이전 내용
[빅분기 실기] 작업형 1유형 : 판다스 주요 문법 2
이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 1이전 내용 [빅분기 실기] 빅분기 실기 접수이전 내용 [빅분기 필기] 응시자격 심사 서류 제출이전 내용 [빅분기 필기] 2차 도전! (요약
puppy-foot-it.tistory.com
데이터프레임 병합
데이터프레임을 병합하는 방법
- concat(): 데이터프레임을 연결하여 새로운 데이터프레임을 생성하는데, 데이터프레임을 단순히 결합하고자 할 때 사용.
- merge(): 두 개 이상의 데이터프레임을 공통된 열 또는 인덱스를 기준으로 조인(join).
◆ concat(): 단순 결합
음료와 디저트라는 데이터프레임을 만들고 각 데이터프레임을 출력해본다.
또한, concat을 이용하여 두 데이터프레임을 연결하고 출력해본다.
# concat
import pandas as pd
# 음료 메뉴
drink = pd.DataFrame({
'Menu': ['Americano', 'Latte', 'Milk', 'Tea', 'Juice'],
'Price': [2500, 3000, 3000, 3500, 3500]
})
# 디저트 메뉴
desserts = pd.DataFrame({
'Menu': ['Cheese Cake', 'Cookie', 'Bread'],
'Price': [5000, 3500, 4000]
})
print(drink)
print(desserts)
print()
concat_menu = pd.concat([drink, desserts], ignore_index=True)
print(concat_menu)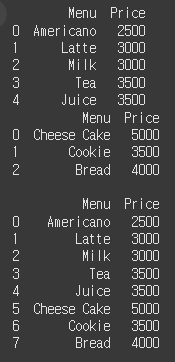
concat() 문법
pd.concat([데이터프레임1, 데이터프레임2, ... 데이터프레임 n], ignore_index=True)※ ignore_index=True는 기존 데이터프레임의 인덱스를 무시하고, 새로 병합된 데이터프레임 기준으로 인덱스를 생성한다.
concat()은 기본적으로 위-아래로 병합하므로, 왼쪽-오른쪽을 병합할 때는 axis=1 값을 부여한다. axis는 축을 의미한다.
concat_menu2 = pd.concat([drink, desserts])
concat_menu2 = concat_menu2.fillna(0) # NaN 값 0으로 채우기
concat_menu2
※ ignore_index=True 를 사용하게 되면 Menu / Price 부분이 0으로 출력되므로 사용 하지 않음.
◆ merge(): 공통된 열 또는 인덱스 기준 결합
아래와 같이 음료 메뉴 데이터프레임과 음료 메뉴의 'HOT/ICE' 여부가 표시된 데이터프레임이 있다.
이때, 이 둘을 병합하려면 둘의 공통된 열인 'Menu'를 기준으로 병합할 수 있는데 이럴 경우 merge()를 사용하고 on='Menu' 옵션을 줘서 메뉴를 기준으로 데이터가 합쳐지게 된다.
# merge
# 음료 메뉴
drink = pd.DataFrame({
'Menu': ['Americano', 'Latte', 'Milk', 'Tea', 'Juice'],
'Price': [2500, 3000, 3000, 3500, 3500]
})
# ICE 여부
hot_or_ice = pd.DataFrame({
'Menu': ['Americano', 'Latte', 'Milk', 'Tea', 'Juice'],
'Hot/Ice': ['Hot/Ice', 'Hot/Ice', 'Hot', 'Hot', 'Ice']
})
merge_menu = pd.merge(drink, hot_or_ice, on='Menu')
merge_menu
피벗테이블
◆ 피벗테이블: 데이터를 원하는 형태로 집계할 때 아주 유용하게 사용할 수 있는 방법으로, 중요한 통계치를 한눈에 볼 수 있어 유용하다. pandas에서는 pivot_table() 함수를 이용해 생성할 수 있다.
피벗테이블의 구성 요소에는
- index(행): 데이터의 그룹 기준이 되는 열. index='기준'
- columns(열): 데이터의 세부 항목을 열로 배치할 때 사용. 기준 인덱스 안에서 세부 항목으로 데이터를 구분하고 싶을 때 columns='세부기준'
- values: 집계할 대상. 숫자데이터
- aggfunc(집계함수): 데이터를 요약하는 방법 (ex. sum-합계, mean-평균, min-최소, max-최대 등)
# df.pivot_table(index='기준', values='집계대상', aggfunc='집계방법')
df.pivot_table(index='Menu', values='price', aggfunc='mean')
- 피벗테이블 기본 형식
아래와 같이 제품, 카테고리, 판매량의 데이터가 있는데, 이 데이터를 활용해 카테고리별 평균 판매량 데이터를 구해본다.
import pandas as pd
# 의류 매장 카테고리별 판매량
data = {
'제품명': ['티셔츠', '블라우스', '치마', '코트', '바지', '벨트', '구두'],
'카테고리': ['상의', '상의', '하의', '아우터', '하의', '액세서리', '신발'],
'판매량': [300, 150, 100, 50, 250, 80, 40]
}
df = pd.DataFrame(data)
print('판매량 데이터')
print(df)
# 피벗테이블: 카테고리별 평균 판매량
pt = df.pivot_table(index='카테고리', values='판매량', aggfunc='mean')
print()
print('카테고리별 평균 판매량 데이터')
print(pt)- index='카테고리': 카테고리별로 그룹핑
- values='판매량': 집계 대상
- aggfunc='mean': 집계 방식은 평균(mean)

- 여러 열로 집계
카테고리와 성별의 판매량 합계를 구해본다.
import pandas as pd
# 의류 매장 카테고리별 판매량
data = {
'성별': ['남성', '여성', '여성', '남성', '남성', '남성', '여성'],
'카테고리': ['상의', '상의', '하의', '아우터', '하의', '액세서리', '신발'],
'판매량': [300, 150, 100, 50, 250, 80, 40]
}
df = pd.DataFrame(data)
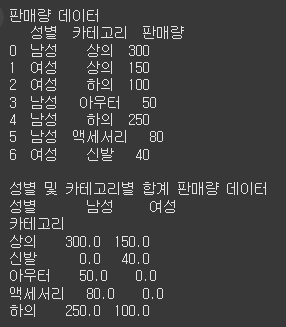
print('판매량 데이터')
print(df)
# 피벗테이블: 성별 & 카테고리별 판매량 합계
pt = df.pivot_table(index='카테고리', columns='성별', values='판매량', aggfunc='sum')
pt = pt.fillna(0)
print()
print('성별 및 카테고리별 합계 판매량 데이터')
print(pt)- index='카테고리': 행이 카테고리를 기준으로 구분
- columns='성별': 열이 성별을 기준으로 구분
- values='판매량': 집계 기준
- aggfunc='sum': 성별 및 카테고리 기준별 판매량 합계 계산
- fillna(0): NaN 값을 0으로 채움 (pivot_table() 함수 내에서 fill_value=0을 줘도 된다)
- index에 여러 기준 주기
아래와 같은 의류매장 데이터가 있다.
import pandas as pd
df = pd.DataFrame({
"구분": ['상의', '상의', '상의', '상의', '하의', '하의', '하의', '하의'],
"성별": ['남성', '남성', '여성', '여성', '여성', '여성', '남성', '여성'],
"사이즈": ['XL', 'L', 'M', 'S', 'S', 'M', 'XL', 'L'],
"판매량": [2, 3, 1, 5, 2, 4, 6, 3],
"재고": [10, 5, 12, 8, 7, 6, 4, 3]
})
df
index에 여러 값을 주고 피벗테이블을 해본다.
pt = df.pivot_table(index=['구분', '성별'],
columns=['사이즈'],
values='판매량',
aggfunc='sum',
fill_value=0)
pt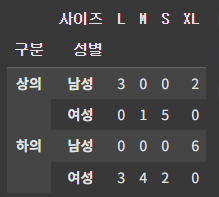
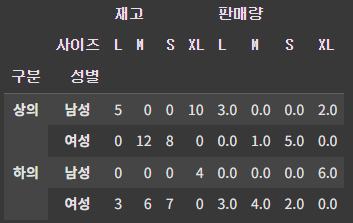
- index에 각기 다른 집계 적용하기
index 뿐 아니라, value에도 여러 값을 줄 수 있으며, aggfunc에도 여러 함수를 적용시킬 수 있다.
pt = df.pivot_table(
index=['구분', '성별'],
columns=['사이즈'],
values=['판매량', '재고'],
aggfunc={'판매량': 'mean', '재고': 'sum'},
fill_value=0)
pt- aggfunc의 경우, 딕셔너리 형태로 지정하면 열마다 다른 함수를 적용한다.
- 하나의 values에 여러 함수 적용하기
pt = df.pivot_table(
index=['구분', '성별'],
columns=['사이즈'],
values=['판매량', '재고'],
aggfunc={'판매량': 'mean', '재고': ['sum', 'mean', 'min', 'max']},
fill_value=0)
pt- aggfunc에 딕셔너리 값에 리스트 형태로 집계 함수를 여러 개 넣어주면 다양한 집계 함수를 사용할 수 있다.

reset_index() 사용 시, 인덱스를 그룹핑이 해제 된 상태로 표시할 수 있다.
pt.reset_index()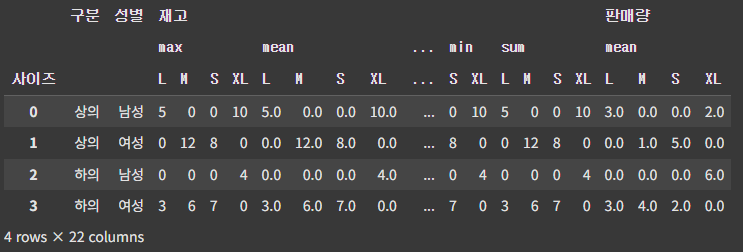
다음 내용
[빅분기 실기] 작업형 2유형 : 머신러닝
이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 3이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 2이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 1이전 내용 [빅분
puppy-foot-it.tistory.com
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅분기 실기] 작업형 2유형 : 이진 분류 실습 (feat. 가짜데이터) (0) | 2025.05.21 |
|---|---|
| [빅분기 실기] 작업형 2유형 : 머신러닝 (0) | 2025.05.21 |
| [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 2 (0) | 2025.05.20 |
| [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 1 (0) | 2025.05.20 |
| [빅분기 실기] 빅분기 실기 접수 (1) | 2025.05.19 |



