이전 내용
[딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 1
이전 내용 [딥러닝] 객체 탐지, 객체 추적이전 내용 [딥러닝] 케라스의 사전 훈련 모델 사용하기이전 내용 [딥러닝] 합성곱 신경망을 사용한 컴퓨터 비전이전 내용 [딥러닝] 텐서플로 데이터셋
puppy-foot-it.tistory.com
윈도와 타깃
윈도(Window)
윈도는 시계열 데이터나 순차 데이터에서 일정한 길이의 연속된 데이터 조각을 의미한다. RNN은 데이터를 순차적으로 처리하기 때문에 데이터를 적절한 크기로 나누어 입력해야 한다. 이때 사용되는 데이터의 부분 집합을 윈도라고 한다.
윈도의 예
- 만약 주식 시장 데이터를 분석할 때 최근 10일간의 주가를 입력으로 사용한다면, 윈도의 크기는 10이 된다.
- 텍스트 데이터를 처리할 때 문장을 일정한 길이로 자른다면, 자른 부분 하나하나가 각각 윈도가 된다.
타깃(Target)
타깃은 주어진 입력 데이터(윈도)에 대해 모델이 예측해야 하는 값 또는 실제 레이블을 의미한다. 타깃은 모델 학습 과정에서 손실을 계산하기 위해 필요하다.
타깃의 예
- 주식 시장 예측에서는 윈도에 해당하는 특정 기간의 데이터가 입력으로 주어지면, 타깃은 그 다음 날의 주가가 된다.
- 텍스트 생성에서는 입력 문장에 대해 다음에 올 단어가 타깃이 된다.
윈도와 타깃의 관계
윈도와 타깃은 모델 학습에 필요한 입력과 정답의 쌍을 형성한다. 데이터셋을 윈도와 타깃으로 나누어 모델에 입력하면, 모델은 윈도를 기반으로 타깃을 예측하는 법을 학습하게 된다.
RNN의 경우 시퀀스를 다루기 때문에 윈도의 선택이 매우 중요하며, 적절한 윈도 크기를 선택하는 것이 모델 성능에 큰 영향을 미칠 수 있다.
머신러닝 모델을 위한 데이터 준비하기
케라스는 훈련 세트를 준비하는 데 도움이 되는 tf.keras.utils.timeseries_dataset_from_array() 함수를 제공한다. 이 함수는 시계열을 입력으로 받고 원하는 길이의 모든 윈도와 타깃을 담은 tf.data.Dataset을 만든다.
아래 코드는 0에서 5까지의 숫자를 담은 시계열을 받아 길이가 3인 윈도와 타깃을 담은 배치 크기 2의 데이터셋을 만든다.
my_series = [0, 1, 2, 3, 4, 5]
my_dataset = tf.keras.utils.timeseries_dataset_from_array(
my_series,
targets=my_series[3:], # 네 번째 원소부터 타깃
sequence_length=3,
batch_size=2
)
# 데이터셋의 내용 확인
list(my_dataset)
tf.data의 Dataset 클래스에 있는 window() 메서드를 사용해서 같은 값을 얻을 수 있으며 세부적으로 제어할 수 있다.
for window_dataset in tf.data.Dataset.range(6).window(4, shift=1):
for element in window_dataset:
print(f'{element}', end=' ' )
print()
▶ 마지막 세 개의 윈도는 시계열의 끝과 만나기 때문에 크기가 작은데, window() 메서드에 drop_remainder=True를 지정하여 작은 윈도를 삭제할 수 있다.
window() 메서드는 리스트의 리시트처럼 중첩된 데이터셋을 반환하는데, 모델은 입력으로 데이터셋이 아니라 텐서를 기대하기 때문에 중첩된 데이터셋을 훈련에 바로 사용할 수 없다. 이때 중첩된 데이터셋을 데이터셋이 아니라 텐서를 담은 플랫 데이터셋으로 변환해 주는 flat_map() 메서드를 호출해야 한다.
flat_map() 메서드는 중첩된 데이터셋을 펼치기 전에 각 데이터셋에 적용하는 변환 함수를 매개변수로 받을 수 있다.
dataset = tf.data.Dataset.range(6).window(4, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window_dataset: window_dataset.batch(4))
for window_tensor in dataset:
print(f'{window_tensor}')
▶ 윈도 데이터셋마다 정확하게 네 개의 항목을 담고 있기 때문에 batch(4)를 호출하여 크기가 4인 텐서를 만든다.
데이터셋에서 윈도를 추출하기 쉽도록 간단한 헬퍼 함수를 만든다.
def to_windows(dataset, length):
dataset = dataset.window(length, shift=1, drop_remainder=True)
return dataset.flat_map(lambda window_ds: window_ds.batch(length))
그리고 map() 메서드를 사용해 윈도를 입력과 타깃으로 나누고, 만들어진 윈도를 크기가 2인 배치로 만들 수 있다.
dataset = to_windows(tf.data.Dataset.range(6), 4) # 입력 3개 + 타깃 1개 = 4
dataset = dataset.map(lambda window: (window[:-1], window[-1]))
list(dataset.batch(2))
◆ 머신러닝 모델 만들기
훈련을 시작하기 전에 데이터를 훈련 세트, 검증 세트, 테스트 세트로나누어야 한다. (이번에는 열차 승객 데이터만 사용)
또한, 값이 대략 0에서 1 사이가 되도록 백만으로 나눈다.
rail_train = df['rail']['2016-01':'2018-12'] / 1e6
rail_valid = df['rail']['2019-01':'2019-05'] / 1e6
rail_test = df['rail']['2019-06':] / 1e6
그리고 timeseries_dataset_from_array() 함수를 사용하여 훈련 세트와 검증 세트를 위한 데이터셋을 만드는 데, 경사 하강법은 훈련 세트에 있는 샘플이 독립 동일 분포라고 가정하기 때문에 윈도 안의 내용이 아닌 훈련 윈도를 섞기 위해 shuffle=True로 지정해야 한다.
seq_length = 56
train_ds = tf.keras.utils.timeseries_dataset_from_array(
rail_train.to_numpy(),
targets=rail_train[seq_length:],
sequence_length=seq_length,
batch_size=32,
shuffle=True,
seed=42
)
valid_ds = tf.keras.utils.timeseries_dataset_from_array(
rail_valid.to_numpy(),
targets=rail_valid[seq_length:],
sequence_length=seq_length,
batch_size=32
)원하는 회귀 모델을 만들고 훈련할 준비를 마쳤다.
선형 모델로 예측하기
MAE 손실을 직접 최소화하는 것보다 더 나은 방법인 후버 손실을 사용하고, 조기 종료를 사용한다.
※ 후버 손실은 회귀 문제에서 주로 사용되는 손실 함수 중 하나이다. 이 손실 함수는 평균 제곱 오차(MSE, Mean Squared Error)와 평균 절대 오차(MAE, Mean Absolute Error)의 장점을 결합한 형태로, 큰 오차에 대해서는 MSE처럼 처벌하고 작은 오차에 대해서는 MAE처럼 작동한다.
tf.random.set_seed(42)
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=[seq_length])
])
ealry_stopping_cb = tf.keras.callbacks.EarlyStopping(
monitor='val_mae', patience=50, restore_best_weights=True)
opt = tf.keras.optimizers.SGD(learning_rate=0.02, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(), optimizer=opt, metrics=['mae'])
history = model.fit(train_ds, validation_data=valid_ds, epochs=500,
callbacks=[ealry_stopping_cb])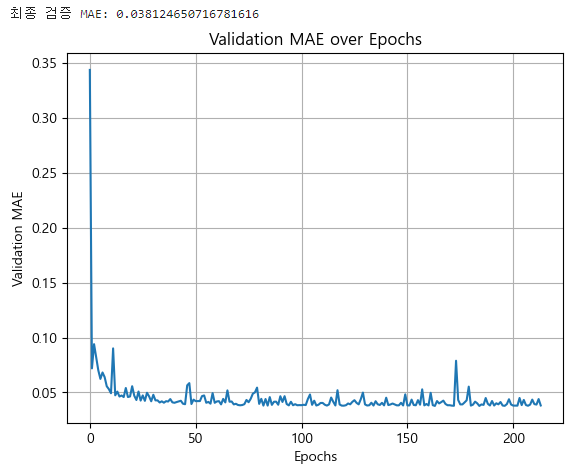
▶ 이 모델의 검증 MAE는 약 38,125으로, 단순 예측보다(42,143)는 좋지만 SARIMA 모델(32,040) 보다는 나쁘다.
간단한 RNN으로 예측하기
하나의 순환 뉴런을 가진 순환 층 하나로 구성된 가장 간단한 RNN을 사용하여 예측해본다.
tf.random.set_seed(42)
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(1, input_shape=[None, 1])
])
ealry_stopping_cb = tf.keras.callbacks.EarlyStopping(
monitor='val_mae', patience=50, restore_best_weights=True)
opt = tf.keras.optimizers.SGD(learning_rate=0.02, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(), optimizer=opt, metrics=['mae'])
history = model.fit(train_ds, validation_data=valid_ds, epochs=500,
callbacks=[ealry_stopping_cb])
val_mae_history = history.history['val_mae']
final_val_mae = val_mae_history[-1]
print(f"최종 검증 MAE: {final_val_mae}")
plt.plot(val_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.title('Validation MAE over Epochs')
plt.grid(True)
plt.show()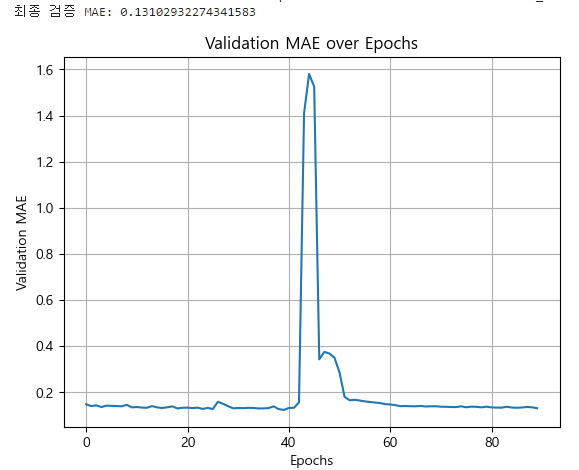
[코드 설명 - 순환 층만]
- 케라스의 모든 순환 층은 [batch_size, time_step, dimensionality] 크기의 3D 입력을 기대한다.
- dimensionality는 단변량 시계열은 1, 다변량 시계열은 1보다 크다.
- input_shape 매개변수에는 첫 번째 차원(배치 크기)을 제외하고 지정하며, 순환 층은 어떤 크기의 입력 시퀀스도 받을 수 있기 때문에 두 번째 차원을 모든 크기를 의미하는 None으로 지정할 수 있다. 그리고 단변량 시계열을 다루기 때문에 마지막 차원 크기를 1로 지정해야 해서 [None, 1]로 지정한다. 이는 임의의 길이를 가진 단변량 시퀀스를 의미한다.
검증 MAE가 10만 이상으로 나오는데, 이는 아래와 같은 이유 때문이다.
- 이 모델은 하나의 순환 뉴런만 가지고 있기 때문에 예측을 만들기 위해 사용되는 데이터는 현재 타임 스텝의 입력값과 이전 타임 스텝의 출력값 뿐으로 많지 않다. 따라서 이 RNN의 기억력은 매우 제한적이다.
- 이 모델의 파라미터는 두 개의 입력을 받는 하나의 순환 뉴런만 있기 때문에 전체 모델에는 세 개의 파라미터(두 개의 가중치, 하나의 편향)만 있어 이 시계열에는 충분하지 않다.
- 이 시계열은 0부터 1.4까지의 값을 담고 있으나, 기본 활성화 함수가 tanh 함수로 순환 층이 -1에서 1 사이의 값만 출력할 수 있어 1.0에서 1.4 사이의 값을 예측할 방법이 없다.
이 문제들을 고치기 위해, 32개의 순환 뉴런을 가진 순환 층과 그 위에 출력 뉴런이 하나이고 활성화 함수가 없는 밀집 층을 추가한 모델을 만든다. 이 순환 층은 한 타임 스텝에서 다음 타임 스텝으로 훨씬 많은 정보를 실어 나를 수 있다.
tf.random.set_seed(42)
univar_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, input_shape=[None, 1]),
tf.keras.layers.Dense(1)
])
fit_and_evaluate(univar_model, train_ds, valid_ds, learning_rate=0.05)
▶ 이 모델을 컴파일하고, 훈련하고, 평가하면 검증 MAE가 28,534에 도달한다. 이 모델의 결과는 현재 훈련한 모델 중 최상의 성능을 보여준다.
심층 RNN으로 예측하기
심층 RNN은 셀을 여러 층으로 쌓아 만든 RNN이다. 케라스로 심층 RNN을 구현하는 것은 쉬운데, 그냥 순환 층을 쌓으면 된다.
tf.random.set_seed(42)
deep_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, return_sequences=True, input_shape=[None, 1]),
tf.keras.layers.SimpleRNN(32, return_sequences=True),
tf.keras.layers.SimpleRNN(32),
tf.keras.layers.Dense(1)
])
fit_and_evaluate(deep_model, train_ds, valid_ds, learning_rate=0.05)
▶ 이 모델의 검증 MAE는 약 30,824로 얕은 RNN보다는 좋지 못하다.
다변량 시계열 예측하기
신경망의 큰 장점은 유연성으로, 구조를 거의 바꾸지 않고도 다변량 시계열을 다룰 수 있다.
버스와 열차 데이터를 입력으로 사용하여 열차 시계열을 예측하고, day_type도 추가해본다. 내일의 요일 유형(평일, 토, 일, 공휴일)을 미리 알 수 있으므로 day_type 시리즈를 하루 미래로 이동하면 모델이 내일의 day_type을 입력으로 사용할 수 있다.
판다스를 통해 이를 처리한다.
df_mulvar = df[['bus', 'rail']]/1e6
df_mulvar['next_day_type'] = df['day_type'].shift(-1)
df_mulvar = pd.get_dummies(df_mulvar)
df_mulvar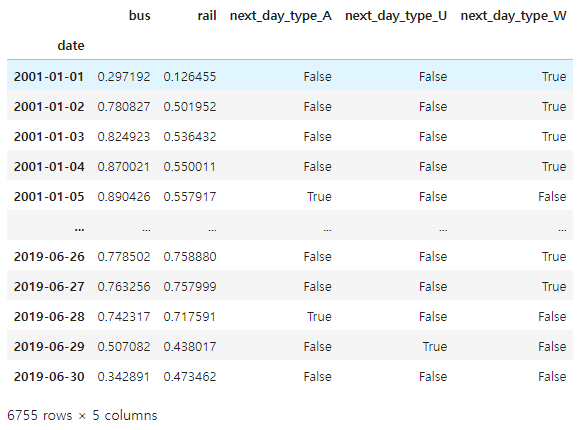
데이터를 훈련, 검증, 테스트 세트로 나눈다.
mulvar_train = df_mulvar['2016-01':'2018-12']
mulvar_valid = df_mulvar['2019-01':'2019-05']
mulvar_test = df_mulvar['2019-06':]
데이터셋을 만든다.
train_mulvar_ds = tf.keras.utils.timeseries_dataset_from_array(
mulvar_train.to_numpy().astype(np.float32),
targets=mulvar_train["rail"][seq_length:],
sequence_length=seq_length,
batch_size=32,
shuffle=True,
seed=42
)
valid_mulvar_ds = tf.keras.utils.timeseries_dataset_from_array(
mulvar_valid.to_numpy().astype(np.float32),
targets=mulvar_valid["rail"][seq_length:],
sequence_length=seq_length,
batch_size=32
)
RNN 모델을 만들고, 컴파일하고, 훈련하고, 평가한다.
tf.random.set_seed(42)
mulvar_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, input_shape=[None, 5]),
tf.keras.layers.Dense(1)
])
fit_and_evaluate(mulvar_model, train_mulvar_ds, valid_mulvar_ds, learning_rate=0.05)
▶ 검증 MAE는 22,526으로 크게 향상되었다.
여러 타임 스텝 앞 예측하기
타깃을 적절히 바꿔 여러 타임 스텝 앞의 값도 손쉽게 예측할 수 있다. 예를 들어 지금부터 2주 뒤의 승객 수를 예측하려면 1일 앞이 아니라 14일 앞의 값을 타깃으로 사용하면 되는데, 다음 값 14개를 예측하는 방법은 아래와 같다.
1) 앞서 훈련된 univar_model을 사용하여 다음 값을 예측한 다음, 예측된 값이 실제로 발견된 것처럼 입력으로 추가한 뒤, 이 모델을 사용해 다시 다음 값을 예측한다.
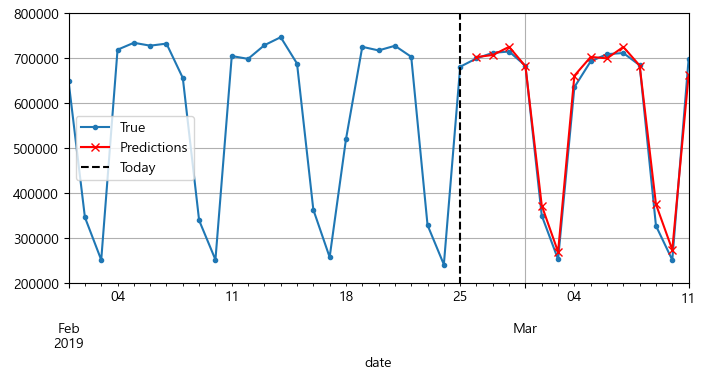
X = rail_valid.to_numpy()[np.newaxis, :seq_length, np.newaxis]
for step_ahead in range(14):
y_pred_one = univar_model.predict(X)
X = np.concatenate([X, y_pred_one.reshape(1, 1, 1)], axis=1)
검증 세트에서 처음 56일치 열차 승객 데이터를 [1, 56, 1] 크기의 넘파이 배열로 변환한 후, 이 모델을 사용해 반복적으로 다음 값을 예측하고 각 예측값을 시간축(axis=1)을 따라 입력 시계열에 덧붙인다.
Y_pred = pd.Series(X[0, -14:, 0], index=pd.date_range("2019-02-26", "2019-03-11"))
fig, ax = plt.subplots(figsize=(8, 3.5))
(rail_valid * 1e6)["2019-02-01":"2019-03-11"].plot(label="True", marker=".", ax=ax)
(Y_pred * 1e6).plot(label="Predictions", grid=True, marker="x", color="r", ax=ax)
ax.vlines("2019-02-25", 0, 1e6, color="k", linestyle="--", label="Today")
ax.set_ylim([200_000, 800_000])
plt.legend(loc="center left")
plt.show()
2) 한 번에 다음 14개 값을 예측하는 RNN 을 훈련한다.
이를 위해 timeseries_dataset_from_arrray() 함수를 다시 사용할 수 있는데, 이번에는 타깃이 없고(targets=None) 길이가 seq_length+14 인 긴 시퀀스를 가진 데이터셋을 만든다.
그리고 데이터셋의 map() 메서드를 사용해 시퀀스의 각 배치에 사용자 정의 함수를 적용하여 입력과 타깃으로 나눈다.
이 예에서는 다변량 시계열(5개열 모두)을 입력으로 사용하고 다음 14일에 해당하는 열차 승객 수를 예측한다.
tf.random.set_seed(42)
def split_inputs_and_targets(mulvar_series, ahead=14, target_col=1):
return mulvar_series[:, :-ahead], mulvar_series[:, -ahead:, target_col]
ahead_train_ds = tf.keras.utils.timeseries_dataset_from_array(
mulvar_train.to_numpy().astype(np.float32),
targets=None,
sequence_length=seq_length + 14,
batch_size=32,
shuffle=True,
seed=42
).map(split_inputs_and_targets)
ahead_valid_ds = tf.keras.utils.timeseries_dataset_from_array(
mulvar_valid.to_numpy().astype(np.float32),
targets=None,
sequence_length=seq_length + 14,
batch_size=32
).map(split_inputs_and_targets)
출력 층의 유닛 개수는 1개가 아니라 14개여야 한다.
tf.random.set_seed(42)
ahead_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, input_shape=[None, 5]),
tf.keras.layers.Dense(14)
])
fit_and_evaluate(ahead_model, ahead_train_ds, ahead_valid_ds, learning_rate=0.02)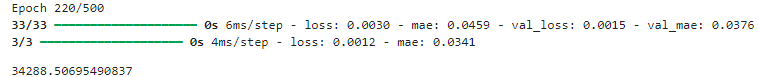
이제 아래와 같이 한 번에 다음 14개 값을 예측할 수 있다.
X = mulvar_valid.to_numpy()[np.newaxis, :seq_length].astype(np.float32)
Y_pred = ahead_model.predict(X)
Y_pred
시퀀스-투-시퀀스 모델로 예측하기
마지막 타임 스텝에서만 다음 14개의 값을 예측하는 모델을 훈련하지 않고 모든 타임 스텝에서 다음 14개의 값을 예측할 수 있도록 훈련할 수 있다. 즉, 시퀀스-투-벡터 RNN을 시퀀스-투-시퀀스 RNN로 바꿀 수 있는데, 이 기법의 장점은 마지막 타임 스텝의 출력뿐 아니라 모든 타임 스텝의 RNN 출력이 손실에 포함된다는 점이고, 이는 훨씬 많은 오차 그레이디언트가 모델로 흘러간다는 것을 의미한다. 각 타임 스텝의 출력에서 오차 그레이디언트가 나오기 때문에 시간을 거슬러 오래 전파되지 않아도 되어 훈련을 안정시키고 속도를 높인다.
이 데이터셋은 샘플마다 입력을 위한 윈도와 출력을 위한 윈도의 시퀀스를 가져야 하므로 만들기가 간단하지 않으나, 한 가지 방법은 앞서 만든 to_window() 함수를 한 행에 두 번 실행하여 연속적인 윈도의 윈도를 얻는 것이다.
예를 들어 0에서 6까지의 숫자로 이루어진 시계열을 길이가 3인 윈도 4개가 연속되는 시퀀스를 담은 데이터셋으로 바꿔본다.
my_series = tf.data.Dataset.range(7)
dataset = to_windows(to_windows(my_series, 3), 4)
list(dataset)
그리고 map() 메서드를 사용해 윈도의 윈도를 입력과 타깃으로 나눌 수 있다.
dataset = dataset.map(lambda S: (S[:, 0], S[:, 1:]))
list(dataset)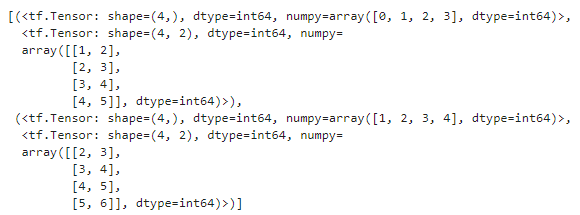
시퀀스-투-시퀀스 모델에 사용할 데이터셋을 준비하기 위해 또 다른 유틸리티 함수를 만들어본다. 이 함수는 셔플링과 배치 처리도 담당한다.
def to_seq2seq_dataset(series, seq_length=56, ahead=14, target_col=1,
batch_size=32, shuffle=False, seed=None):
ds = to_windows(tf.data.Dataset.from_tensor_slices(series), ahead + 1)
ds = to_windows(ds, seq_length).map(lambda S: (S[:, 0], S[:, 1:, 1]))
if shuffle:
ds = ds.shuffle(8 * batch_size, seed=seed)
return ds.batch(batch_size)
이 함수를 사용해 데이터셋을 만든다.
# NumPy 배열로 변환
mulvar_train_np = mulvar_train.to_numpy().astype(np.float32)
mulvar_valid_np = mulvar_valid.to_numpy().astype(np.float32)
seq2seq_train = to_seq2seq_dataset(mulvar_train_np, shuffle=True, seed=42)
seq2seq_valid = to_seq2seq_dataset(mulvar_valid_np)
시퀀스-투-시퀀스 모델을 만들고 컴파일하고, 훈련하고, 검증한다.
tf.random.set_seed(42)
# 모델 정의 및 컴파일
seq2seq_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, return_sequences=True, input_shape=[None, 5]),
tf.keras.layers.Dense(14)
])
fit_and_evaluate(seq2seq_model, seq2seq_train, seq2seq_valid, learning_rate=0.02)
위 모델을 이용하여 다음과 같이 향후 14일 동안의 열차 승객 수를 예측할 수 있다.
X = mulvar_valid.to_numpy()[np.newaxis, :seq_length].astype(np.float32)
Y_pred_14 = seq2seq_model.predict(X)[0, -1] # 마지막 타임 스텝 출력
Y_pred_14
다음 내용
[딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 3
이전 내용 [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 2이전 내용 [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 1이전 내용 [딥러닝] 객체 탐지, 객체 추적이전 내용 [딥러닝] 케라스의
puppy-foot-it.tistory.com
[출처]
핸즈 온 머신러닝
https://www.kaggle.com/code/diegorestrepoleal/cta-ridership-daily-boarding-totals#univar_model
'[파이썬 Projects] > <파이썬 딥러닝, 신경망>' 카테고리의 다른 글
| [딥러닝] RNN을 사용한 자연어 처리 (1) | 2024.12.02 |
|---|---|
| [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 3 (1) | 2024.12.02 |
| [딥러닝] RNN & CNN(feat. 시카고 교통국 데이터셋) - 1 (0) | 2024.11.30 |
| [딥러닝] 객체 탐지, 객체 추적 (0) | 2024.11.29 |
| [딥러닝] 케라스의 사전 훈련 모델 사용하기 (1) | 2024.11.29 |



