앙상블 학습
[머신러닝] 분류 - 앙상블 학습(Ensemble Learning)
앙상블 학습(Ensemble Learning) 앙상블 학습을 통한 분류는,여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법을 말한다. 앙상블 학습의 목표는,다양한
puppy-foot-it.tistory.com
에이다 부스트 (AdaBoost)
◆ 부스팅(Boosting):
부스팅은 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법을 말하며, 앞의 모델을 보완해 나가면서 일련의 예측기를 학습시키는 것이다.
◆ AdaBoost 개념
- 에이다부스트는 Adaptive + Boosting 로 만들어진 단어이며, 알고리즘의 정의를 살펴보면 아래와 같다.
약한 분류기(weak classifier)들이 상호보완 하도록 순차적(sequential)으로 학습하고, 이들을 조합하여 최종적으로 강한 분류기(strong classifier)의 성능을 향상시키는 것이다.
샘플의 가중치를 업데이트하면서 순차적으로 학습하는 부스팅 알고리즘
AdaBoost는 성능을 향상시키기 위하여 다른 많은 형태의 학습 알고리즘과 결합하여 사용할 수 있다. 다른 학습 알고리즘(약한 학습기, weak learner)의 결과물들을 가중치를 두어 더하는 방법으로 가속화 분류기의 최종 결과물을 표현할 수 있다.
AdaBoost는 이전의 분류기에 의해 잘못 분류된 것들을 이어지는 약한 학습기들이 수정해줄 수 있다는 점에서 다양한 상황에 적용할 수 있다(adaptive). 따라서 에이다 부스트는 잡음이 많은 데이터와 이상점(outlier)에 취약한 모습을 보인다. 그러나 또 다른 경우에는, 다른 학습 알고리즘보다 과적합(overfitting)에 덜 취약한 모습을 보이기도 한다. 개별 학습기들의 성능이 떨어지더라도, 각각의 성능이 무작위 추정보다 조금이라도 더 낫다면(이진 분류에서 에러율이 0.5보다 낮다면), 최종 모델은 강한 학습기로 수렴한다는 것을 증명할 수 있다.
모든 학습 알고리즘이 잘 적용될 수 있는 형태의 문제가 있고 그렇지 않은 문제가 있으며, 일반적으로 주어진 데이터 집합에 대한 최고의 성능을 얻기 위해서 많은 파라미터와 설정을 조절해야 하는 반면, (약한 학습기로서 결정 트리 학습법을 이용한) AdaBoost는 종종 최고의 발군의 분류기로 불린다. 결정 트리 학습법과 함께 사용되었을 때, AdaBoost 알고리즘의 각 단계에서 얻을 수 있는 각 훈련 샘플의 상대적 난이도에 대한 정보가 트리 성장 알고리즘에 반영되어 트리가 분류하기 더 어려운 경우에 집중되는 경향이 있다.
에이다부스트(AdaBoost) 동작 원리
출처: 티스토리 블로그 '준비하는 대학생' (https://gsbang.tistory.com/)
AdaBoost는 아래와 같은 순서로 동작:
- 데이터셋의 각 샘플에 동일한 가중치가 부여다. 초기 가중치는 1/N으로 설정되며, N은 샘플의 개수.
- *약한 학습기가 훈련 데이터에 적합하도록 학습. 학습기는 간단한 의사결정나무와 같은 단순한 모델을 사용.
- 각 학습기는 가중치가 적용된 데이터셋에서 오류를 최소화하는 방향으로 학습.
- 학습기의 오류를 계산하고, 학습기에 가중치(alpha)를 부여. 여기서 alpha는 학습기의 정확도에 따라 결정.
- 샘플의 가중치를 업데이트. 잘못 분류된 샘플의 가중치는 증가시키고, 올바르게 분류된 샘플의 가중치는 감소.
- 여러 개의 학습기를 순차적으로 학습시키며 3-5단계를 반복.
- 최종적으로, 학습기들의 예측을 가중합하여 최종 예측을 생성.
* 약한 학습기를 사용하는 이유
- 계산 효율성: 약한 학습기는 일반적으로 단순한 모델로 구성되며, 학습과 예측이 빠르다. 이로 인해 에이다 부스트는 여러 개의 약한 학습기를 조합하여 복잡한 문제를 해결할 수 있으면서도 계산상 효율적.
- 과적합 방지: 복잡한 모델은 과적합(overfitting)되기 쉽다. 약한 학습기는 단순하기 때문에 과적합되기 어렵고, 이를 통해 에이다 부스트는 일반화 성능을 향상시킨다.
- 가중치 조절에 의한 특징 학습: 에이다 부스트는 학습 과정에서 약한 학습기가 잘못 분류한 샘플에 더 높은 가중치를 부여한다. 이는 각 약한 학습기가 데이터셋의 다른 부분에 초점을 맞추도록 하여, 다양한 특징을 학습할 수 있게 한다.
- 앙상블 학습의 강점 활용: 단일 복잡한 모델 대신 여러 개의 약한 학습기를 결합함으로써, 각 학습기의 장점을 취합하고 단점을 상쇄시킬 수 있다. 이를 통해 에이다 부스트는 더 높은 정확도와 안정성을 달성한다.
- 특성 선택: 약한 학습기가 단순한 모델인 경우, 예를 들어 결정 트리의 경우, 데이터의 일부 특성에만 초점을 맞추게 된다. 이를 통해 에이다 부스트는 자연스럽게 특성 선택(feature selection)이 이루어지며, 더욱 효율적인 학습이 가능해진다.
아래는 moons 데이터셋에 훈련시킨 다섯 개의 연속된 예측기의 결정 경계이며, 이 모델은 규제를 강하게 한 RBF 커널 SVM 분류기이다.
m = len(X_train)
fig, axes = plt.subplots(ncols=2, figsize=(10, 4), sharey=True)
for subplot, learning_rate in ((0, 1), (1, 0.5)):
sample_weights = np.ones(m) / m
plt.sca(axes[subplot])
for i in range(5):
svm_clf = SVC(C=0.2, gamma=0.6, random_state=42)
svm_clf.fit(X_train, y_train, sample_weight=sample_weights * m)
y_pred = svm_clf.predict(X_train)
error_weights = sample_weights[y_pred != y_train].sum()
r = error_weights / sample_weights.sum() # equation 7-1
alpha = learning_rate * np.log((1 - r) / r) # equation 7-2
sample_weights[y_pred != y_train] *= np.exp(alpha) # equation 7-3
sample_weights /= sample_weights.sum() # normalization step
plot_decision_boundary(svm_clf, X_train, y_train, alpha=0.4)
plt.title(f"learning_rate = {learning_rate}")
if subplot == 0:
plt.text(-0.75, -0.95, "1", fontsize=16)
plt.text(-1.05, -0.95, "2", fontsize=16)
plt.text(1.0, -0.95, "3", fontsize=16)
plt.text(-1.45, -0.5, "4", fontsize=16)
plt.text(1.36, -0.95, "5", fontsize=16)
else:
plt.ylabel("")
plt.show()
- 첫 번째 분류기가 많은 샘플을 잘못 분류해서 이 샘플들의 가중치가 높아졌다
- 그로인해 두 번째 분류기는 이 샘플들을 더 정확히 예측하게 된다
- 오른쪽 그래프는 학습률을 반으로 낮춘 것만 빼고 똑같은 일련의 예측기를 나타낸 것이며, 학습률을 반으로 낮췄기 때문에 잘못 분류된 샘플의 가중치는 반복마다 절반 정도만 높아진다.
- 이러한 연속된 학습 기법은 경사 하강법과 비슷한 면이 있는데, 경사 하강법은 비용 함수를 최소화하기 위해 한 예측기의 모델 파라미터를 조정해가는 반면 AdaBoost는 점차 더 좋아지도록 앙상블에 예측기를 추가한다.
모든 예측기가 훈련을 마치면 이 앙상블은 배깅이나 페이스팅과 비슷한 방식으로 예측을 만든다. 그러나 가중치가 적용된 훈련 세트의 전반적인 정확도에 따라 예측기마다 다른 가중치가 적용된다.
AdaBoost 알고리즘
1. 각 샘플 가중치는 초기에 1/m로 초기화 된다.
2. 첫 번째 예측기가 학습되고 가중치가 적용된 오류율 r이 훈련 세트에 대해 계산된다
3. 예측기의 가중치는 예측기가 정확할수록 더 높아진다. 만약 랜덤 추측이라면 가중치는 0에 가까워지는데, 랜덤 추측보다 정확도가 낮으면 가중치는 음수가 된다
4. AdaBoost 알고리즘이 샘플의 가중치를 업데이트 함으로써, 잘못 분류된 샘플의 가중치가 높아진다.
5. 모든 샘플의 가중치를 정규화한다.
6. 새 예측기가 업데이트된 가중치를 사용해 훈련되고 전체 과정이 반복된다.
▶새 예측기의 가중치가 계산되고 샘플의 가중치를 업데이트해서 또 다른 예측기를 훈련시키는 방식.
7. 이 알고리즘은 지정된 예측기 수에 도달하거나 완벽한 예측기가 만들어지면 중지된다.
예측을 할 때 AdaBoost는 단순히 모든 예측기의 예측을 계산하고 예측기 가중치를 더해 예측 결과를 만들고, 가중치 합이 가장 큰 클래스가 예측 결과가 된다.
사이킷런에서의 AdaBoost
사이킷런은 SAMME 라는 AdaBoost 의 다중 클래스 버전을 이용하는데, 클래스가 두 개뿐이라면 SAMME는 AdaBoost와 동일하다.
예측기가 predict_proba() 메서드가 있어 클래스의 확률을 추정할 수 있다면 사이킷런은 SAMME의 변형인 SAMME.R(R은 'Real'을 뜻함)을 사용한다. 이 알고리즘은 예측값 대신 클래스 확률을 기반으로 하며 일반적으로 성능이 더 좋다.

[SAMME.R 관련 변경사항]
The SAMME.R algorithm (the default) is deprecated and will be removed in 1.6. Use the SAMME algorithm to circumvent this warning. warnings.warn
이라는 경고가 나올 경우에는,
이 경고 메시지는 scikit-learn 라이브러리를 사용할 때 발생하는 것으로, SAMME.R 알고리즘이 더 이상 권장되지 않으며, scikit-learn 버전 1.6부터는 제거될 예정이라는 내용을 담고 있다. 경고에서 제안하는 대로 SAMME 알고리즘을 사용하여 이 문제를 해결할 수 있다.
[SAMME.R vs SAMME]
- SAMME.R은 실수(real-valued) 기반 부스팅 알고리즘으로, 종종 빠르게 수렴하여 더 적은 에러로 테스트 결과를 낼 수 있지만 곧 지원이 중단된다.
- SAMME는 이산(discrete) 기반 부스팅 알고리즘으로, 향후 계속 지원될 예정이다.
▶ 해결방법
AdaBoostClassifier를 사용할 때, algorithm='SAMME'로 설정하면 경고 없이 사용할 수 있다.
사이킷런에서는 분류를 위해 AdaBoostClassifier를 제공한다. (회귀는 AdaBoostRegressor)
아래는 사이킷런의 AdaBoostClassifier를 사용하여 200개의 아주 얕은 결정 트리를 기반으로 하는 AdaBoost 분류기를 훈련시킨다. 여기서 결정 트리는 max_depth=1 인데, 이는 결정 노드 하나와 리프 노드 두 개로 이루어진 트리를 말하며, 이 트리가 AdaBoostClassifier의 기본 추정기이다.만약 AdaBoost 앙상블이 훈련 세트에 과대적합되면 추정기 수를 줄이거나 추정기의 규제를 더 강하게 해보는 것을 제안한다.
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=30,
learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)
# AdaBoost 분류기에 대한 결정 경계 시각화
plot_decision_boundary(ada_clf, X_train, y_train)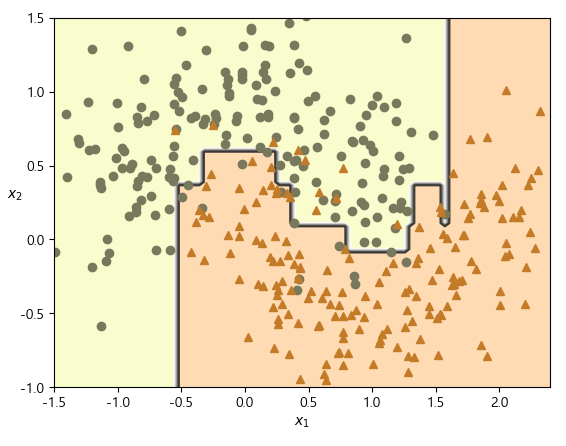
다음 내용
[머신러닝] 분류 - 앙상블 3 : GBM
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.앙상블 학습(Ensemble Learning) [
puppy-foot-it.tistory.com
[출처]
핸즈 온 머신러닝
위키백과
https://pro-jy.tistory.com/25
티스토리 블로그 '준비하는 대학생' https://gsbang.tistory.com/
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 차원 축소: 랜덤 투영, 지역 선형 임베딩 (3) | 2024.11.15 |
|---|---|
| [머신러닝] 차원 축소: 주성분 분석 (추가) (3) | 2024.11.15 |
| [머신러닝] 앙상블: 투표 기반 분류기, 배깅과 페이스팅 (0) | 2024.11.15 |
| [머신러닝] 결정 트리 (추가) (1) | 2024.11.14 |
| [머신러닝] 서포트 벡터 머신(SVM) (1) | 2024.11.14 |



