, 이 연속형 값의 분포를 다른 칼럼의 이산값별로 시각화할 때 유용. |
| 스캐터 플롯(산점도) | 2개의 연속형 값들을 X, Y 좌표상의 점으로 시각화하여 해당 값들이 어떻게 관계되어 있는지 나타낸다. |
| 상관 히트맵 | 다수의 연속형 칼럼들에 대해서 상호 간의 상관 관계를 시각화 |
[Seaborn의 시각화 예시]
Example gallery — seaborn 0.13.2 documentation
seaborn.pydata.org
시본(Seaborn)
시본은 맷플롯립보다 쉬운 구현, 수려한 시각화, 그리고 편리한 판다스(Pandas)와의 연동을 특징으로 하고 있으며, 맷플롯립보다 상대적으로 적은 양의 코딩으로도 보다 수려한 시각화 플롯을 제공한다.
또한 판다스의 칼럼명을 기반으로 자동으로 축 이름을 설정하는 등 편리한 연동 기능을 가지고 있다.
시본은 X축과 Y축으로 구성된 2차원 축에서 데이터를 시각화해주므로 2개의 변수(칼럼)에 대한 정보를 기본적으로 표출해주는데, 시본의 대부분 시각화 함수들은 hue라는 인자를 통해서 또는 플롯의 유형에 따라 연속형 데이터의 정보를 다른 이사현 데이터 값으로 세분화된 정보로 표현할 수 있게 만들어줘서 2개의 변수가 아닌 3개의 변수도 함께 정보로 시각화할 수 있다.
[Seaborn 사이트]
seaborn: statistical data visualization — seaborn 0.13.2 documentation
seaborn: statistical data visualization
seaborn.pydata.org
히스토그램
히스토그램은 데이터의 통계적인 분석을 위해 매우 많이 활용되며, 특히 머신러닝 학습 데이터의 중요 피처들 값이 어떠한 분포도를 가지고 있는지 확인하는 것은 모델 성능을 위해 매우 중요하다.
히스토그램은 시본, 맷플롯립, 판다스에서 제공되는데, 막대 차트처럼 보이지만 연속형 값을 범위 또는 구간으로 그룹화해 개별 구간에 해당되는 데이터의 건수를 시각화해준다.
시본에서는 히스토그램을 위해 histplot() 또는 displot() 함수 사용을 권장하고 있다.
- histplot(): Axes 레벨 함수
- displot(): Figure 레벨 함수
[histplot()]
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
titanic_df = pd.read_csv('C:/Users/niceq/Documents/DataScience/Python ML Guide/Data/01. titanic_train.csv')
plt.figure(figsize=(8,3))
# DataFrame의 칼럼명을 자동으로 인식해서 xleble 값 할당. ylebel 값은 Count로 설정
sns.histplot(titanic_df['Age'], bins=20)
plt.show()
▶ 20개의 bin 구간에 따라 연속으로 이어진 막대 그래프 형태의 도수 분포를 가진 히스토그램이 만들어졌다.
시본의 많은 시각화 함수들은 판다스 DataFrame과 잘 통합되어 있다. 이들 시각화 함수들은 X축과 Y축 각각에 DataFrame을 칼럼명을 입력받아서 처리할 수 있도록 설계되어 있다.
시본의 기본 인자값(data, x, y)을 histplot() 함수에 입력해 다시 시각화하는데,
- data: 시각화 대상 DataFrame 객체 (타이타닉 DataFrame 객체변수 titanic_df)
- x: X축에 사용될 칼럼명 ('Age')
- y: Y축에 사용될 칼럼명(히스토그램은 기본적으로 한 개의 변수만 시각화 하므로 생략)
이번엔 bins=30으로 구간 개수를 늘리고, kde=True 로 설정해 히스토그램의 연속 확률분포 곡선까지 함께 시각화 해본다.
sns.histplot(x='Age', data=titanic_df, bins=30, kde=True)
plt.show()
[displot()]
displot() 함수는 Figure 레벨 함수며, Figure 레벨 함수의 특징은 맷플롯립 API 사용을 최소화하고, 기본 맷플롯립에서 사용하는 기능들을 Figure 레벨 함수의 인자 등으로 대체하게 설계되었다. 그 예로 Figure의 크기는 plt.figure() 로 조절하는 게 아닌, 해당 함수에서 인자로 Figure의 크기를 조절해야 하는 식이다.
displot() 함수를 통해 Age 칼럼값의 히스토그램을 시각화해 본다.
import seaborn as sns
# seaborn의 figure 레벨 그래프는 plt.figure()로 figure 크기를 조절할 수 없다
plt.figure(figsize=(8,4))
sns.displot(x='Age', data=titanic_df, kde=True)
plt.show()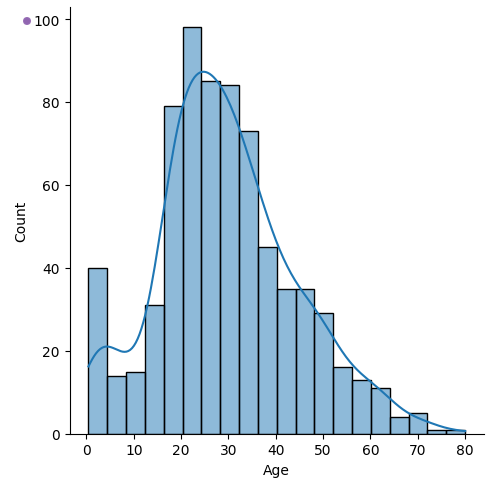
▶ plt.figure(figsize=(8,4))를 이용해 가로의 길이를 8, 세로의 길이를 4로 설정하였으나, 오히려 세로가 더 긴 히스토그램이 생성되었다.
displot() 함수의 Figure 크기를 조절하기 위한 인자로 height와 aspect가 주어진다.
- height: 세로(높이)의 크기
- aspect: 가로와 세로의 배율
width와 같은 별도의 가로(너비) 크기를 설정하는 인자는 제공되지 않고, height * aspect 를 적용하여 자동으로 가로의 크기가 결정된다.
import seaborn as sns
sns.displot(titanic_df['Age'], kde=True, height=4, aspect=2)
plt.show()
▶ 가로 길이가 더 큰 Figure가 만들어졌다.
카운트 플롯
카운트플롯은 이산형 값의 건수를 막대 그래프 형태로 시각화하며, 주로 카테고리성 칼럼 값별 건수를 시각화하는 데 사용된다. 카운트플롯은 시본의 countplot() 을 사용한다.
타이타닉 데이터의 Pclass(선실 등급) 값별 건수 시각화
sns.countplot(x='Pclass', data=titanic_df)
plt.show()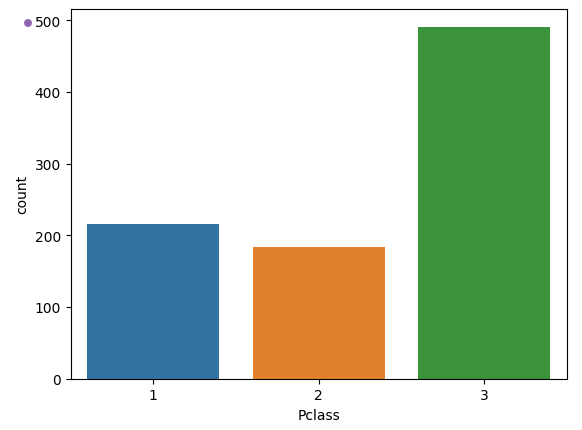
바 플롯(barplot)
바 플롯은 막대 그래프 형태의 플롯으로, 간단한 시각화이지만, 2차원 축 기반의 시각화에 널리 활용된다.
X축 값이 이산형 값으로 값의 종류가 너무 많지 않을 때 유용하게 사용될 수 있다.
바 플롯은 시본의 barplot() 함수로 간단하게 구현할 수 있으며,
- data: 시각화 대상 DataFrame 객체 (타이타닉 DataFrame 객체변수 titanic_df)
- x: X축에 사용될 칼럼명 ('Pclass')
- y: Y축에 사용될 칼럼명 ('Age')
위의 기본 인자들을 입력하면 자동으로 바 플롯을 시각화 해준다.
시본을 이용하여 타이타닉 데이터 세트의 Pclss 1, 2, 3 값 별로 Age 의 평균 값을 바 플롯으로 표현
# 자동으로 xlabel, ylabel을 barplot()의 x 인자값인 Pclass, y 인자값인 Age로 설정
sns.barplot(x='Pclass', y='Age', data=titanic_df)
plt.show()
barplot() 함수는 기본적으로 Y축 값의 평균 값을 나타내는데, 평균 외에도 총합, 중앙값 등을 나타낼 수 있으며 이는 estimator 인자값을 설정하여 변경할 수 있다.
barplot() 함수는 수직 또는 수평 막대 그래프를 시각화 선택을 orient 인자로 설정할 수 있는데, orient가
- v일 경우는 수직(Vertical) 막대그래프
- h일 경우는 수평(Horizontal) 막대그래프
를 그리며, orient 값을 별도로 설정하지 않을 경우 barplot() 함수는 입력된 X축 값과 Y축 값의 데이터 유형을 판단하여 자동으로 수직 또는 수평 막대 그래프를 그려주지만, X축과 Y값이 모두 숫자형 값이면 수직 막대 그래프를 우선하여 그려준다.
바 플롯은 수직 막대 그래프의 경우
- X축 값을 이산형 값으로 설정하며 이산형 값은 숫자값 또는 문자열값 모두 가능
- Y축 값을 문자열 값으로 설정하면 안됨. (문자열 값의 평균, 총합은 정보로서 완전히 다른 의미이며, 시각적으로 이해할 수 없기 때문). 만약 Y축 값을 문자형으로 입력하고, X축 값을 숫자형으로 입력하면 자동으로 수평 막대 그래프로 시각화해줌.
barplot() 함수에 x 인자로 Pclass(숫자형), y인자로 Sex(문자열) 을 입력할 경우
### y축을 문자값으로 설정하면 자동으로 수평 막대 그래프 변환
sns.barplot(x='Pclass', y='Sex', data=titanic_df)
plt.show()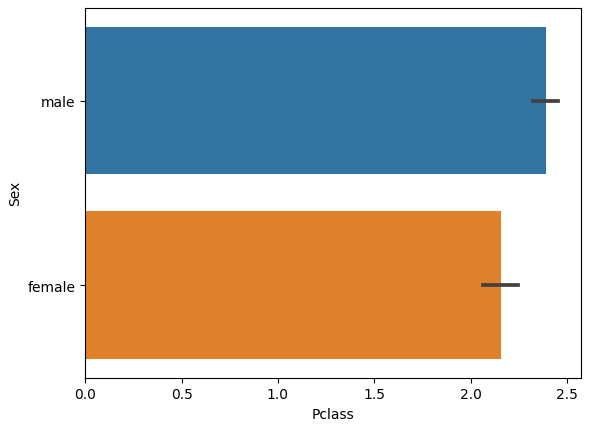
▶ 수평 막대 그래프의 X축 값인 Pclass는 1, 2, 3밖에 없으나, 수평 막대 그래프의 경우 X축 값을 연속형 값을 기대하게 되므로 Pclass 값이 평균값으로 만들어져 표현된다. (수직 막대 그래프의 경우 Y축 값이 연속형 값을 기대하게 된다)
X축, Y축 모두 이산값을 입력한다면 바 플롯으로 표현되는 정보를 시각적으로 잘못 이해될 수 있기 때문에 바 플롯은 수직 막대 그래프의 경우 Y축 값을 연속형 값으로, 수평 막대 그래프는 X축 값을 연속형 값으로 설정해 줘야 시각적으로 정보가 의미하는 바를 명확하게 파악할 수 있다.
또한 바 플롯 생성 시 X축 값과 Y축 값을 모두 문자열 값으로 입력하면 바 플롯이 의미하는 정보의 표현 의도와 완전히 어긋나기 때문에 barplot() 함수는 오류를 발생시킨다.
수직 막대 그래프의 Y축 표현값을 평균이 아니라 총합으로 나타낼 수도 있는데, 이때 estimator=sum 으로 설정하면 된다.
선실 등급(Pclass) 별 생존자 수 시각화하기
# estimator=sum 적용하여 평균이 아니라 총합으로 표현
sns.barplot(x='Pclass', y='Survived', data=titanic_df, ci=None, estimator=sum)
plt.show()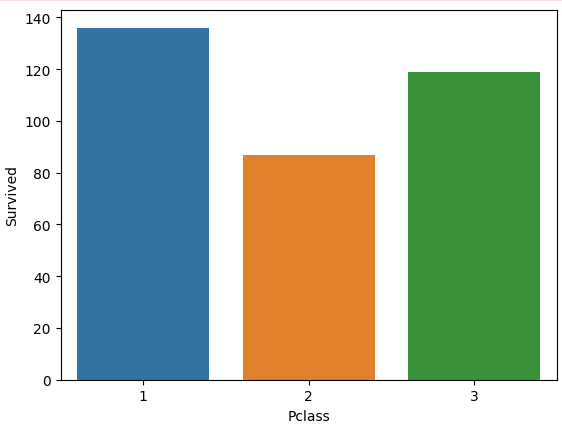
barplot() 함수의 hue 인자를사용하여 시각화 정보를 추가적으로 세분화
barplot() 함수는 hue 인자를 통해서 세부 정보를 추가적으로 전달할 수 있다.
아래는 Pclass를 X축 값, Age를 Y축 값으로 설정한 뒤, barplot() 함수의 hue 인자를 Sex로 설정하여 X축 Pclass 별로 세부적인 추가 정보인 성별(Sex) 값에 따른 평균 나이를 시각화하는 예시이다.
# X축: Pclass, Y축: Age, hue 파라미터: Sex
# 개별 Pclass 값별로 Sex에 따른 Age 평균 값 구함
sns.barplot(x='Pclass', y='Age', hue='Sex', data=titanic_df)
plt.show()
▶ hue='Sex' 가 적용되면서 X축의 Pclass 값이 보다 세분화된 형태로 쪼개졌는데, 각각 Sex의 값이 male 일 때 파란색 막대 그래프, female일 때 주황색 막대 그래프로 나누어졌다. 또한, 오른쪽 상단에는 범례로 Sex 칼럼의 개별 값들과 의미하는 색깔이 표시되어 있다.
Pclass 별 생존율을 좀 더 세분화하여 성별 별 생존율을 시각화 해본다.
sns.barplot(x='Pclass', y='Survived', hue='Sex', data=titanic_df)
plt.show()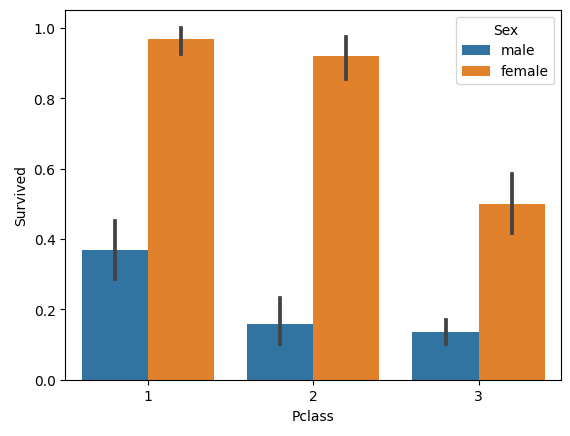
박스 플롯
박스 플롯은 상자 수염 그래프라고도 불리는데, 그래프가 상자 형태로 생긴 몸통 부분과 위, 아래로 길게 이어진 수염 형태로 이뤄져 있기 때문이다.
시본은 박스 플롯 시각화를 위해서 boxplot() 함수를 제공하며, 주요 인자로는 x, y, data 가 있다.
박스 플롯은 분위수를 기반으로 하고 있는데, 분위수는 연속형 값에 적용해야 의미 있는 정보가 될 수 있다. 박스 플롯은 연속형 값에 대한 IQR 분위수와 최소/최대 그리고 이상치 정보를 시각화한다.
boxplot() 함수의 x 또는 y 인자로 연속형 값을 입력할 수 있는데,
- y에 입력 시: 수직 박스 플롯
- x에 입력 시: 수평 박스 플롯
sns.boxplot(y='Age', data=titanic_df)
plt.show()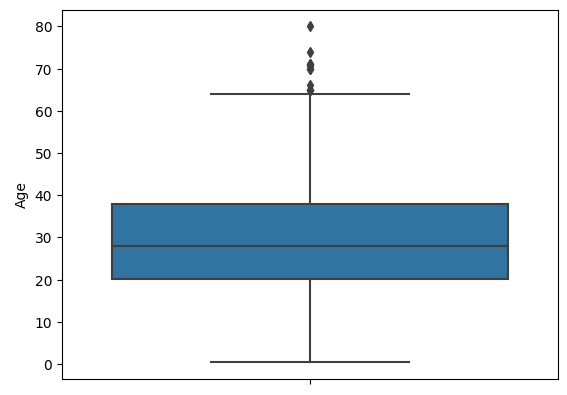
기본적으로 박스 플롯은 단일 칼럼에 대한 분위수를 기반으로 하고 있지만, 추가적인 세분화 레벨에서도 적용이 가능하다.
추가적인 세분화 레벨로 여러 개의 수직 박스 플롯을 표현하고자 한다면 반드시 x 인자는 이산형 값이 되어야 한다. x 인자에 연속형 값을 입력하면 너무 많은 박스 플롯들을 그리기 때문에 표현되는 정보가 큰 의미가 없어지게 되기 때문이다.
sns.boxplot(x='Pclass', y='Age', data=titanic_df)
plt.show()
▶ boxplot() 함수의 y 인자에 Age, x 인자에 Pclass를 입력하여 Pclass 값 1, 2, 3 별로 Age에 대한 수직 박스 플롯을 생성하였다.
여기에 hue를 적용하여 한 단계 더 추가적인 정보를 제공할 수 있는데, hue 인자 값으로 Sex 칼럼명을 입력하게 되면 Pclass 값별로 세부적인 Sex 값인 male과 female에 따른 Age 값의 박스 플롯들을 시각화할 수 있게 된다.
sns.boxplot(x='Pclass', y='Age', hue='Sex', data=titanic_df)
plt.show()
바이올린 플롯
바이올린 플롯은 히스토그램의 연속 확률 분포 곡선과 박스 플롯을 함께 시각화할 수 있는데, 연속 확률 분포 곡선을 대칭적으로 그리고 가운데에 박스 플롯을 검은색 몸통과 수염으로 나타낸 모습이 바이올린과 유사하다고 해서 붙여진 명칭이다.
바이올린 플롯 역시 연속형 값에 적용해야 의미 있는 정보로 시각화될 수 있으며, 시본은 바이올린 플롯을 위해 violinplot() 함수를 제공한다.
violinplot() 함수 역시 x 또는 y 인자로 연속형 값을 입력할 수 있는데,
- y에 입력 시: 수직 박스 플롯
- x에 입력 시: 수평 박스 플롯
# Age 칼럼에 대한 수직 바이올린 플롯 시각화
sns.violinplot(y='Age', data=titanic_df)
plt.show()
violinplot() 함수는 여러 이산값별로 여러 개의 바이올린 플롯들을 그릴 수 있으며, 이는 여러 이산값별로 여러 개의 히스토그램 연속 확률 분포 곡선들을 그려줄 수 있는 장점을 가지고 있다.
sns.violinplot(x='Pclass', y='Age', data=titanic_df)
plt.show()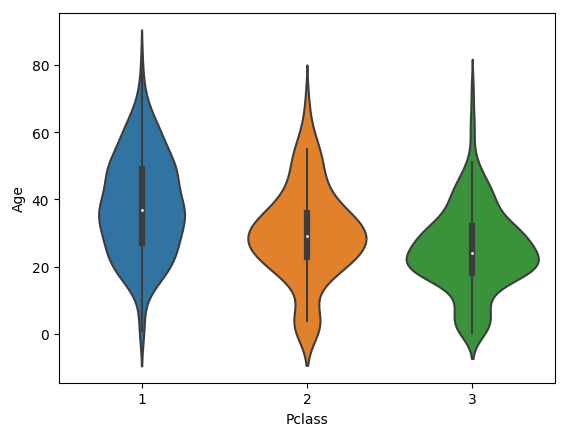
▶ Pclass 별로 Age의 연속 확률분포 곡선과 박스 플롯을 함께 시각화하므로 Age 값의 데이터 분포를 Pclass 별로 비교할 수 있다.
violinplot() 함수 역시 hue를 이용하여 한 단계 더 추가적인 새부 정보를 제공할 수 있다.
sns.violinplot(x='Pclass', y='Age', hue='Sex', data=titanic_df)
plt.show()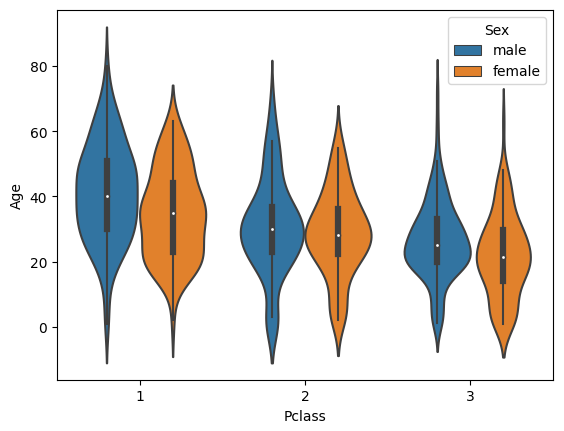
시본의 histplot() 함수는 hue 기능을 제공하지만 그보다는 violinplot() 함수가 특정 이산값에 해당하는 연속형 값의 데이터 분포도를 훨씬 더 효과적으로 시각화해주기 때문에 데이터 분석 시 활용도가 높다.
subplots를 이용하여 시본의 다양한 그래프를 시각화
시본의 시각화 함수를 subplots로 할당된 개별 Axes 객체에 적용하는 방식은 맷플롯립과 약간 다른데, 시본의 모든 Axes 레벨 시각화 함수는 ax라는 인자를 가지고 있다. 시각화 함수 호출 시 이 ax 인자에 개별 Axes 객체를 할당하면 된다.
[이산형 칼럼들에 대한 시각화]
주요 이산형 칼럼인 Survived, Pclass, Sex 의 건수를 시각화 해본다.
- 3개 칼럼이므로 세 개의 Axes 객체를 가지는 subplots를 생성
- 개별 Axes 객체에 시본의 countplot 함수를 적용
- countplot() 함수를 차례로 호출하되, ax 인자값에 왼쪽부터 생성되는 Axes 객체 변수를 순차적으로 입력
cat_columns = ['Survived', 'Pclass', 'Sex']
# nrwos는 1, ncols는 칼럼의 개수만큼
fig, axs = plt.subplots(nrows=1, ncols=len(cat_columns), figsize=(14,4))
for index, column in enumerate(cat_columns):
print('index:', index)
# seaborn의 Axes 레벨 function들은 ax 인자로 subplots의 어느 Axes에 위치할지 설정
sns.countplot(x=column, data=titanic_df, ax=axs[index])
▶ 코드 설명
- 건수를 표현할 칼럼들을 리스트 형태로 [Survived, Pclass, Sex]와 같이 생성
- fig, axs = plt.subplots(nrows=1, ncols=len(cat_columns), figsize=(14,4)) 를 호출하여 3개의 Axes 생성하여 axs 객체 변수에 할당
- axs[0], axs[1], axs[2] 각각은 왼쪽부터 생성되는 Axes 객체를 할당받게 되므로 루프를 돌면서 개별 칼럼에 대한 카운트 플롯을 시각화하되, ax 인자를 차례대로 axs[0], axs[1], axs[2]를 입력하여 3개의 subplots 출력
Pclass, Sex, Embarked 3개의 이산형 칼럼별로 타깃 칼럼인 Survived값의 평균값 시각화
cat_columns = ['Pclass', 'Sex', 'Embarked']
# nrwos는 1, ncols는 칼럼의 개수만큼
fig, axs = plt.subplots(nrows=1, ncols=len(cat_columns), figsize=(14,4))
for index, column in enumerate(cat_columns):
print('index:', index)
# seaborn의 Axes 레벨 function들은 ax 인자로 subplots의 어느 Axes에 위치할지 설정
sns.barplot(x=column, y='Survived', data=titanic_df, ax=axs[index])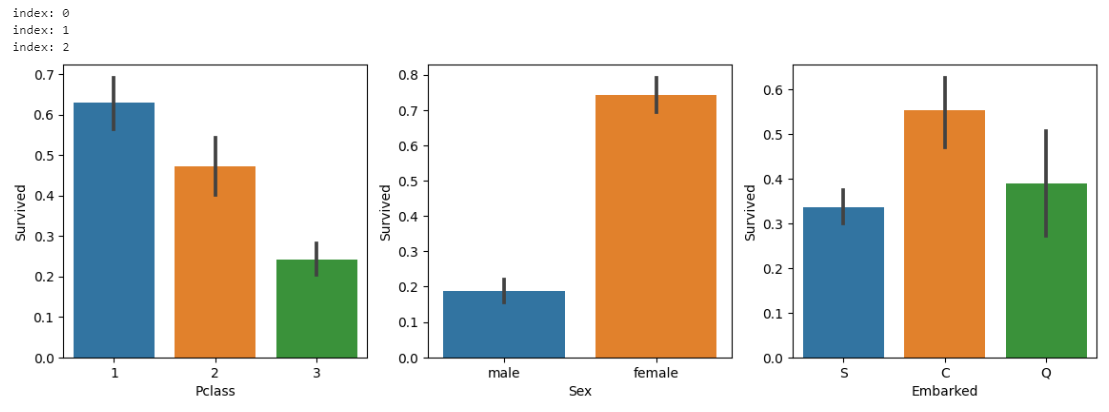
▶ Pclass가 3일때, 성별이 male일 때 생존율이 매우 낮음을 알 수 있다.
[연속형 칼럼들에 대한 시각화]
두 개의 연속형 칼럼 Age와 Fare에 대해서 Survived 값이 0 일 때와 1일 때 각각 데이터 분포도를 확인하되, 개별 칼럼별로 두 개의 서브플롯을 생성하여
- 왼쪽에는 Survived 값에 따른 바이올린 플롯
- 오른쪽에는 Survived 값에 따른 히스토그램
cont_columns = ['Age', 'Fare']
# 리스트로 할당된 칼럼들의 개수만큼 루프 수행
for column in cont_columns:
# 왼쪽- 바이올린, 오른쪽 - 히스토그램. nrows는1, ncols는 2인 서브플롯 생성
fig, axs = plt.subplots(nrows=1, ncols=len(cont_columns), figsize=(10,4))
#왼쪽 Axes 객체에는 Survived 값 0, 1별 개별 칼럼의 바이올린 플롯
sns.violinplot(x='Survived', y=column, data=titanic_df, ax=axs[0])
# 오른쪽 Axes 객체에는 Survived 값에 따른 개별 칼럼의 히스토그램 시각화
sns.histplot(x=column, data=titanic_df, kde=True, hue='Survived', ax=axs[1])
산점도, 스캐터 플롯(Scatter Plot)
산점도는 스캐터 플롯이라고 불리며, 보통 좌표상에 점을 표시하여 변수 간의 관계를 나타낸다. 2차원 축, X축과 Y축이 있다면 X축에 해당하는 변숫값과 Y축에 해당하는 변숫값이 만나는 지점에 점을 표시하여 변수 간의 관계를 시각화한다.
일반적으로 산점도에 사용되는 X축 값, Y축 값 모두 연속형 숫자값을 적용해야 의미있는 시각화 정보를 얻을 수 있다.
시본에서는 scatterplot 함수를 이용하여 시각화 할 수 있다.
# X축- Age, Y축 - Fare
sns.scatterplot(x='Age', y='Fare', data=titanic_df)
plt.show()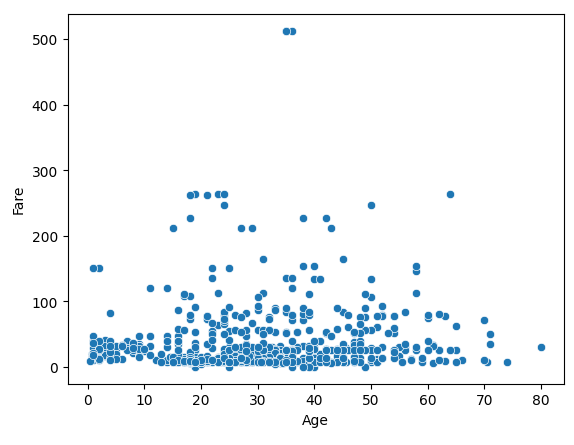
▶ 주로 100이하의 낮은 요금(Fare)이 전 연령대(Age)에 걸쳐서 분포되어 있는 것으로 보인다.
scatterplot 함수는 시본의 다른 함수와 마찬가지로 hue 인자를 지원한다.
sns.scatterplot(x='Age', y='Fare', hue='Survived', data=titanic_df)
plt.show()
▶ 사망/생존으로 추가적인 분리를 적용했다.
scatterplot() 함수는 hue 외에도 sytle 인자로 한 단계 더 세분화된 추가 정보를 제공할 수 있다.
sns.scatterplot(x='Age', y='Fare', hue='Survived', style='Sex', data=titanic_df)
plt.show()
▶ X축 Age와 Y축 Fare로 표현되는 점들이 세부적으로 사망/생존은 파란색/주황색 으로 구분되며, 남성/여성 성별은 원/엑스(X) 모양으로 구분됨을 알 수 있다.
상관 히트맵(Correlation Heatmap)
상관 히트맵은 다수의 속성들 간의 상관계수를 히트맵 형태로 나타낼 수 있는데, 히트맵은 이름 그대로 열을 의미하는 히트(Heat)와 지도를 의미하는 맵(Map)이 결합된 단어이다. 수치값을 온도를 연상시키는 다양한 색상으로 표현하는 것을 특징으로 하고 있다. 상관 히트맵은 다수의 칼럼들 간의 상관 계수를 온도를 연상시키는 여러 가지 색상으로 표현하여 직관적으로 칼럼들 간의 상관도를 이해할 수 있게 해주는 훌륭한 시각화 기법이다.
상관계수는 두 속성(변수/칼럼/피처) 들 간의 선형적인 연관 관계를 수치화한 값으로,
- 두 속성의 값이 서로 상관없으면 0
- 같은 방향으로 완전히 동일하면 1. A 속성의 값이 증가할 때 B 속성의 값도 함께 증가 (양의 상관 관계)
- 반대 방향으로 완전히 동일하면 -1. A 속성의 값이 증가할 때 B 속성의 값은 감소(음의 상관 관계)
상관 히트맵은 시본에서 heatmap() 함수를 통해 시각화될 수 있으며, 인자로 칼럼들 간의 상관계수를 가지는 DataFrame을 입력받아야 시각화가 가능하다. 판다스 DataFrame의 corr() 메서드를 호출하면 간단하게 상관계수를 가지는 DataFrame을 생성할 수 있다.
corr() 함수는 숫자형 데이터 간의 상관관계를 계산하므로, 문자열이 포함된 열이 있으면 오류가 발생하게 된다. 이 문제를 해결하려면 데이터에서 숫자형 열만 선택하거나, 문자열을 숫자로 변환할 수 있도록 전처리 작업이 필요하하다.
방법1) 숫자형 열만 선택
numeric_df = titanic_df.select_dtypes(include=[float, int]) # 숫자형 열만 선택
corr_df = numeric_df.corr()
corr_df
방법2) 불필요한 열 제거: 문자열 데이터를 포함한 열을 제거하여 상관관계 계산에서 제외할 수도 있다. 예를 들어, 승객의 이름이나 성별이 포함된 열을 제거한한다.
titanic_df = titanic_df.drop(columns=['Name', 'Sex']) # 문자열 데이터가 있는 열 제거
corr_df = titanic_df.corr()

▶ 생성된 상관계수 DataFrame을 살펴보면 상단에 열 방향으로 칼럼들이 존재하며 왼쪽에 행 방향으로 역시 같은 칼럼들이 존재하는 것을 볼 수 있는데, 이는 칼럼과 칼럼 간의 상관계수 값을 행과 열로 매핑하여 알 수 있게 해준다.
위에서 구한 상관계수 DataFrame을 heatmap() 함수의 인자로 입력하면 히트맵으로 표현이 가능하다.
sns.heatmap(corr_df)
plt.show()
heatmap() 함수는 여러 인자들로 보다 다양한 시각화를 할 수 있다.
- cmap: color map으로서 히트맵의 색상을 변경할 수 있게 해주는데, cmap 인자값을 설정하지 않으면 기본으로 'rocket'으로 설정된다. (마치 로켓이 뿜어내는 화염을 연상하게 하는 색상)
- annot: True/False 로 설정할 수 있으며, True 일 경우 숫자로 된 상관계수 값을 표시 (생략될 경우 False)
- fmt: annot 인자로 숫자 상관계수 값을 표시할 경우 정밀도가 너무 높으면 개별 숫자값의 길이가 길어져 서로 겹쳐 보이게 되는데, 이러한 경우 fmt='.1f' 로 설정하면 소수점 한 자리까지만 상관계수 값을 표시
- cbar: True/False로 설정할 수 있으며, True 일 경우 숫자값에 따른 색깔 기준 막대로 표시 (False는 색깔 기준 막대 표시 하지 않음, 인자 생략할 경우 True)
[시본 색상 관련 정보]
Choosing color palettes — seaborn 0.13.2 documentation
Choosing color palettes Seaborn makes it easy to use colors that are well-suited to the characteristics of your data and your visualization goals. This chapter discusses both the general principles that should guide your choices and the tools in seaborn th
seaborn.pydata.org
sns.heatmap(corr_df, cmap='flare', annot=True, fmt='.1f', cbar=True)
plt.show()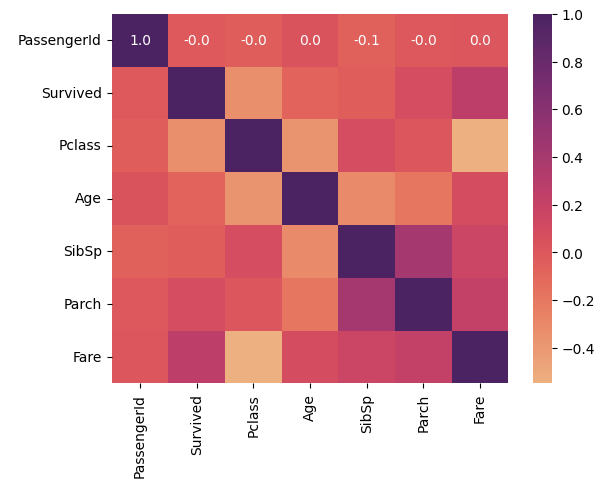
※ 상관계수 값이 첫 줄만 나오는 오류 헤결 방법
이때에는 cmd (명령 프롬프트)를 켜고
pip install seaborn --upgrade를 입력한 뒤, 시본 버전을 업그레이드 후

다시 코드를 실행해보면 된다. (업그레이드 후 주피터노트북도 재실행했다)

다음 내용
[머신러닝] 캘리포니아 주택 가격 프로젝트
◆ 프로젝트: 캘리포니아 주택 가격 데이터셋을 이용한 머신러닝 프로젝트이 데이터셋은 1990년 캘리포니아 인구 조사 데이터를 기반으로 하며, 진행할 주요 단계는 아래와 같다.데이터 준비데
puppy-foot-it.tistory.com
[출처]
파이썬 머신러닝 완벽 가이드
모두의 연구소
https://seaborn.pydata.org/
'[파이썬 Projects] > <파이썬 기초>' 카테고리의 다른 글
| [Visual Studio Code] VS CODE 다운로드 (0) | 2025.01.13 |
|---|---|
| [파이썬] 파이썬 기초: 함수 (보완) (0) | 2025.01.10 |
| [파이썬] 파이썬 기초: 파이썬 프로그래밍 (1) | 2024.10.18 |
| [파이썬] 파이썬 기초: 라이브러리-2 (0) | 2024.10.16 |
| [파이썬] 파이썬 기초: 라이브러리-1 (2) | 2024.10.16 |



