이전 내용
[딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 3
이전 내용 [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 2이전 내용 [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 1이전 내용 [딥러닝] 객체 탐지, 객체 추적이전 내용 [딥러닝] 케라스의
puppy-foot-it.tistory.com
Char-RNN
◆ Char-RNN(문자 기반 순환신경망)
Char-RNN은 문자 단위(Character-level)로 텍스트 데이터를 생성하거나 예측하는 순환 신경망(RNN) 모델로, 이 모델은 텍스트를 단어 단위가 아닌 문자 단위로 처리하며, 텍스트 생성, 언어 모델링, 문서 분류 등의 다양한 자연어 처리 문제에 사용된다.
- 주요 특징
- 문자 단위 처리: Char-RNN은 텍스트를 문자 단위로 처리하여 각 문자를 개별 입력으로 받는다. 이를 통해 알파벳, 숫자, 특수 문자 등 다양한 문자들을 학습할 수 있다.
- 순차 학습: RNN 구조를 이용하여 입력된 문자의 순서를 학습한다. 이전 시점의 문맥을 기억하며 이후 시점의 문자를 예측하는 데 사용할 수 있다.
- 다양한 응용 분야: 텍스트 생성, 언어 모델링, 철자 교정, 코드 자동 완성 등 여러 자연어 처리 작업에 응용할 수 있다.
- Char-RNN의 구조
Char-RNN의 구조는 일반적인 RNN 구조와 동일하지만, 텍스트를 문자 단위로 처리하기 위해 특화되어 있다.
- 입력 임베딩(Input Embedding): 각 문자를 고정된 크기의 벡터로 변환한다. 이는 대개 원-핫 인코딩(One-Hot Encoding) 또는 임베딩 레이어(Embedding Layer)를 통해 수행된다.
- 순환 신경망(RNN, LSTM, GRU 등): 순차 데이터를 처리하기 위해 RNN 셀을 사용한다. 각 타임 스텝에서 입력된 문자를 기반으로 은닉 상태를 업데이트한다. LSTM(Long Short-Term Memory) 또는 GRU(Gated Recurrent Unit) 같은 셀을 사용하여 장기 의존성 문제를 해결할 수 있습니다.
- 출력 레이어(Output Layer): 최종 출력 레이어는 다음 문자의 확률 분포를 예측한다. 이는 대개 소프트맥스(Softmax) 함수를 사용하여 각 문자에 대한 확률을 계산한다.
- Char-RNN의 작동 방식
Char-RNN의 학습과 예측 과정은 다음과 같다:
1) 학습
입력 텍스트를 일정한 길이의 시퀀스로 분할하여 RNN에 입력한다.
각 타임스텝에서 다음 문자를 예측하도록 모델을 학습시킨다. 예를 들어, 문자 시퀀스 "hello"가 주어지면, 'h' 다음에 'e', 'e' 다음에 'l', 'l' 다음에 'o'를 예측하도록 학습한다. 손실 함수로는 주로 교차 엔트로피 손실(Categorical Cross-Entropy Loss)을 사용한다.
2)예측
학습된 모델을 사용하여 시드 문자(Seed Character)로부터 시작하여 다음 문자를 계속해서 예측한다.
예를 들어, 시드 문자 'h'를 입력으로 주면, 'h' 다음에 올 문자를 예측하고, 그다음 문자를 예측하여 텍스트를 생성한다.
◆ Char-RNN으로 세익스피어 문체 생성하기
1) 훈련 데이터셋 만들기
케라스의 tf.keras.utils.get_file() 함수를 사용해 안드레이 카르파시의 Char-RNN 프로젝트에서 셰익스피어 작품을 모두 다운로드 한다.
shakespeare_url = 'http://homl.info/shakespeare'
filepath = tf.keras.utils.get_file('shakespeare.txt', shakespeare_url)
with open(filepath) as f:
shakespeare_text = f.read()
# 파일이 잘 다운로드 됐는지 확인
print(shakespeare_text[:80])
tf.keras.layers.TextVectorization 층을 사용해 이 텍스트를 인코딩하는 데, 기본 단어 수준 인코딩 대신에 split='character'로 설정해 문자 수준 인코딩을 한다. 작업을 간단히 하기 위해 standardize='lower'를 사용해 텍스트를 소문자로 바꾼다.
각 문자는 2부터 시작하는 정수에 매핑된다. TextVectorization 층은 패딩 토큰을 위해 0을 사용하고 알려지지 않은 문자를 위해 1을 사용한다. 지금은 이런 토큰이 모두 필요치 않으므로 문자 ID에서 2를 빼서 고유한 문자 개수와 총 문자 개수를 계산해본다.
text_vec_layer = tf.keras.layers.TextVectorization(split='character',
standardize='lower')
text_vec_layer.adapt([shakespeare_text])
encoded = text_vec_layer([shakespeare_text])[0]
encoded -= 2 # 토큰 0(패딩 토큰)과 1(알려지지 않은 문자)을 사용하지 않으므로 무시
n_tokens = text_vec_layer.vocabulary_size() - 2 # 고유한 문자 개수
dataset_size = len(encoded) # 총 문자 개수
print(n_tokens)
print(dataset_size)
그리고 매우 긴 이 시퀀스를 시퀀스-투-시퀀스 RNN을 훈련하는 데 사용할 수 있도록 윈도의 데이터셋으로 바꾼다. 타깃은 입력과 비슷하지만 한 타임 스텝 미래로 이동한다.
문자 ID로 구성된 긴 시퀀스를 입력과 타깃 윈도 쌍의 데이터셋으로 변환하는 작은 유틸리티 핫무를 작성한다.
def to_dataset(sequence, length, shuffle=False, seed=None, batch_size=32):
ds = tf.data.Dataset.from_tensor_slices(sequence)
ds = ds.window(length + 1, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda window_ds: window_ds.batch(length + 1))
if shuffle:
ds = ds.shuffle(buffer_size=100_000, seed=seed)
ds = ds.batch(batch_size)
return ds.map(lambda window : (window[:, :-1], window[:, 1:])).prefetch(1)[코드 설명]
- 시퀀스(인코딩된 텍스트)를 입력으로 받고 원하는 길이의 모든 윈도를 담은 데이터셋 생성
- 타깃을 위한 다음 문자가 필요하기 때문에 길이를 하나 증가 시킴
- 선택적으로 윈도를 섞고, 배치로 묶고, 입력/출력 쌍으로 나누고, 프리페칭 활성화
이제 훈련 세트(90%), 검증 세트(5%), 테스트 세트(5%)를 만든다.
length = 100
tf.random.set_seed(42)
train_set = to_dataset(encoded[:1_000_000], length=length, shuffle=True, seed=42)
valid_set = to_dataset(encoded[1_000_000:1_600_000], length=length)
test_set = to_dataset(encoded[1_600_000:], length=length)
2) Char-RNN 모델 만들고 훈련하기
언어 모델링은 데이터셋이 매우 크기 때문에 순환 뉴런 몇 개를 가진 단순한 RNN 이상의 것이 필요하다. 128개의 유닛으로 구성된 하나의 GRU 층을 가진 모델을 구축하고 훈련해본다.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=n_tokens, output_dim=16),
tf.keras.layers.GRU(128, return_sequences=True),
tf.keras.layers.Dense(n_tokens, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer='nadam',
metrics=['accuracy'])
model_ckpt = tf.keras.callbacks.ModelCheckpoint(
'my_shakespeare_model.keras', monitor='val_accuracy', save_best_only=True)
history = model.fit(train_set, validation_data=valid_set, epochs=10,
callbacks=[model_ckpt])[코드 설명]
- Embedding 층을 사용하여 문자 ID 인코딩. Embedding 층의 입력 차원 수는 고유한 문자 ID의 개수이며, 출력 차원 수는 조정할 수 있는 하이퍼파라미터로 여기서는 16. Embedding 층의 입력은 크기가 [배치 크기, 윈도 길이]인 2D 텐서이나 Embedding 층의 출력은 크기가 [배치 크기, 윈도 길이, 임베딩 크기]인 3D 텐서가 된다
- 출력 층에 Dense 층을 사용. 텍스트에 39개의 고유 문자가 있고 가능한 각 문자에 대한 확률을 출력하고 싶기 때문에 출력 층은 39개의 유닛(n_tokens)을 가져야 한다. 39개 출력의 확률의 합은 각 타임 스텝마다 1어야 하므로 Dense 층의 출력에 소프트맥스 활성화 함수 적용.
- 'sparse_categorical_crossentropy' 손실과 Nadam 옵티마이저를 사용하여 이 모델을 컴파일하고 여러 에포크 동안 모델을 훈련한다. 훈련이 진행됨에 따라 ModelCheckpoint 콜백을 사용하여 검증 정확도 측면에서 최적의 모델을 저장한다.
※ 상단의 코드를 실행하면 꽤 오랜 시간이 소요된다.
이 모델은 텍스트 전처리를 포함하지 않으므로, 첫 번째 층으로 tf.keras.layers.TextVectorization 층을 포함한 최종 모델로 감싼다. 또한 지금은 패딩과 알려지지 않은 문자를 위한 토큰을 사용하지 않으므로 tf.keras.layers.lambda 층을 사용해 문자 ID에서 2를 뺀다.
shakespeare_model = tf.keras.Sequential([
text_vec_layer,
tf.keras.layers.Lambda(lambda X: X - 2), # <PAD>와 <UNK' 토큰 제외
model
])
여기까지 진행한 후, 추후에는 훈련된 모델을 불러올 것이므로, keras 파일로 저장
model.save('jun_shakespeare_model.keras')
저장이 잘 됐는지, 로드하여 확인
shakespeare_mode = tf.keras.models.load_model('jun_shakespeare_model.keras')▶ RNN의 대부분 프로젝트는 gpu 사용이 요구되므로 (또는 gpu 사용 시 수행 속도가 훨씬 빠르므로), 되도록 코랩으로 진행하는 게 좋을 거 같다. (최종적으로는 주피터노트북에 gpu를 연결하는 방식으로 해결)
* 이틀 넘게 고생한 부분.
결국, 사전 훈련 모델 + GPU 사용 등 설정에 애먹어서 더 이상 시간을 지체할 수 없기 때문에 구글 코랩에서 진행하기로 변경. 코랩에서는 GPU를 사용할 수 있기 때문에, 시간적으로나, 정신적으로나 코랩에서 진행하는 게 훨 낫다.
추가로, 나중에 코랩의 코드를 주피터노트북으로 다운 받을 수 있다고 하니 나중에 다운받으면 될 듯 싶다.
# (시간 관계상) 사전 훈련된 모델 다운로드
from tensorflow.keras.models import save_model
url = "https://github.com/ageron/data/raw/main/shakespeare_model.tgz"
path = tf.keras.utils.get_file("shakespeare_model.tgz", url, extract=True)
model_path = Path(path).with_name("shakespeare_model")
# SavedModel 형식의 모델을 로드
shakespeare_model = tf.keras.layers.TFSMLayer(str(model_path), call_endpoint='serving_default')사전 훈련된 모델을 다운 받아 하려다가, 후속 과정 진행에 차질이 생겨서 그냥 구글 코랩에서 GPU 를 사용하여 모델을 훈련 뒤에 keras 파일로 저장하기로 변경했다.
▶ 코랩으로도 다운 먹어서 주피터노트북에 gpu를 연결해서 사용하는 방식으로 해결.
[문제 해결] 주피터노트북에 GPU 연결하기
GPU vs CPU출처: 챗GPT ◆ CPU (Central Processing Unit) - 특징 CPU는 범용 프로세서로, 다양한 작업을 처리하는 데 최적화되어 있습니다. 소수의 강력한 코어를 가지고 있어 다중 작업 처리에 적합합
puppy-foot-it.tistory.com
이제 이 모델을 사용해 시퀀스의 다음 문자를 예측해본다.
y_proba = shakespeare_model.predict(['To be or not to b'])[0, -1]
y_pred = tf.argmax(y_proba)
text_vec_layer.get_vocabulary()[y_pred+2]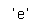
▶ 모델이 다음 글자를 정확히 예측했다.
가짜 셰익스피어 텍스트 생성하기
Char-RNN 모델을 사용해 새로운 텍스를 생성하기 위해 먼저 초기 텍스트를 주입하고 모델이 가장 가능성 있는 다음 글자를 예측한다. 그리고 예측한 글자를 텍스트 끝에 추가하고 늘어난 텍스트를 모델에 전달하여 다음 글자를 예측한다. 이를 그리디 디코딩(Greedy Decoding) 이라고 하는데, 이렇게 하면 같은 단어가 계속 반복되는 경우가 많다.
따라서 이 대신에 텐서플로의 tf.random.categorical() 함수를 사용해 모델이 추정한 확률을 기반으로 다음 글자를 랜덤으로 선택할 수 있다. 이 방식은 더 다양하고 흥미로운 텍스트를 생성한다.
categorical() 함수는 클랫의 로그 확률을 전달하면 랜덤하게 클래스 인덱스를 샘플링하는 데, 생성된 텍스트의 다양성을 더 많이 제어하려면 온도라고 불리는 숫자로 로짓(로그 확률)을 나눈다.
log_probas = tf.math.log([[0.5, 0.4, 0.1]]) # 확률: 50%, 40%, 10%
tf.random.set_seed(42)
tf.random.categorical(log_probas, num_samples=8) # 8개의 샘플 출력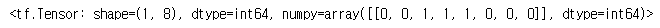
온도를 원하는 값으로 설정할 수 있는데, 0에 가까울수록 높은 확률을 가진 글자를 선택하며, 온도가 높으면 모든 글자가 동일한 확률을 가진다.
- 비교적 정확한 텍스트 생성: 낮은 온도 선호
- 다양하고 창의적인 텍스트 생성: 높은 온도 선호
다음 next_char() 헬퍼 함수는 이 방식을 사용해 다음 글자를 선택하고 입력 텍스트에 추가한다.
def next_char(text, temperature=1):
y_proba = shakespeare_model.predict([text])[0, -1:]
rescaled_logits = tf.math.log(y_proba) / temperature
char_id = tf.random.categorical(rescaled_logits, num_samples=1)[0, 0]
return text_vec_layer.get_vocabulary()[char_id + 2]
그리고 next_char() 함수를 반복 호출하여 다음 글자를 얻고 텍스트에 추가하는 작은 함수를 만든다.
def extend_text(text, n_chars=50, temperature=1):
for _ in range(n_chars):
text += next_char(text, temperature)
return text
온도를 다르게 해보며 텍스트를 생성해본다.
tf.random.set_seed(42)
print('온도:0.01:', extend_text("To be or not to be", temperature=0.01))
print('온도:1:', extend_text("To be or not to be", temperature=1))
print('온도:100:', extend_text("To be or not to be", temperature=100))
▶ 이 셰익스피어 모델은 온도에 취약해보인다. 더 설득력 있는 텍스트를 생성하기 위한 일반적인 기법은 상위 k개의 문자에서 샘플링하거나 총 확률이 특정 임곗값을 초과하는 가장 작은 상위 문자 집합에서만 샘플링하는 것으로, 이를 뉴클리어스 샘플링(nucleaus sampling)이라고 한다.
또는 빔 서치(beam search)를 사용하거나 더 많은 GRU 층과 층마다 더 많은 뉴런을 사용하고, 더 오래 훈련하고, 필요한 경우 규제를 추가할 수도 있다.
이 모델은 현재 length가 100자를 초과하는 긴 패턴을 학습할 수 없다. 윈도를 크게 할 수는 있으나 훈련이 더 어려워지며, LSTM과 GRU 셀이라도 매우 긴 시퀀스는 다룰 수 없다.
상태가 있는 RNN
위 문제의 대안으로 상태가 있는 RNN을 사용한다.
- 상태가 없는 RNN: 훈련 반복마다 모델의 은닉 상태를 0으로 초기화한다. 타임 스텝마다 이 상태를 업데이트하고 마지막 타임 스텝 후에는 더는 필요가 없기 때문에 버린다.
- 상태가 있는 RNN: 한 훈련 배치를 처리한 후에 마지막 상태를 다음 훈련 배치의 초기 상태로 사용한다. 이렇게 하면 역전파는 짧은 시퀀스에서 일어나지만 모델이 장기간 패턴을 학습할 수 있다.
상태가 있는 RNN은 배치에 있는 각 입력 시퀀스가 이전 배치의 시퀀스가 끝난 지점에서 시작해야 한다. 따라서 첫 번째로 할 일은 순차적이고 겹치지 않는 입력 시퀀스를 만드는 것이다.
tf.data.Dataset을 만들 때 window() 메서드에서 shift=1 대신 shift=n_steps를 사용하며, shuffle() 메서드를 호출하지 않는다.
상태가 있는 RNN을 위한 데이터셋은 상태가 없는 RNN의 경우보다 배치를 구성하기 더 힘들다. 이 문제에 대한 가장 간단한 해결책은 크기가 1인 배치를 사용하는 것으로, to_dataset_for_stateful_rnn() 유틸리티 함수는 이런 전략을 사용해 상태가 있는 RNN을 위한 데이터셋을 준비한다.
def to_dataset_for_stateful_rnn(sequence, length):
ds = tf.data.Dataset.from_tensor_slices(sequence)
ds = ds.window(length + 1, shift=length, drop_remainder=True)
ds = ds.flat_map(lambda window: window.batch(length + 1)).batch(1)
return ds.map(lambda window: (window[:, :-1], window[:, 1:])).prefetch(1)
stateful_train_set = to_dataset_for_stateful_rnn(encoded[:1_000_000], length)
stateful_valid_set = to_dataset_for_stateful_rnn(encoded[1_000_000:1_060_000],length)
stateful_test_set = to_dataset_for_stateful_rnn(encoded[1_060_000:], length)[코드 설명]
- to_dataset_for_stateful_rnn 함수:
- 이 함수는 입력 시퀀스를 받아 Stateful RNN에 적합한 데이터셋을 생성.
def to_dataset_for_stateful_rnn(sequence, length): ds = tf.data.Dataset.from_tensor_slices(sequence) ds = ds.windowlength+1,shift=length,dropremainder=Truelength+1,shift=length,dropremainder=True ds = ds.flat_maplambdawindow:window.batch(length+1lambdawindow:window.batch(length+1).batch(1) return ds.map(lambda window: (window[:,-1], window[:, 1:])).prefetch(1)- from_tensor_slices(sequence): 주어진 시퀀스를 텐서 슬라이스로 변환하여 TensorFlow 데이터셋(tf.data.Dataset)을 만든다.
- windowlength+1,shift=length,dropremainder=True: 윈도우 방식을 사용하여 데이터를 length + 1 크기의 윈도우로 나누며, shift를 통해 넘어가는 단계를 지정하고, drop_remainder를 True로 설정하여 윈도우 사이즈가 부족할 경우 해당 윈도우를 버린다.
- flat_maplambdawindow:window.batch(length+1): 각각의 윈도우를 하나의 배치로 만든다.
- batch(1): 한 번에 하나의 배치만 처리되도록 한다.
- **map(lambda window: (window[:,-1], window[:, 1:])): 윈도우 중 마지막 요소를 레이블로 사용하고, 그 외의 요소들을 입력으로 사용한다.
- prefetch(1): 데이터셋을 미리 가져와서 성능을 최적화한다.
- 데이터셋 구성:.
stateful_train_set = to_dataset_for_stateful_rnn(encoded[:1_000_000], length)
stateful_valid_set = to_dataset_for_stateful_rnn(encoded[1_000_000:1_060_000], length)
stateful_test_set = to_dataset_for_stateful_rnn(encoded[1_060_000:], length)- 위 함수 to_dataset_for_stateful_rnn을 사용하여 학습(stateful_train_set), 검증(stateful_valid_set), 및 테스트(stateful_test_set) 데이터셋을 만든다.
- encoded 데이터를 일정한 크기의 세 부분으로 나누어 각각 train, valid, test 데이터셋을 생성한다.
이제 상태가 있는 RNN을 만든다. 각 순환 층을 만들 때 stateful 매개변수를 True로 지정해야 하고, 배치에 있는 입력 시퀀스의 상태를 보존해야 하기 때문에 배치 크기를 알아야 한다. 따라서 첫 번째 층에 batch_input_shape 매개변수를 지정해야 하며, 입력 길이에 제한이 없으므로 두 번째 차원은 지정하지 않아도 된다.
tf.random.set_seed(42)
Layers = tf.keras.layers
model = tf.keras.Sequential([
Layers.Embedding(input_dim=n_tokens, output_dim=16,
batch_input_shape=[1, None]),
Layers.GRU(128, return_sequences=True, stateful=True),
Layers.Dense(n_tokens, activation='softmax')
])
에포크 끝마다 텍스트를 다시 시작하기 전에 상태를 재설정해야 하므로, 사용자 정의 콜백 함수를 사용한다.
class ResetStatesCallback(tf.keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs):
self.model.reset_states()
다른 디렉터리를 사용하여 체크포인트를 저장한다.
model_ckpt = tf.keras.callbacks.ModelCheckpoint(
"my_stateful_shakespeare_model",
monitor="val_accuracy",
save_best_only=True)
이제 모델을 컴파일하고 이 콜백을 사용하여 훈련한다.
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam",
metrics=["accuracy"])
history = model.fit(stateful_train_set, validation_data=stateful_valid_set,
epochs=10, callbacks=[ResetStatesCallback(), model_ckpt])
▶ 이 모델을 훈련한 후에 훈련할 때 사용한 것과 동일한 크기의 배치로만 예측을 만들 수 있다. 이런 제약을 없애려면 동일한 구조의 상태가 없는 모델을 만들고 상태가 있는 모델의 가중치를 복사한다.
다음 내용
[딥러닝] RNN을 사용한 자연어 처리: 감성분석
이전 내용 [딥러닝] RNN을 사용한 자연어 처리이전 내용 [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 3이전 내용 [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 2이전 내용 [딥러닝] RNN & C
puppy-foot-it.tistory.com
[출처]
핸즈 온 머신러닝
'[파이썬 Projects] > <파이썬 딥러닝, 신경망>' 카테고리의 다른 글
| [딥러닝] 비지도 학습: 오토인코더 (1) | 2024.12.03 |
|---|---|
| [딥러닝] 비지도 학습: 오토인코더, GAN, 확산 모델 (0) | 2024.12.03 |
| [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 3 (1) | 2024.12.02 |
| [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 2 (1) | 2024.12.01 |
| [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 1 (0) | 2024.11.30 |



