1번

도메인: 엔터티 내에서 속성에 대한 데이터 타입과 크기, 제약사항 지정
(1) 제약조건: 데이터의 무결성 유지
4번

발생시점에 따른 엔터티 분류
1) 기본엔터티: 키 엔터티, 독립적으로 생성 및 관리 - 고객, 부서, 판매 제품, 조직, 사원 등
2) 중심엔터티: 기본 엔터티로부터 발행되는 행위 엔터티를 생성하는 중간 엔터티 - 계좌, 주문, 수납, 계약, 사고, 매출 등
3) 행위엔터티: 상위에 있는 2개 이상의 엔터티로부터 발생 - 주문 이력, 수납 이력, 접속 이력, 주문 내역, 계약 진행 등
> 상품, 주문 상품은 기본엔터티 (정답은 3-C)
11번
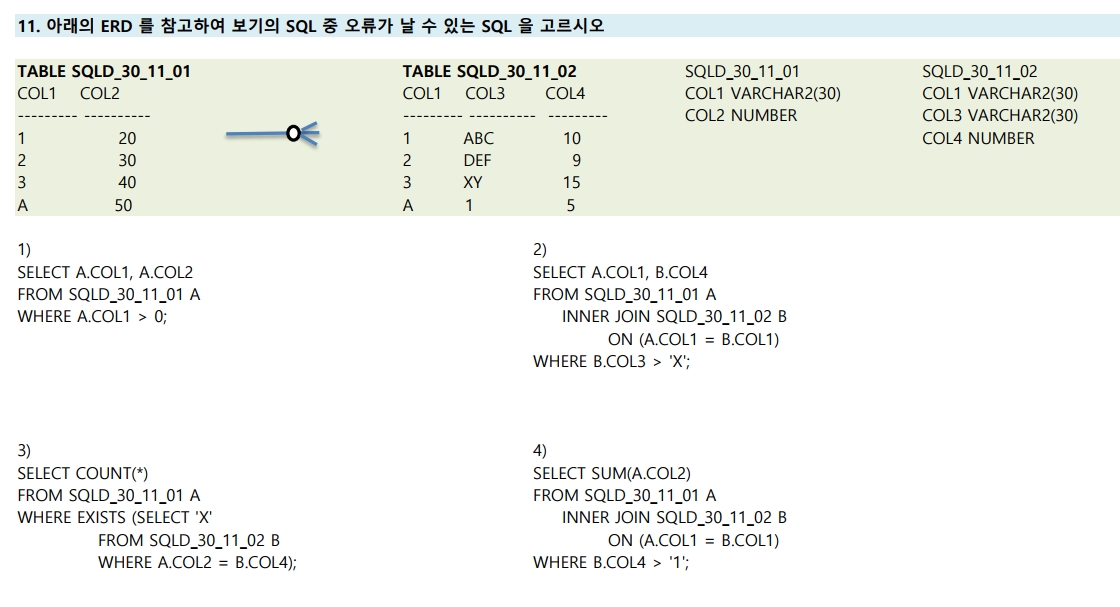
1) 'WHERE A.COL1 >0;' :A테이블의 컬럼1이 0보다 큰 수
SQLD_30_11_01 테이블의 COL1의 제약 조건은 'VARCHAR2(30)'
VARCHAR2 는 가변 문자열이므로 비교연산 불가
12번
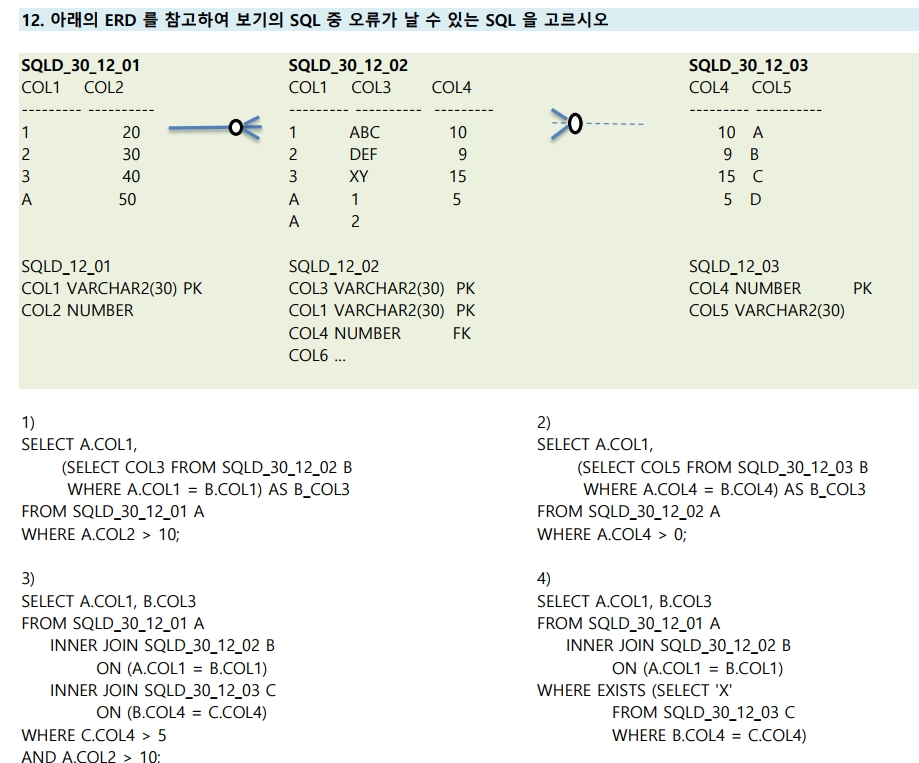
1) SELECT A.COL1, > A테이블의 COL1 선택
(SELECT COL3 FROM SQLD_30_12_02 B >
WHERE A.COL1 = B.COL1) > A.COL1 = B.COL1에서 B테이블의 COL1에서 'A'가 2개 중복되어 오류
AS B_COL3
FROM SQLD_30_12_01 A
WHERE A.COL2 > 10; > A.COL2 > 10 이니 A테이블 전체
13번
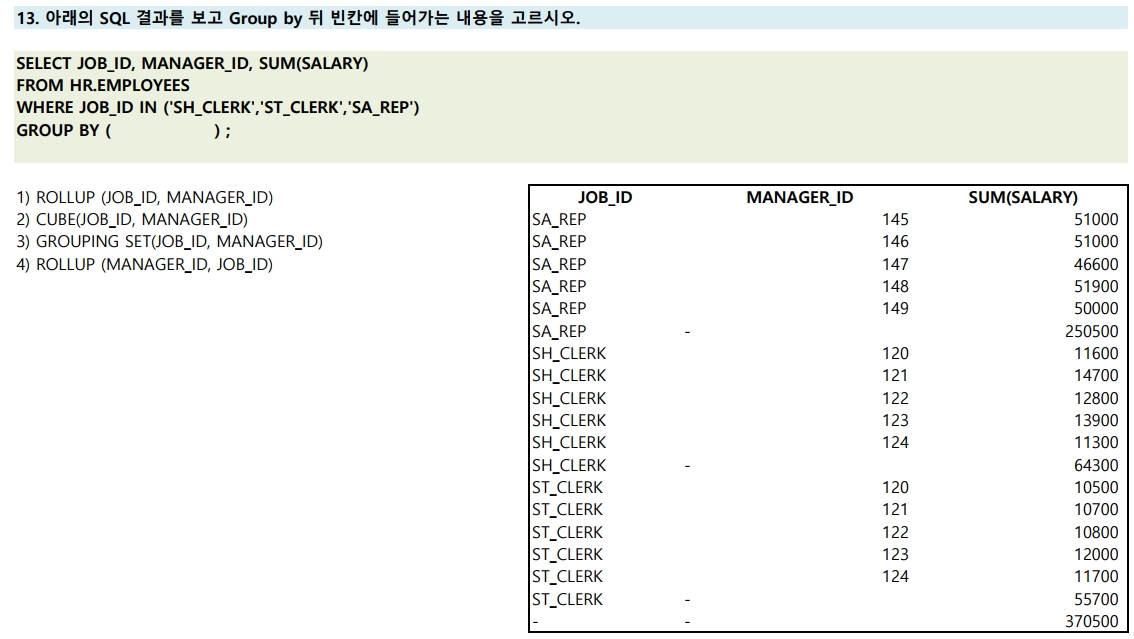
- ROLLUP: SUBTOTAL을 생성하기 위해 사용. GROUPING 컬럼의 수를 N이라 했을 때, N+1 LEVEL의 SUBTOTAL 생성
- GROUPING: 집계 표시면 1, 아니면 0
- CUBE: 결합가능한 모든 값에 대하여 다차원 집계 실행
- GROUPING SETS: 인수들에 대한 개별집계
1) ROLLUP (JOB_ID, MANAGER_ID) > JOB_ID에 대한 합과 총합을 구함 (인수 순서 바꾸면 값 달라짐)
2) CUBE(JOB_ID, MANAGER_ID) > JOB_ID 합, MANAGER_ID 합, 총합 다 구함
3) GROUPING SETS(JOB_ID, MANAGER_ID) > 총합 없음.
14번
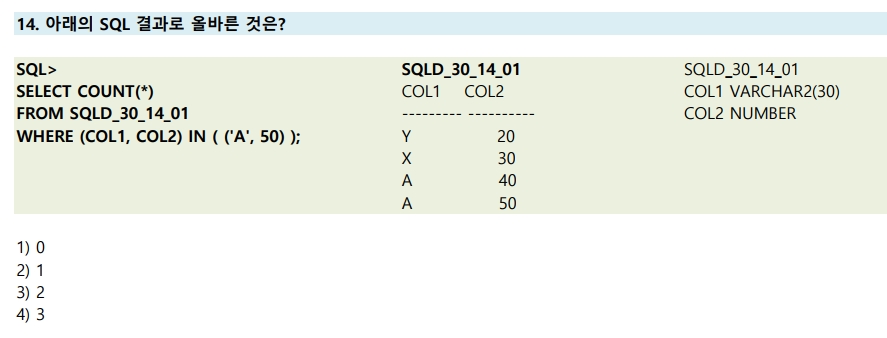
SELECT COUNT(*) > 전체 개수
FROM SQLD_30_14_01
WHERE (COL1, COL2) IN (('A', 50)); > 괄호로 묶여 있으므로, COL1 = A 이면서 (AND) COL2 = 50 인 값
따라서 1개
※ IN: 리스트에 있는 값 중 어느 하나라도 일치
15번
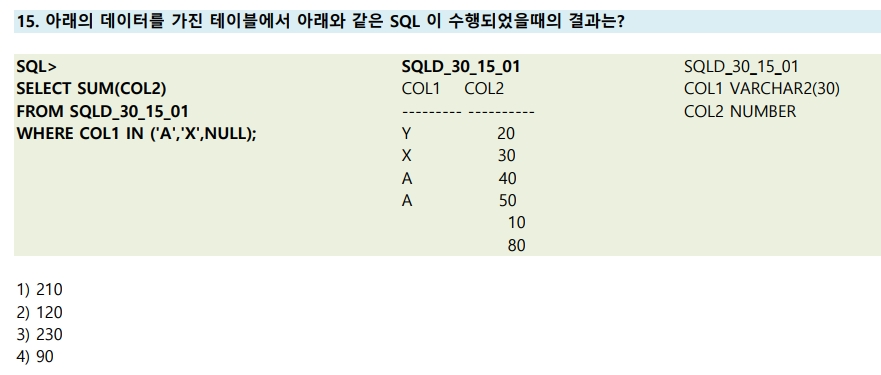
SELECT SUM(COL2) > COL2의 합계
FROM SQLD_30_15_01
WHERE COL1 IN ('A', 'X', NULL); > COL1이 A 이거나, X이거나 NULL인 값
30+40+50 = 120
※ 집계함수는 NULL 값 합산하지 않음
16번

- 계층구조: 선행테이블 > 인덱스 > 조인 (BY INDEX ROWID 가 붙는 경우, 가장 안 쪽부터 읽음)
- 5번이 가장 안 쪽이나, 'TABLE ACCESS (FULL)' 있음
- 3번, 4번 같은 위치이나, 3번이 더 위에 있으므로 3번 먼저 수행
- 3 > 5 > 4
- 7번이 더 안 쪽이나, 2번 아래에 3~5번 계획이 있었던 것. 계획을 수정했으니, 2번 수행 후 마무리
- 3 > 5> 4 > 2 > 7
- 나머지는 가장 안쪽부터 차례로
- 정답은: 3 > 5 > 4 > 2 > 7 > 6 > 1 > 0 (1번)
17번
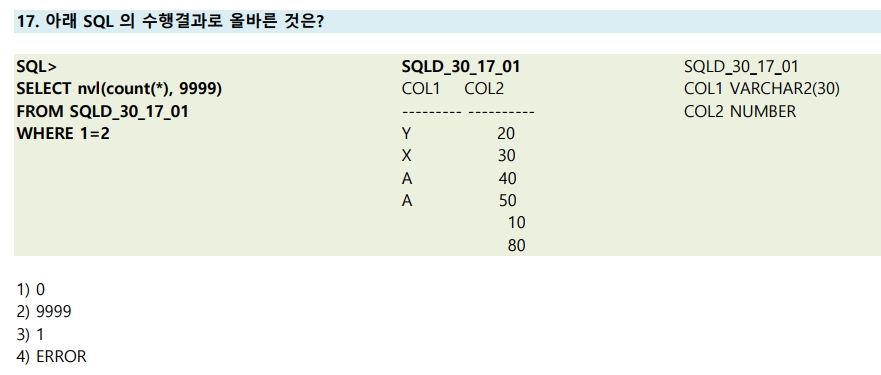
SELECT NVL(COUNT(*), 9999) > COUNT(*) IS NULL 이면 9999, 아니면 COUNT(*) 반환
FROM SQLD_30_17_01
WHERE 1 = 2 > SQL에서 해당 문은 항상 False
해당하는 행이 없으므로 정답은 0
18번
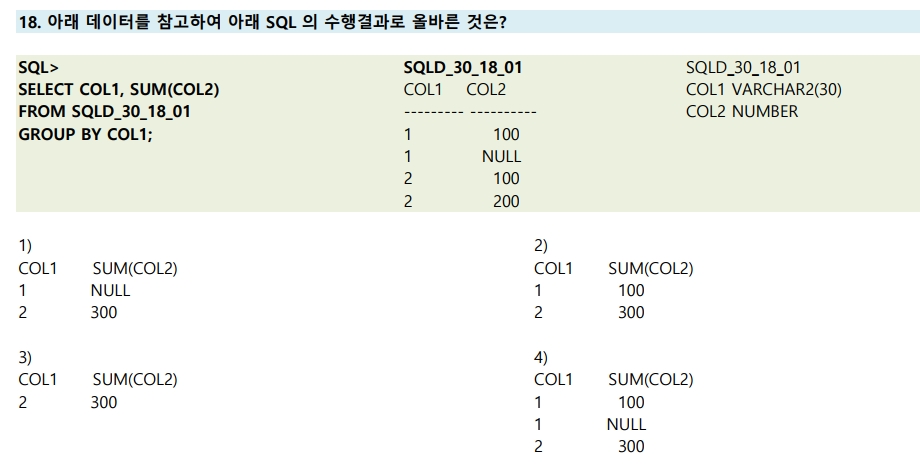
SELECT COL1, SUM(COL2) > 집계함수 SUM은 NULL 값 미포함
FROM SQLD_30_18_01
GROUP BY COL1; > COL1 기준으로 그룹
▼
| COL1 | SUM(COL2) |
| 1 | 100 |
| 2 | 300 |
22번
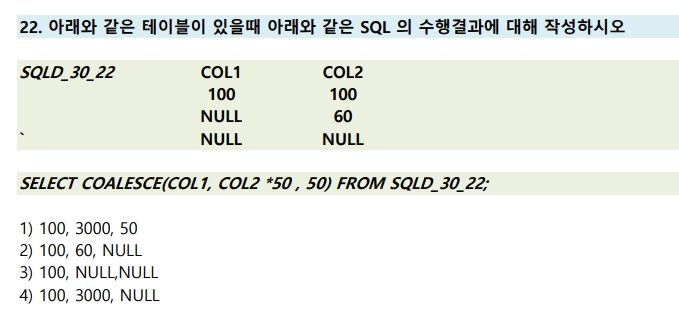
SELECT COALESCE(COL1, COL2 *50, 50) FROM SQLD_30_22;
※ COALESCE 함수는 처음으로 NULL 이 아닌 컬럼 값을 만나면 그 컬럼 값을 리턴
COALESCE(COL1, COL2 *50, 50) > 100, 60*50 = 3000, 50 (NULL NULL 이므로 패스)
정답은 100, 3000, 50
24번

| 명령어 유형 | 명령어 | 기능 |
| DML (데이터 조작어) | SELECT | 조회, 검색 |
| INSERT | 삽입 | |
| UPDATE | 수정 | |
| DELETE | 삭제 | |
| DDL (데이터 정의어) | CREATE | 생성 |
| ALTER | 변경 | |
| RENAME | 이름 재설정 | |
| DROP | 삭제 | |
| DCL (데이터 제어어) | GRANT | 권한 부여 |
| REVOKE | 권한 회수 | |
| TCL (트랜잭션 제어어) | COMMIT | 결과 저장 |
| ROLLBACK | 결과 되돌리기 |
26번

SELECT TOP(10) FIRST_NAME, JOB_ID
FROM HR.EMPLOYEES
ORDER BY SALARY;
※ TOP(N): ORDER BY 가 있을 시, 정렬 후 상위 N개 노출
1) WHERE ROWNUM <= 10 : 위에서 10줄 선택
ORDER BY SALARY; : (선택 후) 정렬
※ 정렬 후 10줄 노출
2) SELECT TOP(10) WITH TIES : 상위 10개 뽑되, 'WITH TIES'로 같은 SALARY 받는 사람 같이 출력.
3) SELECT FIRST_NAME, JOB_ID
FROM (
SELECT FIRST_NAME, JOB_ID, ROWNUM RN
FROM HR.EMPLOYEES
ORDER BY SALARY
)
WHERE RN <= 10;
HR.EMPLOYEES 테이블에서 FIRST_NAME, JOB_ID 선택하고 ROWNUM 먼저 시행
그 후 SALARY로 정렬
서브쿼리 내에서 salary기준으로 정렬되기 전인 상태의 ROWNUM가 RN컬럼이 되어 RN 기준으로 10번째꺼 이하를 출력해도 정렬된 상태가 아님.
4) SELECT FIRST_NAME, JOB_ID
FROM (
SELECT FIRST_NAME, JOB_ID
FROM HR.EMPLOYEES
ORDER BY SALARY
)
WHERE ROWNUM <= 10;
HR.EMPLOYEES 테이블에서 FIRST_NAME, JOB_ID 선택 후 SALARY로 정렬 한 뒤에 상위 10개 노출
※ ROWNUM이 TOP과 같으려면 FROM 절에서 인라인 뷰로 ORDER BY 한 절을 가지고 있어야 함.
30번

1) SELECT A.고객명,
NVL(SUM(C.수량*B.상품가격),0) AS 총주문금액
FROM SQLD_30_30_고객 A
INNER JOIN SQLD_30_30_주문 C ON A.고객ID = C.고객ID
INNER JOIN SQLD_30_30_상품 B ON C.상품ID = B.상품ID
WHERE 1=1
GROUP BY A.고객명
ORDER BY 1,2;
※ 모든 고객의 총 주문금액인데 INNER JOIN을 하면 서로 겹치는 것만 선택 됨.
32번
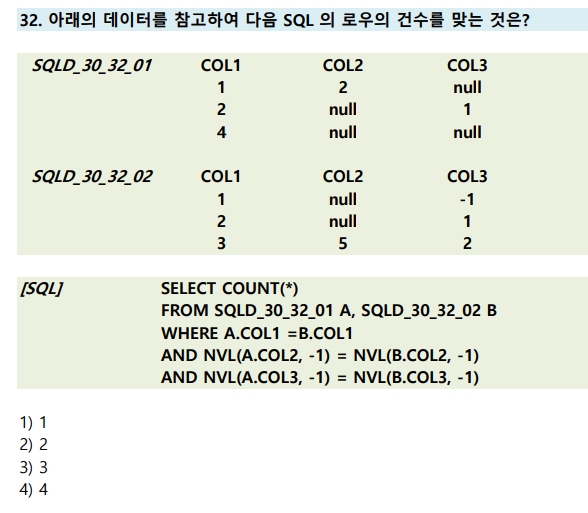
※ NVL: NULL 값일 경우, 지정된 값 대신에 해당 표현식 자체 반환
(조건1) A.COL1 = B.COL1 :1,2 번행 만족
(조건2) AND NVL(A.COL2, -1) = NVL(B.COL2, -1) : A.COL2이 NULL 값이면 -1 / B.COL2이 NULL 값이면 -1 반환
▶ A.COL2 과 B.COL2 의 값은 같아야 한다 (NVL 함수 무시해도 무방하다고 보여짐.)
▶ 2번 행만 만족
(조건3) AND NVL(A.COL3, -1) = NLV(B.COL3, -1) : A.COL3이 NULL 값이면 -1 / B.COL3이 NULL 값이면 -1 반환
▶ A.COL3 과 B.COL3 의 값은 같아야 한다.
▶ 2번, 3번 행 만족
조건절에 AND가 들어가기 때문에, 조건1/조건2/조건3을 모두 만족해야 함.
▶ (1), (2), (3) 모두 만족하는 행, 수 : 2번 행(1개)
34번

1) 고객
| 고객ID | 고객명 |
| COO1 | AAA |
2) 주문
| 주문ID | 고객ID | 상품 |
| O001 | C001 | XXX |
3) 주문 (2번 테이블에서 주문ID가 'O001'인 행의 고객ID를 NULL 값으로 변경)
| 주문ID | 고객ID | 상품 |
| O001 | NULL | XXX |
4) 부모 테이블에 없는 데이터 'C002'가 자식 테이블에 있어 오류 (고객ID가 주문 테이블에만 있을 수 없음)
35번

NATURAL JOIN: 특정 JOIN 컬럼 명시적으로 적을 수 없음. (JOIN 키는 컬럼명으로 결정됨.)
▶ 2번, 4번 맞음
CROSS JOIN 특징: JOIN에 참여하는 테이블의 JOIN KEY가 없는 경우 발생
▶ 3번 맞음
CROSS JOIN과 NATURAL JOIN은 WHERE 절에서 조건을 걸 수 없다. (차이점이 아님)
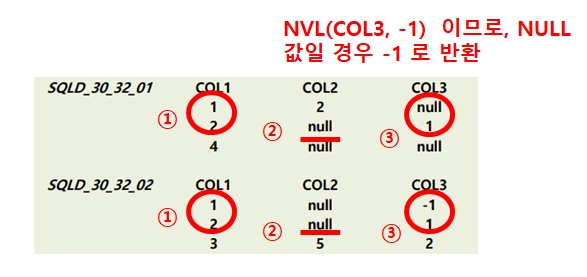
40번
AVG: 평균
NVL(COL2, 0): COL2의 NULL 값은 0으로 표기
AVG(10, 20, 0) = (10+20+0)/3 = 10
43번

3.8 / 3 / 3 /4
ABS: 절대값
FLOOR: 정수로 내림 ↔ CEIL
TRUNC: 소수점 내림
ROUND: 반올림
45번

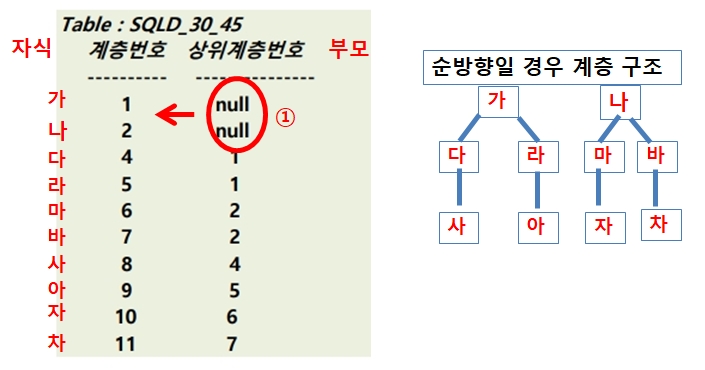
① START WITH 상위계층번호 IS NULL : 상위계층번호 컬럼의 NULL 값부터 시작
② CONNECT BY 계층번호 = PRIOR 상위계층번호
CONNECT BY 자식 = PRIOR 부모 ▶ 역방향
따라서, 역방향일 경우 '가'와 '나'를 자식노드로 둔 부모노드가 없기 때문에
답은 2건
전체 문제 풀어보기
출처: 데이터 포럼 네이버 카페
'자격증 > SQLD' 카테고리의 다른 글
| [SQLD] 자주 틀렸던 부분 (2) | 2024.03.08 |
|---|---|
| [SQLD] 34회 기출문제 오답노트 (0) | 2024.03.02 |
| [SQLD] PIVOT / UNPIVOT (보강-2) (0) | 2024.03.01 |
| [SQLD] PIVOT/UNPIVOT (보강-1) (0) | 2024.03.01 |
| [SQLD] TOP N Query (보강) (3) | 2024.03.01 |


