이전 내용
[파이썬] Streamlit 웹 개발 - 5: 로또 번호 생성 페이지
이전 내용 [파이썬] Streamlit 으로 웹 페이지 만들기 - 4이전 내용 [파이썬] [파이썬] Streamlit으로 웹 페이지 만들기 - 3이전 내용 [파이썬] Streamlit으로 웹 페이지 만들기 - 2이전 내용 [파이썬] Stre
puppy-foot-it.tistory.com
session state
Session에 내가 저장하고 싶은 변수들을 기억할 수 있는 기능
import streamlit as st
# seession_state 사용 전
counter = 0
button = st.button('클릭!')
if button:
counter += 1
st.write(f'버튼을 {counter}번 클릭하였습니다.')
버튼을 클릭하면 수가 증가해야 하는데, 한 번만 증가되고 더이상 증가되지 않는다.
# session_state 사용 후
if "counter" not in st.session_state:
st.session_state.counter = 0
button = st.button('클릭!')
if button:
st.session_state.counter += 1
st.write(f"버튼을 **:red[{st.session_state.counter} 번]** 클릭하였습니다.")
버튼을 누를 때 값이 잘 증가된다.
cache_data
Streamlit에게 데이터를 캐시(저장해 뒀다가 나중에 필요할 때 불러옴) 할 수 있는 함수
※ Cache: 컴퓨터 과학에서 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 캐시는 캐시의 접근 시간에 비해 미가공 데이터 또는 1차 데이터에 접근하는 시간이 오래 걸리는 경우나 값을 다시 계산하는 시간을 절약하고 싶은 경우에 사용한다.
@st.cache_data: 데코레이터를 사용하여 함수를 캐싱한다.
▶ 함수를 실행한 결과가 캐시에 보관되고, 그 이후부터는 파라미터가 달라졌거나 구현 내용이 달라진 경우에 한해서만 함수를 다시 실행한다. 만일 함수의 코드가 변경되지 않았고, 이전에 호출된 파라미터와 동일하다면, 캐시에 보관되어 있는 결과를 반환함으로써 불필요한 재실행을 막는다.
※ 데코레이터: 함수나 메서드에 적용되어 기능을 확장하거나 변경하는 역할 '@데코레이터_이름' 형태
@데코레이터
def 함수():
# 함수 내용
앞서, Streamlit 공식 페이지의 튜토리얼 시각화에 관한 글에서 작성된 코드 중에 하단의 코드가 있다.
@st.cache_data
# 사용자 프로필 데이터 생성
# 기본으로 20개의 항목 생성
def get_profile_dataset(number_of_items: int = 20, seed: int = 0) -> pd.DataFrame: # 결과를 DataFrame으로 반환
new_data = [] # 생성할 사용자 데이터 저장할 리스트 초기화
fake = Faker() # Faker를 사용하여 가상의 사용자 프로필 생성
np.random.seed(seed) # 난수 생성기
Faker.seed(seed)
# 사용자 프로필 생성을 위한 반복문
for i in range(number_of_items): # 20개의 가짜 프로필
profile = fake.profile() # 가상의 사용자 프로필 정보 가져옴
new_data.append( # new_data 리스트에 추가
{
"name": profile["name"], # name 필드
"daily_activity": np.random.rand(25), # 0과 1 사이의 랜덤 숫자로 구성된 25개의 데이터 생성 (일일 활동)
"activity": np.random.randint(2, 90, size=12), # 2에서 89 사이의 정수로 이뤄진 12개 수치 생성 (연간 활동)
}
)
profile_df = pd.DataFrame(new_data) # new_data 리스트를 DataFrame 으로 변환하여 profile_df 변수에 저장
return profile_df
이 코드는 가짜 사용자 프로필을 20개 생성하여 데이터프레임에 저장하는 함수에 대한 내용인데, 데코레이터로 인해 매번 사용 시마다 프로필이 생성되지 않고 최초 수행 시 한 번 생성되어 캐싱(임시 저장) 되어있다가 매개변수가 기타 사항이 변경될 때마다 함수가 호출된다.
스트림릿에서 SQL 사용하기
MySQL 에 있는 데이터베이스를 불러와 보는 작업을 수행해 본다.

이를 위해 먼저 필요한 라이브러리를 설치한다.
pip install streamlit_sqlalchemy # streamlit에서 사용 가능한 SQLAlchemy
pip install pymysql # python에서 사용 가능한 mysql
- 필요한 라이브러리 import
import streamlit as st
from sqlalchemy import create_engine
import pandas as pd
import pymysql
- MySQL 정보를 입력하고 엔진 생성
※ create_engine: SQLAlchemy 라이브러리의 중요한 기능으로, 데이터베이스에 대한 연결을 생성하는 데 사용된다. 이 함수는 데이터베이스와의 상호작용을 위한 기본적인 엔진 역할을 하며, 데이터베이스 종류에 따라 다양한 매개변수를 사용할 수 있다.
- MySQL 정보는 내 로컬 PC에 설치된 정보와 동일한 정보를 가져오면 된다.
- 데이터를 가져오는 쿼리문과 해당 데이터를 읽어와 (판다스의 read_sql 함수) 데이터프레임으로 만들어주는 사용자 함수 "fetch_data()" 를 정의한다.
- 그리고 [데이터 로드] 라는 이름의 버튼을 생성하고, 버튼이 눌렸을 경우(True) fecth_data() 함수에서 불러온 데이터프레임을 띄우도록 설정해 준다.
# MySQL 정보
DB_HOST='localhost'
DB_PORT='3306'
DB_NAME='tabledb'
DB_USER='root'
DB_PASS='1234'
# 데이터베이스 정보 보기위한 코드이므로 생략 가능
DB_INFO_keys = ['DB_HOST', 'DB_PORT', 'DB_NAME', 'DB_USER', 'DB_PASS']
DB_INFO_values = [DB_HOST, DB_PORT, DB_NAME, DB_USER, DB_PASS]
# 데이터베이스 정보 보기위한 코드이므로 생략 가능
for i, DB_INFO_key in enumerate(DB_INFO_values):
print(f"{DB_INFO_keys[i]}: {DB_INFO_values[i]}")
# SQLAlchemy 엔진 생성 (MySQL용)
engine = create_engine(f"mysql+pymysql://{DB_USER}:{DB_PASS}@{DB_HOST}:{DB_PORT}/{DB_NAME}")
# 데이터 가져오는 함수
def fetch_data():
query = "SELECT * FROM usertbl;"
df = pd.read_sql(query, engine) # SQLAlchemy 엔진 사용
return df
# Streamlit 앱
st.title("MySQL 데이터 조회")
if st.button("데이터 로드"):
df = fetch_data()
st.dataframe(df) # 데이터 출력
- 터미널에서 streamlit 실행
streamlit run 파일명.py
[데이터 로드] 버튼을 클릭하면 쿼리문이 실행되며 MySQL의 데이터베이스에 저장된 데이터가 로드된다.
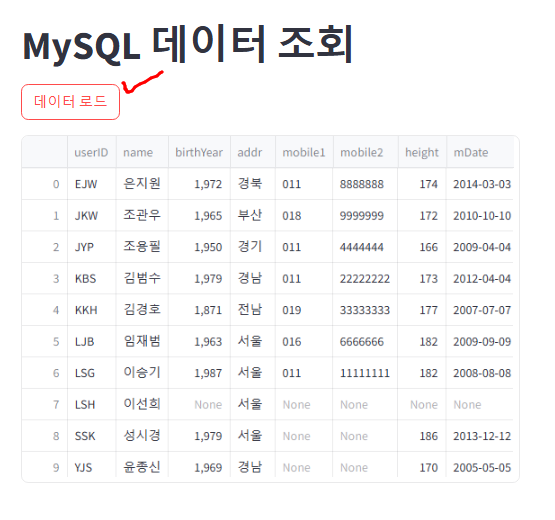
데이터베이스 보완
: 테이블 선택 기능 추가
코드를 만들고나서, 만약 데이터베이스에 여러 테이블이 있을 경우 선택할 수 있게끔 하는 기능을 넣어주면 어떨까 하는 생각이 들어 이를 구현해 보기로 한다.
streamlit의 selectbox 기능으로 테이블 목록이 뜨고, 원하는 테이블을 선택할 수 있도록 한다.
from sqlalchemy import create_engine, inspect
# SQLAlchemy 엔진 생성 (MySQL용)
engine = create_engine(f"mysql+pymysql://{DB_USER}:{DB_PASS}@{DB_HOST}:{DB_PORT}/{DB_NAME}")
# 인스펙터 생성
inspector = inspect(engine)
# 데이터베이스의 테이블 목록 조회
table_names = inspector.get_table_names()
# Streamlit 앱
st.title("MySQL 데이터 조회")
selected_table = st.selectbox("조회할 테이블을 선택하세요", table_names)
# 데이터 가져오는 함수
def fetch_data():
query = f"SELECT * FROM {selected_table};"
df = pd.read_sql(query, engine) # SQLAlchemy 엔진 사용
return df
if st.button("데이터 로드"):
df = fetch_data()
st.dataframe(df) # 데이터 출력
- sqlalchemy 라이브러리에 inspect를 추가로 import 해준다.
- 그리고 inspector를 생성하고, get_table_names()를 통해 해당 데이터베이스 내에 있는 테이블 이름을 받도록 한다.
- selectbox 버튼을 추가하는 데, 데이터를 가져오는 함수에 추가해줘야 하므로 selected_table 이라는 변수를 만들어 저장해 주도록 한다.
- fetch_data() 함수에서 선택된 테이블의 데이터를 불러올 수 있도록 query문을 수정해 준다.
이를 실행하면
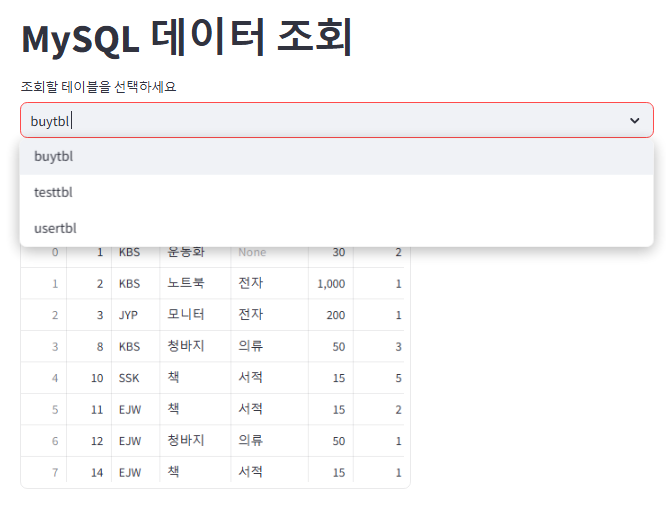
해당 데이터베이스에 있는 테이블 목록이 셀렉트박스를 통해 출력되고, 이를 선택한 후 [데이터 로드] 버튼을 누르면 해당 테이블의 데이터가 데이터프레임 형태로 불러와 진다.
[참고]
위키백과
'[파이썬 Projects] > <파이썬 웹개발>' 카테고리의 다른 글
| [파이썬] Streamlit 웹 개발 - 8: 대시보드 꾸미기 (0) | 2025.03.19 |
|---|---|
| [파이썬] Streamlit 웹 개발 - 7: DB (0) | 2025.03.19 |
| [파이썬] Streamlit 웹 개발 - 5: 로또 번호 생성 페이지 (0) | 2025.03.18 |
| [파이썬] Streamlit 웹 개발 - 4: 차트 (1) | 2025.03.18 |
| [파이썬] Streamlit 웹 개발 - 3: 시각화(튜토리얼) (0) | 2025.03.18 |



