이전 내용
[빅분기 실기] 작업형 2유형 : 머신러닝
이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 3이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 2이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 1이전 내용 [빅분
puppy-foot-it.tistory.com
[머신러닝 프로세스]
문제 정의 → 라이브러리/데이터 로드 → EDA → 데이터 전처리 → 데이터 분할 → 머신러닝 학습 및 평가 → 예측 (및 제출)
이진 분류 실습: 1. 가짜 데이터 생성
이진 분류 문제를 실습하는 방법은 아주 많다. 캐글에서 찾거나, 이전에 공부한 머신러닝 데이터셋에서 찾거나, 구글링을 하거나. 하지만 대부분 풀이 방법도 같이 나와있기도 해서 새로운 데이터를 해보는 방법은 없을까 하다가 가짜 데이터셋을 만들어서 하면 좋겠다라는 생각이 들었다.
가짜 데이터셋을 만드는 두 가지 방법
- 사이킷런의 make_classification() 사용
- 판다스를 통해 데이터프레임을 만든 후 복제하여 가공하기
1. 사이킷런의 make_classification()
sklearn의 make_classification() 함수는 머신러닝 연습용으로 아주 적절한 가짜 데이터를 자동으로 만들어 준다.
from sklearn.datasets import make_classification
import pandas as pd
# 데이터 생성
X, y = make_classification(n_samples=1000, # 샘플수
n_features=5, # 총 특성 수
n_informative=3, # 정보가 있는 특성
n_redundant=1, # 중복된 특성
n_classes=2, # 이진 분류
random_state=42)
# 데이터프레임으로 반환
df = pd.DataFrame(X, columns=['feature1', 'feature2', 'feature3', 'feature4', 'feature5'])
df['target'] = y
print(df.head())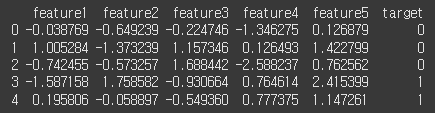
2. 판다스를 통해 데이터프레임을 만든 후 복제하여 가공하기
import numpy as np
# 데이터프레임
df = pd.DataFrame({
'age': [25, 45, 35, 50, 23, 36, 52, 48],
'income': [30000, 80000, 50000, 120000, 25000, 52000, 110000, 105000],
'married': [0, 1, 1, 1, 0, 1, 1, 1],
'buy': [0, 1, 0, 1, 1, 0, 0, 1]
})
# 데이터프레임 복사
clone_df = pd.concat([df] * 200, ignore_index=True)
# 노이즈 추가
np.random.seed(42)
clone_df['age'] = clone_df['age'] + np.random.randint(-3, 4, size=len(clone_df))
clone_df['income'] = clone_df['income'] + np.random.randint(-5000, 5000, size=len(clone_df))
print(clone_df.shape)
print(clone_df.head())데이터프레임을 만들고,
해당 데이터프레임을 200개로 복사한 뒤,
age 컬럼의 숫자를 -3~4 중 임의의 수를 더해주고, income 컬럼의 각 데이터를 -5000 ~ 5000 중 임의의 숫자를 더해준다.

▶ 1600개의 행을 가진 데이터가 생성되었다. (물론, 머신러닝 모델을 학습하기엔 좀 적은 데이터 일수도 있다.)
필자의 생각엔, 첫번째 방법보다 두번째 방법이 보다 현실감있는 수치일 것 같으므로, 2번 방식을 통해 가짜 데이터를 생성하여 이진분류 머신러닝 실습을 진행해 보려 한다.
현재 2번의 방법으로 만들어진 데이터를 간략하게 말하면,
- 정답이 정해져 있는 지도 학습 (target: buy 컬럼)
- buy 컬럼은 나이, 수입, 혼인여부를 통해 구매 여부를 나타낸다.
- 혼인 0: 미혼, 1: 기혼
- 구매 여부 0: 비구매, 1: 구매
해당 데이터를 토대로 구매 예측 모델을 만들어 평가하는 과정을 수행해 본다.
이진 분류 실습: 2. 탐색적 데이터 분석
데이터를 불러오는 과정은 이미 진행하였으니, 탐색적 데이터 분석(EDA)를 진행해 본다.
- 자료형 확인
먼저 df 변수에 clone_df를 대입하고 info()를 통해 자료형을 확인한다.
df = clone_df
df.info()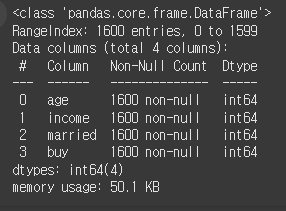
- 기초 통계 확인
describe()을 통해 기초 통계 수치를 확인한다.
df.describe()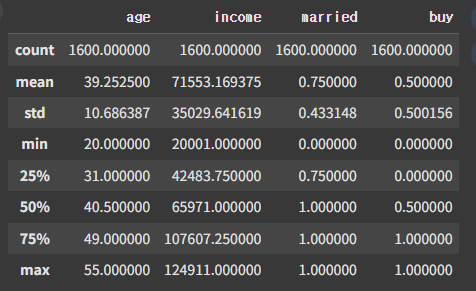
▶ 결측치, 이상치 등을 확인해 볼 수 있다.
※ 이상치의 경우, age가 음수(-) 또는 0 이거나, 소득이 없어야 하는 나이(예. 7) 인데 있거나 하는 방식으로 추측 또는 IQR을 활용하여 계산해 볼 수 있다. income 역시 음수인 경우 이상치로 판단해 볼 수 있다.
- 결측치 확인
info와 shape을 통해 행이 1600 개라는 것을 확인했고, count의 수치도 1600 이니 결측치는 없는 것으로 보인다. 그래도 확인해 본다.
df.isna().sum()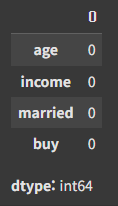
- 카테고리별 개수 확인
우리가 예측해야 할 buy 컬럼의 카테고리별 개수를 확인해 본다.
df['buy'].value_counts()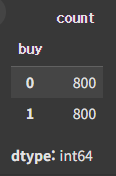
정확히 반으로 갈라져 있는데, 실제 데이터와는 괴리가 있다.
※ value_counts()를 통해 이진 분류인지, 다중 분류인지, 또한 데이터 불균형 여부를 판단할 수 있다.
이진 분류 실습: 3. 데이터 전처리
데이터 전처리의 경우, 무조건 진행해야 하는 것은 아니다.
- 결측치: 결측치 있을 경우 결측치 처리 필수 (dropna, fillna 등)
- 이상치: 선택 사항. 실무에서는 IQR 등을 통해 데이터를 파악하고 처리 (IQR: Q3 - Q1) ▶ Q1 - (IQR * 1.5) 보다 작고, Q3 + (IQR * 1.5) 보다 큰 데이터
- 인코딩: 범주형 데이터가 있을 경우 필수 (LabelEncoder, get_dummies)
- 스케일링: 선택 사항. 실무에서는 특성(Feature)들의 범위(range)를 정규화 해주기 위해 작업. (MinMaxScaler, StandardScaler)
현재 데이터는 결측치와 이상치가 없기 때문에 결측치와 이상치를 처리할 필요는 없어 보인다.
인코딩의 경우, 범주형 데이터 (이를 테면 혼인 칼럼의 데이터가 0, 1 이 아닌 '미혼', '기혼' 등의 데이터)로 되어있다면 컴퓨터가 이를 이해하지 못하므로 숫자로 바꿔주어야 한다.
역시, 데이터 생성 시 이미 0, 1 로 생성하였기 때문에 건너뛴다. (이번에는 전체적인 맥락 파악을 위해 간단히 과정을 짚고 넘어가는 것이지만 실무에서 매우 중요)
스케일링의 경우, 수치형 데이터의 범위를 조정하는 작업으로
- 최소-최대 스케일링 (MinMaxScaler): 데이터를 0~1 사이로 변환. 최솟값은 0이 되고, 최댓값은 1이 되며 나머지 데이터들은 그 범위에 맞게 매핑된다.
- 스탠다드 스케일링(StandardScaler): 데이터를 평균이 0이고 표준편차가 1인 분포로 변환.
- 로버스트 스케일링(RobustScaler): 각 값의 중앙값을 빼고 IQR로 나누는 방법. (이상치의 영향을 덜 받음)
이진 분류 실습: 4. 데이터 분할 (검증 데이터)
모델의 성능을 평가하고 개선하기 위해 데이터 분할을 한다.
▶ 모델이 얼마나 잘 학습했는지, 그리고 새로운 데이터에 얼마나 잘 일반화할 수 있는지를 평가하기 위해 훈련용, 검증용, 테스트용 데이터를 나누어서 사용한다.
[데이터 분할 방법]
하나의 데이터셋으로 훈련 데이터와 테스트 데이터를 나누는 경우도 있고,
미리 테스트 데이터셋을 빼놓고 훈련 데이터를 또 훈련 데이터와 검증 데이터로 나누는 경우가 있다.
| 구분 | 설명 | 분할 예시 |
| 훈련 데이터 (Train Set) | 모델이 학습하는 데 사용 | 60~80% |
| 검증 데이터 (Validation Set) | 하이퍼파라미터 튜닝, 모델 선택에 사용 | 10~20% |
| 테스트 데이터 (Test Set) | 최종 성능 평가용 (모델이 절대 본 적 없어야 함!) | 10~20% |
① 훈련/테스트만 나누는 방식
전체 데이터 → 훈련 데이터 (Train) + 테스트 데이터 (Test)
- 초간단 방식 (소규모 실습용에 적합)
- 성능 평가가 살짝 불안정할 수 있음
② 훈련/검증/테스트로 나누는 방식 (실무에서 많이 사용)
전체 데이터 → 훈련 데이터 → (검증 + 훈련) → 테스트 데이터는 처음부터 따로 떼어놓음
- 하이퍼파라미터 튜닝에 검증 데이터를 사용
- 테스트 데이터는 마지막 성능 평가에만 사용 (모델이 한 번도 본 적 없어야 함!)
실제로 시험에서도 2번의 방식으로 진행하기 때문에, 데이터를 훈련 / 테스트 데이터로 나누고, 훈련 데이터를 다시 훈련 / 검증 데이터로 나눠본다.
데이터 분할을 위해 사이킷런의 model_selection의 train_test_split을 사용한다.
from sklearn.model_selection import train_test_split
# 훈련 / 테스트 나눔
X_trainval, X_test, y_trainval, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 훈련을 훈련/검증으로 나눔
X_train, X_val, y_train, y_val = train_test_split(X_trainval, y_trainval, test_size=0.25, random_state=42)
# 데이터 크기 확인
print(X_train.shape)
print(X_val.shape)
print(X_test.shape)
print(y_train.shape)
print(y_val.shape)
print(y_test.shape)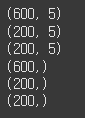
이진 분류 실습: 5. 머신러닝 학습
머신러닝 모델은 랜덤포레스트를 사용하려고 한다.
랜덤포레스트는 여러 개의 의사결정 나무를 기반으로 한 앙상블 학습 알고리즘이며, 랜덤포레스트 분류 모델을 사용하기 위해서는 사이킷런 앙상블(ensemble)의 RandomForestClassifier를 불러와야 한다.
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=42) # 모델 정의
rf.fit(X_train, y_train) # 학습
pred = rf.predict_proba(X_val) # 예측
print(rf.classes_) # 컬럼 순서
pred[:10] # 상위 10개 출력- predict: 예측된 각 레이블(클래스) 반환
- predict_proba: 각 레이블에 속할 확률 반환
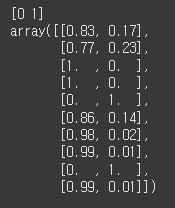
▶ 즉, 0번 인덱스의 데이터는 구매하지 않을 확률: 83%, 구매할 확률: 17% 임을 의미하며, 이 수치는 랜덤포레스트가 예측한 확률이다.
이진 분류 학습: 6. 학습 및 예측 평가하기
이전 내용을 읽었거나, 이 시험을 준비하는 분이라면 모델 (분류, 회귀)에 따라 평가 지표가 다르다고 했던 것을 알 것이다.
분류 모델의 평가지표로는
| 지표 이름 | 설명 | sklearn 함수 | 기준 (좋다고 판단하는 값) |
| 정확도 (Accuracy) | 전체 중 맞춘 비율 | accuracy_score | 0.90 이상이면 좋음 (단, 클래스 불균형 시 신뢰 어려움) |
| 정밀도 (Precision) | 양성 예측 중 진짜 양성의 비율 | precision_score | 0.80 이상이면 좋음 (False Positive 줄이고 싶을 때 중요) |
| 재현율 (Recall, Sensitivity) | 실제 양성 중 모델이 맞춘 비율 | recall_score | 0.80 이상이면 좋음 (False Negative 줄이고 싶을 때 중요) |
| F1 점수 (F1-score) | 정밀도와 재현율의 조화 평균 | f1_score | 0.80 이상이면 좋음 (Precision과 Recall의 균형이 중요할 때) |
| ROC-AUC 점수 | 분류 기준 임계값 전체에 대한 성능 | roc_auc_score | 0.90 이상이면 우수, 0.80 이상이면 양호 |
| 혼동 행렬 (Confusion Matrix) | 예측 vs 실제 결과를 표로 표현 | confusion_matrix | 특정 기준 없음 (False Positive/Negative 수를 보고 판단) |
| 정밀도-재현율 곡선 | 다양한 threshold에서 precision-recall 시각화 | precision_recall_curve | 곡선이 오른쪽 위로 치우칠수록 좋음 |
분류의 성능 지표를 출력해본다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)
pred = rf.predict_proba(X_val)
accuracy = accuracy_score(y_val, pred)
precision = precision_score(y_val, pred)
recall = recall_score(y_val, pred)
f1 = f1_score(y_val, pred)
roc_auc = roc_auc_score(y_val, pred)
metrics_list = [accuracy, precision, recall, f1, roc_auc]
for metric in metrics_list:
print(metric)
그러나, roc_auc_score를 제외한 대부분의 성능 지표의 경우 에러가 발생한다.
ValueError
: Classification metrics can't handle a mix of binary and continuous-multioutput targets
이는, 확률을 반환하는 predict_prboa()를 사용하기 때문인데, pred가 확률 값인 경우 올바른 계산이 이루어지지 않을 수 있어 이진 예측을 기준으로 메트릭을 계산해야 한다. 따라서, predict_proba()가 아닌 이진 값을 반환하는 predict() 를 사용해야 한다.
| 구분 | 평가지표 | 설명 |
| predict_proba() | roc_auc | 각 클래스의 예측 확률 반환 |
| predict() | 정확도, 재현율, F1 score, 정밀도 등 | 예측된 각 클래스 반환 |
※ predict_proba()는 각 클래스의 확률을 예측하므로 2차원 구조의 결과를 반환한다. 따라서, [:, x] 에서 x가 0이면 첫번째 열, 1이면 두번째 열을 불러온다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)
pred = rf.predict(X_val) # 이진 예측 값 반환
accuracy = accuracy_score(y_val, pred)
precision = precision_score(y_val, pred)
recall = recall_score(y_val, pred)
f1 = f1_score(y_val, pred)
roc_auc = roc_auc_score(y_val, rf.predict_proba(X_val)[:, 1]) # Positive class의 확률 반환
metrics_list = [accuracy, precision, recall, f1, roc_auc]
metrics_names = ['정확도', '정밀도', '재현율', 'F1_Score', 'ROC_AUC']
for name, metric in zip(metrics_names, metrics_list):
print(f"{name}: {round(metric, 3)}") # 소수점 3자리 수 반환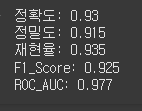
이진 분류 학습: 7. 최종 예측 하기
앞서 검증 데이터(val)를 예측 및 평가했으므로, 이번엔 테스트 데이터를 예측한다. 테스트 데이터를 예측할 때는 X_test로 예측을 하고 평가는 y_test를 이용해서 진행한다.
- X_test: 이 변수는 테스트 데이터의 특성(features)만 포함하고 있다. 즉, 모델이 예측을 수행하는 데 필요한 입력 정보.
- y_test: 이 변수는 테스트 데이터의 실제 레이블(labels) 또는 결과를 포함하고 있다. 이는 모델이 이전에 학습한 데이터를 기반으로 예측한 값과 비교하는 데 사용.
# test 데이터 예측
pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, rf.predict_proba(X_test)[:, 1]) # Positive class의 확률 반환
metrics_list = [accuracy, precision, recall, f1, roc_auc]
metrics_names = ['정확도', '정밀도', '재현율', 'F1_Score', 'ROC_AUC']
for name, metric in zip(metrics_names, metrics_list):
print(f"{name}: {round(metric, 3)}") # 소수점 3자리 수 반환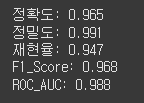
▶ 각 평가 지표의 수치가 1에 가까울 수록 좋은 모델이다.
다음 내용
[빅분기 실기] 작업형 2유형 : 다중 분류 실습
이전 내용 [빅분기 실기] 작업형 2유형 : 이진 분류 실습 (feat. 가짜데이터)이전 내용 [빅분기 실기] 작업형 2유형 : 머신러닝이전 내용 [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 3이전 내용 [
puppy-foot-it.tistory.com
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅분기 실기] 작업형 2유형 : 회귀 실습 (0) | 2025.05.27 |
|---|---|
| [빅분기 실기] 작업형 2유형 : 다중 분류 실습 (1) | 2025.05.26 |
| [빅분기 실기] 작업형 2유형 : 머신러닝 (0) | 2025.05.21 |
| [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 3 (0) | 2025.05.20 |
| [빅분기 실기] 작업형 1유형 : 판다스 주요 문법 2 (0) | 2025.05.20 |



