앙상블 학습
[머신러닝] 분류 - 앙상블 학습(Ensemble Learning)
앙상블 학습(Ensemble Learning) 앙상블 학습을 통한 분류는,여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법을 말한다. 앙상블 학습의 목표는,다양한
puppy-foot-it.tistory.com
투표 기반 분류기 - 직접 투표(hard voting)
더 좋은 분류기를 만드는 매우 간단한 방법은 각 분류기의 예측을 집계하는 것인데, 가장 많은 표를 얻은 클래스가 앙상블의 예측이 되며, 이렇게 다수결 투표로 정해지는 분류기를 직접 투표 (하드 보팅, hard voting) 분류기라고 한다.
이 다수결 투표 분류기가 앙상블에 포함된 개별 분류기 중 가장 뛰어난 것보다도 정확도가 높은 경우가 많은데, 각 분류기가 약한 학습기 일지라도 약한 학습기가 충분히 많고 다양하면 앙상블은 강한 학습기가 될 수 있다.
※ 약한 학습기(weak learner): 랜덤 추측보다 조금 더 높은 성능을 내는 분류기
이게 가능한 이유는 더 많은 시도를 할수록 확률이 증가하는 큰 수의 법칙 때문인데, 동전 던지기로 예를 들면 동전을 던졌을 때 앞면이 51%, 뒷면이 49%가 나오는 조금 균형이 맞지 않는 동전이 있다고 가정할 경우, 동전을 자꾸 던질수록 앞면이 다수가 될 확률은 10번에 비해 100번이, 100번에 비해 1000번이 더 높아진다.
아래는 균형이 틀어진 동전을 10번 실험하는 코드 및 그래프이다.
import matplotlib.pyplot as plt
import numpy as np
heads_proba = 0.51
np.random.seed(42)
coin_tosses = (np.random.rand(10000, 10) < heads_proba).astype(np.int32)
cumulative_heads = coin_tosses.cumsum(axis=0)
cumulative_heads_ratio = cumulative_heads / np.arange(1, 10001).reshape(-1, 1)
plt.figure(figsize=(8, 3.5))
plt.plot(cumulative_heads_ratio)
plt.plot([0, 10000], [0.51, 0.51], "k--", linewidth=2, label="51%")
plt.plot([0, 10000], [0.5, 0.5], "k-", label="50%")
plt.xlabel("동전을 던진 횟수")
plt.ylabel("앞면이 나온 비율")
plt.legend(loc="lower right")
plt.axis([0, 10000, 0.42, 0.58])
plt.grid()
plt.show()
▶ 던진 횟수가 증가할수록 앞면이 나올 확률 51%에 가까워지고, 결국 10번의 실험 모두 50%보다 높게 유지되며 51%에 수렴하며 끝나고 있다.
이와 비슷하게 51% 정확도를 가진 1,000개의 분류기로 앙상블 모델을 구축한다고 가정하면, 가장 많은 클래스를 예측으로 삼는다면 75%의 정확도를 기대할 수 있다. 그러나 이런 가정은 모든 분류기가 완벽하게 독립적이고 오차에 상관관계가 없어야 가능한데, 분류기들이 같은 종류의 오차를 만들기 쉽기 때문에 잘못된 클래스가 다수인 경우가 많고 앙상블의 정확도가 낮아진다.
앙상블 방법은 예측기가 가능한 한 서로 독립적일 때 최고의 성능을 발휘한다. 다양한 분류기를 얻는 한 가지 방법은 각기 다른 알고리즘으로 학습시키는 것이며, 이렇게 하면 매우 다른 종류의 오차를 만들 가능성이 높기 때문에 앙상블 모델의 정확도가 향상된다.
- 사이킷런은 이름/예측기 쌍의 리스트를 제공하기만 하면 일반 분류기처럼 쉽게 사용할 수 있는 VotingClassifier 클래스를 제공한다. 이를 moons 데이터셋에 사용해본다.
from sklearn.datasets import make_moons
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
voting_clf = VotingClassifier(
estimators=[
('lr', LogisticRegression(random_state=42)),
('rf', RandomForestClassifier(random_state=42)),
('svc', SVC(random_state=42))
]
)
voting_clf.fit(X_train, y_train)
- VotingClassifier를 훈련할 때 이 클래스는 모든 추정기를 복제하여 복제된 추정기를 훈련한다.
- 원본 추정기는 estimators 속성을 통해 참조할 수 있으며 훈련된 복제본은 estimators_ 속성에 저장된다.
- 리스트 대신 딕셔너리를 전달하는 경우 named_estimators 또는 named_estimators)를 사용할 수 있다.
- 테스트 세트에서 훈련된 각 분류기의 정확도를 살펴본다.
for name, clf in voting_clf.named_estimators_.items():
print(name, '=', clf.score(X_test, y_test))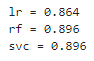
- 투표 기반 분류기의 predict() 메서드를 호출하면 직접 투표를 수행한다.
voting_clf.predict(X_test[:1]) # 테스트 세트의 첫 번째 샘플에 대한 예측
[clf.predict(X_test[:1]) for clf in voting_clf.estimators_]
▶ 이 투표 기반 분류기는 테스트 세트의 첫 번째 샘플에 대해 클래스 1을 예측하는데, 이는 세 분류기 중 두 분류기가 해당 클래스를 예측하기 때문이다.
- 테스트 세트에서 투표 기반 분류기의 성능을 살펴본다.
voting_clf.score(X_test, y_test)
▶ 투표 기반 분류기가 다른 개별 분류기보다 성능이 조금 더 높다.
투표 기반 분류기 - 간접 투표(soft voting)
모든 분류기가 (predict_proba() 메서드를 사용하여) 클래스의 확률을 예측할 수 있으면 개별 분류기의 예측을 평균 내어 확률이 가장 높은 클래스를 예측할 수 있으며, 이를 간접 투표(소프트 보팅, soft voting)이라 한다. 이 방식은 확률이 높은 투표에 비중을 더 두기 때문에 직접 투표 방식보다 성능이 높다.
이 방식을 사용하기 위해서는 투표 기반 분류기의 voting 매개변수를 'soft'로 바꾸고 모든 분류기가 클래스의 확률을 추정할 수 있도록 하면 된다.
SVC는 기본 값에서는 클래스 확률을 제공하지 않으므로 probability 매개변수를 True로 지정해야 하며, 이렇게 하면 클래스 확률을 추정하기 위해 교차 검증을 사용하므로 훈련 속도가 느려지지만 SVC에서 predict_proba() 메서드를 사용할 수 있다.
voting_clf.voting = 'soft'
voting_clf.named_estimators['svc'].probability= True
voting_clf.fit(X_train, y_train)
voting_clf.score(X_test, y_test)
▶ 간접 투표(소프트 보팅) 방식을 사용해 92%의 정확도를 얻었다.
배깅과 페이스팅
[다양한 분류기를 만드는 방법]
- 각기 다른 훈련 알고리즘을 사용하는 것
- 같은 알고리즘을 사용하고 훈련 세트의 서브셋을 랜덤으로 구성하여 분류기를 각기 다르게 학습하는 방식.
[배깅과 페이스팅]
배깅과 페이스팅에서는 같은 훈련 샘플을 여러 개의 예측기에 걸쳐 사용할 수 있고, 예측기는 동시에 다른 CPU 코어나 서버에서 병렬로 학습시킬 수 있다. 또한 이와 유사하게 예측도 병렬로 수행할 수 있는 확장성 덕분에 배깅과 페이스팅의 인기가 높다.
- 배깅: 훈련 세트에서 중복을 허용하여 샘플링하는 방식. 한 예측기를 위해 같은 훈련 샘플을 여러 번 샘플링 할 수 있다. bootstrap aggregating의 줄임말
- 페이스팅: 중복을 허용하지 않고 샘플링하는 방식.
모든 예측기가 훈련을 마치면 앙상블은 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 만든다.
집계 함수는 일반적으로 분류일 때는 통계적 최빈값을, 회귀에 대해서는 평균을 계산한다.
※ 통계적 최빈값: 가장 많은 예측 결과
개별 예측기는 원본 훈련 세트로 훈련시킨 것보다 훨씬 크게 편향되어 있지만 집계 함수를 통과하면 편향과 분산이 모두 감소한다. 일반적으로 앙상블의 결과는 원본 데이터셋으로 하나의 예측기를 훈련시킬 때와 비교해 편향은 비슷하지만 분산은 줄어든다.
배깅은 각 예측기가 학습하는 서브셋에 다양성을 추가하므로 배깅이 페이스팅보다 편향이 조금 더 높다. 하지만 다양성을 추가한다는 것은 예측기들의 상관관계를 줄이므로 다양성의 분산이 줄어든다는 것을 의미한다.
전반적으로 배깅이 더 나은 모델을 만들기 때문에 일반적으로 더 선호되나, 시간과 CPU 파워에 여유가 있다면 교차 검증으로 배깅과 페이스팅 모두 평가해서 더 나은 쪽을 선택하는 것이 좋다.
[사이킷런의 배깅과 페이스팅]
사이킷런은 배깅과 페이스팅을 위해 간편한 API로 구성된 BaggingClassifier (회귀는 BaggingRegressor)를 제공한다.
◆ 결정 트리에서 500개의 앙상블을 훈련시키기
- 각 분류기는 훈련 세트에서 중복을 허용하여 랜덤으로 선택된 100개의 샘플로 훈련된다. (배깅)
- 만약, 페이스팅을 사용하려면 bootstrap=False로 지정하면 된다.
- n_jobs 매개변수는 사이킷런이 훈련과 예측에 사용할 CPU 코어 수를 지정하며, -1로 지정하면 가용한 모든 코어를 사용한다.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
max_samples=100, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
※ BaggingClassifier는 기반이 되는 분류기가 결정 트리 분류기처럼 클래스 확률을 추정할 수 있으면 (predict_proba() 함수가 있으면) 직접 투표 대신 자동으로 간접 투표 방식을 사용한다.
아래는 단일 결정 트리의 결정 경계와 500개의 트리를 사용한 배깅 앙상블의 결정 경계를 비교한 것이며, 둘 다 moons 데이터셋에 훈련시켰다.
def plot_decision_boundary(clf, X, y, alpha=1.0):
axes=[-1.5, 2.4, -1, 1.5]
x1, x2 = np.meshgrid(np.linspace(axes[0], axes[1], 100),
np.linspace(axes[2], axes[3], 100))
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
plt.contourf(x1, x2, y_pred, alpha=0.3 * alpha, cmap='Wistia')
plt.contour(x1, x2, y_pred, cmap="Greys", alpha=0.8 * alpha)
colors = ["#78785c", "#c47b27"]
markers = ("o", "^")
for idx in (0, 1):
plt.plot(X[:, 0][y == idx], X[:, 1][y == idx],
color=colors[idx], marker=markers[idx], linestyle="none")
plt.axis(axes)
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$", rotation=0)
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
fig, axes = plt.subplots(ncols=2, figsize=(10, 4), sharey=True)
plt.sca(axes[0])
plot_decision_boundary(tree_clf, X_train, y_train)
plt.title("결정 트리")
plt.sca(axes[1])
plot_decision_boundary(bag_clf, X_train, y_train)
plt.title("배깅을 사용한 결정 트리")
plt.ylabel("")
plt.show()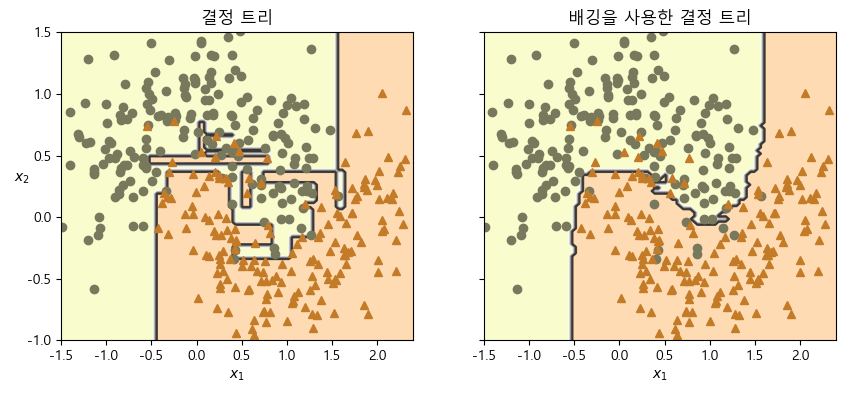
▶ 앙상블의 예측이 결정 트리 하나의 예측보다 일반화가 훨씬 잘된 것으로 보여진다.
앙상블은 훈련 세트의 오차 수가 거의 동일하지만 결정 경계는 덜 불규칙하며, 비슷한 편향에서 더 작은 분산을 만든다.
OOB 평가
배깅을 사용하면 어떤 샘플을 한 예측기를 위해 여러 번 샘플링되고 어떤 것은 전혀 선택되지 않을 수 있다.
BaggingClassifier는 기본값으로 중복을 허용하여 (bootstrap=True) 훈련 세트의 크기만큼 m개 샘플을 선택하며, 이는 평균적으로 각 예측기에 훈련 샘플의 63% 정도만 샘플링된다는 것을 의미한다.
선택되지 않은 나머지 37%를 OOB(Out-of-bag) 샘플이라고 부르며, 예측기마다 남겨진 37% 모두 다르다.
예측기가 훈련되는 동안에는 OOB 샘플을 사용하지 않으므로 별도의 검증 세트를 사용하지 않고 OOB 샘플을 사용해 평가할 수 있다. 앙상블의 평가는 각 예측기의 OOB 평가를 평균하여 얻는다.
사이킷런에서 BaggingClassifier를 만들 때 oob_score=True로 지정하면 훈련이 끝난 후 자동으로 OOB 평가를 수행한다.
평가 점수 결과는 oob_score_ 변수에 저장되어 있다.
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
oob_score=True, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_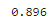
▶ OOB 평가 결과를 보면 이 BaggingClassifier는 테스트 세트에서 약 89.6%의 정확도를 얻을 것으로 보인다.
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)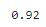
▶ 테스트 세트에서 92%의 정확도를 얻었다.
OOB 샘플에 대한 결정 함수의 값도 oob_decision_function_ 변수에서 확인할 수 있다. 기반이 되는 예측기가 predict_proba() 메서드를 가지고 있기 때문에 결정함수는 각 훈련 샘플의 클래스 확률을 반환한다.
bag_clf.oob_decision_function_[:3] # 처음 3개의 샘플에 대한 확률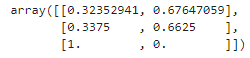
▶ OOB 평가는 첫 번째 훈련 샘플이 양성 클래스에 속할 확률을 약 67.6%, 음성 클래스에 속할 확률을 약 32.4%로 추정하고 있다.
랜덤 패치와 랜덤 서브스페이스
BaggingClassifier는 특성 샘플링도 지원하는데, 샘플링은 max_features, bootstrap_features 두 매개변수로 조절된다. max_samples, bootstrap과 동일한 방식으로 작동하지만 샘플이 아닌 특성에 대한 샘플링에 사용되며, 따라서 각 예측기는 랜덤으로 선택한 입력 특성의 일부분으로 훈련된다.
이 기법은 훈련 속도를 크게 높일 수 있기 때문에 특히 이미지와 같은 매우 고차원의 데이터셋을 다룰 때 유용하다.
- 랜덤 패치 방식(random patches method): 훈련 특성과 샘플을 모두 샘플링하는 것
- 랜덤 서브스페이스 방식(random subspaces method): 훈련 샘플을 모두 사용하고 특성을 샘플링하는 것. 훈련 샘플 ▶(bootstrap=False, max_samples=1.0으로 설정) / 특성 ▶ bootstrap_features=True 또는 max_features는 1.0보다 작게 설정
특성 샘플링은 더 다양한 예측기를 만들며 편향을 늘리는 대신 분산을 낮춘다.
다음 내용
[머신러닝] 분류 - 앙상블 2 : 랜덤 포레스트
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.앙상블 학습(Ensemble Learning) [
puppy-foot-it.tistory.com
[출처]
핸즈 온 머신러닝
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 차원 축소: 주성분 분석 (추가) (3) | 2024.11.15 |
|---|---|
| [머신러닝] 앙상블 : AdaBoost (2) | 2024.11.15 |
| [머신러닝] 결정 트리 (추가) (1) | 2024.11.14 |
| [머신러닝] 서포트 벡터 머신(SVM) (1) | 2024.11.14 |
| [머신러닝] 모델 훈련 - 2 (3) | 2024.11.13 |



