이전 내용
[빅분기 실기] 빅분기 실기 접수
이전 내용 [빅분기 필기] 응시자격 심사 서류 제출이전 내용 [빅분기 필기] 2차 도전! (요약 자료 다운로드)이전 내용 [빅분기 필기] (분노와 슬픔의) 시험 후기시험결과 24년 4월 19일 사전 점수 발
puppy-foot-it.tistory.com
작업형1 유형
작업형1은 3문항이 나오며, 각 문항 당 10점 총, 30점 만점으로, 주어진 데이터를 정체, 변환, 연산하고 요구하는 조건에 맞는 값을 제출하면 된다.
★ Tip
시험 중에 함수나 철자가 기억나지 않거나 사용법이 생각나지 않으면 dir()이나 help() 함수를 활용하면 된다.
ex)
dir(pd): 판다스 함수의 풀네임 확인
help(pd.함수명): 함수 사용 방법 및 예시
파이썬 기초 부분은 어느정도 배웠다는 전제 하에, 시험에 도움될 만한 유용한 판다스 문법을 정리해보고자 한다.
파이썬을 기초부터 공부하고 싶다면, 아래 링크 확인
'[파이썬 Projects]/<파이썬 기초>' 카테고리의 글 목록
스스로 성장하기 위해, 성장을 통해 얻게 된 꿀팁들을 나누기 위해 열심히 살아가(고자하)는 기록자
puppy-foot-it.tistory.com
데이터프레임 기초
※ DataFrame은 보통 df 라는 변수명으로 저장하므로, df로 줄여서 표현
import pandas ad pd
df = pd.DataFrame({...
- 데이터 프레임 크기
df.shape
- 컬럼별 자료형
df.info()
- 상관 관계
df.corr(numeric_only=True) # 숫자형 데이터에만 적용
- 고유한 값의 개수
df.nunique() # 컬럼별로 고유한 값의 개수 출력
df.unique() # 구체적인 항목 출력
df.value_counts() # nunique + unique
- 기술통계
df.describe()
- 자료형 변환
astype('변경할 자료형')
# '높이' 컬럼을 정수형으로 변경
df['높이'].astype('int')
# '길이' 컬럼을 실수형으로 변경
df['길이'].astype('float')
- 새로운 컬럼 추가
df['새컬럼명'] = 조건
# 'BMI' 칼럼 추가하기 (기존 컬럼 사용)
df['BMI'] = df['몸무게'] / (df['키'] ** 2)
- 데이터 삭제
drop('컬럼명', axis=1) # 1: 열
drop('인덱스', axis=0) # 0: 행
# inplace=True: 결괏값 저장
drop('컬럼명', axis=1, inplace=True)
drop('인덱스', axis=0, inplace=True)
- 인덱싱
# loc
df.loc['인덱스명(문자)']
df.loc[인덱스(숫자)]
# 특정 행과 특정 열의 교차지점
df.loc[인덱스, 컬럼명]
df.loc[2, '키']
# iloc: 숫자만 가능
df.iloc[인덱스(숫자)]
# 특정 교차점
df.iloc[행번호, 열번호]
- 슬라이싱
df.loc[행 범위 또는 특정 행, 컬럼 범위 또는 특정 컬럼]
# 범위
시작 인덱스: 끝 인덱스
: 끝 인덱스 -> 시작 인덱스는 처음부터
시작 인덱스: -> 시작 인덱스부터 끝까지
: -> 전체 범위
df.loc[:, '몸무게'] # 몸무게 컬럼의 전체 행
df.loc[:, '나이':'몸무게'] # 나이부터 몸무게 컬럼의 전체 행
df.loc[:, ['나이', '몸무게']] # 나이와 몸무게 컬럼의 전체 행
df.loc[2:4, ['나이', '몸무게']] # 나이와 몸무게 칼럼의 2번부터 4번 행
# iloc는 숫자로만 지정 가능
df.iloc[2, [1,3]] # 1번 3번 컬럼의 2번행
df.iloc[2, 1:3]] # 1,2번 컬럼의 2번행
[loc 와 iloc]
| 방식 | 범위 | 예시 |
| loc[인덱스명, 컬럼명] | 끝 인덱스 포함 | [0:3] > 0, 1, 2, 3 으로 3포함 |
| iloc[인덱스번호, 컬럼번호] | 끝 인덱스 미포함 (끝 인덱스 -1) | [0:3] > 0, 1, 2로 3미포함 |
- loc 활용 값 변경
# loc[인덱스(범위), 컬럼(범위)]
df.loc[0, '브랜드'] = '현대' # 0번 행의 브랜드 칼럼 값을 현대로 변경
df.loc[1:4, '국가'] = '이탈리아' # 1번~4번 행의 국가 칼럼 값을 이탈리아로 변경
- loc 활용 값 추가
#df.loc[새 인덱스명] = [값]
df.loc[10] = ['k5', 3500, 2023, '기아'] # 가장 마지막 행에 10번이라는 이름의 행 추가하며, 각 값을 추가
# 행 이름은 문자도 가능
df.loc['김철수'] = ['k5', 3500, 2023, '기아'] # 김철수 라는 이름의 행 추가
# 딕셔너리 형태로도 추가 가능
df.loc['김철수'] = {
'제품명': 'k5',
'가격(만원)': 3500,
'연식': 2023,
'브랜드': '기아'
}
- 정렬
- 정렬은 인덱스 기준(sort_index)과 데이터 값 기준(sort_values)이 있다.
- 오름차순(ascending=True), 내림차순(ascending=False) 으로 정렬 순서를 정할 수 있으며, 생략 시 기본값은 오름차순
import pandas as pd
import numpy as np
df = pd.DataFrame({
"제품명": ['아반떼', '소나타', '클레오스', '말리부', '토레스', '팰리세이드'],
"가격(만원)": [3000, 3500, 4000, 3800, 3200, 6000],
"연식": [2024, 2023, np.nan, 2020, np.nan, np.nan],
"브랜드": ['현대', '현대', '르노', '쉐보레', 'KGM', np.nan],
})
df = df.sort_values(by='가격(만원)', ascending=True)
df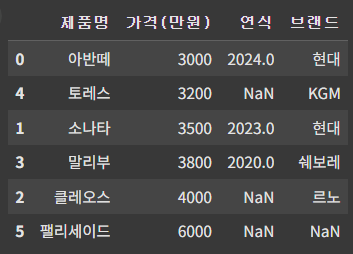
▶ '가격(만원)' 기준 오름차순
pd.DataFrame({딕셔너리}) :데이터프레임 만들기 {키(컬럼): 값(값)}
np.nan: 결측치
by='컬럼명': 정렬 기준
ascending=True: 오름차순 정렬
★ 2개 이상의 컬럼, 컬럼마다 다른 정렬 기준
import pandas as pd
import numpy as np
df = pd.DataFrame({
"제품명": ['아반떼', '소나타', '클레오스', '말리부', '토레스', '팰리세이드'],
"가격(만원)": [3000, 3500, 4000, 3800, 3200, 6000],
"연식": [2024, 2023, np.nan, 2020, np.nan, np.nan],
"브랜드": ['현대', '현대', '르노', '쉐보레', 'KGM', np.nan],
})
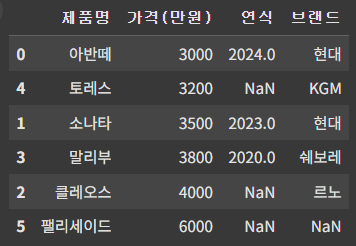
df = df.sort_values(['가격(만원)', '연식'], ascending=[True, False])
df▶ '가격(만원)'과 '연식' 기준으로, 가격(만원)은 오름차순, 연식은 내림차순으로 정렬
※ 먼저 작성된 컬럼이 우선순위가 높음.
- 인덱스 초기화
sort_values()로 정렬된 상태에서 reset_index()를 사용하면 인덱스가 0부터 새로 만들어진다.
기존 인덱스는 새로운 컬럼에 저장되므로, 필요 없을 시에는 drop=True 로 설정
df = df.reset_index(drop=True)
df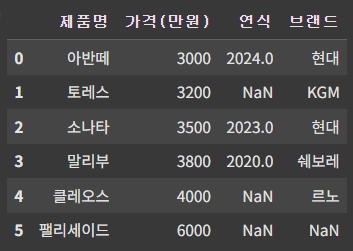
데이터 필터링
- 특정 조건 필터링
특정 칼럼에 조건식 (<, >, ==, != 등)을 적용하면 True/False를 반환하는데 이를 데이터프레임의 대괄호 안에 넣으면 True로 표시된 행들만 선택된다.
[파이썬 조건식]
| 기호 | 의미 | 설명 | 예시 | 결과 |
| < | 작다 (less than) | 왼쪽 값이 오른쪽 값보다 작은지 확인 | 3 < 5 | True |
| > | 크다 (greater than) | 왼쪽 값이 오른쪽 값보다 큰지 확인 | 7 > 10 | False |
| <= | 작거나 같다 (less than or equal) | 왼쪽 값이 오른쪽 값보다 작거나 같은지 확인 | 5 <= 5 | True |
| >= | 크거나 같다 (greater than or equal) | 왼쪽 값이 오른쪽 값보다 크거나 같은지 확인 | 8 >= 2 | True |
| == | 같다 (equal) | 두 값이 같은지 확인 | 4 == 4 | True |
| != | 같지 않다 (not equal) | 두 값이 다른지 확인 | 6 != 9 | True |
※ '=' 이 항상 뒤에 온다는 것을 기억!
cond = df['가격(만원)'] > 3500 # 가격 3500 초과
df_2 = df[cond]
df_2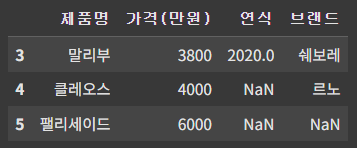
▶ '가격(만원)'이 3500 초과 조건을 cond 라는 변수에 저장한 후, 해당 조건에 맞는 행만 필터링
★ NOT 연산자 (~): 조건의 반대를 필터링하는 데 사용.
cond = df['가격(만원)'] > 3500 # 가격 3500 초과
df_2 = df[~cond] # 3500 미만
df_2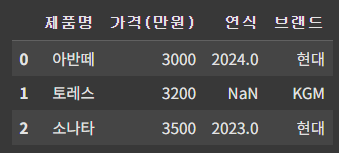
▶ 필터링 기준인 cond 변수 앞에 '~'를 붙여 cond 조건의 반대 (3500 미만)에 부합하는 행만 필터링
★ 복수 조건 필터링 (AND, OR)
| 조건 | 설명 | 기호 |
| AND (교집합) | 두 조건이 모두 참일 때 True, 둘 중 하나라도 거짓이면 False | & |
| OR (합집합) | 두 조건 중 하나라도 참일 때 True | | |
cond1= df['가격(만원)'] >= 3500 # 3500 이상
cond2 = df['연식'] <= 2022
df_4 = df[cond1 & cond2] # 두 가지 조건을 모두 만족
df_4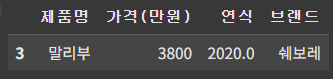
cond1= df['가격(만원)'] >= 3500 # 3500 이상
cond2 = df['연식'] <= 2022
df_5 = df[cond1 | cond2] # 두 조건 중 하나라도 만족
df_5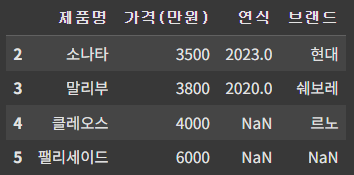
- isin() 사용한 필터링
isin()은 주어진 값이 있는지 확인하는 함수로, 데이터프레임이나 시리즈 값 중에 포함여부를 체크해 포함 시 True, 미포함 시 False를 반환.
df['브랜드'].isin(['현대'])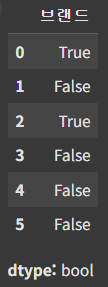
isin()의 결과는 True/False 이므로, 앞서 배운 데이터 필터링을 적용해 True를 반환하는 행만 출력하도록 해본다.
# 브랜드 현대 찾기
cond = df['브랜드'].isin(['현대'])
df_6 = df[cond]
df_6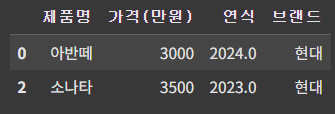
isin()을 사용하면 여러 개의 조건을 한 번에 찾을 수 있다. isin(['조건1', '조건2', '조건3']) 처럼 리스트 형태로 묶어주면 된다.
브랜드가 현대, 쉐보레, 르노 인 행만 출력되도록 해 본다.
# 여러 브랜드 출력하기
cond = df['브랜드'].isin(['현대','쉐보레','르노'])
df_7 = df[cond]
df_7
또는,
# 여러 브랜드 출력하기
cond_list = ['현대','쉐보레','르노']
cond = df['브랜드'].isin(cond_list)
df_7 = df[cond]
df_7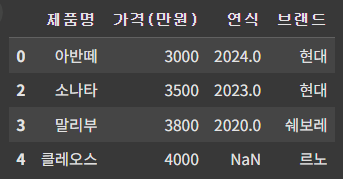
데이터 값 다루기
◆ 결측치 처리
- 결측치 탐색: isnull(), isna()
df.isnull()을 입력하면 null 값은 True, null 값이 아니면 False 반환 ▶ isna()를 사용해도 동일한 결과 얻음
df.isnull()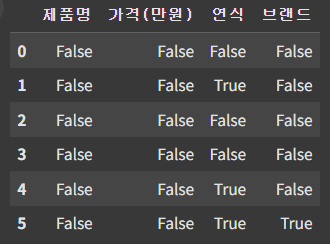
sum()을 붙이면 컬럼별로 모두 더하는데, True는 1, False 는 0이다. ▶ isna()를 사용해도 동일한 결과 얻음
df.isnull().sum()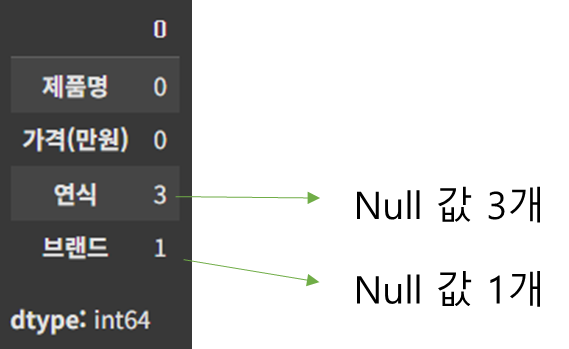
- 결측치 채우기: fillna()
df['컬럼명'].fillna('채울값', inplace=True)▶ 특정 컬럼의 null 값을 특정 값으로 채우고, 결과를 적용한다.
연식의 컬럼을 2022로 채워본다.
df['연식'].fillna(2022, inplace=True)
df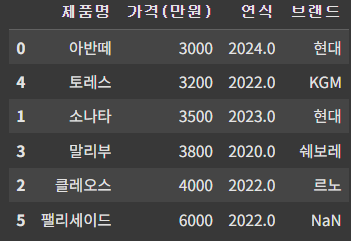
- 특정 값 찾아 변경하기: replace()
replace('변경 전', '변경 후', inplace=True)
아래의 행을 추가했는데
df.loc[6] = ['K5', 3500, 2024, '테슬라']
df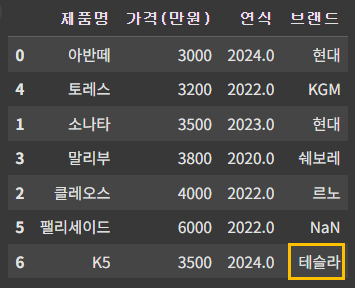
알다시피, K5의 브랜드는 테슬라가 아닌 기아 이므로, 해당 값을 바꿔줘야 한다.
df.replace('테슬라', '기아', inplace=True)
이렇게 할 수 있으나, 만약 테슬라의 값이 여러 개라면?
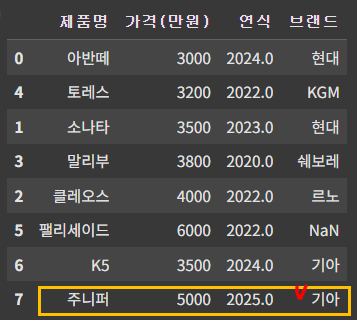
★ loc 활용하기
이렇게 제대로 된 값 마저 변경되어 버리므로, 특정 위치의 값만 변경해 줄 필요가 있다. 이럴때 loc와 같이 사용하면 된다.
# df.loc[인덱스명, '컬럼명'] = 변경할 값
df.loc[6, '브랜드'] = '기아'
df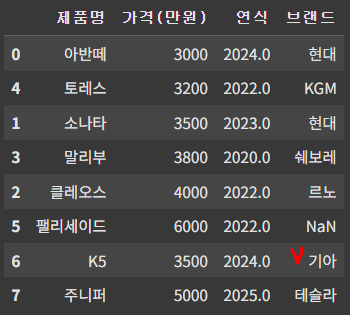
문자열 처리
★ 문자열 값 변경하기
아래와 같이, '제조국' 이라는 새로운 컬럼을 추가하고 값을 입력해 준다.
df['제조국'] = ['corea', 'corea', 'corea', 'USA', 'France', 'corea', 'corea', 'USA']
df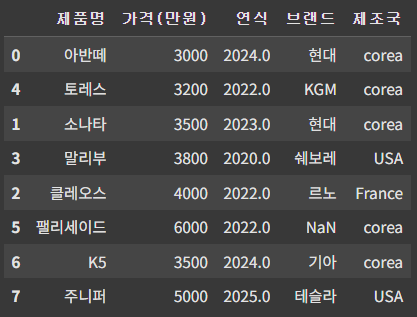
이 중에서 제조국이 corea 로 되어 있는 것을 Korea로 바꾸고 싶을 경우, replace('corea', 'Korea')를 써도 되지만, c만 k로 바꾸는 방법도 사용할 수 있다.
이때 아래와 같이 사용하면 값이 바뀌지 않는다.
df.replace('c', 'k', inplace=True)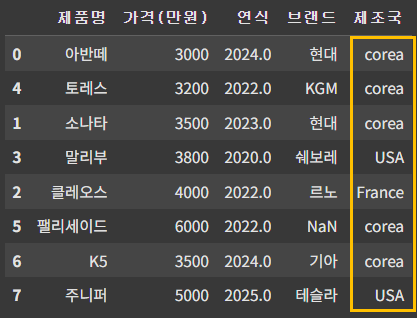
replace는 전체 단어를 다른 단어로 바꿀 수는 있으나, 위 처럼 일부 단어만 변경하는 것은 어렵다.
이렇게 일부 단어만 변경해야 하는 경우에는 str을 사용하는데, str 접근자를 사용하게 되면 데이터프레임에 있는 값을 문자열로 인식한다.
df['제조국'] = df['제조국'].str.replace('c', 'K')
df = df.replace('FranKe', 'France') # France의 데이터도 바뀌므로
df- str.replace 메소드는 '제조국' 열에 대한 특정 변경을 수행하는 동안, 결과를 새로 저장해야 변경 사항이 데이터프레임에 적용.
- df.replace 메소드 또한 결과를 데이터프레임에 다시 할당.
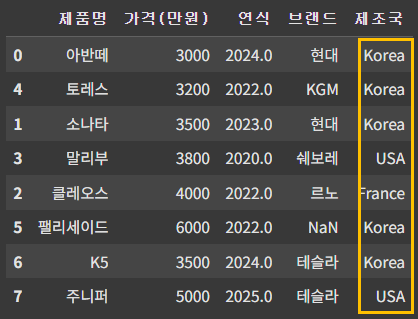
▶ str.replace를 보여주기 위한 예시이므로, 실제로는 replace('corea', 'Korea') 가 더 유용하다.
※ K5를 기아로 바꾼 뒤 inplace=True 적용을 안 해서 계속 테슬라로 나올 예정.
※ str은 데이터가 문자열일 경우에만 사용할 수 있으므로, 정수형이나 실수형 같은 문자열이 아닌 데이터에 사용할 수 없다.
- 문자열 분리: str.split()
괄호 안에 값이 없으면 띄어쓰기를 기준으로 값을 분리한다.
아래와 같이 재고 유무 컬럼을 추가해 본다.
df['재고유무'] = ['재고 없음', '재고 없음', '재고 있음', '재고 있음', '재고 있음', '재고 없음', '재고 없음', '재고 있음']
df
재고 유무 컬럼의 데이터를 띄어쓰기로 분리해 보자.
df['재고유무'].str.split()
분리 후 특정 단어만 선택할 수도 있다.
재고유무에서 '재고' 라는 단어는 공통 단어 이므로, 뒤에 있는 '있음' 또는 '없음'만 선택하여 새로운 컬럼에 넣어본다.
df['재고'] = df['재고유무'].str.split().str[1] # 분리 후 두 번째 단어만 추출
df▶ str[1]은 각 리스트의 두 번째 값을 선택한다.
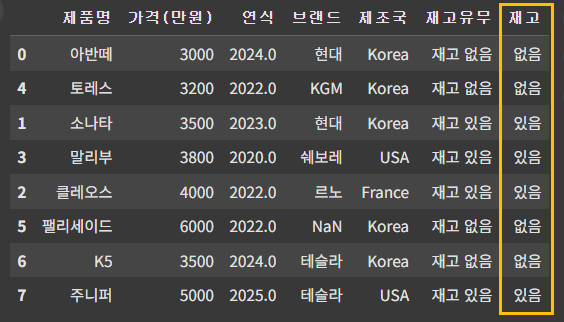
- 특정 문자열 탐색: str.contains('찾을 단어')
예를 들어, 제조국에 'Ko'를 포함하는지 아래와 같이 검색해보면 True/False를 반환한다.
df_8 = df['제조국'].str.contains('Ko')
df_8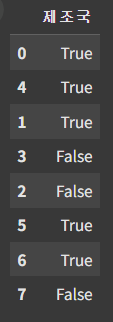
필터링을 하려면 해당 조건을 변수에 추가한 뒤, df[조건 변수명]을 입력해 주면 된다.
cond = df['제조국'].str.contains('Ko')
df[cond]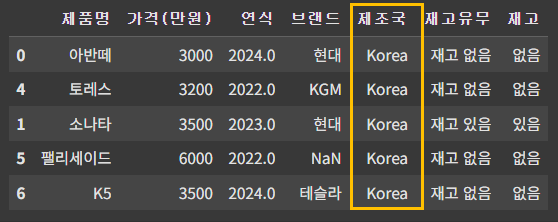
[isin()과 str.contain() 차이]
| 항목 | isin() | str.contains() |
| 목적 | 값의 집합에 포함 여부 확인 | 문자열 내 패턴이나 서브스트링 포함 여부 확인 |
| 사용 예 | 특정 값들 리스트와 비교 | 문자열 내에서 특정 패턴 찾기 |
| 인수 | 리스트 또는 배열 | 찾을 문자열 또는 정규 표현식 |
| 결과 | 불리언 시리즈 반환 | 불리언 시리즈 반환 |
| 적용 대상 | 카테고리형 데이터 | 문자열형 데이터 |
| 특징 | 여러 값에 대한 비교 가능 | 패턴 매칭 및 대소문자 구분 가능 |
isin()
- 주로 값의 집합에 대한 포함 여부를 확인할 때 사용
- 여러 값을 한번에 비교 가능
- 대괄호[] 필요
str.contains()
- 문자열 내에서 서브스트링이나 정규 표현식의 존재를 확인할 때 사용
- 패턴 매칭을 통해 더욱 유연한 검색이 가능
- 대괄포 불필요
▶ 데이터프레임 또는 시리즈에서는 둘 다 모두 사용 가능하다.
- 문자열 길이: str.len()
df['제품명'].str.len()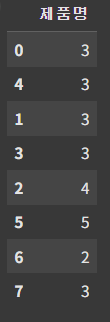
- 대소문자 변경: str.upper() -> 대문자 / str.lower() -> 소문자
df['제조국'] = df['제조국'].str.upper()
df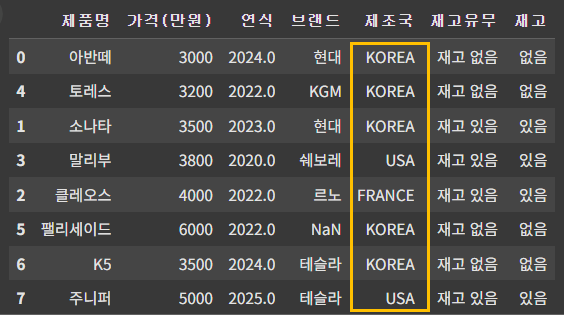
df['제조국'] = df['제조국'].str.lower()
df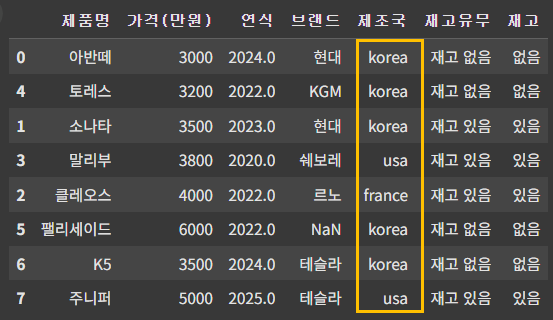
- 공백 제거: str.trim()
- str.trim(): 양쪽 공백 제거
- str.ltrim(): 왼쪽 공백 제거
- str.rtrim(): 오른쪽 공백 제거
내장 함수
- len(): 길이
- 리스트: 데이터의 수
- 데이터프레임: 행의 수
- df.shape[0]: 행의 수
- df.shape[1]: 열의 수
print(f"행의 수: {len(df)}")
print(f"행의 수: {df.shape[0]}")
print(f"열의 수: {df.shape[1]}")
조건에 맞는 개수도 구할 수 있다.
cond = df['가격(만원)'] <= 4000
print(f"가격이 4000만원 이하인 행의 수: {len(df[cond])}")
- sum(): 합계 함수
위처럼 조건에 맞는 개수를 구할 때도 사용할 수 있고,
cond = df['가격(만원)'] <= 4000
print(f"가격이 4000만원 이하인 행의 수: {len(df[cond])}")
print(f"가격이 4000만원 이하인 행의 수: {sum(cond)}")
컬럼별 합계를 구할 수도 있다.
df.sum(numeric_only=True)
※ 연식의 경우 정수형으로 저장되어 있기 때문에 계산된다.
★ 행별 합계 구하기
- 전치: df.T ▶ T는 transpose의 약자로 행과 열을 변경(전치)해준다.
- 축(axis) 변경 ▶ axis를 생략 시 기본값은 0이므로, 이를 1로 변경하면 된다.
▶ drop과는 반대 (drop - 행:0, 축:1) 된다는 것을 숙지
- 기초 통계 함수
- min(): 최솟값
- max(): 최댓값
- mean(): 평균
- median(): 중앙값
- sum(): 합계
- std(): 표준편차
- var(): 분산
▶ 간단하게 앞서 설명한 describe() 함수를 써도 된다.
df.describe()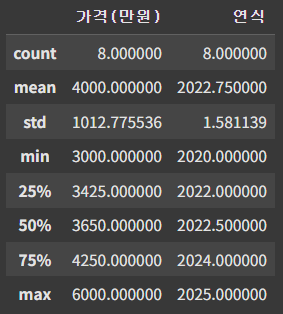
※ 중앙값의 경우 (50%) 와 동일한 값
※ 25%, 50%, 75%의 경우 분위수(quantitle)로 데이터의 하위수를 나타낸다.
print("합계: ",df['가격(만원)'].sum())
print("분산: ",df['가격(만원)'].var())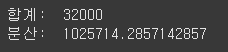
- quantile() 함수에는 특정 값을 넣어 특정 하위수를 구할 수 있다.
print("가격의 하위 10%: ", df['가격(만원)'].quantile(.1))
역시, 해당 값을 조건에 입력하여 데이터프레임 필터링을 할 수 있다.
cond = df['가격(만원)'].quantile(0.25) > df['가격(만원)']
df[cond]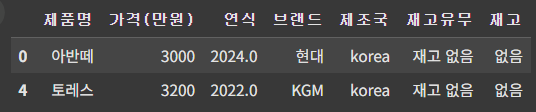
▶ 가격이 1사분위수(25%) 보다 작은 데이터 필터링
- 최빈값: mode()
가장 빈도가 높은 데이터 값을 반환해 준다.
df['제조국'].mode()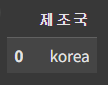
- idxmax(), idxmin(): 데이터프레임 또는 시리즈 열에서 최댓값과 최솟값을 갖는 인덱스를 반환
print(f"idxmin값: {df['가격(만원)'].idxmin()}")
print(f"idxmax값: {df['가격(만원)'].idxmax()}")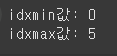
그리고 loc를 활용해 출력된 인덱스의 데이터를 확인할 수 있다.
min_idx = df['가격(만원)'].idxmin()
df.loc[min_idx]
만약 가장 높은 가격의 제품명을 찾는다면, 뒤에 컬럼명을 주면 된다.
max_idx = df['가격(만원)'].idxmax()
df.loc[max_idx]['제품명']
- nlargest(), nsmallest(): 데이터프레임의 특정 컬럼에서 가장 큰 값, 또는 가장 작은 값 반환
(정수, '컬럼명')을 사용하면 특정 컬럼 중에 큰 값 (또는 작은 값) 순으로 정수 개를 반환한다.
# 차 값이 비싼 차 3종
df.nlargest(3, '가격(만원)')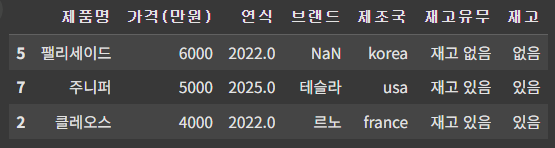
★ apply()
apply() 함수는 Pandas의 DataFrame 및 Series 객체에서 사용되는 매우 유용한 메소드다. 이 함수는 각 행(row)이나 열(column)에 대해 사용자 정의 함수를 적용할 수 있도록 하며, 효율적으로 데이터를 처리할 수 있는 방법을 제공한다.
가격이 4000만원 미만이면서 재고가 있는 차를 구매하려고 한다고 가정하고 가능여부 라는 컬럼을 생성하고 가능여부에 '가능', '불가' 라는 데이터를 추가해본다.
# 가능 여부 추가 - 4000만원 미만이면서 재고가 있는 차
def buycar(row):
if row['가격(만원)'] < 4000 and row['재고'] == '있음':
return "가능"
else:
return "불가"
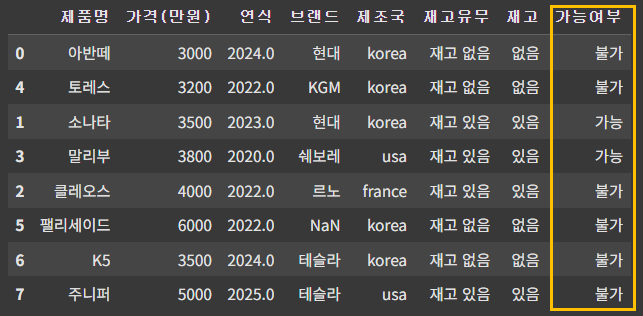
df['가능여부'] = df.apply(buycar, axis=1)
df- 비교 연산자: &는 비트 연산에 사용되며, 조건문에는 적합하지 않기 때문에 논리연산자인 and를 사용한다.
- apply() 함수의 매개변수: apply() 함수의 기본 설정은 데이터프레임의 각 열에 함수를 적용한다. 두 개의 열을 동시에 사용할 경우, axis=1로 설정해야 한다.
- melt(): 데이터프레임 재구조화
melt() 함수는 넓은 형태의 데이터프레임을 긴 형태의 데이터로 변환해 준다.
pd.melt(df)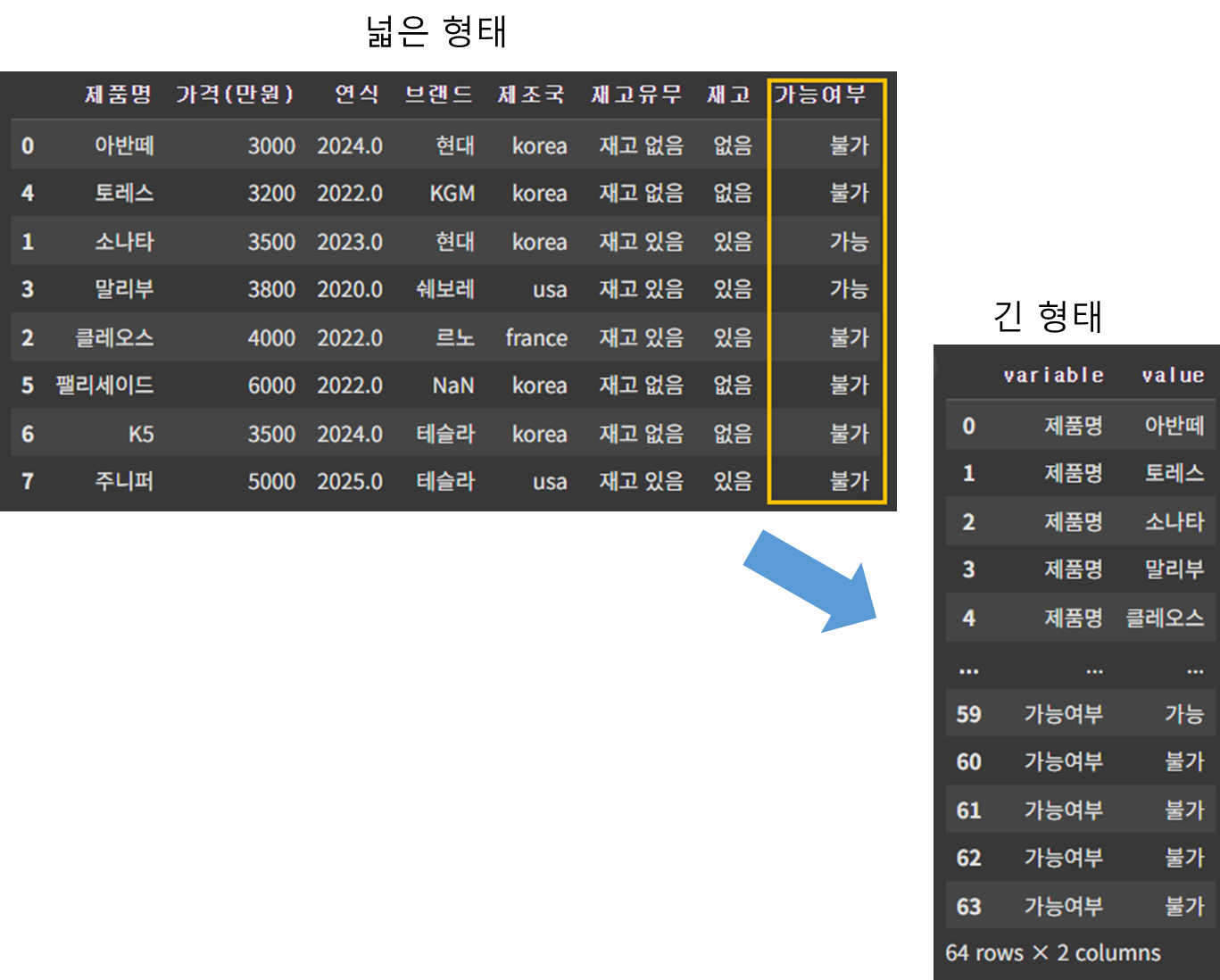
★ id_vars, value_vars에 컬럼을 지정하면 해당 컬럼만 긴 형태로 변형된다.
pd.melt(df, id_vars=['제품명'], value_vars=['브랜드'])
여러 컬럼도 지정가능하다.
pd.melt(df, id_vars=['제품명'], value_vars=['브랜드', '제조국'])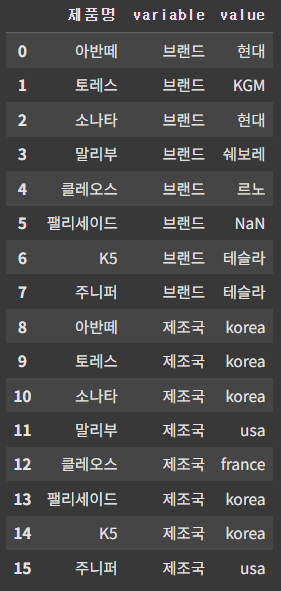
그룹핑
groupby
데이터를 집계하고 분석할 때에는 groupby()를 사용한다.
만약, 브랜드를 기준으로 그룹핑을 하고 평균값을 계산한다고 하면 아래와 같이 입력하면 된다.
df_9 = df.groupby('브랜드').mean(numeric_only=True)
df_9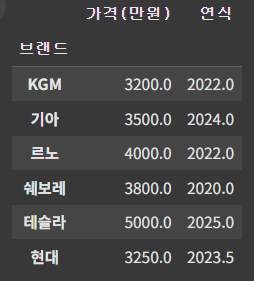
평균이 아닌 다른 값을 구하고 싶을 때에는 앞서 언급한 연산(min, max, count, sum, count 등)을 입력하면 된다.
df_9 = df.groupby('브랜드').size()
df_9size는 결측치를 포함한 빈도를 계산한다.

- 기준 2개 이상
기준이 2개 이상일 경우에는 대괄호를 사용하여 입력하면 된다.
df_10 = df.groupby(['브랜드', '제품명']).sum()
df_10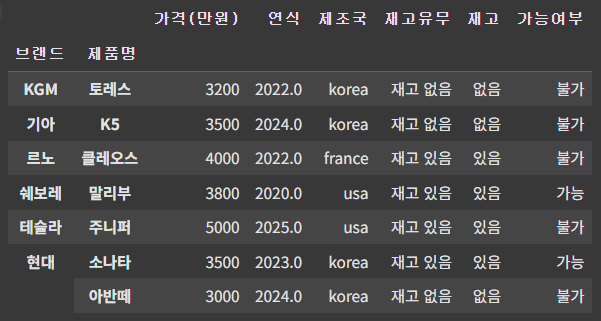
★ agg(): 여러 개의 컬럼에 대해 다양한 집계 연산을 동시에 수행
먼저, agg() 함수를 사용 시 데이터프레임에는 연산이 가능한 숫자형 데이터만 있어야 하므로, 새로운 데이터프레임을 만든다.
# 숫자형 데이터만 연산 가능
df_num = pd.DataFrame({
"제품명": ['아반떼', '소나타', '클레오스', '말리부', '토레스', '팰리세이드', '주니퍼', 'K5'],
"가격(만원)": [3000, 3500, 4000, 3800, 3200, 6000, 5000, 3500],
"연식": [2024, 2023, 2022, 2020, 2022, 2022, 2025, 2024],
"브랜드": ['현대', '현대', '르노', '쉐보레', 'KGM', '현대', '테슬라', '기아'],
})
df_num = df_num.sort_values(['가격(만원)', '연식'], ascending=[True, False])
df_num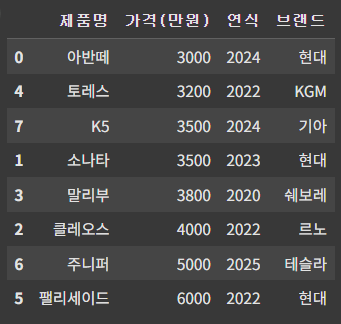
agg() 함수를 사용해 제품과 브랜드 기준으로 평균값과 합계를 구한다.
df_num1 = df_num.groupby(['제품명','브랜드']).agg(['mean', 'sum'])
df_num1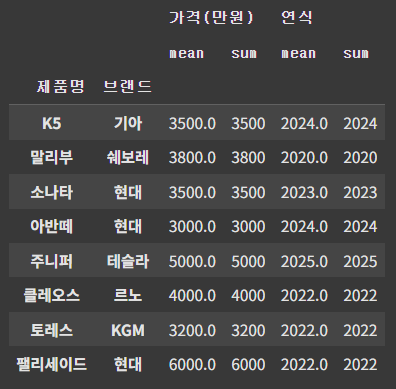
다음 내용
[빅분기 실기] 작업형 1유형 : 판다스 주요 문법 2
이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 1이전 내용 [빅분기 실기] 빅분기 실기 접수이전 내용 [빅분기 필기] 응시자격 심사 서류 제출이전 내용 [빅분기 필기] 2차 도전! (요약
puppy-foot-it.tistory.com
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 3 (0) | 2025.05.20 |
|---|---|
| [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 2 (0) | 2025.05.20 |
| [빅분기 실기] 빅분기 실기 접수 (1) | 2025.05.19 |
| [빅분기 필기] 응시자격 심사 서류 제출 (0) | 2025.04.28 |
| [빅분기 필기] 2차 도전! (요약 자료 다운로드) (3) | 2025.03.10 |



