시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
네이버 도서
책으로 만나는 새로운 세상
search.shopping.naver.com
이전 내용
[파이썬] 판다스 (Pandas) - 4
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 네이버 도서책으로 만나는
puppy-foot-it.tistory.com
결손 데이터 처리하기(feat. isna / fillna)
결손 데이터는 칼럼에 값이 없는 Null을 의미하며, 이를 넘파이의 NaN으로 표시한다.
머신러닝 알고리즘은 이 NaN 값을 처리하지 않고, NaN 값은 평균, 총합 등의 함수 연산 시 제외가 되므로 다른 값으로 대체해야 한다.
예를들어, 100개 데이터 중 10개가 NaN 값일 경우, 이 칼럼의 평균 값은 90개의 데이터에 대한 평균이다.
- isna: NaN 여부를 확인하는 API
- fillna: NaN 값을 다른 값으로 대체하는 API

isna( )로 결손 데이터 여부 확인
DataFrame에 isna( )를 수행하면 모든 칼럼의 값이 NaN 인지 아닌지를 True 또는 False로 알려준다.
결손 데이터의 개수는 isna( ) 결과에 sum( ) 함수를 추가해 구할 수 있다.
sum( )을 호출 시 True는 내부적으로 숫자 1로, False는 숫자 0으로 변환되므로 결손 데이터의 개수를 구할 수 있다.
fillna( )로 결손 데이터 대체하기
fillna( )를 이용하면 결손 데이터를 편리하게 다른 값으로 대체할 수 있다.
★ 타이타닉 데이터 세트의 'Cabin' 칼럼의 NaN 값을 'C000'으로 대체하기
[주의] fillna( )를 이용해 반환 값을 다시 받거나 inplace=True 파라미터를 fillna( )에 추가해야 실제 데이터 세트 값이 변경된다.
앞서 진행한 변환된 결손값을 다시 정해주거나 반환 변숫값을 지정하지 않으려면 inplace=True를 설정해야 한다.
★ 'Age' 칼럼의 NaN 값을 평균 나이로, 'Embarked' 칼럼의 NaN 값을 'S'로 대체해 모든 결손 데이터를 처리
lambda 식
판다스는 apply 함수에 lambda 식을 결합해 DataFrame이나 Seires의 레코드별로 데이터를 가공하는 기능을 제공한다.
lambda 식: 파이썬에서 함수 프로그래밍을 지원하기 위해 만들어졌다. 함수의 선언과 함수 내의 처리를 한 줄의 식으로 쉽게 변환하는 식이다.
이를테면 다음과 같이 입력값의 제곱 값을 구해서 반환하는 get_square(a)라는 함수가 있다고 가정하면,
위의 함수는 함수명과 입력 인자를 먼저 선언하고 이후 함수 내에서 입력 인자를 가공한 뒤 결괎값을 return과 같은 문법으로 반환해야 한다.
이를 lambda 식으로 변환하면,
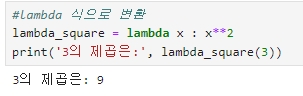
▶ lambda x : x **2 에서 ':' 로 입력 인자와 반환될 입력 인자의 계산식을 분리한다. (: 의 왼쪽에 있는 x는 입력 인자, 오른쪽은 입력 인자의 계산식)
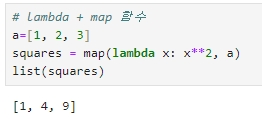
★ 여러 개의 값을 입력 인자로 사용하는 lambda 식의 경우 보통 map( ) 함수를 결합해서 사용한다.
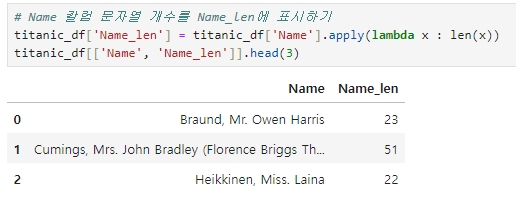
◆ 판다스 DataFrame의 apply에 lambda 식을 적용해 데이터 가공
★ 'Name' 칼럼의 문자열 개수를 별도의 칼럼인 'Name_len'에 생성
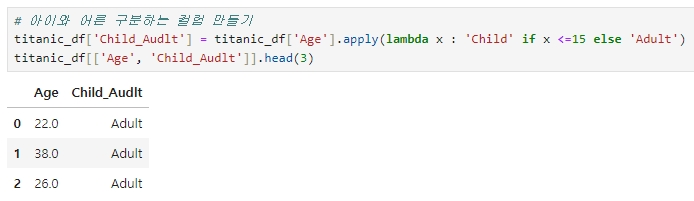
◆ lambda 식에서 if else 절 사용하여 데이터 가공
★ 나이가 15세 미만이면(if) 'Child', 그렇지 않으면(else) 'Adult'로 구분하는 새로운 칼럼 'Child_Adult' 만들기
[주의] lambda 식은 if else를 지원하는데, if 절의 경우 if 식보다 반환 값을 먼저 기술해야 한다.
이는 lambda 식 ':' 기호의 오른편에 반환 값이 있어야 하기 때문이다.
else의 경우는 else 식이 먼저 나오고 반환 값이 나중에 오면 된다.
- lambda x : if x <=15 'Child' else 'Adult' (X)
- lambda x : 'Child' if x <=15 else 'Adult' (O)
[주의] lambda는 if, else만 지원하고 if, else if, else 와 같이 else if는 지원하지 않는다.
else if를 이용하기 위해서는 else 절을 ( )로 내포해 ( ) 내에서 다시 if else로 적용해 사용한다.
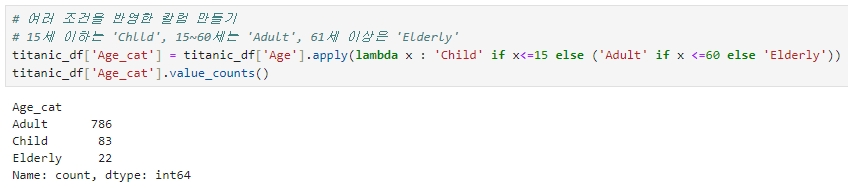
★ 나이가 15세 이하이면 Child, 15~60세는 Adult, 61세 이상은 Elderly로 분류하는 'Age_Cat' 칼럼 만들기
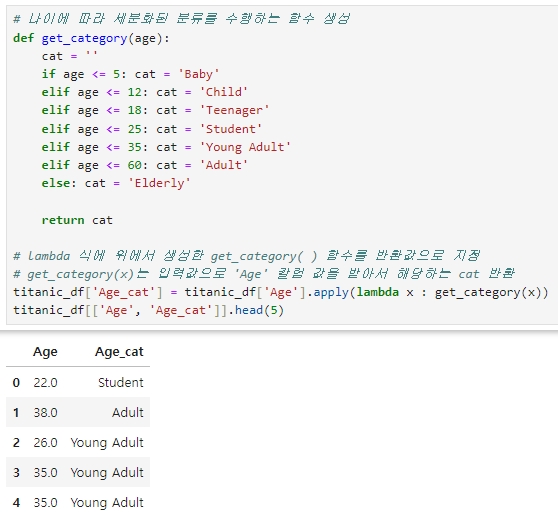
◆ 조건이 더 다양한 경우 (세분화된 분류)
★ 5살 이하는 Baby, 12살 이하는 Child, 18살 이하는 Teenage, 25살 이하는 Student, 35살 이하는 Young Adult, 60세 이하는 Adult, 그리고 그 이상은 Elderly로 분류
apply( ) 함수
pandas의 apply( ) 함수는 DataFrame의 각 행이나 열에 복잡한 연산을 적용할 때 매우 유용하다.
이 함수를 사용하면 사용자 정의 함수를 각 행이나 열에 쉽게 적용할 수 있어, 데이터 처리 작업을 보다 효율적으로 할 수 있다.
예를 들어, 각 행의 최댓값과 최솟값의 차이 계산, 특정 열에 대해 복잡한 수학적 연산을 수행할 때 apply( ) 함수를 사용할 수 있다.
또한, apply( ) 함수는 코드를 간결하게 유지하면서도 강력한 데이터 처리 기능을 제공하며, 판다스에서 데이터 변환과 조직을 위한 핵심적인 도구로서, 데이터 분석 과정을 효과적으로 지원한다.
판다스 기초 전체 코드
'[파이썬 Projects] > <파이썬 기초>' 카테고리의 다른 글
| [파이썬] 파이썬기초: 자료형 - 문자열 자료형 (1) (2) | 2024.06.13 |
|---|---|
| [파이썬] 파이썬 기초: 자료형 - 숫자형 (0) | 2024.06.13 |
| [파이썬] 판다스 (Pandas) - 4 (0) | 2024.05.28 |
| [파이썬] 판다스 (Pandas) - 3 (0) | 2024.05.27 |
| [파이썬] 판다스 (Pandas) - 2 (0) | 2024.05.25 |



