인공 신경망
[딥러닝] 인공 신경망(ANN)
머신러닝 기반 분석 모형 선정 [머신러닝] 머신러닝 기반 분석 모형 선정머신러닝 기반 분석 모형 선정 지도 학습, 비지도 학습, 강화 학습, 준지도 학습, 전이 학습 1) 지도 학습: 정답인 레
puppy-foot-it.tistory.com
퍼셉트론(perceptron), 다층 퍼셉트론 (MLP)
[딥러닝] 인공 신경망: 퍼셉트론, 다층 퍼셉트론
머신러닝 기반 분석 모형 선정 [머신러닝] 머신러닝 기반 분석 모형 선정머신러닝 기반 분석 모형 선정 지도 학습, 비지도 학습, 강화 학습, 준지도 학습, 전이 학습 1) 지도 학습: 정답인 레이
puppy-foot-it.tistory.com
케라스
케라스는 신경망 구축, 훈련, 평가, 실행을 목적으로 설계된 멋지고 간결한 고수준 API이며, 아주 다앙햔 신경망 구조를 만들 수 있을 만큼 유연하고 표현력이 뛰어나다.

텐서플로의 문제를 해결하기 위해 보다 단순화된 인터페이스를 제공하는 케라스가 개발되었다. 케라스의 핵심적인 데이터 구조는 모델이다.
원래는 신경망 구축을 위한 고수준 API였으나 현재는 TensorFlow의 일부로 통합되었다 (tf.keras). 신경망 모델을 쉽게 구축하고 훈련할 수 있도록 사용자 친화적인 인터페이스를 제공한다. Keras는 신속한 실험과 프로토타입 제작에 적합하다.
케라스에서 제공하는 시퀀스 모델로 원하는 레이어를 쉽게 순차적으로 쌓을 수 있으며, 다중 출력 등 더 복잡한 모델을 구성할 때는 케라스 함수 API를 사용하여 쉽게 구성할 수 있다. 이처럼 케라스는 딥러닝 초급자도 각자 분야에서 손쉽게 딥러닝 모델을 개발하고 활용할 수 있도록 직관적인 API를 제공한다.
케라스로 다층 퍼셉트론 구현하기
◆ 패션 MNIST 로 이미지 분류기 만들기
MNIST와 형태가 같은 10개의 클래스로 이루어진 28*28 픽셀 크기의 흑백 이미지 70,000개로 이루어졌지만, 손글씨가 아닌 패션 아이템을 나타내는 이미지이다. 클래스마다 샘플이 더 다양해 MNIST 보다 훨씬 어려운 문제다.

◆ 케라스로 데이터셋 적재하기
케라스는 MNIST, 패션MNIST 데이터셋 등 다양한 데이터셋을 다운로드하고 적재할 수 있는 유틸리티 함수를 제공한다.
데이터셋을 로드하고, 훈련 세트(60,000개 이미지)와 테스트 세트(10,000개 이미지)로 분할되어 있는 이미지를 검증 세트를 위해 훈련 세트의 마지막 5,000개 이미지를 떼어놓는다.
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist.load_data()
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist
X_train, y_train = X_train_full[:-5000], y_train_full[:-5000]
X_valid, y_valid = X_train_full[-5000:], y_train_full[-5000:]
print(X_train.shape)
print(X_train.dtype)
텐서플로는 일반적으로 tf로 임포트하며, tf.keras 로 케라스 API를 사용할 수 있다.
사이킷런 대신 케라스를 사용하여 MNIST (패션 MNIST 포함) 데이터를 적재할 때 중요한 차이점은 각 이미지가 784 크기의 1D 배열이 아니라 28*28 배열이라는 것이다.
또한, 픽셀 강도가 실수 (0.0~255.0)가 아니라 정수(0~255)로 표현되어 있다.
간단히 픽셀 강도를 255.0으로 나누어 0~1 사이 범위로 조정한다.
X_train, X_valid, X_test = X_train / 255., X_valid / 255., X_test / 255.
MNIST 와 달리 패션 MNIST는 레이블에 해당하는 아이템을 나타내기 위해 클래스 이름의 리스트를 만들어야 한다.
(MNIST의 경우, 레이블이 5이면 이미지가 손글씨 숫자 5라는 의미)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# 훈련 세트에 있는 첫 번째 이미지의 레이블 확인
class_names[y_train[0]]
▶ 훈련 세트에 있는 첫 번째 이미지는 앵클 부츠를 나타낸다
◆ 시퀀셜 API로 모델 만들기
신경망을 만드는데, 아래는 두 개의 은닉 층으로 이루어진 분류용 다층 퍼셉트론을 만드는 코드이다.
tf.random.set_seed(42)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Input(shape=[28, 28]))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(300, activation='relu'))
model.add(tf.keras.layers.Dense(100, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
[코드 설명]
- 결과를 재현할 수 있도록 텐서플로의 랜덤 시드 설정. 은닉 층과 출력 층의 랜덤한 가중치가 노트북을 실행할 때마다 동일하게 유지. ▶ tf.keras.utils.set_random_seed() 함수를 사용해 텐서플로, 파이썬(random.seed()), 넘파이(np.random.seed())의 랜덤 시드를 편리하게 설정
- Sequential 모델 생성. 이 모델은 가장 간단한 케라스의 신경망 모델이며, 순서대로 연결된 층을 일렬로 쌓아서 구성.
- 첫 번째 층(Input 층)을 만들어 모델에 추가. 배치 크기는 포함하지 않고 샘플의 크기만 담은 shape 매개변수 지정. ▶ 케라스는 입력의 크기를 알아야 첫 번째 은닉 층의 연결 가중치 행렬의 크기를 결정할 수 있음.
- Flatten 층 추가. 이 층의 역할은 각 입력 이미지를 1D 배열로 변환하는 것. 예를 들어, [32, 28, 28] 크기의 배치를 받으면 [32, 784] 로 크기를 변경한다. 즉, 입력 데이터 X를 받으면 X.reshape(-1, 784)를 계산. 이 층은 매개변수가 없으며 간단한 전처리만 수행
- 뉴런 300개를 가진 Dense 은닉 층 추가. 이 층은 ReLU 활성화 함수를 사용하며, Dense 층마다 각자 가중치 행렬을 관리. 이 행렬에는 층의 뉴런과 입력 사이의 모든 연결 가중치가 포함되며, 뉴런마다 하나씩 있는 편향도 벡터로 관리한다.
- 뉴런 100개를 가진 두 번째 Dense 은닉 층 추가. 이 층도 ReLU 활성화 함수 사용
- 클래스마다 하나씩 뉴런 10개를 가진 Dense 출력 층 추가. 이 층은 배타적인 클래스이므로 Softmax 활성화 함수 사용.
상단의 코드처럼 층을 하나씩 추가하지 않고 Sequential 모델을 만들 때 층의 리스트를 전달하면 더 편리하며, Input 층 대신에 첫 번째 층에 input_shape를 지정할 수 있다.
또한 모델의 summary() 메서드는 모델에 있는 모든 층을 출력한다.
tf.random.set_seed(42)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28]),
tf.keras.layers.Dense(300, activation='relu'),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 모델에 있는 모든 층 출력
model.summary()
▶ 출력 내용
- 각 층의 이름(층을 만들 때 지정하지 않으면 자동으로 생성) ▶ 모델 간에 이름을 고유하게 만드는 이유는 이름 충돌 없이 모델을 쉽게 병합할 수 있기 때문이다.
- 출력 크기(None은 배치 크기에 어떤 값도 가능하다는 의미)
- 파라미터 개수
- 전체 파라미터 개수
- 훈련되는 파라미터
- 훈련되지 않은 파라미터 개수
layers 속성을 사용하여 모델의 총 목록을 쉽게 얻을 수 있으며 get_layers() 메서드를 사용하여 층 이름으로 층을 선택할 수 있다.
model.layers
hidden1 = model.layers[1]
hidden1.name
model.get_layer('dense') is hidden1
층의 모든 파라미터는 get_weights() 메서드와 set_weights() 메서드를 사용해 접근할 수 있다.
weights, biases = hidden1.get_weights()
weights
weights.shape
biases
biases.shape
▶ Dense 층의 경우 연결 가중치와 편향이 모두 포함되어 있다.
◆ 모델 컴파일
모델을 만들고 compile() 메서드를 호출하여 사용할 손실 함수와 옵티마이저를 지정해야 하며, 부가적으로 훈련과 평가 시에 계산할 지표를 지정할 수 있다.
model.compile(loss='sparse_categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
[코드 설명]
- 레이블이 정수 하나로 이루어져 있고 클래스가 배타적이므로 ''sparse_categorical_crossentropy' 손실 사용. (만약 샘플마다 클래스별 타깃 확률을 갖고 있다면 ' categorical_crossentropy' 손실 사용)
-
- 이진 분류나 다중 레이블 이진 분류를 수행한다면 출력 층에 'softmax' 함수 대신 'sigmoid' 함수를 사용하고 'binary_crossentropy' 손실 사용
- 옵티마이저에 'sgd' 를 지정하면 확률적 경사 하강법을 사용하여 모델을 훈련한다는 의미이며, 다른 의미로 하면 역전파 알고리즘 수행 (SGD 옵티마이저를 사용할 때 학습률을 튜닝하는 것이 중요하여 보통 optimizer=tf.keras.optimizers.SGD(learning_rate=??)와 같이 학습률을 지정. 기본값은 learning_rate=0.01)
- 분류기이므로 훈련과 평가 시에 정확도를 측정하는 것이 유용하므로 metrics=['accuracy']
◆ 모델 훈련과 평가
모델을 훈련하려면 fit() 메서드 호출
hisotry = model.fit(X_train, y_train, epochs=30,
validation_data =(X_valid, y_valid))
▶ 입력 특성(X_train)과 타깃 클래스(y_train), 훈련할 에포크 횟수(미지정 시 기본값은 1)를 전달하고, 검증 세트 전달(이는 선택 사항)
케라스는 에포크가 끝날 때마다 검증 세트를 사용해 손실과 추가적인 측정 지표를 계산하는데, 이 지표는 모델이 얼마나 잘 수행하는지 확인하는 데 유용하다. 훈련 세트 성능이 검증 세트보다 월등히 높다면 아마도 모델이 훈련 세트에 과대적합되었거나, 훈련 세트와 검증 세트 간의 데이터 불일치 등의 버그가 있을 수 있다.
★ 가중치 관련 매개변수
어떤 클래스는 많이 등장하고 다른 클래스는 조금 등장하여 훈련 세트가 편중되어 있다면 fit() 메서드 호출 시 class_weight 매개변수를 지정하는 것이 좋다. 이렇게 하면 적게 등장하는 클래스는 높은 가중치를 부여하고 많이 등장하는 클래스는 낮은 가중치를 부여하며, 케라스가 손실을 계산할 때 이 가중치를 사용한다.
샘플별로 가중치를 부여하고 싶다면 sample_weight 매개변수를 지정하며, class_weight와 sample_weight가 모두 지정되면 케라스는 두 값을 곱하여 사용한다.
validation_data 듀플의 세 번째 원소로 검증 세트에 대한 샘플별 가중치를 지정할 수도 있다. (클래스 가중치는 지정 불가)
◆ 학습 곡선 시각화
fit() 메서드가 반환하는 history 객체에는 훈련 파라미터 (history.params), 수행된 에포크 리스트(history.epoch)가 포함된다. 이 객체의 가장 중요한 속성은 에포크가 끝날 때마다 훈련 세트와 검증 세트(검증 세트 부여 시)에 대한 손실과 측정한 지표를 담은 딕셔너리(history.history) 이다.
이 딕셔너리를 사용해 판다스 DataFrame을 만들고 plot() 메서드를 호출하여 학습 곡선을 시각화해 본다.
import matplotlib.pyplot as plt
import pandas as pd
pd.DataFrame(history.history).plot(
figsize=(8,5), xlim=[0, 29], ylim=[0, 1], grid=True, xlabel='에포크',
style=['r--', 'r--.', 'b-', 'b-*'])
plt.show()
▶ 훈련하는 동안 정확도(accuracy)와 검증 정확도(val_accuracy)가 상승하는 것을 볼 수 있다.
일반적으로 충분히 오래 훈련하면 훈련 세트의 성능이 검증 세트의 성능을 앞지른다. 검증 손실이 여전히 감소한다면 모델이 완전히 수렴되지 않았다고 볼 수 있어 훈련을 계속 해야할 것이다. 케라스에서는 fit() 메서드를 다시 호출하면 중지되었던 곳에서부터 훈련을 이어갈 수 있다.
[모델 성능 개선 방안]
- 모델 성능이 만족스럽지 않다면 처음으로 되돌아가서 하이퍼파라미터를 튜닝해야 하는데, 맨처음 확인할 것은 학습률이다.
- 학습률이 도움이 되지 않는다면 다른 옵티마이저를 테스트해야 하는데, 항상 다른 옵티마이저를 바꾼 후에는 학습률을 다시 튜닝해야 한다.
- 여전히 성능이 높지 않으면 층 개수, 층에 있는 뉴런 개수, 은닉 층이 사용하는 활성화 함수와 같은 모델의 하이퍼파라미터를 튜닝해 본다.
- 배치 크기와 같은 다른 하이퍼파라미터를 튜닝해볼 수도 있다 (fit() 메서드 호출 시 batch_size 매개변수로 지정, 기본값은 32)
모델의 검증 정확도가 만족 스럽다면 모델을 제품 환경으로 배포하기 전에 테스트 세트로 모델을 평가하여 일반화 오차를 추정해야 하며, 이때 evaluate() 메서드를 사용한다.
이 메서드는 batch_size와 sample_weight 같은 다른 매개변수도 지원한다.
model.evaluate(X_test, y_test)
▶ 테스트 세트에서 하이퍼파라미터를 튜닝하면 절대 안 된다. 그렇지 않으면 일반화 오차를 매우 낙관적으로 추정하게 된다.
◆ 모델로 예측 만들기
모델의 predict() 메서드를 사용해 새로운 샘플에 대해 예측을 만들 수 있다.
(여기서는 실제 샘플이 없으므로 테스트 세트의 처음 3개 샘플 사용)
X_new = X_test[:3]
y_proba = model.predict(X_new)
y_proba.round(2)
▶ 모델은 각 샘플에 대해서 0부터 9까지 클래스마다 각각의 확률을 추정했으며, 이는 사이킷런 분류기의 predict_proba() 메서드 출력과 비슷하다.
첫 번째 이미지: 클래스 9(앵클 부츠)의 확률 94%
두 번째 이미지: 클래스 2(풀오버)의 확률 100%
세 번째 이미지: 클래스 1(트루저)의 확률 100%
가장 높은 확률을 가진 클래스에만 관심이 있다면 argmax() 메서드를 사용하여 각 샘플에 대해 가장 높은 확률의 클래스 인덱스를 얻을 수 있다.
import numpy as np
y_pred = y_proba.argmax(axis=1)
y_pred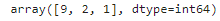
np.array(class_names)[y_pred]
y_new = y_test[:3]
y_new
세 개의 이미지를 맞게 분류했는지 이미지를 불러와보면
plt.figure(figsize=(7.2, 2.4))
for index, image in enumerate(X_new):
plt.subplot(1, 3, index + 1)
plt.imshow(image, cmap="binary", interpolation="nearest")
plt.axis('off')
plt.title(class_names[y_test[index]])
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()
▶ 이 분류기는 세 개의 이미지 모두 올바르게 분류했다.
다음 내용
[딥러닝] 케라스로 다층 퍼셉트론 구현하기 - 2
인공 신경망 [딥러닝] 인공 신경망(ANN)머신러닝 기반 분석 모형 선정 [머신러닝] 머신러닝 기반 분석 모형 선정머신러닝 기반 분석 모형 선정 지도 학습, 비지도 학습, 강화 학습, 준지도
puppy-foot-it.tistory.com
[출처]
핸즈 온 머신러닝
'[파이썬 Projects] > <파이썬 딥러닝, 신경망>' 카테고리의 다른 글
| [딥러닝] 케라스로 다층 퍼셉트론 구현하기 - 3 (1) | 2024.11.20 |
|---|---|
| [딥러닝] 케라스로 다층 퍼셉트론 구현하기 - 2 (0) | 2024.11.20 |
| [딥러닝] 인공 신경망: 퍼셉트론, 다층 퍼셉트론 (1) | 2024.11.19 |
| [딥러닝] 인공 신경망(ANN) (2) | 2024.11.19 |
| [딥러닝] Deep Learning 기본 개념 및 문제 (1) | 2024.09.25 |



