이전 내용
[파이썬] Streamlit 웹 개발 - 7: DB
이전 내용 [파이썬] Streamlit 웹 개발 - 6: 저장 관련이전 내용 [파이썬] Streamlit 웹 개발 - 5: 로또 번호 생성 페이지이전 내용 [파이썬] Streamlit 으로 웹 페이지 만들기 - 4이전 내용 [파이썬] [파이
puppy-foot-it.tistory.com
대시보드 꾸미기
: 기초 작업
이전에는 진행했던 cars.csv 파일을 데이터베이스에 연동시켜 테이블을 생성하고 화면에 띄우는 과정을 진행했다.
이번에는 데이터프레임을 화면에 띄우는 것을 넘어, 이 데이터를 가지고 대시보드를 꾸며보는 과정을 진행해 본다.
시작 전에 필요한 라이브러리를 설치한다.
pip install pandas numpy streamlit plotly mysql-connector-python
- 데이터베이스와 프로그램 연결하기
이전 시간에 사용했던 create_database_connection() 함수를 그대로 사용한다.
# 데이터베이스와 프로그램 간 연결 (파이프라인)
def create_database_connection():
try:
connection = mysql.connector.connect( # 데이터베이스를 연동하는 객체
host=DB_HOST,
database=DB_NAME,
user=DB_USER,
password=DB_PASS
)
if connection.is_connected():
print("MySQL 데이터베이스에 성공적으로 연결되었습니다.")
return connection
except Error as e:
print(f"데이터베이스 연결 오류 발생: {e}")
return None
- cars 테이블을 가져와서 데이터프레임으로 생성하기
데이터베이스와 프로그램이 연결됐으면, 테이블로부터 데이터를 가져와서 데이터프레임으로 생성할 수 있게 하는 사용자 함수를 정의한다.
데이터를 판다스의 read_sql로 불러온 후, 컬럼명을 변경한 뒤 데이터프레임으로 생성하여 반환한다.
단, 프로그램이 실행될 때마다 불러오지 않게끔 데코레이터를 설정하여 변동사항이 있을 때만 함수를 호출하도록 한다.
# 데이터 가져오기 (캐싱 적용)
@st.cache_data
def get_data():
connection = create_database_connection()
if connection is None:
return pd.DataFrame()
try:
query = f"SELECT * FROM {DB_TABLE}"
df = pd.read_sql(query, connection)
# 열 이름 조정
df = df.rename(columns={
"foreign_local_used": "Foreign_Local_Used",
"seat_make": "seat-make",
"make_year": "make-year",
"automation": "Automation" # 추가: 소문자 -> 대문자
})
return df
except Error as e:
print(f"데이터 조회 중 오류 발생: {e}")
return pd.DataFrame()
finally:
if connection.is_connected():
connection.close()
- 데이터 필터링 기능을 적용할 컬럼 설정
대시보드에 데이터 필터링 기능을 적용할 것이므로, 필터링이 적용될 컬럼을 설정해 준다.
필터링 기능을 적용할 칼럼은 제조사, 변속기, 국산/외제차, 색상, 생산년도 이다.
※ 미국에서 작성된 데이터라 국산=미국산
# 필터링된 데이터 캐싱
@st.cache_data
def filter_data(df, manufacturer, automation, use_category, color, make_year):
return df.query(
"manufacturer == @manufacturer & Automation == @automation & Foreign_Local_Used == @use_category & \
color == @color & make-year == @make_year_range"
)
# 데이터 가져오기
df = get_data()
# 데이터가 비어있는 경우 처리
if df.empty:
st.error("데이터베이스에서 데이터를 가져오지 못했습니다. 연결 정보를 확인하세요.")
st.stop()대시보드 꾸미기
: 1. 사이드바 생성하기
데이터 필터링을 위해 필터링 기준을 줄 컬럼을 선정하여 사이드바에 넣어 옵션을 설정해 준다.
필터링 컬럼은
- 제조사: 다중 선택 박스(multiselect) 로 제조사를 선택 후, 제조사별로 데이터가 출력되게끔 설정 ▶ 전체 선택 버튼을 추가하여 리스트가 일괄 선택되도록 함. (전체선택 시, 다른 제조사는 자동으로 해제되도록 구현하려 하였으나 실패)
- 변속기: 라디오 버튼으로 변속기별(자동, 수동)로 데이터가 출력되게끔 설정
- 사용 (지역) 카테고리: 라디오 버튼으로 사용 지역별(국내, 해외)로 데이터가 출력되게끔 설정
# 사이드바 생성
st.sidebar.header('데이터 조회 옵션 선택')
# 제조사 멀티셀렉트 옵션 생성
manufacturer_options = ['All'] + df['manufacturer'].unique().tolist() # 전체 선택 및 제조사의 유니크 값
# 사용자가 선택한 제조사 저장
manufacturer = st.sidebar.multiselect(
"제조사를 선택하세요:",
options=manufacturer_options,
default=['All'] # 기본값 .
)
# 선택 처리 로직
# if 'All' in manufacturer:
# if len(manufacturer) > 1:
# # "All"이 선택된 상태에서 다른 제조사가 선택되면
# manufacturer = ['All']
# else:
# # "All"이 선택되지 않은 경우, 사용자가 선택한 목록을 유지
# if len(manufacturer) == 0:
# manufacturer = []
# 전체 선택 시
if 'All' in manufacturer:
manufacturer = df['manufacturer'].unique().tolist() # 모든 제조사 선택
else:
manufacturer = manufacturer # 사용자가 선택한 제조사 유지
# 변속기 라디오 버튼
automation = st.sidebar.radio(
"변속기를 선택하세요:",
options=df['Automation'].unique()
)
# 사용 카테고리 라디오 버튼
use_category = st.sidebar.radio(
"카테고리를 선택하세요:",
options=df['Foreign_Local_Used'].unique()
)
# 데이터 필터링
df_select = filter_data(df, manufacturer, automation, use_category)
# 필터링된 데이터가 비어있는 경우 처리
if df_select.empty:
st.warning("현재 필터 설정에 해당하는 데이터가 없습니다!")
st.stop()
데이터 필터링 적용시키기
+ 메인화면 꾸미기
앞서 설정해준 사이드바 옵션을 통해 선택된 옵션에 따라 데이터가 필터링되어 출력되도록 설정해 준다.
또한, 필터링된 데이터프레임이 출력될 메인 화면도 설정해 준다.
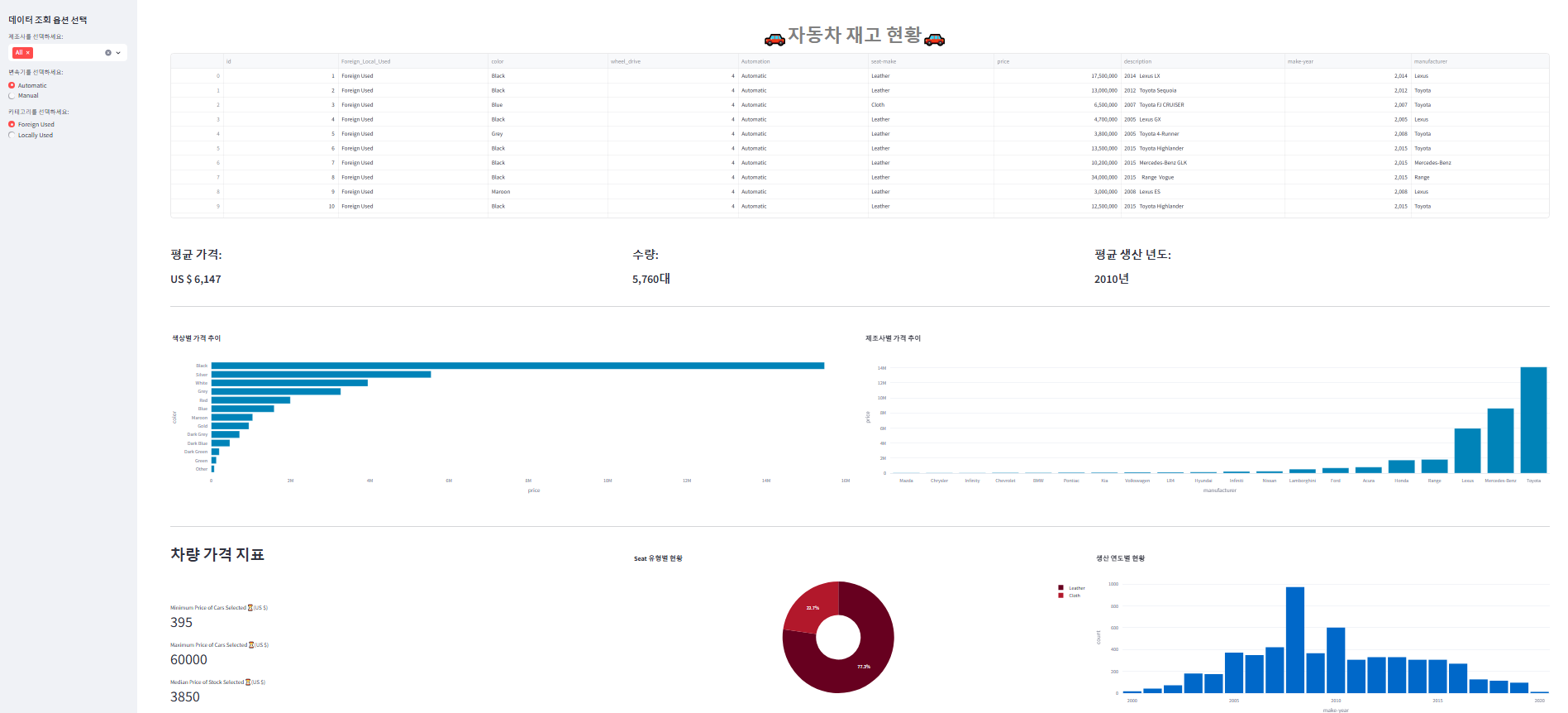
메인 화면에는 아래의 항목들이 표시된다.
- 데이터프레임
- KPI 수치
- 색상별 가격 막대 차트
- 제조사별 가격 막대 차트
- 시트 유형별 파이 차트
- 가격 지표: 최소 가격, 최대 가격, 중간 가격 (3열로 표시)
- 생산연도별 히스토그램
그리고, 데이터프레임이 화면에 넓게 표시되도록 코드 상단에 아래의 코드를 먼저 추가해 준다.
# 메인 페이지 너비 넓게 (가장 처음에 설정해야 함)
st.set_page_config(layout="wide")
- 데이터프레임 영역
# 데이터 필터링
df_select = filter_data(df, manufacturer, automation, use_category)
# 필터링된 데이터가 비어있는 경우 처리
if df_select.empty:
st.warning("현재 필터 설정에 해당하는 데이터가 없습니다!")
st.stop()
# emoji url: https://streamlit-emoji-shortcodes-streamlit-app-gwckff.streamlit.app/
# 메인 화면
title = "자동차 재고 현황"
st.markdown(f"<h1 style='text-align: center; color: grey;'>🚗{title}🚗</h1>", unsafe_allow_html=True)
st.dataframe(df_select, use_container_width=True)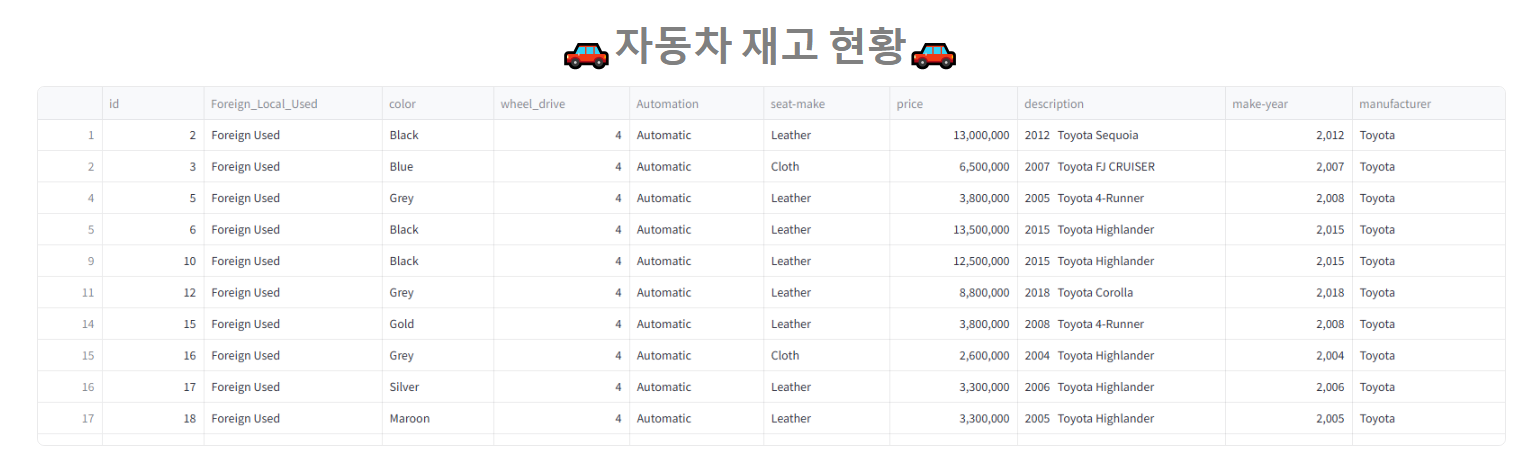
- 핵심 성과 지표 영역
# (핵심 성과 지표) 계산
average_price = int(df_select['price'].mean() / 1000)
car_count = df_select.shape[0]
avg_make_year = df_select['make-year'].mean()
st.markdown('#####')
# KPI 표시
first_column, second_column, third_column = st.columns(3)
with first_column:
st.subheader("평균 가격:")
st.subheader(f"US $ {average_price:,}")
with second_column:
st.subheader("수량:")
st.subheader(f"{car_count:,}대")
with third_column:
st.subheader("평균 생산 년도:")
st.subheader(f"{(avg_make_year):.0f}년")
st.divider()
- 색상별 가격 막대 차트, 제조사별 가격 막대 차트 영역
# 색상별 가격 막대 차트
price_per_color = df_select.groupby(by=["color"])[["price"]].sum().sort_values(by="price")
fig_color_price = px.bar(
price_per_color / 1000,
x="price",
y=price_per_color.index,
orientation="h",
title="<b>색상별 가격 추이</b>",
color_discrete_sequence=["#0083B8"] * len(price_per_color),
template="plotly_white",
)
fig_color_price.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
# 제조사별 가격 막대 차트
price_per_make = df_select.groupby(by=["manufacturer"])[["price"]].sum().sort_values(by="price")
make_price_fig = px.bar(
price_per_make / 1000,
x=price_per_make.index,
y="price",
orientation="v",
title="<b>제조사별 가격 추이</b>",
color_discrete_sequence=["#0083B8"] * len(price_per_make),
template="plotly_white",
)
make_price_fig.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
# 차트 표시
left_column, right_column = st.columns(2)
left_column.plotly_chart(fig_color_price, use_container_width=True)
right_column.plotly_chart(make_price_fig, use_container_width=True)
st.divider()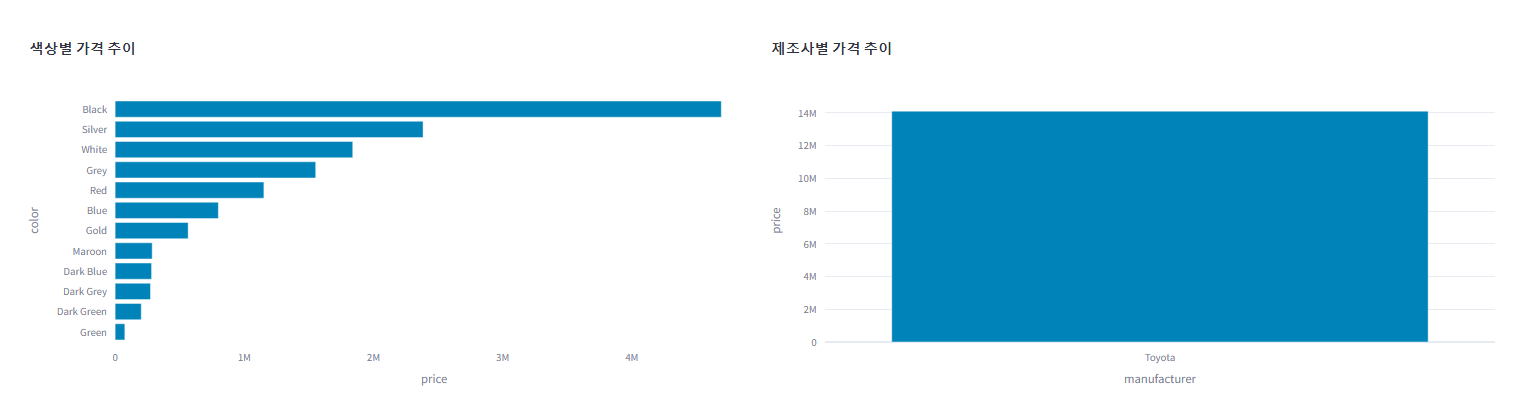
- 시트 유형별 파이차트, 차량 가격 지표, 생산 연도별 히스토그램 영역
# 시트 유형별 파이 차트
seat_make_dist = df.groupby(by=["seat-make"])[['price']].agg('count').sort_values(by='seat-make')
fig_seat_dist = px.pie(
seat_make_dist,
values="price",
title="Seat 유형별 현황",
names=seat_make_dist.index,
color_discrete_sequence=px.colors.sequential.RdBu,
hole=0.4
)
fig_seat_dist.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
# 가격 지표
max_price = df_select['price'].max()
min_price = df_select['price'].min()
median_price = df_select['price'].median()
# 3열 레이아웃
left_column, middle_column, right_column = st.columns(3)
with left_column:
st.markdown("## 차량 가격 지표")
st.markdown('##')
left_column.metric(label="Minimum Price of Cars Selected ⏳(US $)", value=int(min_price / 1000))
left_column.metric(label="Maximum Price of Cars Selected ⏳(US $)", value=int(max_price / 1000))
left_column.metric(label="Median Price of Stock Selected ⏳(US $)", value=int(median_price / 1000))
middle_column.plotly_chart(fig_seat_dist, use_container_width=True)
# 생산 연도별 히스토그램
make_year_fig = px.histogram(
df_select,
x="make-year",
title='생산 연도별 현황'
)
make_year_fig.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
bargap=0.1,
xaxis=dict(showgrid=False)
)
right_column.plotly_chart(make_year_fig, use_container_width=True)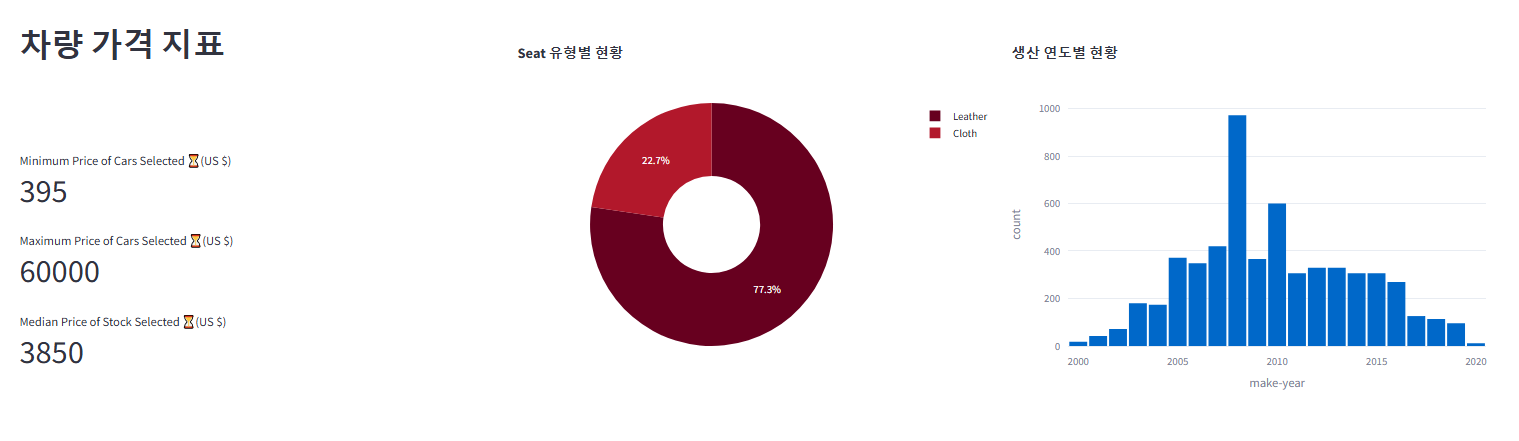
전체코드
실패한 전체선택 해제 관련 코드를 제외한 전체 코드는 아래와 같다.
import pandas as pd
import numpy as np
import streamlit as st
import plotly.express as px
import mysql.connector
from mysql.connector import Error
# MySQL 정보
DB_HOST = 'localhost'
DB_PORT = '3306'
DB_NAME = 'tabledb'
DB_USER = 'root'
DB_PASS = '1234'
DB_TABLE = 'cars' # 테이블 이름
# 메인 페이지 너비 넓게 (가장 처음에 설정해야 함)
st.set_page_config(layout="wide")
# 데이터베이스와 프로그램 간 연결 (파이프라인)
def create_database_connection():
try:
connection = mysql.connector.connect( # 데이터베이스를 연동하는 객체
host=DB_HOST,
database=DB_NAME,
user=DB_USER,
password=DB_PASS
)
if connection.is_connected():
print("MySQL 데이터베이스에 성공적으로 연결되었습니다.")
return connection
except Error as e:
print(f"데이터베이스 연결 오류 발생: {e}")
return None
# 데이터 가져오기 (캐싱 적용)
@st.cache_data
def get_data():
connection = create_database_connection()
if connection is None:
return pd.DataFrame()
try:
query = f"SELECT * FROM {DB_TABLE}"
df = pd.read_sql(query, connection)
# 열 이름 조정
df = df.rename(columns={
"foreign_local_used": "Foreign_Local_Used",
"seat_make": "seat-make",
"make_year": "make-year",
"automation": "Automation" # 추가: 소문자 -> 대문자
})
return df
except Error as e:
print(f"데이터 조회 중 오류 발생: {e}")
return pd.DataFrame()
finally:
if connection.is_connected():
connection.close()
# 필터링된 데이터 캐싱
@st.cache_data
def filter_data(df, manufacturer, automation, use_category):
return df.query(
"manufacturer == @manufacturer & Automation == @automation & Foreign_Local_Used == @use_category"
)
# 데이터 가져오기
df = get_data()
# 데이터가 비어있는 경우 처리
if df.empty:
st.error("데이터베이스에서 데이터를 가져오지 못했습니다. 연결 정보를 확인하세요.")
st.stop()
# 사이드바 생성
st.sidebar.header('데이터 조회 옵션 선택')
# 제조사 멀티셀렉트 옵션 생성
manufacturer_options = ['All'] + df['manufacturer'].unique().tolist() # 전체 선택 및 제조사의 유니크 값
# 사용자가 선택한 제조사 저장
manufacturer = st.sidebar.multiselect(
"제조사를 선택하세요:",
options=manufacturer_options,
default=['All'] # 기본값 .
)
# 전체 선택 시
if 'All' in manufacturer:
manufacturer = df['manufacturer'].unique().tolist() # 모든 제조사 선택
else:
manufacturer = manufacturer # 사용자가 선택한 제조사 유지
# 변속기 라디오 버튼
automation = st.sidebar.radio(
"변속기를 선택하세요:",
options=df['Automation'].unique()
)
# 사용 카테고리 라디오 버튼
use_category = st.sidebar.radio(
"카테고리를 선택하세요:",
options=df['Foreign_Local_Used'].unique()
)
# 데이터 필터링
df_select = filter_data(df, manufacturer, automation, use_category)
# 필터링된 데이터가 비어있는 경우 처리
if df_select.empty:
st.warning("현재 필터 설정에 해당하는 데이터가 없습니다!")
st.stop()
# emoji url: https://streamlit-emoji-shortcodes-streamlit-app-gwckff.streamlit.app/
# 메인 화면
title = "자동차 재고 현황"
st.markdown(f"<h1 style='text-align: center; color: grey;'>🚗{title}🚗</h1>", unsafe_allow_html=True)
st.dataframe(df_select, use_container_width=True)
# (핵심 성과 지표) 계산
average_price = int(df_select['price'].mean() / 1000)
car_count = df_select.shape[0]
avg_make_year = df_select['make-year'].mean()
st.markdown('#####')
# KPI 표시
first_column, second_column, third_column = st.columns(3)
with first_column:
st.subheader("평균 가격:")
st.subheader(f"US $ {average_price:,}")
with second_column:
st.subheader("수량:")
st.subheader(f"{car_count:,}대")
with third_column:
st.subheader("평균 생산 년도:")
st.subheader(f"{(avg_make_year):.0f}년")
st.divider()
# 색상별 가격 막대 차트
price_per_color = df_select.groupby(by=["color"])[["price"]].sum().sort_values(by="price")
fig_color_price = px.bar(
price_per_color / 1000,
x="price",
y=price_per_color.index,
orientation="h",
title="<b>색상별 가격 추이</b>",
color_discrete_sequence=["#0083B8"] * len(price_per_color),
template="plotly_white",
)
fig_color_price.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
# 제조사별 가격 막대 차트
price_per_make = df_select.groupby(by=["manufacturer"])[["price"]].sum().sort_values(by="price")
make_price_fig = px.bar(
price_per_make / 1000,
x=price_per_make.index,
y="price",
orientation="v",
title="<b>제조사별 가격 추이</b>",
color_discrete_sequence=["#0083B8"] * len(price_per_make),
template="plotly_white",
)
make_price_fig.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
# 차트 표시
left_column, right_column = st.columns(2)
left_column.plotly_chart(fig_color_price, use_container_width=True)
right_column.plotly_chart(make_price_fig, use_container_width=True)
st.divider()
# 시트 유형별 파이 차트
seat_make_dist = df.groupby(by=["seat-make"])[['price']].agg('count').sort_values(by='seat-make')
fig_seat_dist = px.pie(
seat_make_dist,
values="price",
title="Seat 유형별 현황",
names=seat_make_dist.index,
color_discrete_sequence=px.colors.sequential.RdBu,
hole=0.4
)
fig_seat_dist.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
# 가격 지표
max_price = df_select['price'].max()
min_price = df_select['price'].min()
median_price = df_select['price'].median()
# 3열 레이아웃
left_column, middle_column, right_column = st.columns(3)
with left_column:
st.markdown("## 차량 가격 지표")
st.markdown('##')
left_column.metric(label="Minimum Price of Cars Selected ⏳(US $)", value=int(min_price / 1000))
left_column.metric(label="Maximum Price of Cars Selected ⏳(US $)", value=int(max_price / 1000))
left_column.metric(label="Median Price of Stock Selected ⏳(US $)", value=int(median_price / 1000))
middle_column.plotly_chart(fig_seat_dist, use_container_width=True)
# 생산 연도별 히스토그램
make_year_fig = px.histogram(
df_select,
x="make-year",
title='생산 연도별 현황'
)
make_year_fig.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
bargap=0.1,
xaxis=dict(showgrid=False)
)
right_column.plotly_chart(make_year_fig, use_container_width=True)
# Streamlit 스타일 숨기기 및 푸터 추가
st.markdown(
"""
<style>
footer {visibility: hidden;}
footer:after{
content: 'Created by Samson Afolabi';
visibility: visible;
position: relative;
right: 115px;
}
</style>
""",
unsafe_allow_html=True,
)
다음 내용
[파이썬] Faker 라이브러리로 가짜 데이터 생성하기
이전 내용 [파이썬] Streamlit 웹 개발 - 8: 대시보드 꾸미기이전 내용 [파이썬] Streamlit 웹 개발 - 7: DB이전 내용 [파이썬] Streamlit 웹 개발 - 6: 저장 관련이전 내용 [파이썬] Streamlit 웹 개발 - 5: 로
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 웹개발>' 카테고리의 다른 글
| [파이썬] 프로젝트 : 웹 페이지 구축 - 6(DB 연동) (0) | 2025.03.21 |
|---|---|
| [파이썬] Faker 라이브러리로 가짜 데이터 생성하기 (2) | 2025.03.20 |
| [파이썬] Streamlit 웹 개발 - 7: DB (0) | 2025.03.19 |
| [파이썬] Streamlit 웹 개발 - 6: 저장 관련 (0) | 2025.03.19 |
| [파이썬] Streamlit 웹 개발 - 5: 로또 번호 생성 페이지 (0) | 2025.03.18 |



