이전 내용
[파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 6
이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 5이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 4이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 3
puppy-foot-it.tistory.com
사이드바, 탭 만들기
앞서 짜뒀던 레이아웃에 맞게 전체 레이아웃을 변경하고, 안에 들어갈 내용을 세부적으로 꾸미는 순으로 진행해 본다.
기본 레이아웃을 짜준 다음 날짜 기준, 요일 기준으로 데이터를 조회할 수 있도록 만들어야 하기 때문에 이를 데이터프레임에 연동시켜줘야 하는 작업까지 해야 한다.
1. 데이터 가져오는 함수 수정
첫 부분과 메인 함수 부분은 기존과 동일하나, 데이터를 가져오는 부분을 수정하였다.
수정한 이유는 기존 데이터에 요일 정보를 추가해야 하기 때문이며, dt.day_of_week를 사용하여 DATE 열로부터 요일 정보를 받아오도록 했다. 그러나 반환이 0부터 6까지의 정수형 값으로 반환되기 때문에 출력될 때는 각 요일로 나타날 수 있도록 이를 각 요일에 매핑해줘야 한다.
해당 부분을 수정해줘서 데이터를 불러올 때 요일 정보가 자동으로 입력된 데이터프레임을 반환한다.
(근데 이거 해결하느라 너무 힘들었어서, 다음부터는 그냥 csv에 넣어버리는 게 100만배 낫다 😣)
# 기존 코드와 동일 (필요한 라이브러리 import, DB연결, 테이블 생성, 데이터 삽입 등)
# 데이터 가져오기 (캐싱 적용)
@st.cache_data
def get_data():
connection = get_db_connection()
if connection is None:
return pd.DataFrame()
try:
query = f"SELECT * FROM {DB_TABLE}"
df = pd.read_sql(query, connection)
# 열 이름 조정
df = df.rename(columns={
"날짜":"DATE",
"지역":"CITY",
"방문자수":"VISITORS",
"연령대":"age",
"성별":"gender",
"이벤트 종류":"CAMP",
"참여자수":"PART",
"참여비율":"P_Ratio"
})
df['DATE'] = pd.to_datetime(df['DATE']) # DATE 컬럼을 datetime 형식으로 변환
df['WEEKDAY'] = df['DATE'].dt.day_of_week # 요일 정보 추가하여 데이터프레임에 추가
# 요일의 인덱스와 매칭하기 위한 딕셔너리
week_mapping = {
0:'월',
1:'화',
2:'수',
3:'목',
4:'금',
5:'토',
6:'일'
}
# WEEKDAY 컬럼의 숫자를 한글 요일로 변환
df['WEEKDAY'] = df['WEEKDAY'].map(week_mapping)
return df
except Error as e:
print(f"데이터 조회 중 오류 발생: {e}")
return pd.DataFrame()
finally:
if connection.is_connected():
connection.close()
# 메인 함수 (기존과 동일)
def main():
2. 날짜와 요일 기준으로 필터링된 데이터를 저장하는 기능 추가
사용자로부터 입력받은 날짜 범위 및 요일 기준에 따라 필터링된 데이터프레임을 반환하는 함수를 정의하고, 무의미하게 반복적인 호출을 하지 않도록 데코레이터를 설정해 준다.
또한, 요일의 필터링 기준에는 전체('All')를 추가하여 전체를 선택했을 때는 모든 요일이 보일 수 있도록 한다.
# 필터링된 데이터 캐싱
@st.cache_data
def filter_data(df, start_date_input, end_date_input, selected_day_w):
# 날짜와 요일 기준으로 필터링
if 'All' in selected_day_w:
return df[(df['DATE'] >= start_date_input) & (df['DATE'] <= end_date_input)]
else:
return df[(df['DATE'] >= start_date_input) &
(df['DATE'] <= end_date_input) &
(df['WEEKDAY'].isin(selected_day_w))]
3. Streamlit 레이아웃짜기 + 기능 넣어주기
Streamlit을 이용하여 특정 날짜 및 요일에 따라 성과 지표를 동적으로 필터링하는 기능을 넣어주었다.
특히, 두 데이터가 해당 사이드바의 영향을 받아야 하므로, 사이드바 내에 탭을 넣어주었다.
그리고 데이터가 출력될 때 특정 컬럼만 출력되도록 추가로 설정해주었다.
기간의 경우, 시작날짜와 종료날짜를 지정해놓고 기본값은 각 기간의 1사분위수와 3사분위수가 지정되도록 하였다.
# Streamlit UI
st.markdown("# :recycle: :rainbow[재활용 이벤트 성과 지표] :recycle:")
# 데이터에서 날짜 정보 추출
df = get_data() # 데이터프레임 가져오기
df['DATE'] = pd.to_datetime(df['DATE'], errors='coerce') # FORMAT 변경
# min_year = df['DATE'].dt.year.min() # 데이터프레임의 최소 연도
# max_year = df['DATE'].dt.year.max() # 데이터프레임의 최대 연도
period_q1 = df['DATE'].quantile(0.25) # 전체 기간의 1사분위 지점
period_q3 = df['DATE'].quantile(0.75) # 전체 기간의 3사분위 지점
start_date = df['DATE'].min() # 데이터의 시작 일자
end_date = df['DATE'].max() # 데이터의 종료 일자
# 사이드바: 화면 왼쪽의 영역을 나누어 사용
st.sidebar.header('데이터 조회 옵션 선택')
# 1. 날짜 조회 슬라이더
st.sidebar.write(":calendar: **기간 조회** :calendar:")
start_date_input = st.sidebar.date_input(
"시작날짜",
value=period_q1,
min_value=start_date, # 데이터의 최소 날짜
max_value=end_date # 데이터의 최대 날짜
)
end_date_input = st.sidebar.date_input(
"종료날짜",
value=period_q3,
min_value=start_date, # 데이터의 최소 날짜
max_value=end_date # 데이터의 최대 날짜
)
# 입력된 날짜를 datetime 타입으로 변환
start_date_input = pd.to_datetime(start_date_input)
end_date_input = pd.to_datetime(end_date_input)
# 요일 조회 레이아웃 추가
wdays_options = ['All'] + df['WEEKDAY'].unique().tolist() # 전체 선택 및 요일의 유니크 값
selected_day_w = st.sidebar.multiselect(
('**:blue[요일을 선택해 주세요]**'),
options=wdays_options,
default=['All'], # 기본값: 전체
placeholder='요일 선택'
)
# 탭 생성하기
tab1, tab2 = st.tabs(['오프라인', '온라인'])
# 데이터 조회 버튼
if st.sidebar.button("데이터 조회"):
# 데이터 필터링
df_select = filter_data(df, start_date_input, end_date_input, selected_day_w)
# 데이터 출력
with tab1:
st.markdown("## :runner: **:grey[오프라인 마케팅 데이터]** :runner:")
# 특정열만 출력
columns_to_display = ['DATE', 'CITY', 'VISITORS', 'age', 'gender', 'CAMP', 'PART', 'P_Ratio', 'WEEKDAY']
# 선택열만 출력
filtered_selected_df = df_select[columns_to_display]
if not filtered_selected_df.empty:
st.dataframe(filtered_selected_df) # 필터링된 데이터프레임 출력
else:
st.warning("조회된 데이터가 없습니다.")
with tab2:
st.write("온라인 데이터 입니다.") # 온라인 탭의 내용이를 실행해보면,

DB 연동에 필터링 기능까지 걸었으니, 이제 데이터를 통한 시각화 기능을 넣어주면 된다. (근데 온라인 데이터 넣을 때 아마 대폭 수정해야 할지도 모르겠다. 😂)
오프라인 탭에 시각화 기능 추가하기
시각화의 경우, 전날 코드를 다양하게 짜놨기 때문에, 그 코드들을 최대한 활용해서 진행하면 될 듯 하다.
- 핵심 지표 출력
특정 기간 동안 방문자수, 참여자수, 참여율, 참여 도시, 진행 이벤트의 수를 출력하는 레이아웃을 짜고, 해당 변수들을 넣어주었다.
# (핵심 지표) 계산
total_visitors = int(filtered_selected_df['VISITORS'].sum())
total_part = int(filtered_selected_df['PART'].sum())
part_ratio = (total_part/total_visitors) * 100
cities_count = len(filtered_selected_df['CITY'].unique())
evnets_count = len(filtered_selected_df['CAMP'].unique())
st.markdown('#####')
# KPI 표시
first_column, second_column, third_column, fourth_column, fifth_column = st.columns(5)
with first_column:
st.subheader("방문자수:")
st.subheader(f"{(total_visitors):,.0f}명")
with second_column:
st.subheader("참여자수:")
st.subheader(f"{(total_part):,.0f}명")
with third_column:
st.subheader("참여비율:")
st.subheader(f"{(part_ratio):.1f}%")
with fourth_column:
st.subheader("참여 도시:")
st.subheader(cities_count)
with fifth_column:
st.subheader("진행 이벤트:")
st.subheader(evnets_count)
st.divider()
- 방문자수, 참여자수 막대그래프
조회 기간동안의 방문자수와 참여자수의 막대그래프가 출력되도록 하였다.
# 데이터 시각화
# 'DATE'를 월 단위로 그룹화하고 각 도시별 방문자 수를 합산
monthly_visitors = filtered_selected_df.groupby(['CITY', pd.Grouper(key='DATE', freq='M')])['VISITORS'].sum().reset_index()
fig_month_visitors = px.bar(
monthly_visitors,
x="CITY",
y='VISITORS',
orientation="v",
title="<b>지역별 월간 방문자수</b>",
color_discrete_sequence=["#0083B8"] * len(monthly_visitors),
template="plotly_white",
)
fig_month_visitors.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
# 'DATE'를 월 단위로 그룹화하고 각 도시별 참여자 수를 합산
monthly_part = filtered_selected_df.groupby(['CITY', pd.Grouper(key='DATE', freq='M')])['PART'].sum().reset_index()
fig_month_part = px.bar(
monthly_part,
x="CITY",
y='PART',
orientation="v",
title="<b>지역별 월간 참여자수</b>",
color_discrete_sequence=["#0083B8"] * len(monthly_part),
template="plotly_white",
)
fig_month_part.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
# 차트 표시
left_column, right_column = st.columns(2)
left_column.plotly_chart(fig_month_visitors, use_container_width=True)
right_column.plotly_chart(fig_month_part, use_container_width=True)
st.divider()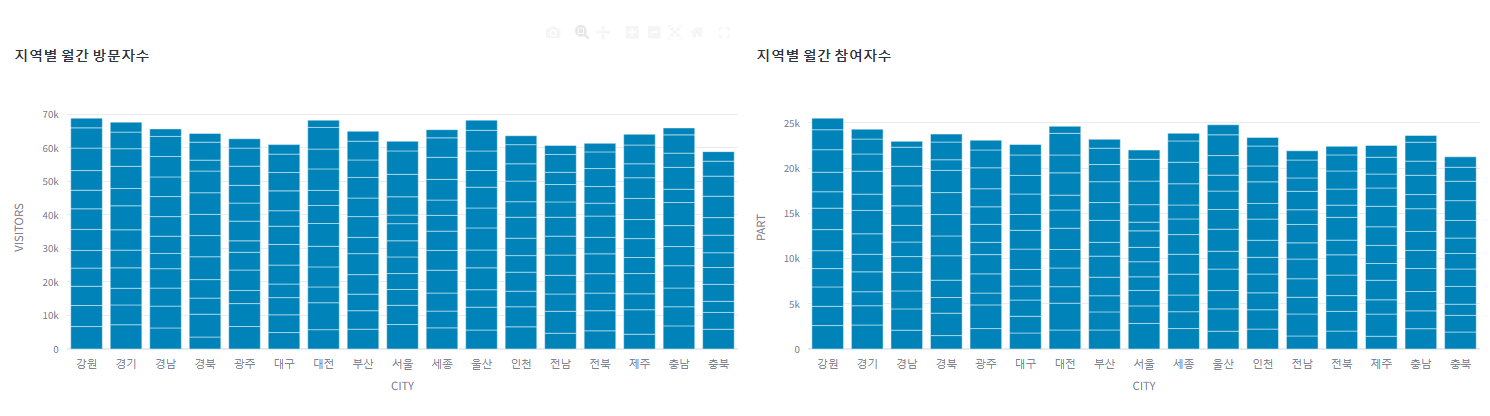
▶ 차트 안에 전체, 성별, 캠페인별, 연령대별 의 옵션을 주고, 특정 옵션을 선택하면 데이터가 동적으로 바뀌게 구현하려고 했지만 해당 기능을 아직 지원하지는 않는 듯 하다. (옵션을 선택하면 페이지가 아예 새로고침 돼버린다)
또한, 방문자수 차트와 참여자수 차트 시각화 코드는 거의 비슷하므로, 함수를 정의하여 효율을 높이는 방향으로 개선했다.
[개선 코드]
def create_monthly_bar_chart(data, value_col, title):
# 월별로 그룹화하여 합계 계산
monthly_data = data.groupby(['CITY', pd.Grouper(key='DATE', freq='M')])[value_col].sum().reset_index()
# Plotly로 막대 그래프 생성
fig = px.bar(
monthly_data,
x="CITY",
y=value_col,
orientation="v",
title=f"<b>{title}</b>",
color_discrete_sequence=["#0083B8"] * len(monthly_data),
template="plotly_white",
)
# 레이아웃 업데이트
fig.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
return fig
# 차트 생성
left_column, right_column = st.columns(2)
with left_column:
fig_month_visitors = create_monthly_bar_chart(filtered_selected_df, 'VISITORS', '지역별 월간 방문자수')
st.plotly_chart(fig_month_visitors, use_container_width=True)
with right_column:
fig_month_part = create_monthly_bar_chart(filtered_selected_df, 'PART', '지역별 월간 참여자수')
st.plotly_chart(fig_month_part, use_container_width=True)
st.divider()- 캠페인별 방문 비율, 참여 비율 파이 차트 시각화
마찬가지로, 파이 차트를 생성하는 함수를 정의하여 효율성을 높였다.
# 캠페인별 비율 파이차트
# 파이차트를 생성하는 함수
def create_pie_chart(data, value_col, label_col, title):
summary = data.groupby([label_col])[value_col].sum().reset_index()
labels = summary[label_col].unique()
explode = [0.1 for _ in range(len(labels))] # 모든 섹터를 약간 부풀리기
colors = sns.color_palette("Set2", len(labels))
plt.figure(figsize=(6, 6))
plt.pie(
summary[value_col],
labels=labels,
autopct='%.1f%%',
startangle=260,
colors=colors,
explode=explode,
shadow=True
)
plt.title(title)
plt.axis('equal') # 원형 비율을 유지하기 위해 설정
# 차트 생성
left_column, right_column = st.columns(2)
with left_column:
create_pie_chart(filtered_selected_df, 'VISITORS', 'CAMP', '캠페인별 방문율')
st.pyplot(plt.gcf()) # 현재의 plt Figure를 Streamlit에 표시
with right_column:
create_pie_chart(filtered_selected_df, 'PART', 'CAMP', '캠페인별 참여율')
st.pyplot(plt.gcf()) # 현재의 plt Figure를 Streamlit에 표시
st.divider()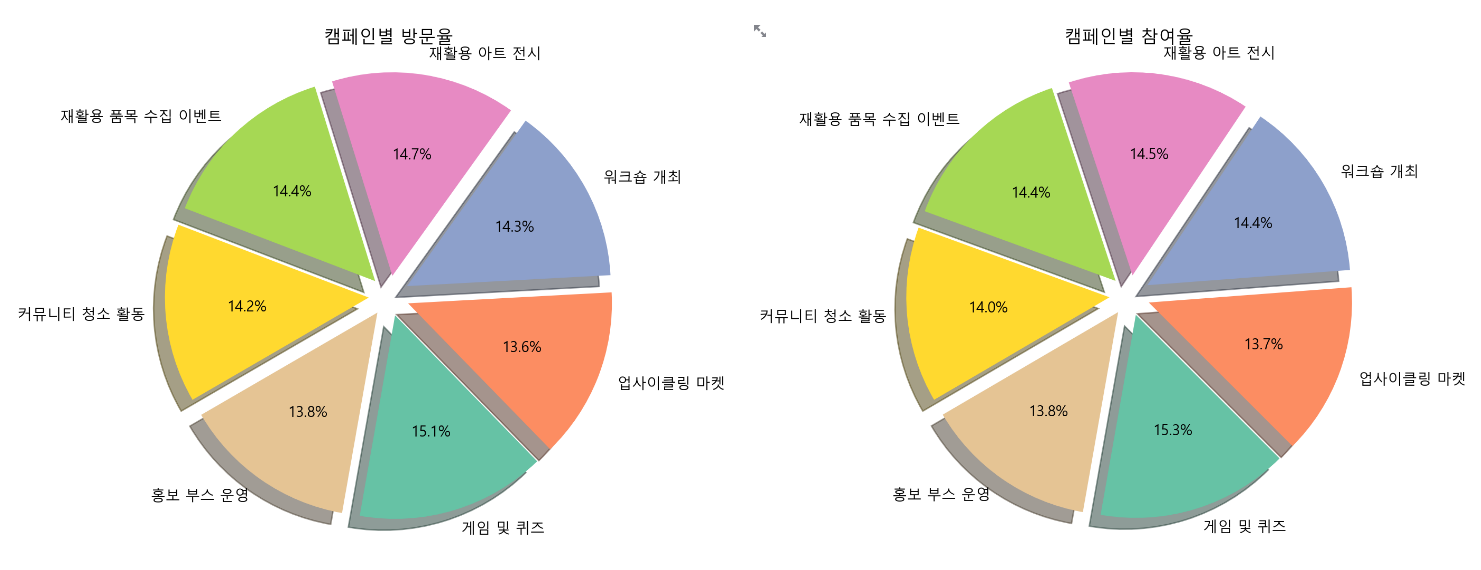
- 연령대별 방문수, 참여수 라인 차트 그리기
역시 기존에 작성돼있는 코드 + 함수 정의를 활용하여 라인 차트도 그려준다.
# 연령대별 데이터 시각화: 선 그래프 생성 함수
def create_line_chart(data, value_col, title):
summary = data.groupby(['DATE', 'age'])[value_col].sum().reset_index()
plt.figure(figsize=(10, 6))
# 라인 차트 그리기
sns.lineplot(data=summary, x='DATE', y=value_col, hue='age', marker='o')
# 라벨과 제목 설정
plt.xlabel("기간")
plt.ylabel(value_col)
plt.title(title)
# 날짜 형식 설정
plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=2)) # 2개월 간격
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
# 최대 6개 레이블 표시하도록 설정
ax = plt.gca()
ax.xaxis.set_major_locator(ticker.MaxNLocator(nbins=6, prune='both'))
plt.gcf().autofmt_xdate() # X축 레이블 자동 회전
# 그래프 레이아웃 조정
plt.grid(True)
plt.tight_layout()
# 차트 생성
left_column, right_column = st.columns(2)
with left_column:
create_line_chart(filtered_selected_df, 'VISITORS', '연령대별 월별 방문율')
st.pyplot(plt.gcf()) # 현재의 plt Figure를 Streamlit에 표시
with right_column:
create_line_chart(filtered_selected_df, 'PART', '연령대별 월별 참여율')
st.pyplot(plt.gcf()) # 현재의 plt Figure를 Streamlit에 표시
st.divider()
코드 (뼈대) 대폭 수정
레이아웃을 짜고 시각화 기능을 넣고 있는데, 아까 실패했던 세부 조건별로 시각화를 하는 법을 개선하였다. (진짜 오랜 시간이 걸렸다..)
핵심적으로는,
- 지역별로 필터링이 되게끔 하는데, 탭의 상단에 Mulitselect 버튼을 추가하여 특정 지역들만 선택할 수 있도록 함. 물론, 전체 지역을 선택할 수 있는 'All_CITIES' 라는 옵션도 추가
- 따라서, 데이터 필터링에는 기존의 시작일, 종료일, 요일에서 도시가 추가되었다.
- 기존에 사이드바에 있던 데이터 조회 버튼을 지역을 선택한 후 조회할 수 있도록 하였는데,
- 데이터프레임, 성과 지표, 차트 등 모든 출력되는 버튼들을 if 문 안에 넣어줘서 조회 버튼을 누른 다음에 출력되게끔 변경하였다.
- 기존에 차트를 생성하는 코드는 들여쓰기만 바꿔주고 그대로 쓸 수 있도록 하였다.
[개선된 전체 코드]
import streamlit as st
import pandas as pd
import mysql.connector
from mysql.connector import Error
import numpy as np
import datetime
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as px
import streamlit as st
import time
import matplotlib.dates as mdates
import matplotlib.ticker as ticker
# 메인 페이지 너비 넓게 (가장 처음에 설정해야 함)
st.set_page_config(layout="wide")
with st.spinner("잠시만 기다려 주세요..."):
time.sleep(1) # 대기 시간 시뮬레이션
st.success("Data Loaded!")
# 한글 및 마이너스 깨짐
from matplotlib import rc
plt.rcParams['font.family'] = "Malgun Gothic"
plt.rcParams['axes.unicode_minus'] = False
# CSV 파일 경로 설정
CSV_FILE_PATH = 'https://raw.githubusercontent.com/.../main/recycling_off.csv'
# Streamlit emoji: https://streamlit-emoji-shortcodes-streamlit-app-gwckff.streamlit.app/
# 테이블 이름 설정
DB_TABLE = 'recycle_off'
# MySQL 연결 정보 (secrets.toml에서 가져옴)
def get_db_connection():
try:
secrets = st.secrets["mysql"]
connection = mysql.connector.connect(
host=secrets["host"],
database=secrets["database"],
user=secrets["user"],
password=secrets["password"]
)
if connection.is_connected():
st.write()
return connection
except Error as e:
st.error(f"데이터베이스 연결 실패: {e}")
return None
# 프로그램에서 테이블 생성
@st.cache_data
def create_table(_connection): # 인자 이름에 "_" 추가
try:
cursor = _connection.cursor()
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {DB_TABLE} (
id INT AUTO_INCREMENT PRIMARY KEY,
날짜 DATETIME,
지역 VARCHAR(20),
방문자수 INT,
연령대 VARCHAR(20),
성별 VARCHAR(10),
`이벤트 종류` VARCHAR(20),
참여자수 INT,
참여비율 FLOAT
);
"""
cursor.execute(create_table_query) # 쿼리 실행
_connection.commit()
print(f"'{DB_TABLE}' 테이블이 성공적으로 생성되었습니다.")
except Error as e:
st.error(f"테이블 생성 중 오류 발생: {e}")
finally:
cursor.close()
# 데이터 삽입 함수
@st.cache_data
def insert_data(_connection, df): # 인자 이름에 "_" 추가
try:
cursor = _connection.cursor()
insert_query = f"""
INSERT INTO {DB_TABLE} (
날짜, 지역, 방문자수, 연령대, 성별, `이벤트 종류`, 참여자수, 참여비율
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
# 판다스 데이터프레임을 numpy 배열로 만들어 배열을 하나씩 꺼내 튜플로 생성
data = [tuple(row) for row in df.values]
cursor.executemany(insert_query, data) # 여러 줄 처리
_connection.commit()
print(f"{cursor.rowcount}개의 레코드가 '{DB_TABLE}' 테이블에 삽입되었습니다.")
except Error as e:
st.error(f"데이터 삽입 중 오류 발생: {e}")
finally:
cursor.close()
# 데이터 가져오기 (캐싱 적용)
@st.cache_data
def get_data():
connection = get_db_connection()
if connection is None:
return pd.DataFrame()
try:
query = f"SELECT * FROM {DB_TABLE}"
df = pd.read_sql(query, connection)
# 열 이름 조정
df = df.rename(columns={
"날짜":"DATE",
"지역":"CITY",
"방문자수":"VISITORS",
"연령대":"age",
"성별":"gender",
"이벤트 종류":"CAMP",
"참여자수":"PART",
"참여비율":"P_Ratio"
})
df['DATE'] = pd.to_datetime(df['DATE']) # DATE 컬럼을 datetime 형식으로 변환
df['WEEKDAY'] = df['DATE'].dt.day_of_week # 요일 정보 추가하여 데이터프레임에 추가
# 요일의 인덱스와 매칭하기 위한 딕셔너리
week_mapping = {
0:'월',
1:'화',
2:'수',
3:'목',
4:'금',
5:'토',
6:'일'
}
# WEEKDAY 컬럼의 숫자를 한글 요일로 변환
df['WEEKDAY'] = df['WEEKDAY'].map(week_mapping)
return df
except Error as e:
print(f"데이터 조회 중 오류 발생: {e}")
return pd.DataFrame()
finally:
if connection.is_connected():
connection.close()
# 메인 함수
def main():
# CSV 파일 읽기
try:
df = pd.read_csv(CSV_FILE_PATH, encoding="UTF8")
print("CSV 파일을 성공적으로 읽었습니다.")
df.replace([np.inf, -np.inf], np.nan, inplace=True)
except FileNotFoundError:
st.error(f"파일 '{CSV_FILE_PATH}'을 찾을 수 없습니다.")
return
except Exception as e:
st.error(f"CSV 파일 읽기 중 오류 발생: {e}")
return
# 데이터베이스 연결
connection = get_db_connection()
if connection is None:
return
# 테이블 생성
create_table(connection) # 호출 시 변경된 인자 사용
# 데이터 삽입
insert_data(connection, df) # 호출 시 변경된 인자 사용
# 연결 종료
if connection.is_connected():
connection.close()
# 메인 함수 실행
if __name__ == "__main__":
main()
# 필터링된 데이터 캐싱
@st.cache_data
def filter_data(df, start_date, end_date, selected_day, selected_city):
# 날짜 필터링
df_filtered = df[(df['DATE'] >= start_date) & (df['DATE'] <= end_date)]
# 요일 필터링: All이 선택되었거나 selected_day가 비어 있을 시 필터링 하지 않음
if selected_day and 'All' not in selected_day:
df_filtered = df_filtered[df_filtered['WEEKDAY'].isin(selected_day)]
# 도시 필터링: 'All_CITIES'가 선택되면 모든 도시를 반환
if 'All_CITIES' not in selected_city:
df_filtered = df_filtered[df_filtered['CITY'].isin(selected_city)]
return df_filtered
# Streamlit UI
st.markdown("# :recycle: :rainbow[재활용 이벤트 성과 지표] :recycle:")
# 데이터에서 날짜 정보 추출
df = get_data() # 데이터프레임 가져오기
df['DATE'] = pd.to_datetime(df['DATE'], errors='coerce') # FORMAT 변경
# min_year = df['DATE'].dt.year.min() # 데이터프레임의 최소 연도
# max_year = df['DATE'].dt.year.max() # 데이터프레임의 최대 연도
period_q1 = df['DATE'].quantile(0.25) # 전체 기간의 1사분위 지점
period_q3 = df['DATE'].quantile(0.75) # 전체 기간의 3사분위 지점
start_date = df['DATE'].min() # 데이터의 시작 일자
end_date = df['DATE'].max() # 데이터의 종료 일자
# 사이드바: 화면 왼쪽의 영역을 나누어 사용
st.sidebar.header('데이터 조회 옵션 선택')
# 1. 날짜 조회 슬라이더
st.sidebar.write(":calendar: **기간 조회** :calendar:")
start_date_input = st.sidebar.date_input(
"시작날짜",
value=period_q1,
min_value=start_date, # 데이터의 최소 날짜
max_value=end_date # 데이터의 최대 날짜
)
end_date_input = st.sidebar.date_input(
"종료날짜",
value=period_q3,
min_value=start_date, # 데이터의 최소 날짜
max_value=end_date # 데이터의 최대 날짜
)
# 입력된 날짜를 datetime 타입으로 변환
start_date_input = pd.to_datetime(start_date_input)
end_date_input = pd.to_datetime(end_date_input)
# 요일 조회 레이아웃 추가
wdays_options = ['All'] + df['WEEKDAY'].unique().tolist() # 전체 선택 및 요일의 유니크 값
selected_day_w = st.sidebar.multiselect(
('**:blue[요일을 선택해 주세요]**'),
options=wdays_options,
default=['All'], # 기본값: 전체
placeholder='요일 선택'
)
# 탭 생성하기
tab1, tab2 = st.tabs(['오프라인', '온라인'])
# 데이터 출력
with tab1:
st.markdown("## :runner: **:grey[오프라인 마케팅 데이터]** :runner:")
# 지역 선택하는 멀티 셀렉트 버튼 생성
city_options = ['All_CITIES'] + df['CITY'].unique().tolist() # 전체 선택 및 지역의 유니크 값
selected_city = st.multiselect(
"**:violet[조회하고자 하는 지역을 선택해 주세요.(중복가능)]**",
options=city_options,
default=['All_CITIES'],
placeholder='도시 선택'
)
# 데이터 조회 버튼
if st.button("데이터 조회"):
# 데이터 필터링
df_select = filter_data(df, start_date_input, end_date_input, selected_day_w, selected_city)
# 특정열만 출력
columns_to_display = ['DATE', 'CITY', 'VISITORS', 'age', 'gender', 'CAMP', 'PART', 'P_Ratio', 'WEEKDAY']
# 선택열만 출력
filtered_selected_df = df_select[columns_to_display]
if not filtered_selected_df.empty:
st.dataframe(filtered_selected_df, use_container_width=True) # 필터링된 데이터프레임 출력
# (핵심 지표) 계산
total_visitors = int(filtered_selected_df['VISITORS'].sum())
total_part = int(filtered_selected_df['PART'].sum())
part_ratio = (total_part / total_visitors * 100) if total_visitors > 0 else 0
cities_count = len(selected_city) if 'All_CITIES' not in selected_city else len(filtered_selected_df['CITY'].unique())
events_count = len(filtered_selected_df['CAMP'].unique())
st.markdown('#####')
# KPI 표시
first_column, second_column, third_column, fourth_column, fifth_column = st.columns(5)
with first_column:
st.subheader("방문자수:")
st.subheader(f"{(total_visitors):,.0f}명")
with second_column:
st.subheader("참여자수:")
st.subheader(f"{(total_part):,.0f}명")
with third_column:
st.subheader("참여비율:")
st.subheader(f"{(part_ratio):.1f}%")
with fourth_column:
st.subheader("참여 도시:")
st.subheader(cities_count)
with fifth_column:
st.subheader("진행 이벤트:")
st.subheader(f"{events_count}건")
st.divider()
# 데이터 시각화
# 'DATE'를 월 단위로 그룹화하고 각 도시별 방문자 수를 합산
# 차트를 생성하는 함수
def create_monthly_bar_chart(data, value_col, title):
# 월별로 그룹화하여 합계 계산
monthly_data = data.groupby(['CITY', pd.Grouper(key='DATE', freq='M')])[value_col].sum().reset_index()
monthly_data = monthly_data.dropna(subset=[value_col]) # NaN 제거
# Plotly로 막대 그래프 생성
fig = px.bar(
monthly_data,
x="CITY",
y=value_col,
orientation="v",
title=f"<b>{title}</b>",
color_discrete_sequence=["#0083B8"] * len(monthly_data),
template="plotly_white",
)
# 레이아웃 업데이트
fig.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
xaxis=dict(showgrid=False)
)
return fig
# 차트 생성
left_column, right_column = st.columns(2)
with left_column:
fig_month_visitors = create_monthly_bar_chart(filtered_selected_df, 'VISITORS', '지역별 월간 방문자수')
st.plotly_chart(fig_month_visitors, use_container_width=True)
with right_column:
fig_month_part = create_monthly_bar_chart(filtered_selected_df, 'PART', '지역별 월간 참여자수')
st.plotly_chart(fig_month_part, use_container_width=True)
st.divider()
# 캠페인별 비율 파이차트: 파이차트 생성 함수
def create_pie_chart(data, value_col, label_col, title):
summary = data.groupby([label_col])[value_col].sum().reset_index()
labels = summary[label_col].unique()
explode = [0.1 for _ in range(len(labels))] # 모든 섹터를 약간 부풀리기
plt.figure(figsize=(6, 6))
plt.pie(
summary[value_col],
labels=labels,
autopct='%.1f%%',
startangle=260,
colors = sns.color_palette("Set2", len(labels)),
explode=explode,
shadow=True
)
plt.title(title)
plt.axis('equal') # 원형 비율을 유지하기 위해 설정
# 차트 생성
left_column, right_column = st.columns(2)
with left_column:
create_pie_chart(filtered_selected_df, 'VISITORS', 'CAMP', '캠페인별 방문율')
st.pyplot(plt.gcf()) # 현재의 plt Figure를 Streamlit에 표시
with right_column:
create_pie_chart(filtered_selected_df, 'PART', 'CAMP', '캠페인별 참여율')
st.pyplot(plt.gcf()) # 현재의 plt Figure를 Streamlit에 표시
st.divider()
# 연령대별 데이터 시각화: 선 그래프 생성 함수
def create_line_chart(data, value_col, title):
summary = data.groupby(['DATE', 'age'])[value_col].sum().reset_index()
plt.figure(figsize=(10, 6))
# 라인 차트 그리기
sns.lineplot(data=summary, x='DATE', y=value_col, hue='age', marker='o')
# 라벨과 제목 설정
plt.xlabel("기간")
plt.ylabel(value_col)
plt.title(title)
# 날짜 형식 설정
plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=2)) # 2개월 간격
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
# 최대 6개 레이블 표시하도록 설정
ax = plt.gca()
ax.xaxis.set_major_locator(ticker.MaxNLocator(nbins=6, prune='both'))
plt.gcf().autofmt_xdate() # X축 레이블 자동 회전
# 그래프 레이아웃 조정
plt.grid(True)
plt.tight_layout()
# 차트 생성
left_column, right_column = st.columns(2)
with left_column:
create_line_chart(filtered_selected_df, 'VISITORS', '연령대별 월별 방문율')
st.pyplot(plt.gcf()) # 현재의 plt Figure를 Streamlit에 표시
with right_column:
create_line_chart(filtered_selected_df, 'PART', '연령대별 월별 참여율')
st.pyplot(plt.gcf()) # 현재의 plt Figure를 Streamlit에 표시
st.divider()
else:
st.warning("조회된 데이터가 없습니다.")
with tab2:
st.write("온라인 데이터 입니다.") # 온라인 탭의 내용(온라인 데이터는 변수가 더 많은데 큰일났다..)
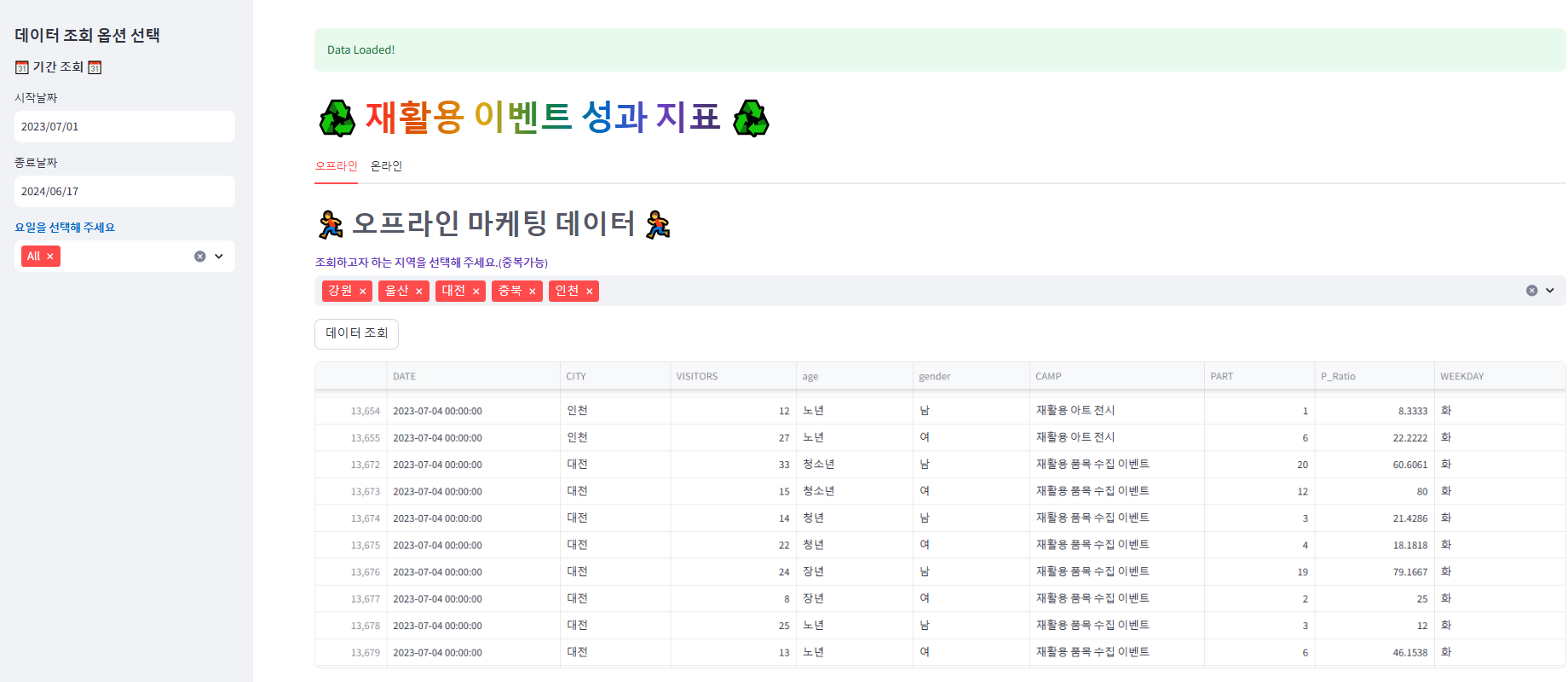
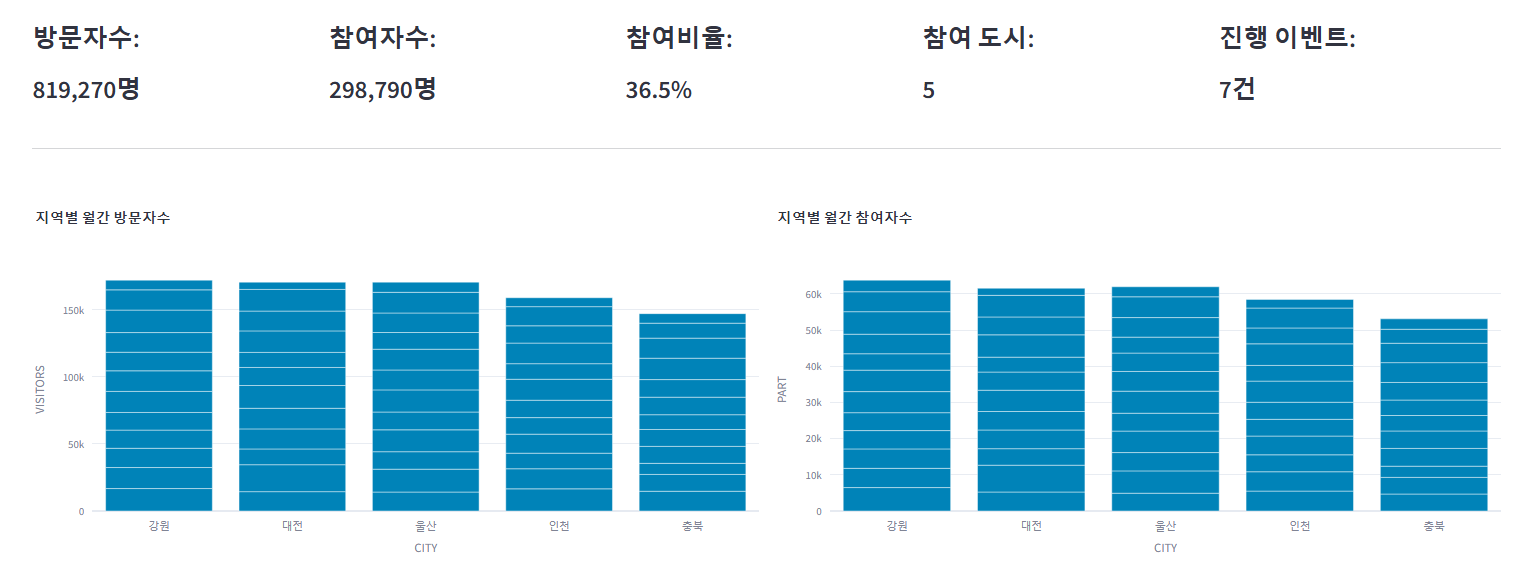
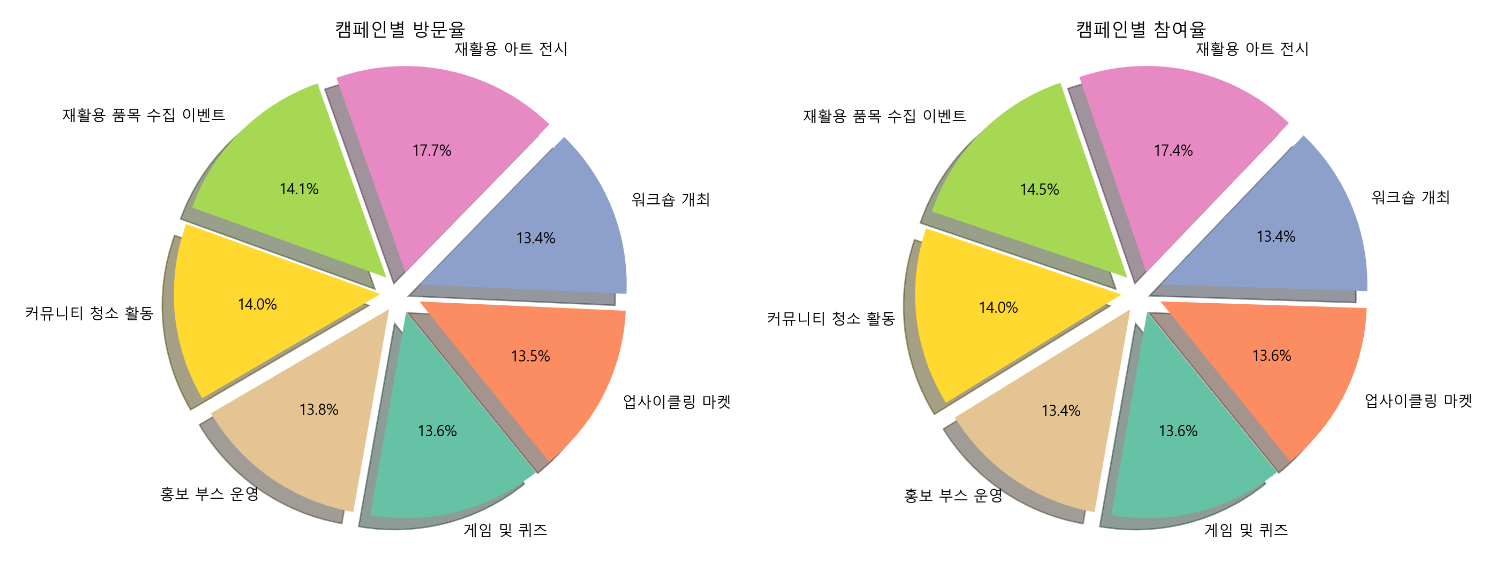
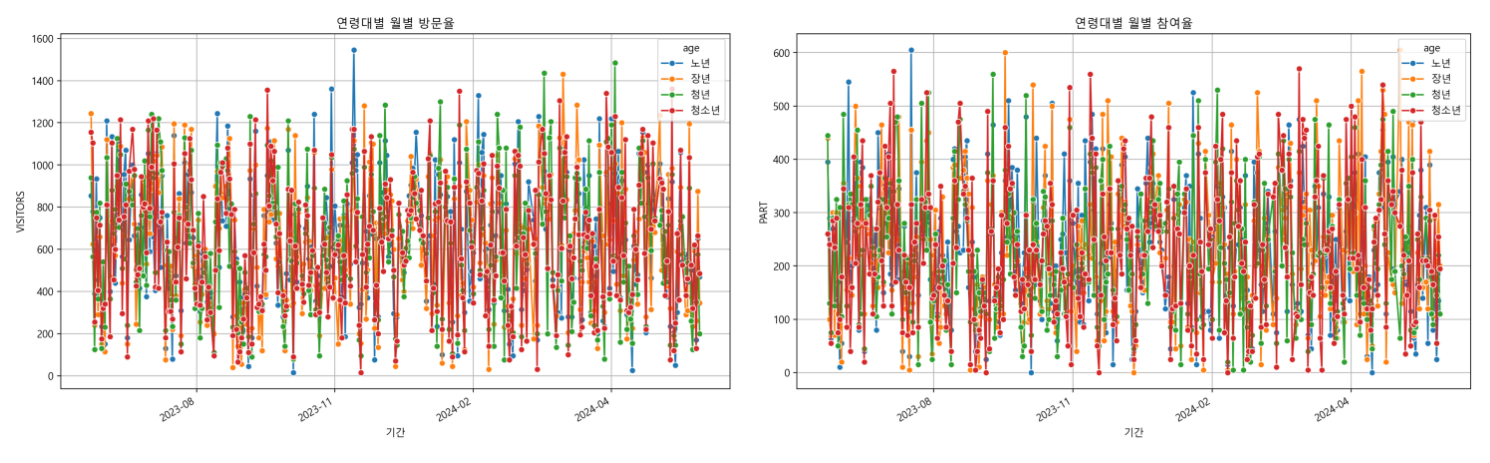
선택된 데이터에 대한 데이터, 지표, 차트 등이 잘 나온다. (몇 가지 디테일한 작업이 필요해 보인다. 특히 라인차트)
머신러닝 기능 넣기
1. 라인 차트 시각화
필터링된 데이터를 기반으로 기간별 참여자수 예측을 한 뒤, 실제 데이터와 비교하는 회귀 분석을 진행하고, 해당 모델의 성능을 rmse로 평가하고, 이를 시각화하는 기능을 추가한다.
# 머신러닝 모델 구현
# 일별 데이터 집계
daily_data = filtered_selected_df.groupby('DATE').agg({'VISITORS':'sum', 'PART':'sum'}).reset_index()
if daily_data.empty:
st.warning("조회된 데이터가 없습니다.")
else:
# 피처와 변수 정의
X = daily_data[['VISITORS']]
y = daily_data[['PART']]
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 회귀 모델 훈련
model = LinearRegression()
model.fit(X_train, y_train)
# 예측 수행
daily_data['PREDICTED_PART'] = model.predict(X) # 전체 데이터에 대한 예측
# 성능 평가
mse = mean_squared_error(y_test, model.predict(X_test))
# MSE 계산 후 RMSE 계산
rmse = np.sqrt(mse)
st.write(f"**:red[회귀 모델 RMSE: {rmse:.2f}]**")
st.write(f"모델이 예측한 참여자 수와 실제 수치 사이의 평균차가 **:blue[{rmse:.2f}]명** 입니다.")
# 기간별 실제 및 예측 참여자 수 시각화
fig = px.line(daily_data, x='DATE', y=['PART', 'PREDICTED_PART'],
labels={'value': '참여자 수'},
title='기간별 실제 참여자 수와 예측 참여자 수 비교',
markers=True)
st.plotly_chart(fig)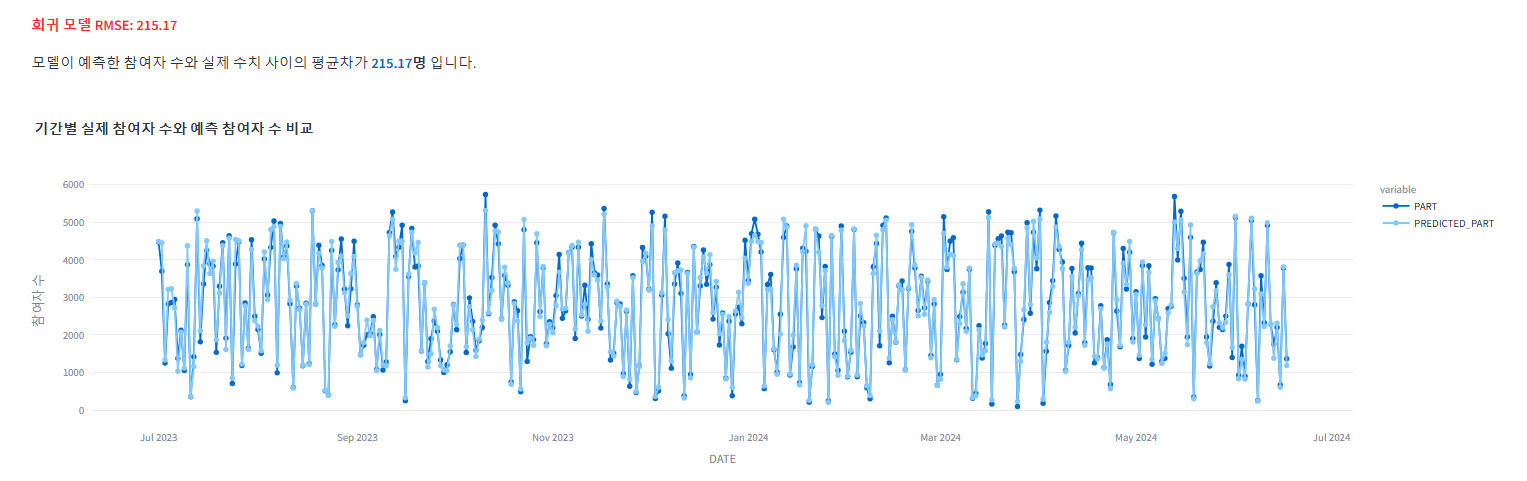
추가로 캠페인별 상관 행렬 히트맵, 조회된 마지막 날짜 기준으로 일수를 입력받아 특정 일자의 참여자를 예측하는 모델 등을 구현하려 했지만 시간 관계상 추후에 기회가 되면 하기로 하고 이제 온라인 데이터를 작업해야 할 거 같다.
다음 내용
[파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 8
이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 7이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 6이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 5
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 웹개발>' 카테고리의 다른 글
| [파이썬] 프로젝트 : 웹 페이지 구축 - 9 (멀티페이지) (0) | 2025.03.24 |
|---|---|
| [파이썬] 프로젝트 : 웹 페이지 구축 - 8 (온라인 페이지 구현) (1) | 2025.03.24 |
| [파이썬] 프로젝트 : 웹 페이지 구축 - 6(DB 연동) (0) | 2025.03.21 |
| [파이썬] Faker 라이브러리로 가짜 데이터 생성하기 (2) | 2025.03.20 |
| [파이썬] Streamlit 웹 개발 - 8: 대시보드 꾸미기 (0) | 2025.03.19 |



