[목차]
[빅데이터 분석기사] 시험 과목 및 주요 내용 (필기)
빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터 분석 기획 빅데이터의 이해 빅데이터 개요 및 활용 빅데이
puppy-foot-it.tistory.com
빅데이터 모델링 - 분석 기법 적용
<분석 기법 적용>
1. 회귀 분석
(1) 회귀 분석
- 독립변수와 종속변수 간에 선형적인 관계를 도출해서 하나 이상의 독립변수들이 종속변수에 미치는 영향을 분석하고, 독립변수를 통해 종속변수를 에측하는 분석 기법
- 독립변수와 종속변수 간에 인과관계가 있다는 말은 독립변수가 원인이 되어 종속변수에 영향을 미친다는 의미이며, 그런 의미에서 독립변수를 원인변수(혹은 설명 변수), 종속변수를 결과변수 (혹은 반응변수)라고도 함
- 독립변수가 하나이면 단순선형회귀분석, 2개 이상이면 다중선형회귀분석으로 분석
- 변수들 사이의 인과관계를 밝히고 모형 적합하여 관심 있는 변수를 예측 하거나 추론하기 위한 분석 방법
- 회귀분석은 기본적으로 변수가 연속형 변수일 때 사용하며, 범주형 변수일 경우 이를 파생변수로 변환하여 사용
- 만약에 종속변수가 범주형일 경우 로지스틱 회귀분석을 사용.
- 변수들이 일정한 경향성을 띈다는 의미는 그 변수들이 일정한 인과관계를 갖고 있다고 추측할 수 있는데, 산점도를 봤을 대 일정한 추세선이 나타난다면 경향성을 가지거나 혹은 변수들 간에 인과관계가 존재한다고 판단 가능
1) 변수
| 영향을 주는 변수 | 독립 변수, 설명 변수, 예측 변수 |
| 영향을 받는 변수 | 종속 변수, 반응 변수, 결과 변수 |
2) 회귀 모형의 가정
선형성, 독립성, 등분산성, 비상관성, 정상성
| 선형성 | - 독립변수와 종속변수가 선형적이어야 한다는 특성 - 독립변수의 변화에 따라 종속변수도 일정 크기로 변화 |
| 독립성 | - 단순선형 회귀 분석에서는 잔차와 독립변수의 값이 서로 독립적이어야 한다는 특성 - 다중선형 회귀 분석에서는 독립변수 간 상관성이 없이 독립적이어야 함 - 통게량으로는 더빈-왓슨 검정을 통해 확인 가능 * 더빈-왓슨 검정: 회귀 모형 오차항이 자기 상관이 있는지에 대한 검정 |
| 등분산성 | - 잔차의 분산이 독립변수와 무관하게 일정해야 한다는 특성 - 잔차가 고르게 분포되어야 함 |
| 비상관성 | - 관측치와 잔차는 서로 상관이 없어야 한다는 특성 - 잔차끼리 서로 독립이면 비상관성이 있다고 판단 |
| 정상성 (정규성) |
- 잔차항이 정규분포의 형태를 이뤄야 한다는 특성 - Q-Q Plot 에서는 잔차가 대각선 방향의 직선의 형태를 띠면 잔차는 정규분포를 따른다고 할 수 있음 - 통계량으로는 샤피로-윌크 검정, 콜모고로프-스미르노프 검정 등을 통해 확인 가능 * Q-Q Plot: 그래프를 그려서 정규성 가정이 만족되는지 시각적으로 확인하는 방법 * 샤피로-윌크 검정: 오차항이 정규분포를 따르는지 알아보는 검정 * 콜모고로프-스미르노프 검정: 데이터가 어떤 특정한 분포를 따르는가를 비교하는 검정 기법 |
3) 회귀 모형의 체크 리스트
- 회귀 모형이 통계적으로 유의미한가? (F-통계량 통해 확인)
- 회귀계수들이 유의미한가? (t-통계량 통해 확인)
- 회귀 모형이 얼마나 설명력을 갖는가? (결정계수로 판단)
- 회귀 모형이 데이터를 잘 적합하고 있는가? (잔차를 그래프로 그리고 회귀진단)
- 데이터가 가정을 만족시키는가? (회귀 모형 가정을 만족해야 함)
(2) 회귀 분석 유형
단순선형 회귀, 다중선형 회귀, 다항 회귀, 곡선 회귀, 로지스틱 회귀, 비선형 회귀
- 단순선형 회귀: 독립변수가 1개이며, 종속변수와의 관계가 직선
- 다중선형 회귀: 독립변수가 K개이며 종속변수와의 관계가 선형 (1차 함수)
- 다항 회귀: 독립변수와 종속변수와의 관계가 1차 함수 이상인 관계 (독립변수가 1개일 경우에는 2차 함수 이상)
- 곡선 회귀: 독립변수가 1개이며, 종속변수와의 관계가 곡선
- 로지스틱 회귀: 종속변수가 범주형인 경우 적용 (단순 로지스틱 회귀 및 다중, 다항 로지스틱 회귀로 확장 가능)
- 비선형 회귀: 회귀식의 모양이 미지의 모수들의 선형관계로 이뤄져 있지 않은 모형
헷갈리는 '회귀분석(regression)'의 종류에 대해 이해해보자.
회귀분석(regression)의 종류 다음의 링크는 R에서 사용하는 회귀분석을 함수를 나타낸 것이다. 대략 205...
blog.naver.com
[머신러닝] 회귀(Regression)
회귀(Regression) 회귀 분석은 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법이다.회귀는 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기
puppy-foot-it.tistory.com
2. 로지스틱 회귀 분석
(1) 로지스틱 회귀 분석
- 독립변수가 수치형이고 종속변수가 범주형인 경우 적용되는 회귀 분석 모형
- 새로운 설명변수의 값이 주어질 때 반응변수의 각 범주에 속할 확률이 얼마인지를 추정하여 추정 확률을 기준치에 따라 분류하는 목적으로 사용
- 사후 확률: 모형의 적합을 통해 추정된 확률
(2) 원리
- 분석 대상이 되는 이항 변수인 0, 1인 로짓을 이용해서 연속변수인 것처럼 바꿔줌으로써 활용. 하지만 바로 로짓으로 변환하지 못하고 먼저 오즈, 오즈비를 거쳐서 로짓으로 변환해야 함
- 오즈(=승산): 특정 사건이 발생할 확률과 그 사건이 발생하지 않을 확률의 비
- 로짓 변환: 오즈에 로그를 취한 함수
- 시그모이드 함수: S자형 곡선 (시그모이드 곡선)을 갖는 수학 함수
- 로짓 함수에 역함수를 취하면 시그모이드 함수가 됨
[머신러닝] 로지스틱 회귀
이전 내용 [머신러닝] 회귀 - 규제 선형 모델: 릿지, 라쏘, 엘라스틱넷이전 내용 [머신러닝] 회귀 - 다항 회귀와 과대(과소) 적합이전 내용 [머신러닝] 회귀 - LinearRegression 클래스사이킷런 LinearReg
puppy-foot-it.tistory.com
3. 의사결정나무
(1) 개념
- 의사결정 규칙을 나무 구조로 나타내어 전체 자료를 몇 개의 소집단으로 분류하거나 예측하는 분석 방법
- 분석의 대상을 분류함수를 활용하여 의사결정 규칙으로 이루어진 나무 모양으로 그리는 기법
- 연속적으로 발생하는 의사결정 문제를 시각화해서 의사결정이 이루어지는 시점과 성과 파악을 쉽게 해줌
- 계산 결과가 의사결정나무에 직접적으로 나타나기 때문에 기법의 해석 용이
(2) 구성요소
- 부모 마디: 주어진 마디의 상위에 있는 마디
- 자식 마디: 하나의 마디로부터 분리되어 나간 2개 이상의 마디들
- 뿌리 마디: 시작되는 마디로 전체 자료를 포함
- 끝마디: 자식 마디가 없는 마디 (잎 노드)
- 중간 마디: 부모 마디와 자식 마디가 모두 있는 마디
- 깊이: 뿌리 마디부터 끝마디까지의 중간 마디들의 수
(3) 해석력과 예측력
- 은행에서 신용평가에서는 평가 결과 부적격 판정이 나온 경우 대상자에게 부적격 이유를 설명해야 하기 때문에 의사결정나무의 해석력에 집중
- 기대 집단의 사람들 중 가장 크고, 많은 반응을 보일 상품 구매 고객의 모집방안을 예측하고자 하는 경우에는 의사결정나무의 예측력에 집중
(4) 분석
1) 분석 과정
- 설명 변수 선택: 목표변수(종속변수)와 관계 있는 설명 변수(독립변수) 들의 선택
- 의사결정나무 생성: 분석의 목적과 자료구조에 따라서 적절한 분리 기준과 정지 규칙을 정하여 의사결정나무 생성
- 가지치기: 부적절한 나뭇가지는 가지치기로 제거
- 모형 평가: 이익, 위험, 비용 등을 고려하여 모형 평가
- 분류 및 예측: 데이터의 분류 및 예측에 활용
2) 분류나무에서 사용되는 분리 기준
[분리기준]
- 하나의 부모 마디로부터 자식 마디들이 형성될 때, 입력변수의 선택과 범주의 병합이 이루어질 기준
- 순수도(불순도): 목표변수의 분포를 구별하는 정도
- 의사결정나무는 부모 마디의 순수도에 비해서 자식 마디들의 순수도가 증가하도록 자식 마디를 형성해 나감
[이산형 목표변수]
- 카이제곱 통계량의 p-값: p-값이 가장 작은 예측변수와 그 당시의 최적 분리를 통해서 자식 마디 형성
- 지니 지수: 불순도를 측정하는 하나의 지수로서 지니 지수를 가장 감소시켜주는 예측 변수와 그 당시의 최적 분리를 통해서 자식 마디 선택
- 엔트로피 지수: 엔트로피 지수가 가장 작은 예측 변수와 그 당시의 최적 분리를 통해서 자식 마디 형성
[연속형 목표변수]
- 분산 분석에서 F-통계량: p-값이 가장 작은 예측변수와 그 당시의 최적 분리를 통해서 자식 마디 형성
- 분산의 감소량: 예측 오차를 최소화하는 것과 같은 기준으로 분산의 감소량을 최대화하는 기준의 최적 분리를 통해서 자식 마디 형성
3) 정지규칙
- 더 이상 분리가 일어나지 않고 현재의 마디가 끝마디가 되도록 하는 규칙
- 정지기준: 의사결정나무의 깊이를 지정, 끝마디의 레코드 수의 최소 개수 지정
4) 가지치기
- 분류 오류를 크게 할 위험이 높거나 부적절한 추론 규칙을 가지고 있는 가지 또는 불필요한 가지를 제거하는 과정
- 너무 큰 나무 모형은 자료를 과대 적합, 너무 작은 나무 모형은 과소 적합할 위험
(5) 불순도의 여러 가지 척도
- 카이제곱 통계량: 데이터의 분포와 사용자가 선택한 기대 또는 가정된 분포 사이의 차이를 나타내는 측정값
- 지니 지수: 노드의 불순도를 나타내는 값
- 엔트포리 지수: 무질서 정도에 대한 측도 (지수의 값이 클수록 순수도가 낮음)
의사결정나무(Decision Tree) 쉽게 이해하기
의사결정나무(Decision Tree)란 ? 의사결정나무(decision tree) 또는 나무 모형(tree model)은 의사결정 규칙을 나무 구조로 나타내어 전체 자료를 몇 개의 소집단으로 분류(classification) 하거나 예측 (predictio
rk1993.tistory.com
(6) 의사결정나무 알고리즘
- CART: 각 독립변수를 이분화하는 과정을 반복하여 이진트리 형태를 형성함으로써 분류를 수행하는 알고리즘 (가장 널리 사용)
- C4.5 / C5.0: 가지치기를 사용할 때 학습자료를 사용하는 알고리즘 (목표변수가 이산형이어야 함)
- CHAID(다지분할): AID를 발전시킨 알고리즘 (불순도의 척도로 카이제곱 통계량 사용, 다지 분리 사용)
- QUEST: 변수 선택 편향이 거의 없음 (CART의 문제점 개선)
(7) 활용 및 장단점
1) 활용
- 분류: 여러 예측변수들에 근거해서 관측 개체의 목표변수 범주를 몇 개의 등급으로 분류
- 예측: 자료에서 규칙을 찾아내고 이를 이용해서 미래의 사건을 예측
- 차원축소 및 변수선택: 매우 많은 수의 예측변수 중에서 목표변수에 큰 영향을 미치는 변수들을 구분
- 교호작용 효과의 파악: 여러 개의 예측변수들을 결합해서 목표변수에 작용하는 규칙을 파악
2) 장단점
| 장점 | 단점 |
| 해석의 용이성 | 비연속성 |
| 상호작용 효과의 해석 가능 | 선형성 또는 주 효과의 결여 |
| 비모수적 모형 | 비안정성 |
| 유연성과 정확도가 높음 |
[머신러닝] 결정 트리 (+시각화)
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 결정 트리(Decision Tree) ◆ 결
puppy-foot-it.tistory.com
4. 인공신경망 (ANN; Artificial Neural Network)
(1) 개념 및 역사
- 사람 두뇌의 신경세포인 뉴런이 전기신호를 전달하는 모습을 모방한 기계학습 모델
- 입력값을 받아서 출력값을 만들기 위해 활성화 함수 사용
- 목적: 가중치를 알아내는 것
- 1세대: 1943 ~ 1986년 (퍼셉트론 제안 / XOR 선형 분리 불가 문제 발생)
- 2세대: 1986 ~ 2006년 (다층 퍼셉트론과 역전파 알고리즘 등장 / 은닉층을 통해 XOR 문제 해결 / 과적합 문제, 사라지는 경사 현장 문제 발생)
- 3세대: 2006년 ~ 현재 (알파고와 이세돌 바둑 대결로 부각 / 딥러닝 활용 / 과적합 문제 및 기울기 소실 문제 해결)
(2) 구조
1) 퍼셉트론
- 인간의 신경망에 있는 뉴런의 모델을 모방하여 입력층, 출력층으로 구성한 인공신경망 모델
- 구성요소: 입력값, 가중치, 순 입력함수, 활성화 함수, 예측값(출력값)
- 문제점: XOR 선형 분리 할 수 없음 (다층 퍼셉트론으로 해결)
2) 다층 퍼셉트론(MLP; Multi-Layer Perceptrons)
- 입력층과 출력층 사이에 하나 이상의 은닉층을 두어 비선형적으로 분리되는 데이터에 대해 학습이 가능한 퍼셉트론
- 입력층, 은닉층, 출력층으로 구성하고 역전파 알고리즘을 통해 다층으로 만들어진 퍼셉트론의 학습 가능
- 활성화 함수로 시그모이드 함수 사용
- 문제점: 과대 적합, 기울기 소실
(3) 뉴런의 활성화 함수
- 순 입력함수로부터 전달받은 값을 출력값으로 변환해 주는 함수
- 계단함수, 부호함수, 선형함수, 시그모이드 함수, tanh 함수, ReLU 함수 등
활성화 함수(Activation Function)
○ 활성화 함수 활성화 함수는 이전 층(layer)의 결과값을 변환하여 다른 층의 뉴런으로 신호를 전달하는 역할을 한다. 활성화 함수가 필요한 이유는 모델의 복잡도를 올리기 위함인데 앞서 다루
syj9700.tistory.com
(4) 인공신경망의 학습
[DL] 인공 신경망의 학습 과정(Learning Process of ANN)
인공 신경망의 학습 과정(Learning Process of ANN) (인공 신경망을 모르신다면 이 링크 먼저 보시는게 좋아요! 인공 신경망) 인공 신경망은 어떻게 학습할까? 위 이미지(속칭 움짤)는 인공 신경망의 학
seahahn.tistory.com
5. 서포트 벡터 머신(SVM; Support Vector Machine)
- 벡터 공간에서 훈련 데이터가 속한 2개의 그룹을 분류하는 선형 분리자를 찾는 기하학적 모델
- 데이터를 분리하는 초평면 중에서 데이틀과 거리가 가장 먼 초평면을 선택하여 분리하는 지도 학습 기반의 이진 선형 분류 모델
- 최대 마진을 가지는 비확률적 선형 판별 분석에 기초한 이진 분류기
- 공간상에서 최적의 분리 초평면을 찾아서 분류 및 회귀 수행
- 변수 속성 간의 의존성은 고려하지 않으며 모든 속성을 활용하는 기법
- 훈련 시간이 상대적으로 느리지만, 정확성이 뛰어나며 다른 방법보다 과대 적합의 가능성이 낮은 모델
(1) 구성요소
- 결정 경계: 데이터 분류의 기준이 되는 경계
- 초평면: n 차원의 공간의 (n-1) 차원 평면
- 마진: 결정 경계에서 서포트 벡터까지의 거리
- 서포트 벡터: 훈련 데이터 중에서 결정 경계와 가장 가까이에 있는 데이터들의 집합
- 슬랙 변수: 완벽한 분리가 불가능할 때 선형적으로 분류를 위해 허용된 오차를 위한 변수
(2) 종류
- 하드 마진 SVM: 마진의 안쪽이나 바깥쪽에 절대로 잘못 분류된 오 분류를 불허
- 소프트 마진 SVM: 오 분류 허용
(3) 적용 기준
| 선형으로 분리 가능 | 최적의 결정 경계 (또는 초평면)를 기준으로 1과 -1로 구분하여 분류 모형으로 사용 |
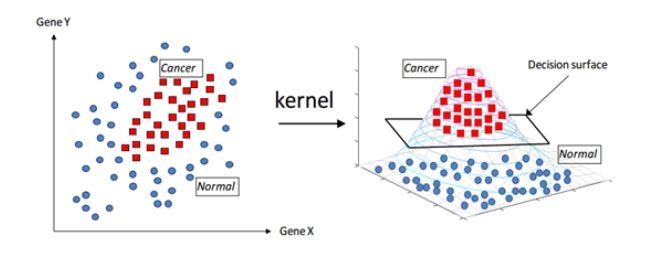
| 선형으로 분리 불가능 | - 저차원 공간을 고차원 공간으로 매핑할 경우에 발생하는 연산의 복잡성은 커널 트릭을 통하여 해결 가능 * 커털 트릭: 저차원에서 함수의 계산만으로 원하는 풀이가 가능한 커널 함수를 이용하여 고차원 공간으로 매핑할 경우에 증가하는 연산량의 문제를 해결하는 기법 |
※ 커널함수: 맵핑 공간에서의 내적과 동등한 함수
- 선형(Linear) 커널: 기본 유형의 커널이며, 1차원이고 다른 함수보다 빠름 (텍스트 분류 문제에 주로 사용)
- 다항(Polynomial) 커널: 선형 커널의 일반화된 공식, 효과성과 정확도 측면에서 효율이 적어 비선호
- RBF (=가우시안 커널): 2차원의 점을 무한한 차원의 점으로 변환 (가장 많이 사용하는 커널, 비선형 데이터가 있는 경우에 일반적으로 활용)
- 시그모이드 커널: 인공신경망에서 선호되는 커널 (다층 퍼셉트론 모델과 유사)
(4) 장단점
| 장점 | 단점 |
| - 데이터가 적을 때 효과적 - 새로운 데이터가 입력되어도 연산량 최소화 - 정확성이 뛰어남 - 커널 트릭을 활용하여 비선형 모델 분류 가능 - 다른 모형보다 과대 적합의 가능성 낮음 - 노이즈의 영향이 적음 |
- 데이터 전처리 과정 중요 - 데이터 세트의 크기가 클 경우 모델링에 많은 시간 소요 - 데이터가 많아질수록 다른 모형에 비해 속도 느림 - 커널과 모델의 매개변수를 조절하기 위해 많은 테스트 필요 |
[머신러닝] 서포트 벡터 머신(SVM)
서포트 벡터 머신(Support Vector Machine, SVM) SVM은 매우 강력할 뿐만 아니라 선형이나 비선형 분류, 회귀, 특이치 탐지에도 사용할 수 있는 다목적 머신러닝 모델이다. SVM은 중소규모의 비선형 데이
puppy-foot-it.tistory.com
6. 연관성 분석 (장바구니 분석, 서열 분석)
(1) 연관성 분석
- 데이터 내부에 존재하는 항목 간의 상호 관계 혹은 종속 관계를 찾아내는 분석 기법
- 데이터 간의 관계에서 조건과 반응을 연결하는 분석
- 목적 변수가 없어 분석 방향이나 목적이 없어도 적용 가능
- 조건 반응(if-then)으로 표현되어 결과를 쉽게 이해
- 매우 간단하게 분석을 위한 계산 가능
- 적절한 세분화로 인한 품목 결정 (너무 세분화된 품목은 의미 없는 결과 도출)
- 교차 판매, 묵음 판매, 상품 진열, 거래 후 쿠폰 제공, 온라인 쇼핑의 상품 추천 등에 활용
- 측징 지표: 지지도, 신뢰도, 향상도
| 지지도 | 전체 거래 중 항목 A와 B를 동시에 포함하는 거래의 비율 |
| 신뢰도 | A 상품을 샀을 때 B 상품을 살 조건부 확률에 대한 척도 |
| 향상도 | 규칙이 우연에 의해 발생한 것인지를 판단하기 위해 연관성의 정도를 측정하는 척도 - 향상도 =1: 서로 독립적 관계 - 향상도 > 1 양(+)의 상관관계 - 향상도 < 1 음(-)의 상관관계 |
(2) 연관성 분석 알고리즘
1) 아프리오리 알고리즘
- 가능한 모든 경우의 수를 탐색하는 방식을 개선하기 위하여 데이터들의 발생빈도가 높은 것(빈발항목)을 찾는 알고리즘
- 분석 대상이 되는 항목의 대상을 최소화하여 연관성 도출을 효율화한 연관분석 알고리즘
- 최소 지지도보다 큰 지지도 값을 갖는 빈발항목 집합에 대해서만 연관규칙을 계산하는 알고리즘
- 연관성 규칙은 항목이 많아질수록 기하급수적으로 늘어나기 때문에 아프리오리 알고리즘을 통해 줄여줄 수 있음
- 한 항목이 자주 발생하지 않는다면 이 항목을 포함하는 집합들도 자주 발생하지 않는다는 규칙을 적용하여 항목 줄여줌
- 최소 지지도 경곗값을 정하고, Database에서 후보항목 집합 생성 > 후보 항목 집합에서 최소 지지도 경곗값을 넘는 빈발항목 집합을 찾아냄
- 규칙1: 한 항목 집합이 빈발하면, 이 항목 집합의 모든 부분집합은 빈발항목 집합
- 규칙2: 한 항목 집합이 빈발하지 않다면, 이 항목 집합을 포함하는 모든 집합은 비 빈발항목 집합
2) FP-Growth 알고리즘
- 아프리오리 알고리즘을 개선한 알고리즘
- FP-Tree 라는 구조를 통해 최소 지지도를 만족하는 빈발 아이템 집합 추출
- 데이터 세트가 큰 경우 모든 후보 아이템 세트들에 대하여 반복적으로 계산하는 단점이 있는 아프리오리 알고리즘 개선
[계산 방법]
- 1단계: 모든 거래를 확인해 각 아이템마다 지지도를 계산하고 최소 지지도 이상의 아이템만 선택
- 2단계: 모든 거래에서 빈도가 높은 아이템 순서대로 순서 정렬
- 3단계: 부모 노드를 중심으로 거래를 자식 노드로 추가해주면서 트리 생성
- 4단계: 새로운 아이템이 나올 경우에는 부모 노드부터 시작하고, 그렇지 않으면 기존의 노드에서 확장
- 5단계: 위의 과정을 모든 거래에 대해 반복하여 FP-Tree 를 만들고 최소 지지도 이상의 패턴만 추출
| 장점 | 단점 |
| - Tree 구조이기 때문에 아프리오리 알고리즘보다 계산 속도가 빠르고 DB에서 스캔하는 횟수도 적음 - 첫 번째 스캔으로 단일 항목집단을 만들고, 두 번째 스캔으로 Tree 구조를 완성하여 분석하는 방식으로 두 번만 스캔하면 되는 간단한 방식 |
- 아프리오리에 비해 설계 어려움 - 지지도 계산은 무조건 FP-Tree 가 만들어져야 가능 |
7. 군집 분석
- 관측된 여러 개의 변숫값들로부터 유사성에만 기초하여 n개의 군집으로 집단화하여 집단의 특성을 분석하는 다변량 분석 기법
- 목적은 레이블이 없는 데이터 세트의 요약 정보를 추출하고, 요약 정보를 통해 전체 데이터 세트가 가지고 있는 특징을 발견하는 것
(1) 가정
- 군집 내에 속한 개체들의 특성은 동질적이고 서로 다른 군집에 속한 개체들 간의 특성은 이질적
- 군집 내의 응집도는 최대화하고 군집 간의 분리도는 최대화
- 군집의 개수 또는 구조와 관계없이 개체 간 거리를 기준으로 분류
- 개별 군집의 특성은 군집에 속한 개체들의 평균값으로 나타냄
(2) 분류와 군집 비교
- 분류: 데이터에 분류 변수가 포함된 지도 학습 방법
- 군집: 데이터에 분류의 기준이 없는 비지도 학습 방법
(3) 유형
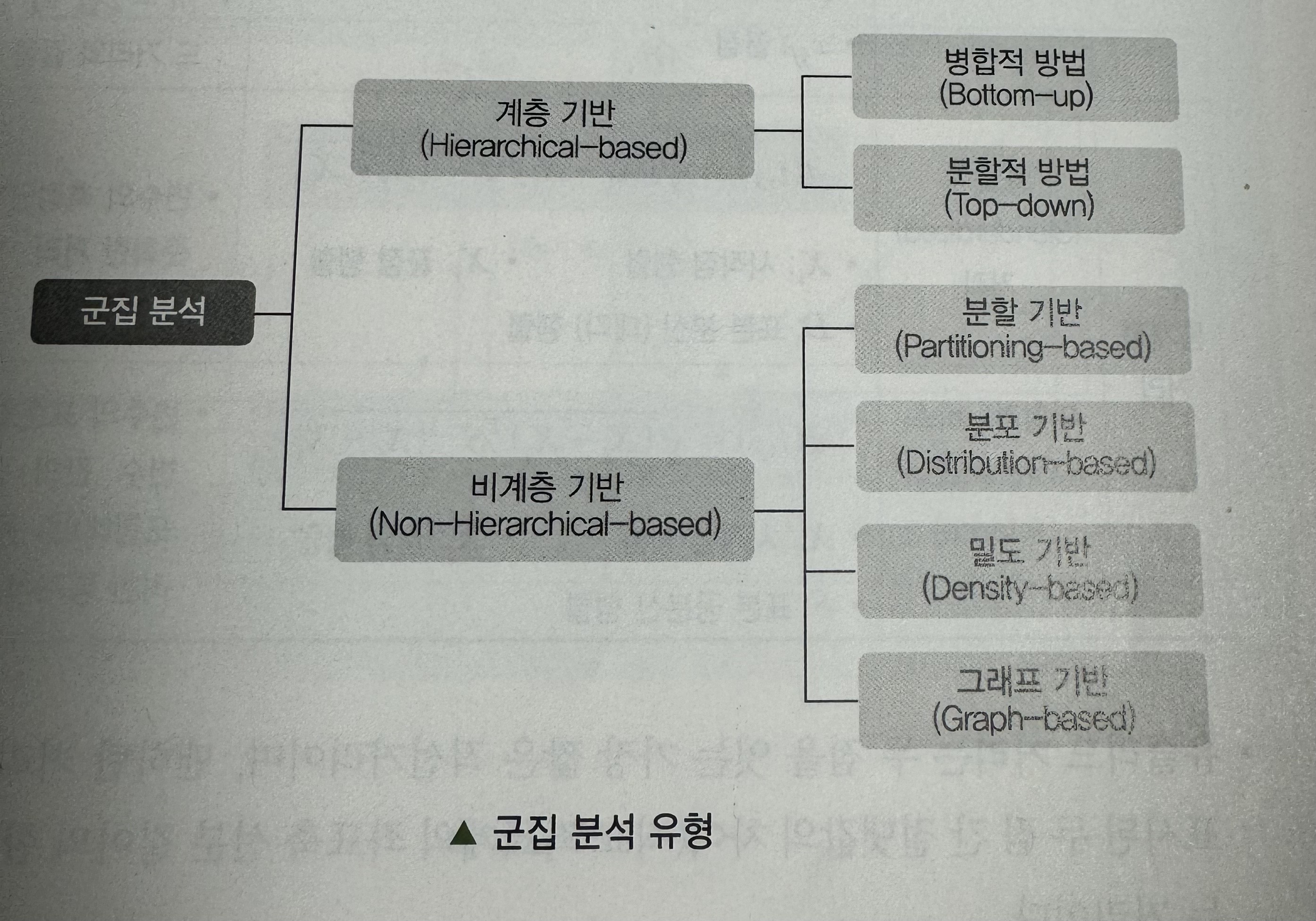
- 계층적 군집: 군집의 개수를 미리 정하지 않고 유사한 개체를 묶어 나가는 과정을 반복하여 원하는 개수의 군집을 형성(계층 기반, 비계층 기반)
- 비계층적 군집: 미리 군집의 개수 지정 (분할 기반, 분포 기반, 밀도 기반, 그래프 기반 등)
(4) 군집 간의 거리 계산
- 거리는 값이 작을수록 관측치가 유사함을 의미
1) 연속형 변수 거리
[수학적 거리]
- 유클리드 거리: 두 점 간 차를 제곱하여 모두 더한 값의 양의 제곱근
- 맨하탄 거리: 두 점 간 차의 절댓값을 합한 값 (시가 거리)
- 민코프스키 거리: m 차원 민코프스키 공간에서의 거리 (m=1 일 때 맨하탄 거리와 같음 / m = 2일 때 유킬드 거리와 같음)
[통계적 거리]
- 표준화 거리: 변수의 측정단위를 표준화한 거리
- 마할라노비스 거리: 변수의 표준화와 함께 변수 간의 상관성을 동시에 고려한 통계적 거리
2) 명목형 변수 거리
- 단순 일치 계수: 전체 속성 중에서 일치하는 속성의 비율
- 자카드 계수: 두 집합 사이의 유사도를 측정하는 방법 (0과 1의 값. 두 집합이 동일하면 1의 값, 공통 원소가 하나도 없으면 0의 값)
- 코사인 유사도: 두 개체 간의 거리 측도 중에서 두 벡터 사이의 각도를 이용하여 개체 간의 유사도를 측정하는 측도 (두 벡터의 내적을 구한 뒤 두 벡터의 크기를 각각 구해서 서로 곱한 것으로 나눔)
3) 순서형 변수 거리 : 순위 상관계수를 이용하여 거리 측정
- 순위 상관계수: 값에 순위를 매겨 그 순위에 대해 상관계수를 구하는 방법
(6) 계층적 군집 분석
- 유사한 개체를 군집화하는 과정을 반복하여 군집을 형성하는 방법
| 병합적 방법 | 작은 군집으로부터 시작하여 군집을 병합하는 방법 (거리가 가까우면 유사성 높음) |
| 분할적 방법 | 큰 군집으로부터 출발하여 군집을 분리해 나가는 방법 |
[계통도]
- 군집의 결과는 계통도 또는 덴드로그램의 형태로 결과가 주어지며 각 개체는 하나의 군집에만 속함
- 항목 간의 거리, 군집 간의 거리를 알 수 있고, 군집 내 항목 간 유사 정도를 파악함으로써 군집의 견고성 해석
[군집 간의 연결법]
- 개체 간의 유사성 (또는 거리)에 대한 다양한 정의 가능
- 최단연결법, 최장연결법, 평균 연결법, 중심연결법, 와드 연결법
- 군집 간의 연결법에 따라 군집의 결과가 달라질 수 있음
군집 분석 Clustering Analytic
군집 분석 Clustering Analytic
velog.io
(7) 비계층적 군집 분석 (분할기반 군집: k-평균 군집 알고리즘)
- 주어진 데이터를 k개의 군집으로 묶는 알고리즘
- k개 만큼 군집수를 초깃값으로 지정하고, 각 개체를 가까운 초깃값에 할당하여 군집을 형성하고 각 군집의 평균을 재계산하여 초깃값을 갱신하는 과정을 반복하여 k개의 최종군집을 형성하는 방법
- 이상값에 민감하게 반응 (k-중앙값 군집을 사용하거나 이상값을 미리 제거 함으로 보완)
※ k-중앙값 군집: 군집을 형성하는 단계마다 평균값 대신 중앙값을 사용하여 군집 형성
[절차]
- k개 객체 선택: 초기 군집 중심으로 k개의 객체를 임의로 선택
- 할당: 자료를 가장 가까운 군집 중심에 할당
- 중심 갱신: 각 군집 내의 자료들이 평균을 계산하여 군집의 중심 갱신
- 반복: 군집 중심의 변화가 거의 없을 때까지 단계 2와 단계 3 반복
[기법]
- 엘보우 기법: x 축에 클러스터의 개수(k값)를 y축에 SSE 값을 두었을 때 기울기가 완만한 부분에 해당하는 클러스터를 선택하는 기법
- 실루엣 기법: 각 군집 간의 거리가 얼마나 분리되어 있는지를 나타내는 기법
- 덴드로그램: 계층적 군집 분석의 덴드로그램 시각화를 이용하여 군집의 개수 결정
(8) 비계층적 군집 분석 (분포 기반 군집: 혼합 분포 군집)
1) 혼합 분포 군집
- 데이터가 k개의 모수적 모형의 가중합으로 표현되는 모집단 모형으로부터 나왔다는 가정하에 자료로부터 모수와 가중치를 추정하는 방법
- k개의 각 모형은 군집을 의미, 각 데이터는 추정된 k개의 모형 중 어느 모형으로부터 나왔을 확률이 높은지에 따라 군집의 분류 이루어짐
- 혼합 모형의 모수를 추정하는 경우 단일 모형과는 달리 표현식이 복잡하여 미분을 통한 이론적 전개가 어렵기 때문에 최대가능도 추정을 위해 EM 알고리즘 등 이용
- 확률 분포를 도입하여 군집 수행
- 군집을 몇 개의 모수로 표현할 수 있고, 서로 다른 크기의 군집 찾을 수 있음
- EM 알고리즘을 이용한 모수 추정에서 데이터가 커지면 수렴에 시간이 걸릴 수 있음
- 군집의 크기가 너무 작으면 추정의 정도가 떨어지거나 어려울 수 있음
- 이상값에 민감하므로 이상값 제거 등의 사전 조치 필요
2) 가우시안 혼합 모델
- 전체 데이터의 확률 분포가 k개의 가우시안 분포의 선형 결합으로 이뤄졌음을 가정하고 각 분포에 속할 확률이 높은 데이터 간의 군집을 형성하는 방법
- 데이터들이 k개의 가우시안 분포 중에서 어디에 속하는 것이 최적인지 추정하기 위해 EM 알고리즘 이용
3) EM 알고리즘
- 관측되지 않은 잠재변수에 의존하는 확률모델에서 최대 가능도나 최대 사후 확률을 갖는 모수의 추정값을 찾는 반복적인 알고리즘
- E-단계, M-단계로 진행
- E-단계: 잠재변수 Z의 기대치 계산
- M-단계: 잠재변수 Z의 기대치를 이용하여 매개변수 추정
- 반복을 수행하며 매개변수 추정값을 도출하며 이를 최대 가능도 추정치로 사용
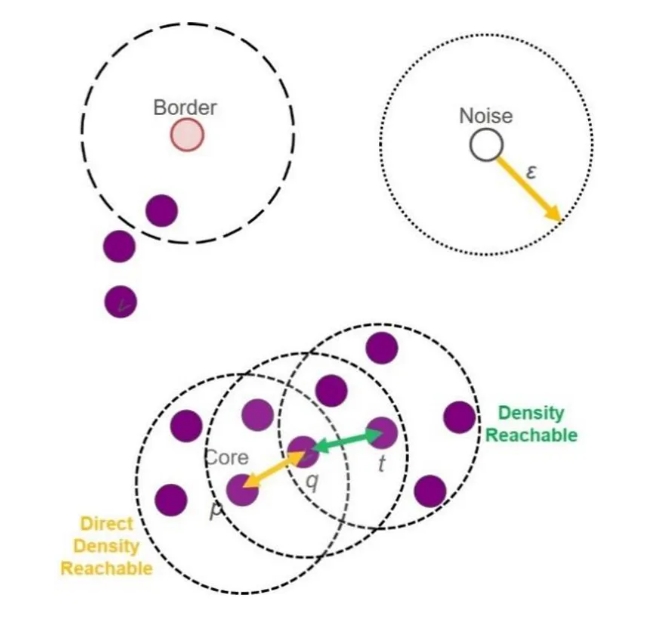
(9) 비계층적 군집 분석(밀도 기반 군집: DBSCAN 알고리즘)
- 개체들의 밀도 계산을 기반으로 밀접하게 분포된 개체들끼리 그룹핑하는 알고리즘
- 클러스터의 개수를 미리 지정할 필요 없음
- 군집 밀도에 따라서 군집을 서로 연결하기 때문에 기하학적인 모양의 군집 분석 가능
- 중심점: 주변 반경 내에 최소 데이터 개수 이상의 다른 데이터를 가지고 있는 데이터
- 이웃점: 특정 데이터 주변 반경 내에 존재하는 다른 데이터
- 경계점: 중심점은 아니지만, 중심점이 주변 반경 내에 존재하는 데이터
- 잡음점: 중심점도 아니고 경계점 조건도 만족하지 못하는 이웃점 (이상치)
[절차]
- 반경 내 최소 점 이상이 포함되도록 중심점 식별
- 모든 비 중심점을 무시하고 인접 그래프에서 중심점과 연결된 구성 요소 탐색
- 중심점 외에 속하면 노이즈로 할당
| 장점 | 단점 |
| - k-평균 군집과 같이 클러스터의 수를 정하지 않아도 됨 - 클러스터의 밀도에 따라서 클러스터를 서로 연결하기 때문에 기하학적인 모양을 갖는 군집도로서 잘 찾을 수 있음 |
- 초매개변수를 결정하기 어려움 - 매개변수의 선택에 민감 - 클러스터들이 다양한 밀도를 가지거나, 차원이 크면 계산에 어려움 |
(10) 비계층적 군집 분석 (그래프 기반 군집: SOM 알고리즘)
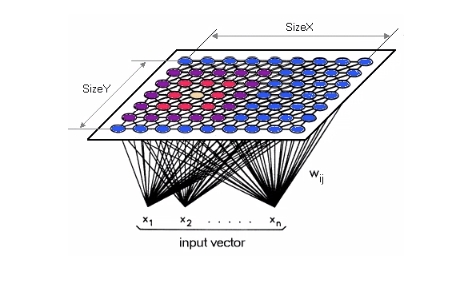
SOM(Self-Organizing Maps, 자기 조직화 지도)
- 대뇌피질과 시각피질의 학습 과정을 기반으로 모델화한 인공신경망
- 자율 학습 방법에 의한 클러스터링 방법을 적용한 알고리즘
- 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 지도의 형태로 형상화한 비지도 신경망
- 형상화는 입력변수의 위치 관계를 그대로 보존
- 실제 공간의 입력변수가 가까이 있으면 지도상에는 가까운 위치에 있게 됨
- 입력층: 입력 벡터를 얻는 층 (입력변수의 개수와 동일하게 뉴런 수 존재)
- 경쟁층: 2차원 격자로 구성된 층 (입력 벡터의 특성에 따라 벡터의 한 점으로 클러스터링 되는 층)
- 단계: 초기화 → 입력 벡터 → 유사도 계산 → 프로토타입 벡터 탐색 → 강도 재조정 → 반복
- 군집 분석은 시장과 고객 차별화, 패턴 인식, 생물 연구, 공간데이터 분석, 웹 문서 분류 등에 활용
- 군집 분석은 세분화, 이상 탐지, 분리 등에 활용
14 장 군집분석 | 데이터과학
\(P\)를 실제로 속한 그룹(클래스)에 따라 데이터를 나눈 파티션이라고 하고, \(Q\)를 클러스터링 알고리즘의 결과 그룹에 의한 파티션이라고 하자. 즉, \(P = \{P_1, P_2, ..., P_S\}\), \(Q = \{Q_1, Q_2, ..., Q_K
bigdata.dongguk.ac.kr
[머신러닝] 군집화 (Clustering)
군집화(Clustering) [군집]군집은 비슷한 샘플을 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업으로, 데이터 분석, 고객 분류, 추천 시스템, 검색 엔진, 이미지 분할, 준지도 학습, 차원 축소
puppy-foot-it.tistory.com
이전글
다음글
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터 분석기사] 4과목 빅데이터 결과 해석(1) (0) | 2024.03.15 |
|---|---|
| [빅데이터 분석기사] 3과목 빅데이터 모델링(3-2-2) (0) | 2024.03.14 |
| [빅분기 기출문제] 오답노트 (0) | 2024.03.14 |
| [빅데이터 분석기사] 3과목 빅데이터 모델링(3-1) (0) | 2024.03.13 |
| [빅데이터 분석기사] 2과목 빅데이터 탐색(2-2-2) (0) | 2024.03.13 |


