해당 내용은 <파이썬으로 데이터 주무르기> 민형기 저, BJPUBLIC 에서 나온 내용을 토대로 작성하였습니다.
Pandas 와 Numpy 모듈 Import 하기
import pandas as pd
import numpy as np두 모듈은 파이썬에서 자주 사용되는 모듈이면서 함께 사용하면 유용
※ 판다스(Pandas)는 파이썬 데이터 처리를 위한 라이브러리입니다. 파이썬을 이용한 데이터 분석과 같은 작업에서 필수 라이브러리로 알려져있다.
※ 넘파이(Numpy)는 수치 데이터를 다루는 파이썬 패키지입니다. Numpy의 핵심이라고 불리는 다차원 행렬 자료구조인 ndarray를 통해 벡터 및 행렬을 사용하는 선형 대수 계산에서 주로 사용된다. Numpy는 편의성뿐만 아니라, 속도면에서도 순수 파이썬에 비해 압도적으로 빠르다는 장점이 있다.
Series: Pandas의 데이터 유형 중 기초
대괄호로 만드는 파이썬의 list 데이터
NaN = Not a Number
s = pd.Series([1,3,5,np.nan,6,8])
s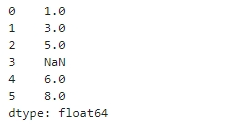
date_range: Pandas의 날짜형 데이터
기본 날짜를 지정하고 periods 옵션으로 특정 일간 지정
dates = pd.date_range('20130101], periods=6)
dates
DataFrame 유형
6행 4열의 random 변수를 만들고, 컬럼에는 columns=['컬럼명1','컬럼명2',...] 지정하고. index 명령으로는 날짜형 데이터 dates를 index=dates 옵션을 이용하여 지정
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=['A', 'B', 'C', 'D'])
df
head()
head() 명령을 사용하면 기본적으로 첫5행을 보여주며, 괄호 안에 숫자를 넣어두면 그 숫자만큼의 행을 볼 수 있음
df.head(3)
index, columns
index, columns 명령을 이용하면 pandas의 DataFrame의 컬럼과 인덱스 확인
df.index
df.columns
values : 내용 확인
values 명령을 사용하면 DataFrame 내에 들어가는 내용 확인 가능
df.values
info : 개요 파악
info() 명령을 통해 DataFrame 개요 파악
df.info()
describe() : 통계적 개요
describe() 명령을 사용하면 통계적 개요 확인 가능.
개수(count), 평균(mean), 최솟값(min), 최댓값(max), 1/4 지점, 표준편차 등 확인 가능
df.describe()
※ Values 가 숫자가 아니라 문자라고 하더라도 그에 맞는 개요가 나타남
sort_values: by로 지정된 컬럼을 기준으로 정렬
※ ascending 옵션 사용 시, 내림차순이나 오름차순으로 정렬 (False : 내림차순 / True = 오름차순)
df.sort_values(by='B', ascending=False)
df
변수명을 적고 실행(shift+Enter) 하면 그 내용이 나타남
df
변수명[컬럼명] 으로 실행하면 해당 컬럼만 Series로 보여줌
df['A']
특정 행들만 보고 싶은 경우에는 변수명[시작행:끝행] 만 입력하면 지정된 범위의 컬럼만 보여줌
df[0:3]
만약, 2013.01.02 부터 2013.01.04 까지의 행을 보고 싶다면
df['20130102':'20130104']
df.loc
앞서 만든 변수(dates)를 사용하여 특정 날짜의 데이터만 보고 싶으면 df.loc 명령을 사용
loc는 location 옵션으로 슬라이싱 할 때 loc 옵션을 이용해서 위치값 지정 가능
df.loc[dates[0]]
A, B열의 모든 행을 보고 싶다면
df.loc[;,['A','B']]
행과 열의 범위를 모두 지정하는 것도 가능
df.loc['20130102':'20130104', ['A','B']]
2013.01.02의 A,B 컬럼 내용만 보고싶을 때
df.loc['20130102', ['A','B']]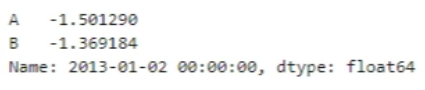
앞서 만든 dates[0]에 맞는 날짜인 2013.01.01 에 A 컬럼의 데이터만 확인하고 싶을 때
df.loc[dates[0], 'A']
iloc
loc 명령과 달리 행과 열의 번호를 이용해서 데이터에 바로 접근할 때 사용
iloc 명령을 사용하면 행이나 열의 범위를 지정하면 됨. 특히 콜론(:) 은 전체를 의미.
iloc[행, 열]
특정 행만 지정
df.iloc[3]
범위 지정 (행, 열)
df.iloc[3:5, 0:2]
범위가 아닌 콤마(,)로 행이나 열 지정하여 데이터 조회 가능
df.iloc[[1,2,4],[0,2]]

행이나 열 중 한 쪽은 전체를 의미하게 하고싶을 때는 콜론(:) 사용
df.iloc[1:3,:]

df.iloc[:,1:3]
특정 조건을 만족하는 데이터 조회
컬럼 A에서 0보다 큰 행 조회
df[df.A > 0]
조건을 만족하지 않은 곳은 NaN 처리 되어 표시
df[df > 0]

copy: DataFrame 복사하기
'=' 기호를 이용해서 복사하면 실제 데이터의 내용이 복사되는 것이 아니라 데이터 위치만 복사되기 때문에 원본 데이터는 하나만 있게 됨.
따라서, 데이터의 내용까지 복사하려면 copy() 옵션을 붙여야 함.
df2 = df.copy()새로운 컬럼 추가 하기
변수명['새로운 컬럼명'] = ['입력값1','입력값2','입력값3',....]
df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
df2
isin: 컬럼에 특정 데이터 있는지 조회
변수명['컬럼명'].isin(['조회하고자 하는 데이터'])
만약, 앞서 새롭게 만든 E컬럼에서 two와 four 가 있는지 보고싶을 때에는
df2['E'].isin(['two', 'four'])

그 결과는 True/False로 반환
df2[df2['E'].isin(['two', 'four'])]

apply: 변수에서 좀 더 통계 느낌의 데이터 볼 때
누적합을 알고 싶을 때는 numpy의 cumsum 사용
df.apply(np.cumsum)
lambda: 차이 혹은 거리 계산
만약 최댓값과 최솟값의 차이 (혹은 거리)를 알고 싶다면 one-line 함수인 lambda 사용
df.apply(lambda x: x.max() - x.min())
Pandas 기초 세부(게시글 링크)
'[파이썬 Projects] > <파이썬 기초>' 카테고리의 다른 글
| [파이썬] 파이썬 시각화 도구 - Matplotlib (0) | 2024.04.13 |
|---|---|
| [파이썬] pandas 고급 기능 : DataFrame 병합하기 (0) | 2024.04.13 |
| [파이썬 실행을 위한 Step] 아나콘다 + Jupyter note book 설치하기 (0) | 2024.04.12 |
| [파이썬 - Jupyter] Jupyter Notebook 'New' 버튼에서 파이썬 안 보일때 (0) | 2024.04.10 |
| 23년 3월 24일 개발일지(... 라 쓰고 받아적기라 읽는다) (0) | 2023.03.24 |



